📖 본 글은 모든 내용을 "Operating System Concepts Ed.10"에서 인용합니다.
👋 프로세스는 무엇일까?
💡 Process is a program in execution.
프로세스는 실행중인 프로그램이다.
💡 A process is the unit of work in a modern computer system.
프로세스는 현대 컴퓨터에서 "작업의 단위"이다.
1. 프로세스 개념
💡 In many respects, all these activities are similar, so we call all of them processes.
컴퓨터에서 실행하는 대부분의 프로그램은 비슷하게 동작하기 때문에,
특별한 구분 없이 "process"라고 부르기로 했다.
💡 It would be misleading to avoid the use of commonly accepted terms that include the word job (such as job scheduling) simply because the process has superseded job.
원래는 프로세스가 아니라 일(job)이라고 불렀었는데,
현대에 들어서서 프로세스가 job이라는 단어를 "상속"했다.
정리하자면, 프로세스는 추상적으로는 "작업"이면서,
시스템적으로는 메모리에 올라온 "실행중인 프로그램"이다.
구조
프로세스의 현재 작업 상황은 PC(program counter)가 보여준다.
가장 최근에 실행한 명령어(inst)의 주소를 가리킨다.
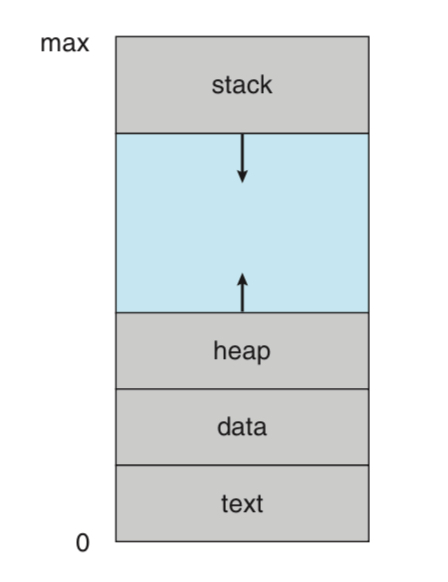
메모리 구조를 설명할 때 사용되는 아주 유명한 그림이다.
근데 이 메모리라고 하는 것이, 메인 메모리가 아니라 프로세스의 메모리다.
잘 보면 4개의 영역으로 나눠져 있는 것을 확인할 수 있다.
-
Text 영역
- 실행가능한 코드
-
Data 영역
- 전역 변수들
-
Heap 영역
- 동적으로 할당되게 남겨둔 메모리 공간
- malloc 함수 등이 여기를 사용한다
-
Stack 영역
- 함수를 호출할 때 사용되는 일시적인 공간
- 함수 인자, 리턴 주소, 지역 변수 등이 해당한다
그런데 text와 data 영역은 고정되어 있는데,
스택(stack)과 힙(heap) 영역은 화살표 방향으로 늘어난다.
💡 Each time a function is called, an activation record containing function parameters, local variables, and the return address is pushed onto the stak; when control is returned from the function, the activation record is popped from the stack.
매 함수 호출 시에, 앞서 언급한 data들이 stack으로 push된다.
이들은 activation record라고 부른다.
그리고 이들은 함수가 반환되면 pop이 되서 원래 주소로 돌아온다.
같은 방식으로, heap 영역도 동적으로 할당된 메모리에 대해서,
할당 시에 주소가 올라가고, 해제 시에 주소가 내려간다.
(스택은 push가 주소가 내려가는 구조임)
이렇게 서로 늘어나는 방향이 다르기 때문에,
여기서 운영체제는 서로 주소가 충돌하지 않게 조심해야 한다.
상태
💡 As a process executes, it changes state. The state of a process is defined in part by the current activity of that process.
모든 프로세스는 자신의 상태를 가지고 있다.
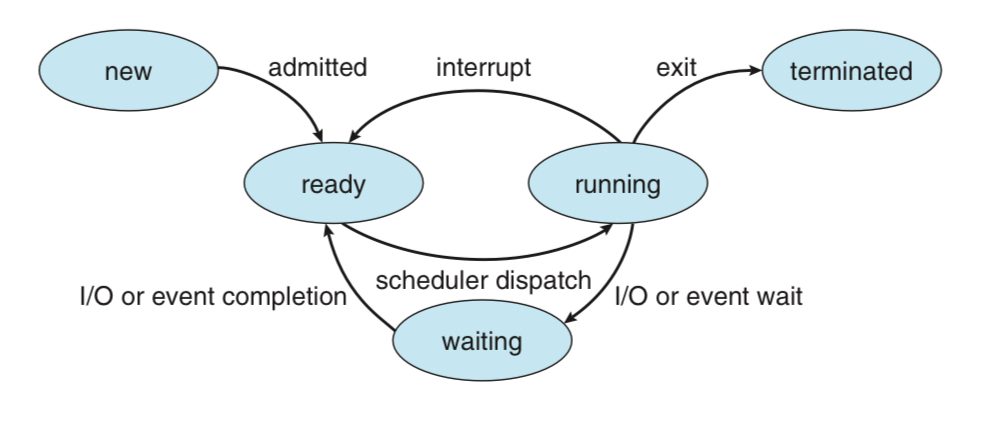
위의 그림을 바탕으로 아래 5가지 상태에 대해 알아보자.
- New: 프로세스가 새로 생성됨
- Running: 명령어들이 수행중 (실행중)
- Waiting: 이벤트(ex. I/O 완료) 등을 기다림
- Ready: 다시 실행되기를 기다림
- Terminated: 실행을 모두 완료함
프로세스의 상태 전이도나 이름 자체는 OS마다 다를 수 있다.
단, 실행중인 프로세스는 항상 한개여야 한다.
PCB
💡 Each process is represented in the operating system by a process control block (PCB) - also called task control block.
운영체제는 프로세스에 대한 정보를 PCB로 인식한다.
다시말해 PCB는 프로세스에 대한 필요한 정보를 가지고 있다.
흔한 오해이지만, PCB는 특정 목적을 가지고 만들어졌다기보다는 원래부터 있었다.
사실 매번 프로세스의 모든 data를 읽을 수는 없으니 PCB는 필수로 있어야 한다.
Block이라고 불리는 이유는 프로세스에 대한 데이터들이 쭉 이어져있기 때문이다.
PCB는 다음과 같은 많은 정보들을 포함하고 있다.
- 프로세스 상태
- PC (program counter)
- CPU 레지스터: 모든 CPU 레지스터가 포함된다
- CPU 스케줄링 정보: 우선순위, 큐 포인터 등
- 메모리 관리 정보: 메모리 저장 상태 (ex. 페이지)
- 어카운팅 정보: CPU 사용량, 시간 제한 등
- I/O 상태 정보: 연결된 외부 디바이스, 열린 파일 리스트 등
쓰레드
💡 The process model discuessed so far has implied that a process is a program that performs a single thread of execution
...
Single thread of control allows the process to perfrom a single thread of execution.
여태까지의 내용은 프로세스가 한가지 일만 한다는 가정이 있었다.
그리고 이게 바로 single thread이다.
싱글 스레드는 하나의 프로그램을 돌릴 때, 문자 그대로 하나의 일만 수행하는 것이다.
예를 들어 워드 프로세서를 사용하고 있다고 해보자.
타이핑을 하는 동시에 맞춤법 검사를 할 수 있을까?
Single thread는 하나의 "일"만 할 수 있으니 불가능하다.
그래서 여러개의 세부 작업을 동시에 실행하기 위해 multi thread 기술이 사용된다.
쓰레드에 대해서는 별도의 글로 자세히 배워보도록 하자.
2. 프로세스 스케줄링
💡 The objective of multiprogramming is to have some process running at all times so as to maximize CPU utilization.
멀티프로그래밍의 목표는 결국 CPU 사용량을 최대로 하는 것이다.
이는 운영체제를 대표하는 철학 중 하나이다.
💡 The objective of time sharing is to switch a CPU core among processes so frequently that users can interact with each program while it is running.
그리고 시간 공유의 목표는 프로세스들이 CPU 사용을 "아주 빠르게" 번갈아가면서 차지하는 것이다.
사용자 입장에서는 동시에 일어나는 것처럼 보이게 할 정도로 빠르다.
💡 To meet there objectives, the process scheduler selects an available process for program execution on a core.
위의 2가지 목표를 달성하기 위해 프로세스 스케줄러가 필요하다.
[참고]
현재 메모리에 올라온 프로세스의 개수를 "degree of multiprogramming"이라고 한다.
이 스케줄러를 잘 짜기 위해서 프로세스의 특성을 잘 파악할 필요가 있다.
보통 프로세스는 I/O bound와 CPU bound로 나뉘게 된다.
- I/O bound: 연산 시간보다 I/O 처리 시간이 더 긴 경우
- CPU bound: I/O가 적게 발생하고 연산이 많은 경우
스케줄링 큐
💡 As process enter the system, they are put into a ready queue, where they are ready and waiting to execute on a CPU's core.
기본적으로 모든 프로세스는 생성과 동시에 ready 큐에 들어간다.
바로 실행되는 것이 아님에 유의하자!
CPU 사용을 하고 나서는, 여러 큐 중에서 상황에 맞는 큐로 이동한다.
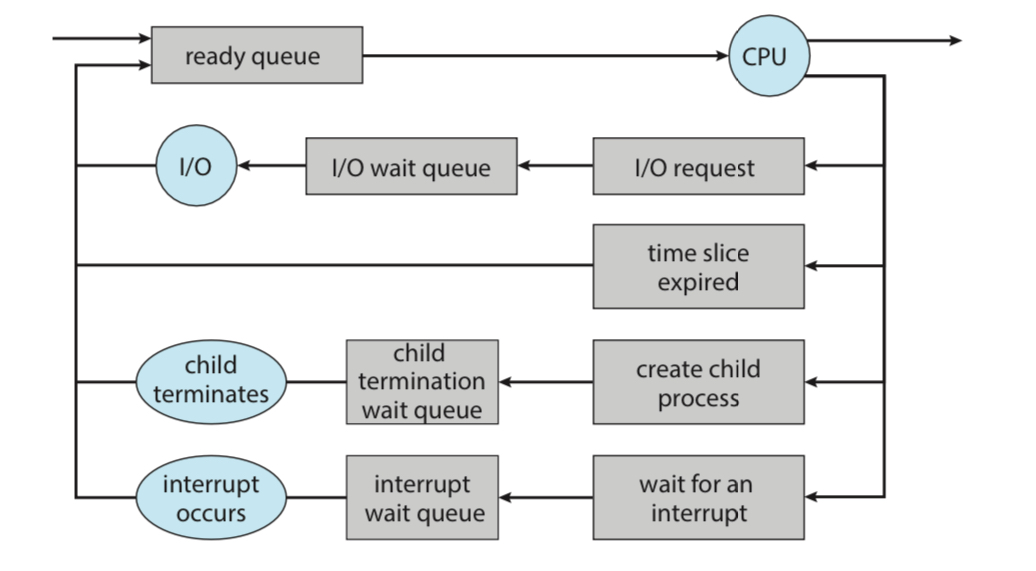
위의 그림은 프로세스의 일생을 일반적으로 보여준다.
CPU 사용 중에, I/O 발생, 시간 소진 등으로 인해 큐로 돌아가고,
본인의 차례를 기다리다가 선택되면 다시 CPU 사용을 시작한다.
💡 A process continues this cycle until it terminates, at which time it is removed from all queues and has its PCB and resources deallocated.
이 모든 과정은 프로세스가 종료될 때까지 계속한다.
종료 시에는 모든 큐로 부터 제거되고 PCB와 자원들을 해제당한다.
[참고]
프로세스를 queue로 보내는 것이 아닌, 아예 메모리에서 "잠깐" 제거하는 방식도 있다.
이 방식은 Swapping이라고 하는데, 메모리가 부족한 경우에 사용된다.
문맥 교환 (Context Switch)
💡 When an interrupt occurs, the system needs to save the current context of the process running on the CPU core so that it can restore that context when its processing is done, essentially suspending the process and then resuming it.
인터럽트가 발생할 경우, 시스템은 프로세스의 문맥(context)을 저장해야 한다.
그래야 나중에 어디까지 일을 했는지, 어떤 data를 쓰고 있었는지 가져올 수 있다.
그러면 그 문맥이라고 하는 것은 어디에 저장되고 어떻게 관리될까?
💡 The context is represented in the PCB of the process. It includes the value of the CPU registers, the process state, and memory-management information.
저번에 배웠던 PCB에 다 저장되어 있다.
복습하자면, PCB는 레지스터, 상태, 메모리 관리 정보 등이 들어있다.
💡 Switching the CPU core to another process requires performing a state save of the current process and a state restore of a different process. This task is known as a context switch.
그 정보들을 저장하고 다음 프로세스의 정보를 로드하는 것을 문맥교환이라고 한다.
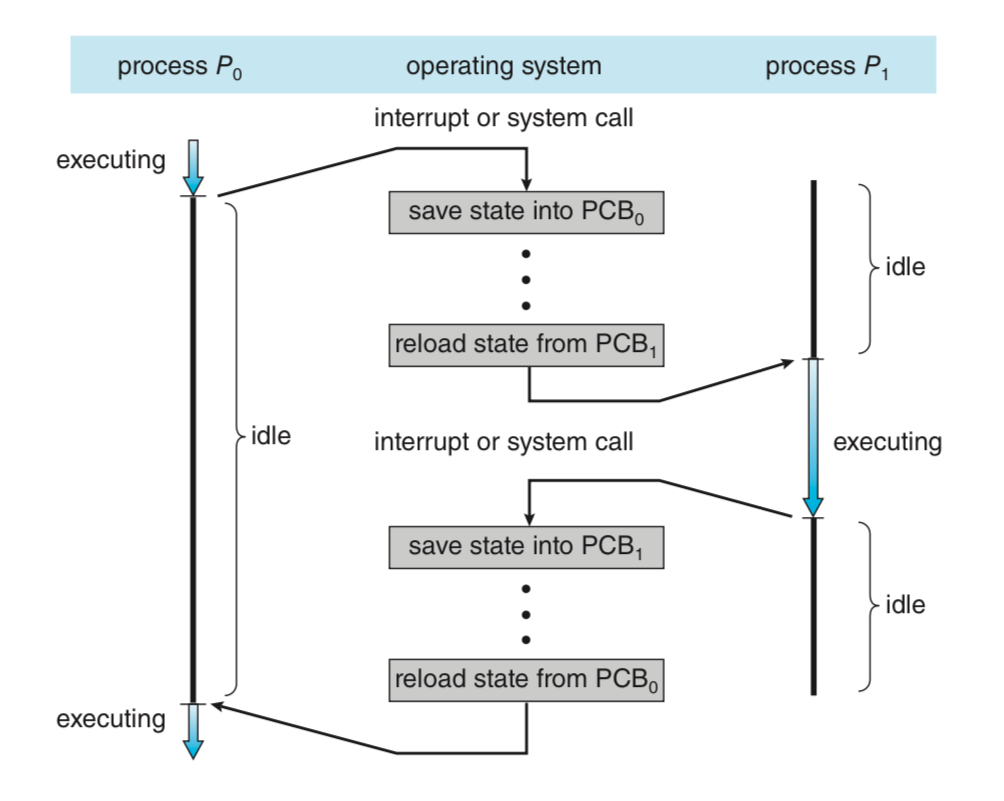
이 그림을 보면서 전체적인 흐름을 파악해보자.
3. 프로세스 관리
💡 The processes in most systems can execute concurrently, and they may be created and deleted dynamically. Thus, there systems must provide a mechanism for process creation and termination.
프로세스는 동시적으로 실행되고, 생성과 종료가 동적으로 발생하기 때문에,
OS는 이를 처리해줄 특수한 방법이 필요하게 되었다.
생성
💡 During the course of execution, a process may create several new processes. As mentioned earlier, the creating process is called a parent process, and the new processes are called the children of that process. Each of these new processes may in turn create other processes, forming a tree of processes.
프로세스가 실행되는 과정에서, 새로운 프로세스를 만들어야 하는 상황이 있을 것이다.
이 경우, 현재 프로세스가 부모 프로세스가 되고, 새로 생긴 프로세스가 자식 프로세스가 된다.
이런식으로 계속해서 프로세스가 만들어지면서 자연스럽게 트리 형태로 생성된다.
그러면 특정 프로세스가 트리의 어디에 있는 지 어떻게 알까?
💡 Most operating systems (including UNIX, Linux, and Windows) identify processes according to a unique process identifier (or pid), which is typically an integer number. The pid provides a unique value for each process in the system, and it can be used as an index to access various attributes of a process within the kernel.
꼭 트리를 타고 들어가야 찾을 수 있는 것은 아니다.
모든 프로세스는 본인의 고유한 ID를 가지고 있고, 보통 pid라는 int값을 갖는다.
이 pid는 kernel에 저장된 프로세스 속성에 접근하기 위한 index로 쓰이기도 한다.
생성과 동시에 부모 프로세스를 어떻게 할 것인지는 2가지 방식이 있다.
- 자식 프로세스 생성과 함께 본인도 계속 실행
- 자식 프로세스가 종료될 때까지 기다림
반대로 자식 프로세스에 대한 주소공간 방식도 2가지가 있다.
- 부모 프로세스의 내용을 전부 복사한다.
- 새로운 프로그램이 올라간다.
UNIX: fork()
우선 UNIX 계열의 프로세스 생성 함수인 fork()에 대해 알아보자.
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
pid_t pid;
pid = fork();
if (pid < 0) { // error
return 1;
}
else if (pid == 0) { // child process
execlp("/bin/ls", "ls", NULL);
}
else { // parent process
wait(NULL); // wait for the child to complete
}
return 0;
}💡 The only difference is that the value of the variable pid for the child process is zero, while that for the parent is an integer value greater than zero (in fact, it is the actual pid of the child process).
fork() 함수를 호출하면, int값을 반환받게 되는데,
자식 프로세스라면 0을 반환받게 되고,
부모 프로세스라면 0보다 큰 값 (자식 프로세스의 pid)를 받는다.
음수값이라면 임의의 오류가 발생했다는 뜻이다.
그러고 자식 프로세스에게 필요한 data를 덮어쓰기 해준다.
🔍 fork()는 기본적으로 부모 프로세스의 모든 정보를 자식에게 복사한다.
그러므로 pid가 0이 나오더라도, 부모와 아직은 똑같은 상태이다.
이후 exec() 함수를 통해서 필요 시에 자신의 프로그램 data를 덮어쓰는 것이다.
💬 위의 예시에서는 자식 프로세스에게 execlp() 함수를 호출하는데,
이는 exec() 시스템콜의 한 버전이다.
Windows: CreateProcess()
💡 CreateProcess() requires loading a specified program into the address space of the child process at process creation. Furthermore, whereas fork() is passed no parametes, CreateProcess() expects no fewer than ten parameters.
윈도우는 UNIX의 fork()와는 하는 기능이 비슷하지만, 사뭇 다르다.
우선, CreateProcess()는 자식 프로세스의 모든 정보를 가진 상태로 생성한다.
그리고 함수 호출인자가 최소 10개 이상이다.
아래 CreateProcess()의 예시 코드를 보자.
#include <stdio.h>
#include <windows.h>
int main(VOID)
{
STARTUPINFO si;
PROCESS_INFORMATION pi;
ZeroMemory(&si, sizeof(si));
si.cb = sizeof(si);
ZeroMemory(&pi, sizeof(pi));
if (!CreateProcess(NULL, "directory", NULL,
NULL, FALSE, 0, NULL, NULL, &si, &pi))
{
// creation failed
return -1;
}
WaitForSingleObject(pi.hProcess, INFINITE);
// child complete
CloseHandle(pi.hProcess);
CloseHandle(pi.hThread);
}보다싶이 호출 인자가 굉장히 많기 때문에 2가지만 짚고 넘어가자.
si는 STARTUPINFO 구조체의 객체로서,
창 크기나 시각 정보 등 프로세스 시작에 필요한 각종 정보가 담겨있다.
pi는 PROCESS_INFORMATION 구조체의 객체로서,
프로세스와 쓰레드에 대한 핸들과 식별자를 가지고 있다.
ZeroMemory() 함수를 통해 위 2가지 구조체에 대한 공간을 할당해주고,
다른 기본 자료형들과 함께 호출 인자로 전달해주는 것이다.
종료
💡 A process terminates when it finishes executing its final statement and asks the operating system to delete it by using the exit() system call. At that point, the process may return a status value (typically an integer) to its waiting parent process (via the wait() system call).
프로세스가 종료되는 시점은 본인의 마지막 코드까지 실행이 끝난 경우이다.
이때 호출하는 시스템콜은 exit().
때에 따라서 자식 프로세스가 종료되기까지 기다리는 wait()을 호출하기도 한다.
또, 필요에 따라서는 TerminateProcess() (Windows 함수) 등을 호출해서,
본인의 자식 프로세스를 강제로 종료하는 경우도 있다.
물론 이 경우에는 다른 자식 프로세스를 종료하지 못하게 막아둔다.
자식 프로세스를 종료시키는 이유는 여러가지 있겠지만, 대표적으로 3가지가 있다.
- 자식이 할당받은 자원을 초과해서 사용하려는 경우
- 자식에게 부여한 작업이 더 이상 필요가 없는 경우
- 부모가 종료되었지만 자식이 부모없이 실행되는 것이 금지된 경우
위의 3번처럼 부모없이 실행될 수 없는 자식들을 종료시키는 것을
Cascading Termination이라고 부른다.
Zombie(좀비)와 Orphan(고아)
💡 When a process terminates, its resources are deallocated by the operating system. However, its entry in the process table must remain there until the parent calls wait(), because the process table contains the process's exit status.
프로세스는 종료시에 OS가 자원을 모두 해제해버린다.
그러나, 프로세스 테이블에 프로세스의 엔트리가 남아있어야 한다.
왜냐하면 그 테이블은 프로세스의 종료 상태를 저장하기 때문이다.
하지만 부모 프로세스가 아직 wait()하지 않으면, 자식은 애매하게 남게 된다.
💡 A process that has terminated, but whose parent has not yet called wait(), is known as a zomie process.
이런 상황에 놓인 자식 프로세스를 zombie라고 부른다.
조금 더 최악의 상황을 고려해보자.
만약 부모 프로세스가 wait()이 아닌 exit()을 해버렸다면?
자식 프로세스는 부모의 wait()을 기다리고 있는데,
영원히 호출되지 않을 것이기 때문에 이를 orphan(고아) 프로세스라 한다.
UNIX는 이 경우에, exit()을 호출한 프로세스의 모든 자식 프로세스에게
init 프로세스를 부모 프로세스로 재지정해준다.
그리고 그 init 프로세스는 주기적으로 wait()을 호출해준다.
4. IPC (프로세스간 통신)
💡 Processes executing concurrently in the operating system mau be either independent processes or cooperating processes.
...
Clearly, any process that shares data with other processes is a cooperating process.
모든 프로세스는 독립적이거나 협력적이다.
다른 프로세스와 데이터를 공유한다면 협력적인 프로세스라 한다.
어떤 경우에 프로세스 간의 데이터 공유가 필요할까?
- 정보 공유
- 같은 데이터 조각이 필요한 여러 프로세스가 존재할 수 있다.
- 굳이 복사본을 만들 필요가 없으니 아예 공유하게 하자.
- 연산 속도
- 하나의 작업을 여러개의 서브태스크로 나눠서 속도를 올릴 수 있다.
- 멀티프로세싱 환경에서 가능하다.
- 모듈성 (Modularity)
- 하나의 기능을 여러 프로세스나 쓰레드로 나누는 경우에 필요하다.
그렇다면 프로세스간 데이터 공유를 어떻게 할까?
💡 Cooperating processes require an interprocess communication (IPC) mechanism that will allow them to exchange data - that is, send data to and receive data from each other.
IPC는 프로세스간 협력을 도와주는 방법론이다.
💡 There are two fundamental models of interprocess communication: shared memory and message passing.
IPC에는 2가지 방식이 있다: 공유 메모리와 메세지 전달
본격적으로 공부하기 전에 아래 그림을 보고 넘어가자.
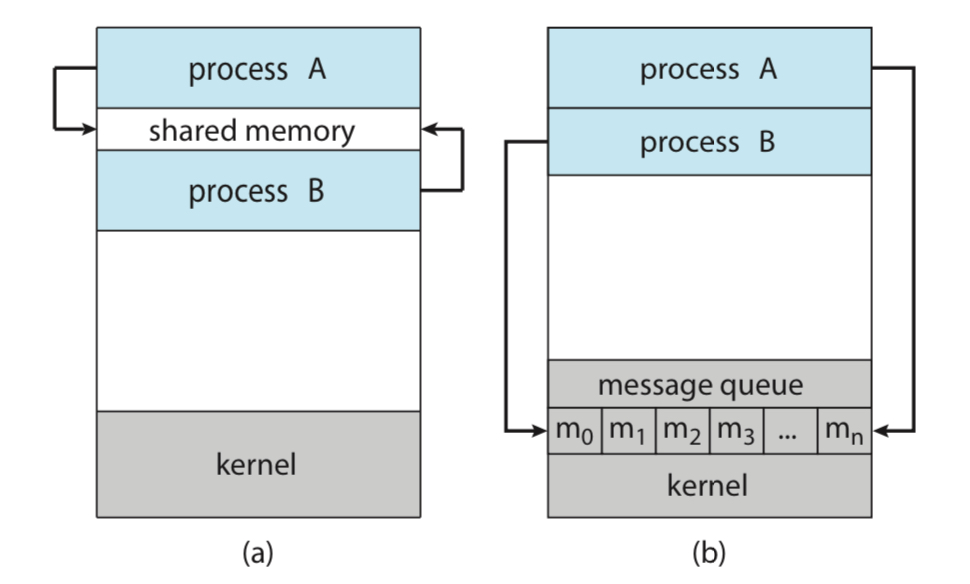
(a)가 공유 메모리이고 (b)가 메세지 전달이다.
메세지 전달 방식을 먼저 보자면, message queue가 있는게 보일 것이다.
어떤 프로세스가 필요한 data를 메세지처럼 큐에 쌓으면,
다른 프로세스가 시스템콜을 통해 읽어오는 방식이다.
💡 Message passing is useful for exchanging smaller amounts of data, because no conflcits need to be avoided.
충돌(conflict)이 일어날 일이 없기 때문에,
적은 양의 데이터를 주고 받을 때에도 효율적이다.
반면에 공유 메모리 방식은 속도가 상대적으로 빠르다.
💡 Shared memory can be faster than message passing, since message-passing systems are typically implemented using system calls and thus required the more time-consuming task of kernel intervention.
메세지 전달 방식을 시스템콜을 사용하기 때문에 느리다.
💬 공유 메모리도 결국 메모리 접근인데 시스템콜이 필요 없을까?
공유 메모리 공간을 할당하는 설정만 시스템콜이다.
이후에는 단순 메모리 접근이기에 커널의 도움이 필요없다.
그런데 사실 대부분의 시스템은 둘 다 구현해두기는 한다.
각자 유리한 상황에 알맞은 방식을 체택하면 되는 것이다.
공유 메모리
💡 Typically, a shared-memory region resides in the address space of the process creating the shared-memory segment. Other processes that wish to communicate using this shared-memory segment must attach it to their address space.
일반적으로, 공유메모리는 해당 프로세스 바로 옆 공간에 있어야 한다.
💬 공유메모리는 생산자-소비자 문제의 해결책 중 하나이다.
공유 공간을 사용함으로서 소비와 동시에 생산을 진행할 수 있다.
공유 메모리 안에는 버퍼를 두어서, 두 프로세스 간의 동기화를 해준다.
한 프로세스가 data를 생산하는 동시에, 다른 프로세스가 data를 사용할 수 있다.
버퍼는 2가지 종류로 나눌 수 있다.
-
Unbounded 버퍼: 사이즈에 제한이 없다.
-
Bounded 버퍼: 고정 사이즈로 구현된 버퍼.
이 중에서 bounded 버퍼의 코드 예시만 살짝 보고 넘어가자.
#define BUFFER_SIZE 10
typedef struct {
// details
} item;
item buffer[BUFFER_SIZE];
int in = 0;
int out = 0;1차원 배열이지만, in과 out이라는 논리적 포인터를 활용해서
원형 큐처럼 동작하게 만든 코드이다.
만약 ((in + 1) % BUFFER_SIZE) == out 이면 full이란 뜻이다.
메세지 전달
메세지 전달 방식은 공유 메모리에 비해 고민할 부분이 조금 더 많다.
크게 3가지 메세지 전달 기준이 있고, 하나씩 알아보자
-
Direct 또는 Indirect
-
Synchronous 또는 Asynchronous
-
Buffering 방식 (Automatic)
네이밍
우선 위의 1번 기준인 직접/간접 통신 방법에 대해 알아보자.
💡 Under direct communication, each process that wants to communicate must explicitly name the recipient or sender of the communication.
직접 통신 방식에서는 수신자 또는 송신자의 이름을 명시해야 한다.
send(P, message);
receive(Q, message);위의 코드를 보면 이해하기가 쉬운데,
전송하는 함수에는 받는 프로세스의 이름을 명시하고 있고,
수신하는 함수에서는 보낸 프로세스의 이름을 명시한다.
💡 This scheme exhibits symmetry in addressing; that is, both the sender process and the receiver process must name the other to communicate.
이러한 방식을 "균형"잡힌 통신이라고 한다.
그렇다면 프로세스 이름을 붙이면서 불균형인 방법도 있나?
💡 Variant of this scheme employs asymmetry in addressing. Here, only the sender names the recipient; the recipient is not required to name the sender.
송신할때만 수신자의 이름을 명시하는 방식이 "불균형" 방식이다.
send(P, message);
receive(id, message);마찬가지로 코드를 보면, send 함수는 동일하다는 것을 볼 수 있는데,
receive 함수는 받는 프로세스 Q 대신 id가 명시되어 있다.
여기서 id는 프로세스가 아닌 통신 그 자체에 붙는 id이다.
(적어도 어떤 통신의 메세지를 받아야 하는지는 알아야 하니까)
그러나 균형이든 불균형이든 한가지 단점이 존재한다.
💡 The disadvantage in both of there schemes (symmetric and asymmetric) is the limited modularity of the resulting process definitions.
모듈화에 있어서 제한사항이 있다는 것이다.
무슨 말이냐 하면, 통신하는 프로세스를 재정의하는 것이 어렵다는 것이다.
결국 프로세스나 통신의 id를 가지고 계속 통신을 해야하는 것인데,
그 id를 수정할 필요가 있다면?
-> 다른 모든 프로세스를 확인하면서 같이 수정해줘야 한다.
이 방식은 hard-coding의 일종이기 때문에 효율적이지 못하다.
그럼 이에 대한 해결방법이 있을까?
💡 With indirect communication, the messages are sent to and received from mailboxes, or ports.
메일박스나 포트를 통해서 특정 주소를 같이 참조하자.
프로세스나 통신은 유동적이기 때문에 일일히 id를 붙일 수도 없는 노릇이니,
서로 메일을 주고받는 것처럼 메일박스를 운용하자.
메일박스는 정적이기 때문에 id한번 붙여두고 여러 프로세스가 접근할 수 있을 것이다.
또한, 이런식으로 하면 N:N 통신도 가능해진다.
send(A, message);
receive(A, message);마찬가지로 send, receive 함수를 쓰기는 하지만,
송수신자 모두 A라는 메일박스의 이름을 붙여서 접근하는 모습니다.
동기화
앞서 얘기한 3가지 기준 중 2번째에 해당하는 내용이다.
💡 Message passing may be either blocking or nonblocking - also known as synchronous and asynchronous.
Blocking & Nonblocking은 Synchronous & Asynchronous와 같은 의미다.
💬 분명히 블로킹과 동기화는 다른 말로 알고 있는데, 왜 같다고 할까?
-> 그건 I/O를 얘기할 경우에 맞는 말이다.
(I/O에 대해 다룰 때 자세히 알아보자)
다시 돌아와서, 블로킹과 논블로킹의 차이는 무엇일까?
송신자, 수신자의 경우로 나눠서 살펴보자.
-
블로킹 송신: 수신자가 받을 때까지 하던일 멈춤
-
논블로킹 송신: 받든 말든 보내자마자 원래 하던일 계속함
-
블로킹 수신: 메세지가 available 할때까지 멈춤
-
논블로킹 수신: 메세지가 valid 하든 말든 일단 받음
💡 When both send() and receive() are blocking, we have a rendezvous between the sender and the receiver.
여기서 주목할 점은, 양쪽이 블로킹이라면 "랑데뷰"가 생긴다는 것이다.
💬 IPC 얘기하는데 웬 랑데뷰?
-> 랑데뷰는 두 주체가 만나는 지점이다. 여기서는 "합의점" 정도로 생각하면 된다.
다시 말해, 서로 기다려주기 때문에 통신 오류가 "거의" 없다.
버퍼링
메세지 전달 방식도 결국에는 큐이기 때문에 버퍼가 필요하다.
근데 그 큐도 3가지 방식으로 만들어질 수 있다.
-
Zero capacity: 큐의 길이가 0인 경우
- 다른 말로 송신자의 블로킹이다. (대기열이 없으니까)
-
Bounded capacity: 큐가 n이라는 고정된 길이를 가짐
- 메세지가 n개까지는 대기할 수 있음
- 단, n개 이상이 되려고 하면 block이 된다
-
Unbounded capacity: 큐의 길이가 무한임
- 즉, 송신자는 죽어도 블로킹 되지는 않음
앞서 얘기한 3가지 기준 중에서, automatic 버퍼링 방식이 2번, 3번이다.
1번 방식은 보통 No-buffering이라고도 부른다.
5. IPC 예시
앞서 얘기한 내용은 프로세스간 통신의 방법론인 것이고,
이제 가장 유명한 4가지 IPC 구현에 대해 알아보자.
POSIX는 공유 메모리,
Mach는 메세지 전달,
Windows는 공유 메모리 방식을 통한 메세지 전달,
PIPE는 UNIX 시스템 초기의 IPC 방식이다.
a) POSIX 공유 메모리
POSIX의 API는 다양하지만, 그 중에서도 공유 메모리만 살펴보자.
💡 POSIX shared memory is organized using memory-mapped files, which associate the region of shared memory with a file.
POSIX 공유 메모리는 메모리맵 파일을 사용해서 구성된다.
생산자 코드 정도만 살펴보면서 이해해보자.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fctnl.h>
#include <sys/shm.h>
#include <sys/stat.h>
#include <sys/mman.h>
int main()
{
const int SIZE = 4096;
const char *name = "OS"
const char *message_0 = "Hello";
const char *message_1 = "World!";
int fd;
char *ptr;
// create shared-memory object
fd = shm_open(name, O_CREATE | O_RDWR, 0666);
// configuring size
ftruncate(fd, SIZE);
// memory map the shared-memory object
ptr = (char*) mmap(0, SIZE, PROT_READ | PROT_WRITE | MAP_SHARED, fd, 0);
return 0;
}코드의 흐름은 다음과 같다.
-
우선 shm_open()을 통해 공유 메모리 오브젝트라는 것을 만들어준다.
-
이후, ftruncate()으로 사용할 메모리 크기를 조정해준다.
-
mmap()으로 오브젝트를 메모리에 mapping해주면 생성 끝!
이렇게 해서 열린 파일을 공유 메모리 영역에 매핑 해줌으로써,
여러 프로세스가 인접 메모리 영역을 통해 곧바로 파일에 접근할 수 있다.
🔍 나중에 자세히 공부하겠지만, 파일이라고 해서 꼭 외부장치에 있는 것은 아니다.
파일은 논리적인 자료구조이고, 여기서는 보통 (가상)메모리에 올라가는 파일을 얘기한다.
b) Mach 메세지 전달
💬 Mach는 운영체제 이름인데, 원래 분산시스템을 위해 디자인 되었다.
그런데 지금은 macOS와 iOS 안에 숨어있다.
Mach OS는 기본적으로 task라는 작업 단위를 사용하고, message를 통해 통신한다.
이때 모든 message는 port라는 공간을 통해 주고받아진다.
💡 Associated with each port is a collection of port rights that identify the capabilities necessary for a task to interact with the port.
여기서 가장 중요한 개념이 바로 port right인데,
port를 접근할 "권리"에 대한 내용이다.
모든 task는 본인이 port를 생성할 수 있고,
이 port로 메세지를 보내고 싶은 프로세스에게 "전송 권리"를 할당한다.
반대로 본인이 상대의 port로 메세지를 보내고 싶은 경우에는
상대방의 port에 대한 전송 권리를 할당 받아야 한다.
그러면 상대의 port 번호를 어떻게 알게될까?
💡 Each task also has access to a bootstrap port, which allows a task to register a port it has created with a system-wide bootstrap server. Once a port has been registered with the bootstrap server, other tasks can look up the port in this registry and obtain rights for sending messages to the port.
그건 바로 "부트스트랩 서버"에 등록을 하기 때문이다.
다른 task는 보내고 싶은 task의 port를 서버에서 찾아서 권리를 얻게 되는 것이다.
메세지 자체는 직접 보내지만, 그 과정에서 port에 대한 관리자를 서버가 해주는 것!
일단 이정도만 알아보고, Mach OS의 메세지 매핑 방식만 확인하고 넘어가자.
💡 The Mach message system attempts to avoid copy operations by using virtual-memory-management techniques. Essentially, Mach maps the address space containing the sender's message into the receiver's address space.
메세지 전달 방식의 가장 큰 문제점이 내용을 복사한다는 것인데,
Mach는 "가상 메모리 관리"를 통해 메세지 주소끼리 매핑해준다.
즉, 실제로 메세지가 복사되는 경우는 없고,
출발 주소를 도착 주소와 매핑해줘서 메세지 원본을 직접 참조하게 만든다.
c) Windows 운영체제
Windows는 Server-Client 구조로 IPC를 지원한다.
💡 The message-passing facility in Windows is called the advanced local procedure call (ALPC) facility.
...
Windows uses two types of ports: connection ports and communication ports.
우선 client와 연결을 성사시켜주는 connection 포트가 공개적으로 열려있다.
통신을 희망하는 client는 이 포트를 통해 communication 포트를 할당받는다.
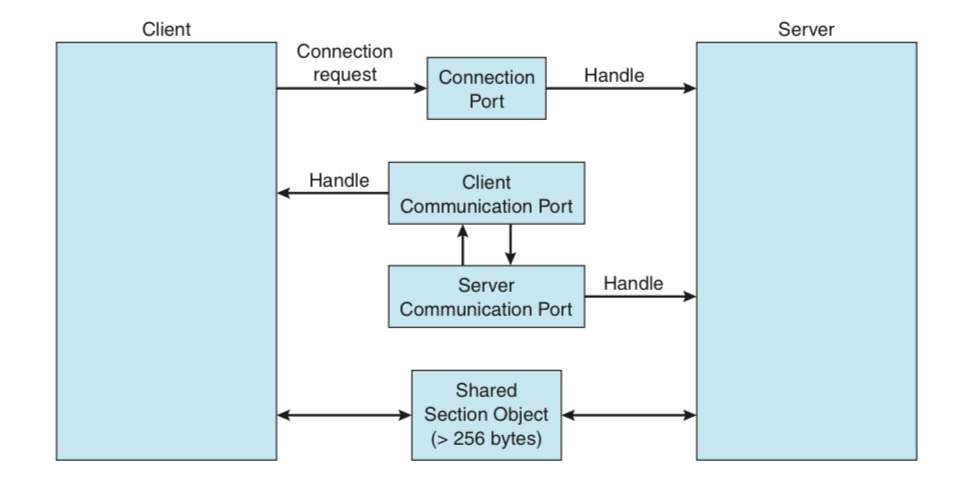
위의 그림처럼 연결이 성사되었다면, 아래 3가지 방법에 따라 통신하게 된다.
-
작은 메세지 (~256bytes): port에 있는 메세지 큐를 통해 통신한다
-
큰 메세지: Section Object를 통해 메세지를 전달한다
- Section Object는 공유메모리의 한 부분이다
-
감당할 수 없을 정도로 큰 메세지: client 공간에 직접 접근
- 서버가 클라이언트 주소공간 내에 직접 써준다
💡 It is important to note that the ALPC facility in Windows is not part of the Windows API and hence is not visible to the application programmer. Rather, applications using the Windows API invoke standard remote procedure calls.
여기서 중요한 건, ALPC는 API가 아니라는 것이다.
어플리케이션 차원에서는 ALPC 대신 RPC를 호출한다.
🔍 RPC는 네트워크를 통해 다른 프로세스의 주소 공간에 접근하는 것을 얘기한다.
d) 파이프 (PIPE)
마지막으로 UNIX 초기의 IPC 방식에 대해 알아보자.
(아마 지금까지 방식 중에 가장 많이 들어봤을 것이다)
💡 A pipe acts as a conduit allowing two processes to communicate.
...
In the following sections, we explore two common types of pipes used on both UNIX and Windows systems: ordinary pipes and named pipes.
파이프는 두 프로세스 간의 통신을 돕는 "도관"이다.
그리고 파이프의 종류는 크게 "보통 파이프"와 "유명 파이프"가 있다.
보통 파이프 (Ordinary Pipe)
💡 Ordinary pipes allow two processes to communicate in standard producer-consumer fashion: the producer writes to one end of the pipe (the write end) and the consumer reads from the other end (the read end).
보통 파이프는 생산자-소비자 방식으로 통신하는 것이다.
생산자가 한쪽 끝에서 쓰면, 소비자가 반대쪽에서 읽는 단방향 통신.
만약 양쪽으로 통신이 가능해야 한다면, 파이프를 2개 쓰면 되는 것이다.
💡 An ordinary pipe cannot be accessed from outside the process that created it. Typically, a parent process creates a pipe and uses it to communicate with a child process that it creates via fork().
그러나, 이러한 방식은 임의의 프로세스와 통신할 수 있는 것이 아니다.
부모 프로세스와 자식 프로세스 간의 통신에만 사용된다.
그래서 fork() 함수가 실행된 직후에 pid를 분기로 pipe를 생성해준다.
비슷하게 Windows에서는 "익명 파이프"를 사용한다.
보통 파이프와 아주 유사한 방식으로 동작하는데, 한가지 다른 점이 있다.
💡 Unlike UNIX systems, in which a child process automatically inherits a pipie created by its parent, Windows requires the programmer to specify which attributes the child process will inherit.
자동으로 pipe 속성을 상속받는 보통 파이프와는 다르게,
익명 파이프는 pipe를 생성할 때 개발자가 직접 속성을 명시해줘야 한다.
명명 파이프 (Named Pipe)
💡 Named pipes provide a much more powerful communication tool. Communication can be bidirectional, and no parent-child relationship is required. Once a named pipe is established, several processes can use it for communication.
명명 파이프는 단일 파이프로 양방향 통신이 가능하며,
부모-자식 관계 외의 여러 프로세스들이 전부 연결 가능하다.
💡 Named pipes are referred to as FIFOs in UNIX systems.
UNIX에서는 이를 FIFO라는 이름으로 가지고 있다.
파이프가 생성되면, 시스템 상으로는 일반적인 "파일"로 인식된다.
하지만 통신이 양방향이더라도, FIFO는 half-duplex 전송만 허용한다.
반대로 Windows에서는 full-duplex 전송을 지원한다.
🎯 마치며
프로세스는 공부할 내용이 너무나도 많다.
IPC는 너무 어렵다.
그래도 하나만큼은 꼭 기억하고 가자.
"프로세스는 실행중인 프로그램이다"
출처
Abraham Silberschatz, 『Operating System Concepts Ed.10』
