📖 본 글은 모든 내용을 "Operating System Concepts Ed.10"에서 인용합니다.
👋 쓰레드는 무엇일까?
💡 A thread is a basic unit of CPU utilization; it compromises a thread ID, a program counter (PC), a register set, and a stack. It shares with other threads belonging to the same process its code section, data section, and other operating-system resources, such as open files and signals.
쓰레드는 CPU를 차지하는 가장 기본적인 단위이다.
ID, PC, 레지스터, 스택을 각각 가지며, 코드, 데이터, OS 자원을 공유한다.
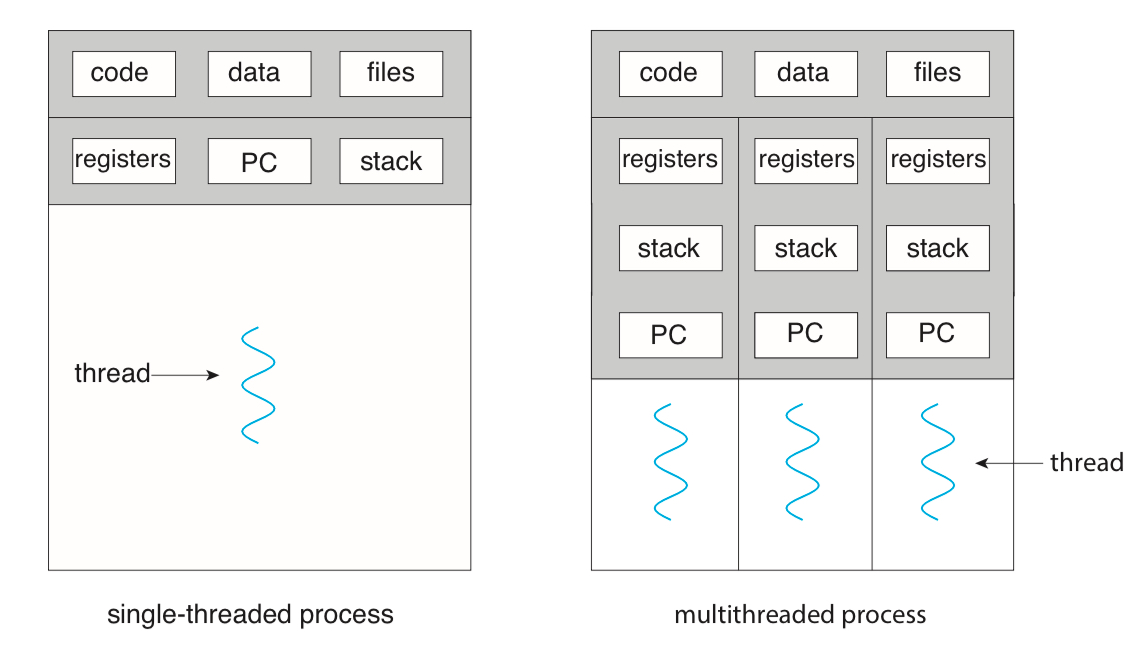
우리가 여태 공부한 내용은 왼쪽의 그림처럼 싱글쓰레드의 경우였다.
그러나, 현대의 컴퓨터는 멀티쓰레드를 주로 사용하고, 오른쪽 그림처럼 생겼다.
1. 개요
쓰레드의 등장
웹 서버를 예시로 들어보면 쓰레드의 존재가치를 쉽게 받아들일 수 있을 것이다.
유저의 요청을 기다리는 Listener 프로세스가 있다고 가정하자.
새로운 접속 시도가 있을 때마다 그에 해당하는 프로세스를 만들게 되면,
프로세스 생성의 오버헤드를 매번 감당해야할 것이다.
그러나, 우리는 프로세스 생성 과정이 오래 걸린다는 것을 이전 챕터에서 공부했다.
어차피 계속해서 "요청 처리"라는 로직을 똑같이 처리할 건데 굳이 프로세스가 필요할까?
따라서, 굳이 프로세스가 아니라 쓰레드를 사용하면 유리할 것 같다.
이처럼 "같은 역할"을 수행해야 한다면, 프로세스 대신에 쓰레드를 사용하는 것이다.
쓰레드의 장점
💡 The benefits of multithread programming can be broken down into four major categories.
멀티쓰레딩의 장점은 크게 4가지의 카테고리로 정리할 수 있다.
-
Responsiveness
- 쓰레드 중 하나가 먹통이 되거나 너무 긴 로직을 수행하는 경우,
다른 쓰레드가 일하면 되기 때문에 반응성이 올라간다. - 사용자와 상호작용이 많은 프로그램에서 특히 체감이 된다.
- 쓰레드 중 하나가 먹통이 되거나 너무 긴 로직을 수행하는 경우,
-
Resource sharing
- 자원을 공유하는 것은 공유 메모리와 메세지 패싱이 있는데,
이들의 도움 없이 자연스럽게 자원을 공유할 수 있다.
- 자원을 공유하는 것은 공유 메모리와 메세지 패싱이 있는데,
-
Economy
- 쓰레드의 생성은 프로세스의 생성보다 오버헤드가 적다.
- 컨텍스트 스위칭 역시 (일반적으로) 프로세스보다 빠르다.
- 위와 비슷하지만, 메모리도 적게 사용해서 유리하다.
-
Scalability
- 멀티코어 프로세싱에서 굉장히 유리하다.
- 싱글스레드는 멀티코어 프로세서에서 병렬적으로 실행될 수 없다.
2. 멀티코어 프로그래밍
중요한 개념을 하나 짚고 넘어가도록 하자.
하나의 CPU는 몇개의 쓰레드를 실행할 수 있을까?
쓰레드가 실행의 최소단위이기 때문에,
CPU는 한번에 하나의 쓰레드만 실행시킬 수 있다.
결국 멀티코어 CPU의 경우에 멀티쓰레딩 기법이 효율을 갖는 것이다.

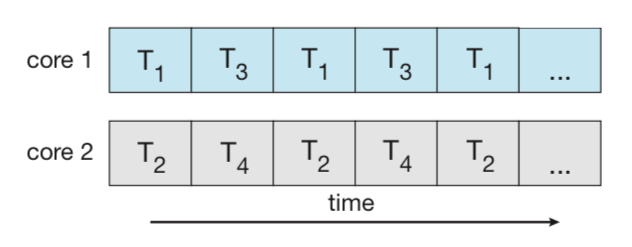
위의 그림을 보면, 코어가 하나인 경우에는 쓰레드 4개를 돌아가며 실행해야 한다.
그러나 코어가 2개라면 쓰레드를 2개씩 맡을 수 있어서 시간이 반으로 단축된다.
그러면 이제 멀티코어의 느낌을 보았으니, 2개의 주요 개념을 비교해보도록 하자.
💡 Notice the distinction between concurrency and parallelism in the discussion. A concurrent system supports more than one task by allowing all the tasks to make progress. In contrast, a parallel system can perform more than one task simultaneously.
하나의 코어가 여러 개의 쓰레드를 실행시키는 것이 "동시성"이다.
여러 쓰레드가 한 시점에 동시에 실행되고 있으면 "병렬성"이다.
위의 그림 2장 에서 첫 번재 그림이 동시성이고,
두 번째 그림이 동시성 + 병렬성이라고 생각하면 된다!
프로그래밍 주의사항
멀티코어에 맞춰서 멀티쓰레드를 생성하는 것은 생각해야 할 것들이 많다.
크게 5가지 관점에서 고민을 해봐야 한다.
- Task 구분
- 앱을 분석하여 분리될 수 있는 태스크를 찾는 것
- 이상적으로는, 모든 태스크가 완전히 독립적으로 돌아가는 것이다
- 밸런스
- 태스크 간의 CPU 사용량을 비슷하게 만들 것
- Data 나누기
- 각 코어에 적절한 data가 들어가는 것
- Data 의존성
- 2개 이상의 task가 접근하는 data의 동기화 (이후 챕터에서 다룸)
- 테스트 & 디버깅
- 멀티코어에서는 다양한 실행경로가 존재할 수 있다
- 각 코어의 실행에 따라 연산 결과가 달라질 수 있다
병렬성의 종류
💡 In general, there are two types of parallelism: data parallelism and task parallelism.
병렬성은 크게 데이터 중심적인 방식과 태스크 중심적인 방식으로 나뉜다.
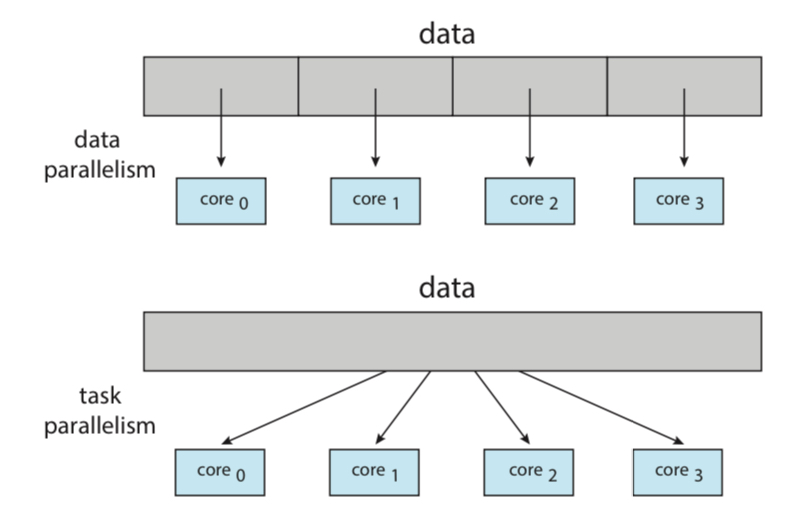
위의 그림 같은 경우가 데이터 병렬성이다.
각 task는 같은 로직을 수행하되, 접근하는 data를 나누는 것이다.
예를 들어, N의 크기를 갖는 배열의 모든 원소의 합을 구한다고 했을 때,
0번 코어가 앞 부분의 N/2개의 합을 구하고,
1번 코어가 나머지 뒷부분 원소의 합을 구하는 방식이다.
아래의 그림이 태스크 병렬성이다.
같은 데이터를 공유하지만, 각 task가 다른 로직을 수행하는 것이다.
예를 들어, 워드 프로세싱 작업을 한다고 했을 때,
0번 코어에서는 사용자 입력을 받아주고,
1번 코어가 그래픽 처리를 해주는 동시에,
2번 코어가 문법 검사를 백그라운드에서 진행하는 것이다.
💬 물론, 위의 2가지 방식이 완전 독립적이지는 않고,
경우에 따라 방법을 적절히 섞은 hybrid 방식도 존재한다.
3. 멀티쓰레딩 모델
이제 아주 중요한 개념인 user thread와 kernel thread에 대해 알아보자.
💡 User threads are supported above the kernel and are managed without kernel support, whereas kernel threads are supported and managed directly by the operating system.
유저 쓰레드는 커널의 도움 없이 유저 레벨에서 실행되고,
커널 쓰레드는 OS가 "직접" 관리하고 운용한다.
그리고 유저 쓰레드와 커널 쓰레드는 반드시 접점이 있어야 한다.
유저가 만든 쓰레드가 하드웨어 자원을 만지기 위해서는 결국 OS의 역할이 필요한데,
이걸 가능하게 해주는 것이 커널 쓰레드라고 보면 된다.
💬 사실상 현대에 모든 OS는 커널쓰레드를 지원한다.
Many-to-One
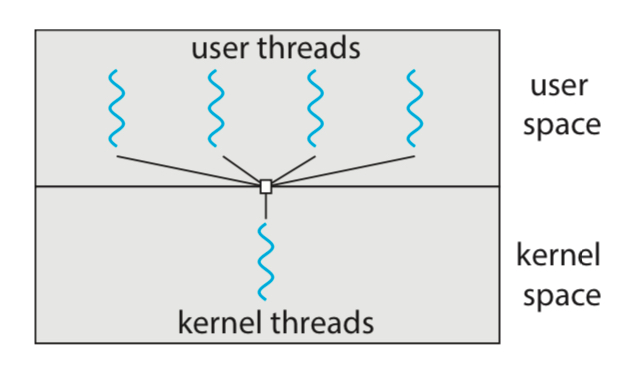
커널은 하나의 쓰레드를 지원하고, 여러 유저 쓰레드가 나눠서 쓴다.
유저 공간에서 쓰레드 라이브러리가 쓰레드를 관리하기 때문에,
효율적인 사용이 가능하다는 장점이 있다.
단, 커널 측 쓰레드가 하나이기 때문에,
blocking 시스템 콜을 호출한다면, 모든 쓰레드가 먹통이 된다.
또한, 커널 쓰레드가 하나이기 때문에 "병렬성"이 보장되지 않는다.
Green threads (라이브러리)가 이 모델을 사용했지만,
멀티코어의 장점을 살리기 어렵다는 이유로 거의 사용되지 않는다.
🔍 Green threads란?
쓰레드 라이브러의 일종으로서, 초기 Java version에 사용되었다.
One-to-One
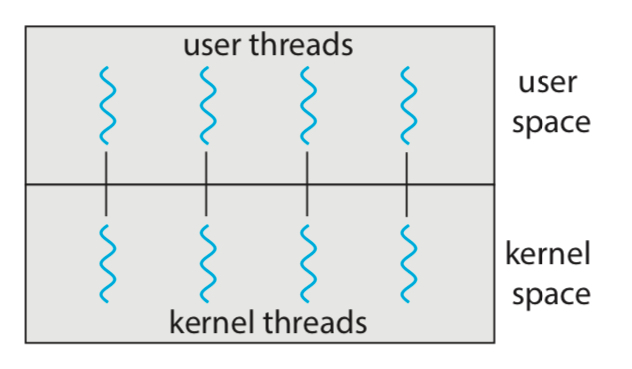
간단히 말해, 모든 유저 쓰레드가 각각의 커널 쓰레드와 매핑이 되는 것이다.
Many-to-One 모델이 가지고 있던 한계점 2개를 극복했다.
1. 블로킹이 발생해도 다른 쓰레드는 문제없이 태스크를 수행한다.
2. 커널 쓰레드가 여러개기 때문에 멀티코어에서의 병렬성이 보장된다.
그러나, 유저 쓰레드가 너무 많아지면, 커널 쓰레드도 같이 많아지기 때문에
시스템 자체에 과부하를 줄 수 있다는 유일한 단점이 존재한다.
그럼에도 불구하고 Linux와 Windows 계열 OS들은 이 모델을 체택한다.
(아래에서 볼 Many-to-Many의 특성을 보면 이유를 알 수 있다)
Many-to-Many
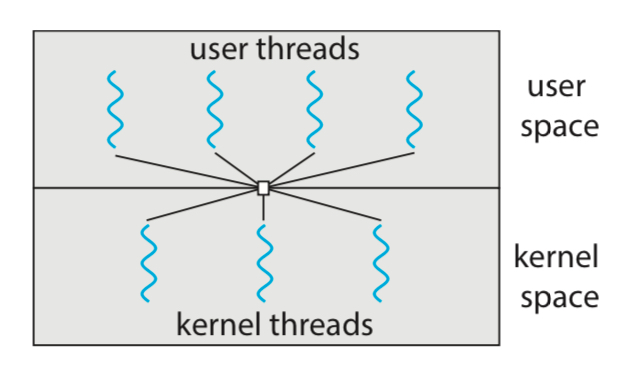
유저 쓰레드 N개를 N개 이하의 커널 쓰레드에 멀티플렉싱하는 방식이다.
🔍 멀티플렉싱이란?
간단히 말해, N개의 객체를 M개의 객체에 매핑시키는 것
이 모델을 체택할 경우, 위에서 살펴본 2개의 모델의 한계점을 전부 극복한다.
유저 쓰레드를 아무리 많이 만들어도, 커널 쓰레드의 개수를 제한하면 그만이고,
멀티코어도 지원하면서 블로킹에도 끄떡없이 동작할 수 있다.
그럼에도 이 모델을 사용하지 않는 이유는 2가지가 있다.
💡 Although the many-to-many model appears to be the most flexible of the models discussed, in practice it is difficult to implement. In addtion, with an increasing number of processing cores appearing on most systems, limiting the number of kernel threads has become less important.
우선, 현실적으로 이를 구현하는 것이 어렵다.
또한, 점점 코어의 개수가 늘어나는 마당에 커널 쓰레드 개수를 제한하는 것이 중요해지지 않고 있다.
4. 쓰레드 라이브러리
쓰레드 라이브러리는 크게 3종류가 있다: POSIX, Windows, Java
POSIX, Windows의 경우는 OS 차원에서 제공되고,
주로 C언어로 구현되기 때문에 전역변수를 쓰레드끼리 공유한다.
Java는 특이하게 JVM이라 하는 가상 머신 위에서 동작하기 때문에,
호스트(기반 OS)에 따라 POSIX 또는 Windows API를 사용하게 된다.
또한, 자바에는 전역변수라는 개념이 없기 때문에,
공유하고 싶은 자원을 직접 명시해야 한다는 특징이 있다.
아래에서는 쓰레드로 "음이 아닌 N개의 정수"를 더하는 과정을
3가지 쓰레드 라이브러리를 활용해서 예시를 간단히 들어보고자 한다.
그 전에, 쓰레딩 기법이 2가지가 있는데 간단히 알아보고 넘어가자.
- 비동기 쓰레딩
부모 쓰레드가 자식 쓰레드를 생성한 뒤, 아예 모르는 쓰레드인 것 마냥 원래 하던 일을 하러 돌아간다. - 동기 쓰레딩
부모 쓰레드는 자식 쓰레드를 생성한 뒤, 그들이 일을 끝낼 때까지 본인의 일을 하지 않고 계속해서 대기한다.
아래 3가지 예시 모두 동기 쓰레딩임을 인지하자.
PThreads (POSIX)
💡 Pthreads refers to the POSIX standard defining an API for thread creation and synchronizaion. This is a specification for thread behavior, not an implementation.
Pthread는 POSIX 스탠다드로서, 쓰레드 생성과 동기화에 대한 API이다.
조심해야 하는 점은, Pthread는 "구현"이 아니라 "명세"에 불과하다는 것이다.
코드를 보면서 어떻게 생겼는지 살펴보자.
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
iut sum; // global variable (shared)
void *runner(void *param); // summation function for threads
int main(int argc, char *argv[])
{
pthread_t tid;
pthread_attr_t attr;
pthread_attr_init(&attr);
pthread_create(&tid, &attr, runner, argv[1]);
pthread_join(tid, NULL);
printf("sum = %d\n", sum);
}
void *runner(void *param)
{
int i, upper = atoi(param);
sum = 0;
for (i = 1; i <= upper; i++)
sum += i;
pthread_exit(0);
}우선, pthread 헤더파일을 불러와서 API를 사용하도록 하자.
음이 아닌 정수 값을 더한 전역변수 sum과,
쓰레드가 실행하게 될 함수 runner을 선언해준다.
main 함수로 들어가게 되면, 그 함수를 실행하면 init 쓰레드가 있을 것이다.
이 쓰레드가 본인의 자식 쓰레드를 하나 만들어준다.
자식 쓰레드를 생성할 때, 쓰레드의 ID와 생성 인자를 전달해준다.
생성 인자는 스택 사이즈와 스케줄링 기법 등이 있다.
(위의 예시에서는 기본값으로 전달하고 있다)
만들어진 쓰레드는 runner 함수를 실행하게 되고,
그 과정에서 모든 정수값을 sum에 더하게 된다.
앞서 말했듯이, 전역변수는 모든 쓰레드가 공유할 것이기 때문에,
init 쓰레드가 printf에서 sum을 불러와도 적절한 값이 출력된다.
그러나 위의 예시는 싱글쓰레드를 예시를 든 것이고,
요즘처럼 멀티쓰레드로 하려면 아래의 예시를 참고해보자.
#define NUM_THREADS 10
pthread_t workers[NUM_THREADS];
for (int i = 0; i < NUM_THREADS; i++)
pthread_join(workers[i], NULL);쓰레드가 저장될 배열을 만들어 둔 뒤,
join 함수를 통해서 10개의 쓰레드를 생성을 해주는 것이다.
Windows
윈도우 쓰레딩 API는 POSIX의 것과 굉장히 유사하다.
#include <windows.h>
#include <stdio.h>
DWORD WINAPI Summation(LPVOID Param)
{
DWORD Upper = *(DWORD*)Param;
for (DWORD i = 1; i <= Upper; i++)
Sum += i;
return 0;
}
int main(int argc, char *argv[])
{
DWORD ThreadId;
HANDLE ThreadHandle;
int Param;
Param = atoi(argv[1]);
ThreadHandle = CreateThread
(NULL, 0, Summation, &Param, 0, &ThreadId);
WaitForSingleObject(ThreadHandle, INFINITE);
CloseHandle(ThreadHandle);
printf("sum = %d\n", Sum);
}💬 C가 익숙하지 않다면 아래 몇가지만 짚고 넘어가자.
DWORD는 32-bit 정수 값이다.
LPVOID는 void형 포인터이다.
Handle이라는 쓰레드의 속성을 담고 있는 자료형만 제외하면,
전체적으로 흐름이 Pthread와 거의 동일하다.
Windows에서도 멀티쓰레딩을 하고 싶다면,
WaitForSingleObject 대신 WaitForMultipleObject를 사용하면 된다.
Java
자바에서의 쓰레드는 몹시 중요한 개념이다.
💡 All Java programs comprise at least a single thread of control - even a simple Java program consisting of only a main() method runs a single thread in the JVM.
main() 함수 하나만 들고 있는 간단한 프로그램이라도,
JVM에서 최소 한 개의 쓰레드가 동작하고 있다.
Java에서 쓰레드를 생성하는 방식은 크게 2가지가 있다.
첫번째는 Thread 클래스를 상속받아 run 메소드를 오버라이딩 하는 것이고,
두번째는 Runnable 인터페이스를 장착해서 run 추상 메소드를 사용하는 것이다.
(보통은 2번째 방식을 주로 사용한다)
Java는 high-level한 언어이기 때문에 예시도 간단하다.
class Task implements Runnable
{
public void run() {
System.out.println("I am a thread.");
}
}앞서 설명한 방식대로 단 3줄로 thread를 구현했다.
쓰레드를 구현하는 데에 성공했으니, 이제 실행시켜보자.
Thread worker = new Thread(new Task());
worker.start();Java에서의 쓰레드 생성은 Runnable을 장착한 객체를 전달하는 것으로 완료된다.
이후, start 메소드를 invoke하는 것으로 작업을 시작한다.
start 메소드는 내부적으로 2가지 일을 하게 되는데,
1. 메모리를 할당하고 JVM 내에 새로운 쓰레드를 생성한다.
2. JVM이 동작시킬 수 있게 run 메소드를 호출한다.
Java Executor 프레임워크
Java가 버전 1.5에 들어서면서, 쓰레드 관련 API를 강화했다.
java.util.concurrent 패키지에서 찾아볼 수 있다.
기존과 달라진 점은 Thread 객체를 굳이 만들지 않더라도,
Executor 인터페이스를 통해 자동으로 관리된다는 점이다.
public interface Executor
{
void execute(Runnable command);
}이 인터페이스를 장착하는 클래스는 execute 메소드를 정의해줘야 한다.
이후, 아래와 같이 execute해주면 된다.
Executor service = new Executor;
service.execute(new Task());사실 얼핏 보면, worker을 만들 때 Task를 집어 넣는 것과
이처럼 service을 실행시킬 때 Task를 넣는 것과 비슷해 보인다.
그냥 Task를 언제 어디에다 넣는 지만 바뀐게 아닌가?
사실 맞다.
그러나 여기서 중요한 점은, Executor는 producer-consumer 모델이라는 점이다.
서비스를 만들 때, 어떤 task가 들어오는 지 아직 모른다.
실행시키고 있는 task를 service에게 실행시키라고 하면,
service는 그 task를 "소비"해서 실행시키는 것이다.
그렇다면 이렇게 했을 때의 장점이 뭘까?
💡 The advantage of this approach is that it not only divides thread creation from execution but also provides a mechanism for communication between concurrent tasks.
쓰레드의 생성과 실행을 구분시켜줄 뿐만 아니라,
실행되고 있는 쓰레드간의 소통을 가능하게 해준다는 것이다.
앞서 얘기했듯이, Java에는 전역 변수라는 개념이 없기 때문에,
return 값으로 소통을 해야 하는데, 쓰레드는 return 값이 없다!
그래서 Callable 인터페이스가 새로 등장한다.
Runnable과 비슷하지만, 결과값을 제공한다는 점에서 차이가 있다.
Callable task가 결과값을 future object에 저장해서 리턴한다.
다른 task는 future 객체에서 get 메소드로 결과값을 빼올 수 있다.
더 자세한 건 아래 코드를 보면서 살펴보도록 하자.
import java.util.concurrent.*;
class Summation implements Callable<Integer>
{
private int upper;
public Summation(int upper) {
this.upper = upper;
}
public Integer call() {
int sum = 0;
for (int i = 1; i <= upper; i++)
sum += i;
return new Integer(sum);
}
}
public class Driver
{
public static void main(String[] args) {
int upper = Integer.parseInt(args[0]);
ExecutorService pool = Executors.newSingleThreadExecutor();
Future<Integer> result = pool.submit(new Summation(upper));
try {
System.out.println("sum = " + result.get());
} catch (InterruptedException | ExecutionException ie) {}
}
}Summation 클래스가 Callable 인터페이스를 장착하고 있다.
그리고 call 함수가 별도의 쓰레드로 실행되는 함수이다.
call 함수 마지막에 결과값을 리턴하고 있다는 것도 보일 것이다.
Driver 클래스가 메인 함수를 가지고 있는 클래스이다.
Pool에다가 새로운 쓰레드를 생성해주고 있고,
Summation 클래스를 실행시켜준 후에 result라는 Future 객체에 저장해준다.
마지막으로 try문에서 result.get()을 통해 결과값을 뽑아준다.
이러한 방식을 체택했을 때 장점이 2가지가 더 있다.
- 부모 쓰레드는 자식 쓰레드가 종료될 때까지 기다리는 것이 아니라,
자식 쓰레드가 "결과값"을 도출할 때까지만 기다린다. - 바로 다음에 배울 내용과 결합하여 강력한 쓰레드 관리 툴이 될 수 있다.
5. 암묵적 쓰레딩
여태 배운 내용들을 활용하여 멀티쓰레딩을 해볼려고 해도,
사실은 쓰레드의 개수가 무수히 많아지고 있는 추세이다.
이를 도와주기 위해 등장한 개념이 바로 암묵적 쓰레딩이다!
💡 One way to address these difficulties and better support the design of concurrent and parallel applications is to transfer the creation and management of threading from application developers to compilers and run-time libraries. This strategy, termed implicit threading, is an increasingly popular trend.
앱 개발자들의 쓰레드 관련 고충을 덜기 위해, 쓰레드 생성과 관리 과정을 컴파일러와 런타임 라이브러리에게 맡기는 것이 암묵적 쓰레딩이다.
지금부터 우리는 개발자가 "쓰레드"가 아닌 "태스크"를 만든다고 가정할 것이고,
그 태스크를 쓰레드로 만드는 전략을 몇가지 살펴볼 것이다.
Thread Pool
맨 앞부분에서 웹 서버를 예시로 들면서 쓰레드의 필요성에 대해 얘기했다.
그러나 여전히 단점이 존재하는데,
1. 한번 쓴 쓰레드는 버려지고,
2. 쓰레드의 개수가 너무 많아지면 시스템에 과부하를 준다
이 2가지 한계점을 해결할 수 있는 것이 바로 "쓰레드 풀"이다.
💡 The general idea behind a thread pool is to create a number of threads at start-up and place them into a pool, where they sit and wait for work.
메인 아이디어는 풀 생성과 동시에 쓰레드를 여러개 만들어 놓고,
각자 본인이 할 수 있는 일을 대기하는 것이다.
쓰레드 풀을 사용했을 때의 이점은 크게 3가지가 있다.
- 요청에 대한 새로운 쓰레드를 만드는 것보다,
놀고 있는 쓰레드를 재활용 하는 것이 빠를 때가 있다. - 쓰레드가 무한히 생성되는 것을 막을 수 있다.
- 태스크의 실행과 관련해 여러가지 커스터마이징이 가능하다.
- 일정 시간 뒤에 실행하거나, 주기적으로 실행시키는 등
💬 쓰레드의 사용 상태를 봐가면서 개수를 조절하여 최적화를 할 수도 있다.
Java Thread Pool
Java는 쓰레드 풀과 관련해 특히 강력한 지원을 해준다.
앞서 봤던 newSingleThreadExecutor() 외에 2개가 더 있는데,
newFixedThreadPool()은 고정된 사이즈의 풀을 생성해주고,
newCachedThreadPool()은 제한 없이 유동적으로 사용되는 풀을 생성해준다.
심지어는 쓰레드의 종료까지 단 한줄로 간편하게 할 수 있게 도와준다.
궁금하다면 아래 코드를 읽고 넘어가도록 하자.
import java.util.concurrent.*;
public class ThreadPoolExample
{
public static void main(String[] args) {
int numTasks = Integer.parseInt(args[0].trim());
ExecutorService pool = Executors.newCachedThreadPool();
for (int i = 0; i < numTasks; i++)
pool.execute(new Task());
// shut down the pool once all threads have completed
pool.shutdown();
}
}Fork Join (Java)
쓰레드 라이브러리를 배울때, 동기 쓰레딩이라는 용어를 사용했다.
fork-join 방식이 동기 쓰레딩의 다른 이름이기도 하다.
사실, fork-join 방식이 명시적 쓰레딩의 대표적인 예시이기도 하지만,
반대로 암묵적 쓰레딩이 될 수 있는 방식이기도 하다.
이를 잘 보여주는 것이 Java 1.7버전이다.
자바에서 API를 활용하여 분할정복 알고리즘을 실행해보자.
Java는 설정된 THRESHOLD 이하의 크기에 대해서는,
금방 끝나는 task라 가정하고 곧바로 해결한다.
반대로 task의 크기가 크다고 판단되면, thread를 할당해준다.
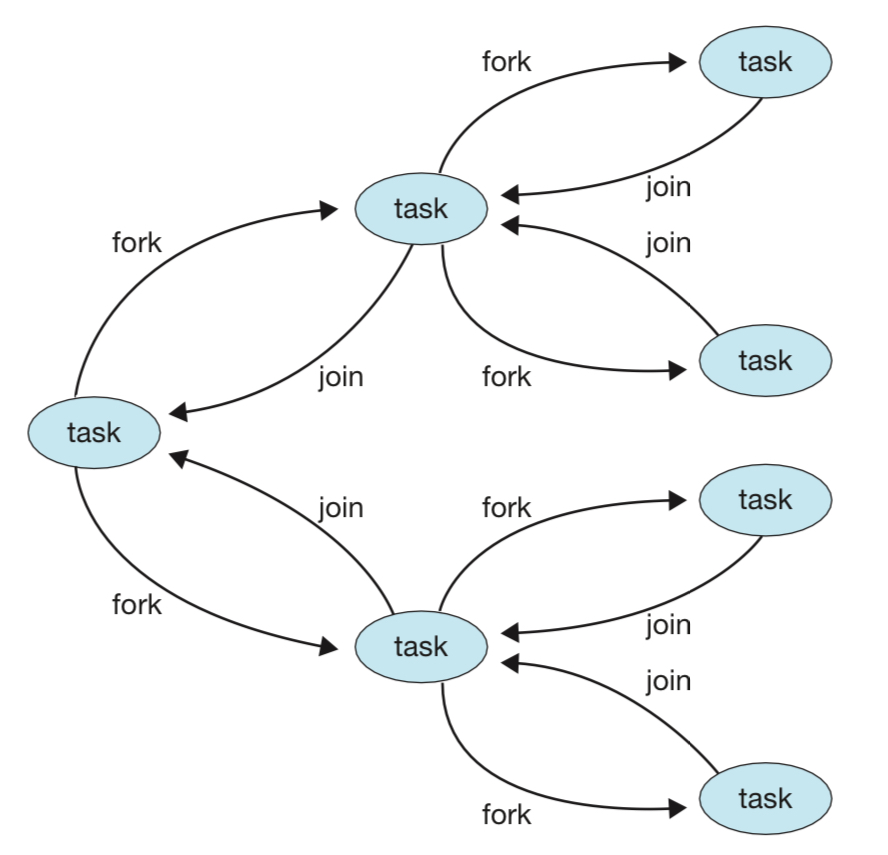
위의 그림이 JVM이 쓰레드를 관리하는 모습을 잘 보여준다.
하나의 task에서 2개의 자식 task를 만들어 쓰레드를 할당하고,
그 자식 task 역시 다시 2개의 자식 쓰레드를 만드는 것을 반복하다.
연산이 끝난 task는 join을 하면서 결과값을 부모 쓰레드에게 전달한다.
이런 방식을 통해 Java는 분할정복 알고리즘을 빠르게 수행할 수 있다.
OpenMP
💡 OpenMP is a set of compiler directives as well as an API for programs written in C, C++, or FORTRAN that provides support for parallel programming in shared-memory environments.
OpenMP는 컴파일러 디렉티브의 집합이면서, API이기도 하다.
C 계열의 언어에게 공유메모리 환경에서의 병렬 프로그래밍을 지원해준다.
🔍 컴파일러 디렉티브란?
#define, #include와 같이 컴파일러에게 지시하는 명령어
OpenMP의 특징은 특정 코드 영역을 "parallel region"으로 설정하는 것이다.
코드가 진행되다가 parallel region으로 들어서게 되면,
기본값으로 최대 개수의 쓰레드를 생성하게 된다.
(코어가 4개면 4개의 쓰레드, 코어가 8개면 8개의 쓰레드)
N개의 정수가 담긴 배열 A와 B의 값을 더해서
C라는 배열에 저장하는 코드를 예시로 들어보자.
#include <omp.h>
#include <stdio.h>
#define MAX 1000
int main(int argc, char *argv[])
{
int a[MAX], b[MAX], c[MAX];
// array init
#pragma omp parallel for
for (int i = 0; i < MAX; i++) {
c[i] = a[i] + b[i];
}
}컴파일러 디렉티브인 #pragma를 확인하면,
쓰레드를 코어 개수에 맞춰 최대로 생성을 해준 뒤,
각 쓰레드는 a, b, c 배열을 각각 맡아서 연산을 시작한다.
물론, 코어 개수에 맞출 필요 없이 개발자가 직접 개수를 설정할 수도 있다.
Grand Central Dispatch (GCD)
💡 Grand Central Dispatch (GCD) is a technology developed by Apple for its macOS and iOS operating systems. It is a combination of a run-time library, an API, and language extensions that allow developers to identify sections of code(tasks) to run in parallel.
GCD는 Apple사에서 개발한 런타임 라이브러리, API, 언어 확장의 결합 기술로서,
개발자에게 특정 영역을 병렬적으로 실행하도록 도움을 준다.
GCD는 OpenMP와 꽤 유사한 성질을 가지고 있는데,
태스크를 "dispatch queue"라는 자료구조에 넣고 스케줄링한다는 점이 다르다.
이 디스패치 큐라는 자료구조는 다시 2가지 타입이 있다.
- Serial Queue
- FIFO의 구조로 되어있다.
- 제거된 태스크가 일을 끝내기 전까지 다른 태스크는 제거될 수 없다.
- 모든 프로세스는 본인만의 serial queue를 가지고 있다.
- 순차적인 로직을 수행하는 경우에 적합나다.
- Concurrent Queue
- 마찬가지로 FIFO의 구조로 되어있다.
- 한번에 여러 태스크가 동시에 제거될 수 있다.
- 이들은 4가지 quality-of-service 클래스로 나뉘어져 있다.
그러면 quality-of-servce 클래스는 어떤 것들이 있을까?
- User-interactive
- 유저와 상호작용을 하는 작업들- 일의 양이 적을 것이 보장되어야 한다
- User-initiated
- 상호작용하는 작업들이긴 하지만, 좀 더 길어도 된다- 파일을 여는 등의 작업이 여기에 해당한다
- 우선적으로 실행되어야 유저가 다음 작업을 할 수 있는 일들이다
- Utility
- 즉각적인 결과가 나오지 않아도 되지만 일의 양이 많은 경우- 중요한 데이터를 다루는 작업도 여기에 해당한다
- Background
- 유저에게 보이지도 않고, 완료 시간도 중요하지 않는 경우- 클라우드에 백업하는 작업 등이 여기에 해당한다
💬 GCD는 내부적으로 Pthread로 구성이 되어 있다.
Thread Building Blocks (TBB)
💡 Intel threading building blocks (TBB) is a template library that supports designing parallel applications in C++. As this is a library, it requires no special compiler or language support.
인텔의 TBB는 C++로 디자인하는 앱을 위한 탬플릿 라이브러리이다.
라이브러리이기 때문에 어떠한 컴파일러나 언어의 지원이 필요 없다.
개발자가 task를 명시만 해준다면, TBB가 알아서 쓰레드에 매핑해준다!
이 TBB task 스케줄러는, 로드밸런싱을 해주는 동시에,
캐시의 상황까지 고려해서 동작한다.
캐시에 데이터가 있을 법한 task를 우선적으로 처리하게 시킨다.
또한, STL에 제공되는 다양한 자료구조도 안전한 버전으로 제공해준다.
아래에서 TBB를 사용하는 코드의 예시를 확인해보자.
// normal code
for (int i = 0; i < n; i++) {
apply(v[i]);
}
// using TBB
parallel_for(size_t(0), n, [=](size_t i) {apply(v[i]);});여기서 중요한 것은 parallel_for 함수의 인자들이다.
기본형은 parallel_for(range, body)의 형태이다.
우선 size_t(0)과 n이 반복문을 돌 범위를 나타낸다.
뒤의 인자가 C++ 람다 함수인데, 조금 복잡하다.
[=](size_t i)라는 인자가 반복문 범위의 각 원소를 나타낸다.
(위 예시에서는 0 ~ n-1이 될 것이다)
그 다음 람다 함수 인자로 v[i]로 넘기면서 함수를 실행시켜준다.
TBB는 위 코드에서 내부적으로 chunk라는 단위로 반복문을 나누게 된다.
그리고 각 chunk에서 일할 task를 생성해줌과 동시에,
그 task를 할당할 thread까지 생성해서 매핑을 해준다.
Java의 fork-join과 방식이 꽤 비슷하다.
🎯 마치며
코어의 개수가 많은 요즘, 쓰레드가 정말 중요하게 느껴진다.
작동 방식을 알고 쓰면 코드를 더 잘 짤 수 있지 않을까 싶다.
출처
Abraham Silberschatz, 『Operating System Concepts Ed.10』
