📖 본 글은 모든 내용을 "Operating System Concepts Ed.10"에서 인용합니다.
1. 기본 개념
사실 OS에서 새로운 개념을 배울 때 가장 헷갈리는 것 중에 하나가,
프로세스를 얘기하는지 쓰레드를 얘기하는지일 것이다.
본 블로그는 참고하는 서적에 따라 일반적인 경우는 "프로세스"를 기본으로 한다.
쓰레드 스케줄링의 경우는 아래에서 하나의 챕터로 따로 배울 예정이다.
한가지 더 정리해야 하는 점은 CPU와 Core간의 관계이다.
앞으로 "CPU에서 동작"이라는 말은 "Core에서 동작"이라고 생각하면 된다.
💬 Core는 연산의 기본 단위이다.
헷갈린다면 코어가 프로세스 하나를 실행시킬 수 있는 단위라고 보면 된다.
CPU-I/O 버스트
모든 프로세스는 CPU 사용량이 많은 CPU-bound와,
I/O 대기가 많은 I/O-bound로 나뉠 수 있다.
그렇다고 꼭 한쪽으로 극심하게 치우친 것은 아니다.
어떤 프로세스든 간에 대략적인 사이클을 가지고 있다.
보통 CPU → I/O → CPU → I/O → ...
이런식으로 CPU burst로 시작하는 사이클이다.
💬 Burst는 특정 기능을 많이 필요로 하는 상황을 얘기한다.
CPU burst라 하면 잠시 CPU를 많이 사용하게 된다는 뜻이다.
그래서 운영체제의 "CPU Scheduler"가 이러한 특성들을 잘 고려하여 다음으로 실행될 프로세스에 대한 선택을 하게 된다.
그리고 뒤에서 자세히 다루겠지만, 선택을 기다리는 프로세스들은
ready queue라는 자료구조에 저장되고, 실제로 저장되는 것은 PCB다.
선점형 (Preemptive)
우선 스케줄러가 결정을 내리는 상황은 다음과 같이 4가지가 있다.
- running → waiting (I/O 대기 또는 wait() 호출)
- running → ready (인터럽트 발생)
- waiting → ready (I/O 처리 완료)
- termination (프로세스 종료)
💡 For situations 1 and 4, there is no choice in terms of scheduling. A new process must be selected for execution. There is a choice, however, for situations 2 and 3.
1번과 4번의 경우는 스케줄러의 선택에 의해 발생하지 않는다.
반대로 2번과 3번의 경우는 스케줄러의 선택이 있다.
1번과 4번만 존재하게 하는 스케줄링 방식이 바로
"nonpreemptive"(비선점) 또는 "cooperative"이다.
그러나 2번이나 3번의 경우도 존재하는 방식이라면?
그것이 바로 "preemptive"(선점) 방식이다.
💬 현재의 거의 모든 OS는 선점형 알고리즘을 채택한다.
적어도 Windows, macOS, Linux, UNIX가 그러하다.
그런데 사실 선점형 스케줄링은 race condition이 발생할 여지가 있다.
(다음 챕터에서 race condition에 대해 자세히 다룰 것이다)
그렇다면 왜 선점형을 사용하는 것일까?
그건 계속해서 강조해왔던 동시성 때문이다.
2번의 경우를 없앤다는 것 자체가 interrupt를 허용하지 않겠다는 건데,
그렇다면 여러 프로세스를 동시에 실행시키는 것처럼 보이게 못하지 않겠는가.
우리는 인터럽트는 당연히 있는 거라고 생각해야 하고,
그러다보니 자연스럽게 선점형 알고리즘이 자리를 잡게 된 것이다.
디스패처 (Dispatcher)
디스패처는 꽤나 생소한 용어일 수 있지만, 사실 익숙한 일을 한다.
스케줄러가 선택한 프로세스에게 Core의 제어권을 넘겨주는게 이 친구다!
참고로 디스패처가 하는 일은 아래 3가지로 볼 수 있다.
- 문맥 교환
- user mode로 전환
- 프로그램의 마지막 실행 시점으로 jump
즉, 이전 프로세스가 일을 중단하는 바로 그 시점부터,
다음 프로세스가 실행되기 바로 직전까지의 과정을 수행한다.
스케줄링 기준
스케줄링 알고리즘의 종류는 정말 많다.
그래서 알고리즘을 선택하기 위한 기준들이 정리가 되어있다.
아래의 주요 기준들을 살펴보고 목적에 맞는 알고리즘을 선택하면 된다.
-
CPU Utilization: CPU를 최대한 1초도 쉬지 않게 만들어야 한다.
-
Throughput: 특정 시간 내에 완료된 프로세스의 수
-
Turnaround Time: 특정 프로세스가 완료되기 위한 총 시간
-
Waiting Time: ready queue에서 기다린 시간
-
Response Time: 사용자의 입력에 대한 반응 시간
위의 5가지 기준을 전부 맞추기에는 힘들 수 있다.
그래서 컴퓨터의 용도에 맞게 잘 조절하는 것이 중요하다.
2. 스케줄링 알고리즘
FCFS
💡 With this scheme, the process that requests the CPU first is allocated the CPU first.
CPU를 먼저 요청하는 프로세스에게 사용할 기회를 먼저 준다.
우리가 흔히 쓰는 FIFO Queue로 아주 쉽게 구현할 수 있다.
이 방식은 "공평성"에서는 굉장히 좋은 알고리즘이지만,
사실 CPU 사용량과 프로세스 대기 시간에 있어서 최악이다.
| 프로세스 | CPU 사용시간 (초) |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
편의상 CPU 사용시간을 초 단위라고 치고 위의 표를 보자.
위의 순서대로 프로세스가 들어왔다고 치면,
P2는 24초를 기다리고, P3는 27초를 기다려야 한다.
3개의 프로세스가 평균 17초의 대기시간을 갖는다
그런데 순서를 살짝만 바꿔서 P2 → P3 → P1 순서로 왔다고 친다면?
P3는 3초를 기다리고, P1은 6초만 기다리면 된다.
3개의 프로세스가 평균 3초만 대기하게 된다!
이렇게 CPU 사용시간이 긴 프로세스가 먼저 오게 되었을 때,
평균 대기시간이 굉장히 큰 폭으로 증가하게 될 수도 있다.
심지어, 만약 P2와 P3가 I/O bound 프로세스라고 한다면,
1초만 수행하고 I/O 기다리러 다시 큐 뒤쪽으로 가게 된다.
그러면 나머지 2초를 위해서 다시 27초를 기다려야한다!
💡 There is a convoy effect as all the other processes wait for the one big process to get off the CPU.
여러 프로세스가 하나의 긴 프로세스를 기다리는 "convoy" 효과가 발생한다.
SJF
SJF는 위의 문제인 "평균 대기시간"을 줄이기 위한 알고리즘이다.
Shortest-Job-First, 즉 "짧은 프로세스 먼저"라는 뜻이다.
💡 Note that a more appropriate term for this scheduling method would be the "shortest-next-CPU-burst" algorithm, because scheduling depends on the length of the next CPU burst of a process, rather than its total length.
정확히 하자면, "다음 CPU 버스트가 적은 프로세스 먼저"가 맞는 표현이다.
그러나 SJF가 줄임말이 편하기도 하고 직관적이라 이렇게 많이 부른다.
| 프로세스 | CPU 사용 시간 (초) |
|---|---|
| P1 | 6 |
| P2 | 8 |
| P3 | 7 |
| P4 | 3 |
만약 위의 표대로 프로세스가 들어왔다고 치자.
그렇다면 SJF에 따라서 실행되는 프로세스의 순서는 아래와 같다.
P4 → P1 → P3 → P2
이렇게 했을 때 평균 대기시간이 이론적으로 가장 짧다!
그런데 왜 "이론적으로" 짧다고 말하는 것일까?
사실 SJF는 평균 대기시간도 짧을 뿐만 아니라,
특정 시간 내에 가장 많은 프로세스를 완료시키는 throughput이 제일 높다.
하지만 여기서 제일 큰 문제는, 프로세스의 CPU 버스트 타임을 알 수 없다는 것.
그래서 프로세스의 다음 버스트 타임을 예측하는 수식이 생기게 되었다.
t가 가장 최근에 발생 버스트 타임을 들고 있는 변수고,
τ는 그 전까지의 버스트 타임을 기록하는 변수이다.
위의 수식은 τ가 2개라서 좀 헷갈릴 수 있으니,
직접 계산해보고 싶다면 아래의 전체 수식을 참고해보자.
위의 α값은 개발자가 직접 설정을 할 수 있는 변수로,
값이 1에 가까우면 현재 정보, 0에 가까우면 예전 정보에 의존하게 된다.
α값을 1/2 근처로 두면 과거와 현재의 정보를 잘 저울질하면서 예측할 수 있게 된다.
SRTF
여태까지가 "짧은 작업"을 먼저 하는 거였다면,
SRTF는 "남은 시간이 짧은 작업"을 뜻하게 된다.
Shortest-Remaining-Time-First의 줄임말로,
정확히는 SJF의 선점형 버전이라고 보면 된다.
| 프로세스 | 도착 시간 | CPU 사용 시간 (초) |
|---|---|---|
| P1 | 0 | 8 |
| P2 | 1 | 4 |
| P3 | 2 | 9 |
| P4 | 3 | 5 |
P1이 0초에 먼저 도착해서 1초를 먼저 실행한다.
이후, P2가 도착하는데, P1은 7초가 남고 P2는 4초가 남았으니까
P1은 다시 큐 뒤로가고 P2를 먼저 실행해주는 방식이다.
SJF와 비교했을 때, 평균 대기시간이 보다 짧아진다.
대신 어디까지나 선점형이기 때문에 공평성을 해칠 수 있다는 단점은 있다.
💬 공평성이라는 얘기가 계속 나오는데, 왜 중요할까?
공평성이 보장된다는 것은 CPU 사용을 뺏기지 않는다는 말이다.
이게 중요한 이유는 프로세스가 끝나는 시간을 예측할 수 있기 때문이다.
Round-Robin
💡 The round-robin (RR) scheduling algorithm is similar to FCFS scheduling, but preemption is added to enable the system to switch between processes. A small unit of time, called a time quantum or time slice, is defined.
라운드 로빈 방식은 FCFS와 유사하지만, 선점형이 추가된 방식이다.
타임 퀀텀이나, 타임 슬라이스라는 새로운 시간 단위가 추가된다.
여기서 타임 퀀텀은 프로세스가 CPU를 한번에 들 수 있는 최대 시간이다.
보통 10~100 미리초 사이로 설정되는데, 그 시간이 지나면 CPU를 놔줘야 한다.
사실 이 방식은 문맥교환도 자주 일어나고, 평균 대기시간도 결코 짧지 않다.
그럼에도 불구하고 모든 프로세스가 조금씩은 진전이 있다는 점이 강점이다.
어려운 개념이 아니니, 계산해보고 싶다면 아래 예시 표를 보고 해보자.
| 프로세스 | CPU 사용 시간 (초) |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
타임 퀀텀이 2일 때, 10일 때를 가정하고 한번씩 해보면 금방 감을 잡을 수 있다.
넘어가기 전에 한가지 특징을 잡고 가자면,
타임 퀀텀이 너무 짧다면 문맥교환이 너무 자주 일어나서 overhead가 크고,
반대로 너무 길면 FCFS와 다를 점이 없어진다.
💬 80%의 CPU 버스트는 타임퀀텀보다 짧아야 하는 규칙이 있다.
Priority
💡 The SJF algorithm is a special case of the general priority-scheduling algorithm.
SJF도 우선순위 스케줄링 알고리즘의 일종이다.
우선순위 스케줄링 자체는 말 그대로 이해하면된다.
각 프로세스에 우선순위를 줘서, 높은 우선순위부터 실행하는 것이다.
SJF의 경우에는 다음 CPU 버스트 시간이 짧은 것이 우선순위가 높은 경우이다.
| 프로세스 | CPU 사용 시간 (초) | 우선 순위 |
|---|---|---|
| P1 | 10 | 3 |
| P2 | 1 | 1 |
| P3 | 2 | 4 |
| P4 | 1 | 5 |
| P5 | 5 | 2 |
위 표를 예시로 들어서 평균 대기시간을 계산해보자.
실행 순서는 P2→P5→P1→P3→P4과 같을 것이고,
총 0+1+6+16+18=41초의 총 대기시간과 8.2초의 평균 대기시간을 가진다.
💬 우선순위가 작을수록 중요도가 높다는 뜻이다.
하지만 이 부분은 사람마다 생각하는 것이 다르기 때문에,
본 블로그에서는 인용하는 책의 기준대로 용어를 사용한다.
정리 : 우선순위가 높다 == 우선순위 값이 낮다
💡 Priorities can be defined either internally or externally.
우선순위는 내부적이나 외부적으로 설정될 수 있다.
내부적으로는 프로세스의 특성, 열린 파일의 개수 등으로 계산될 수 있고,
외부적으로는 프로세스의 중요도 등의 개발자의 생각이 반영될 수 있다.
💡 Priority scheduling can be either preemptive or non preemptive.
우선순위 스케줄링은 선점/비선점이 정해진 바가 없다.
더 중요한 프로세스가 왔다고 해서 기존 프로세스를 중단할 필요는 없다.
물론 선점형으로 구현하여 강제로 CPU를 넘겨주는 방식을 체택할 수도 있다.
💡 A major problem with priority scheduling algorithms is indefinite blocking, or starvation.
우선순위 스케줄링의 큰 문제는 굶주림 현상이 있다는 것이다.
만약 우선순위가 높은 프로세스가 계속해서 큐에 들어오게 된다면,
우선순위가 낮은 프로세스들이 영원히 CPU를 사용하지 못하는 현상이다.
그래서 "aging"이라는 기법을 추가하면 된다.
너무 오래 큐에서 기다린 프로세스들에게 나이를 들게 하여서,
일정 나이에 도달하면 프로세스의 우선순위를 높여주는 것이다.
Multilevel Queue
멀티레벨 큐도 개념 자체는 굉장히 단순하다.
그냥 같은 특성의 프로세스끼리 같은 큐로 들어갈 수 있도록 큐를 여러개 두는 것이다.
💬 반드시 우선순위대로 큐를 나눌 필요는 없다.
단지 우선순위대로 나누는 것이 일반적이고 유리하다.
큐의 특성이라고 하면은 개발자 나름대로 정할 수 있겠지만,
대표적인 방식은 foreground와 background 프로세스끼리 나누는 것이다.
foreground는 interative한 프로세스이기 때문에,
우선순위를 높여서 사용자에 대한 반응성을 높일 필요가 있기 때문이다.
여기서 끝내는 것이 아니라, 큐 간에도 우선순위를 둘 수가 있다.
foreground 프로세스에게 8의 타임 퀀텀을 주고,
background에는 2의 타임 퀀텀을 주게 된다면,
CPU의 80%는 foreground 프로세스가 가져가게 된다.
Multilevel Feedback Queue
멀티레벨 큐는 정의상 프로세스가 다른 큐로 이동할 방법이 없다.
그런데 만약 CPU 버스트가 심한 프로세스가 우선순위가 높거나,
CPU 사용시간도 많지 않은데 우선순위가 너무 낮다보면,
전체적으로 봤을 때 효율적이지 못할 수가 있다.
그래서 특정 조건에 따라서 프로세스가 다른 큐로 이동할 수 있게 해주는 것이다!
💡 The definition of a multilevel feedback queue scheduler makes it the most general CPU-scheduling algorithm.
멀티레벨 피드백 큐가 가장 일반적인 CPU 스케줄링 알고리즘이다.
사실 그 조건이라는 것이, 완전히 개발자의 선택에 달려있기도 하고,
큐마다 알고리즘을 다 다르게 할 수도 있는 등 자유도가 굉장히 높다.
이렇게 설정이 자유롭게 가능하다는 특성이 실용성을 많이 높여주게 되었다.
3. 멀티프로세서
이전 챕터에서는 유저쓰레드와 커널쓰레드에 대해서 알아보았다.
그리고 현대의 OS는 프로세스가 아닌 쓰레드를 스케줄링한다.
유저쓰레드가 CPU에서 작동하기 위해서는 커널쓰레드에 연결되어야 한다.
단, 그 과정에서 간접적으로 연결될 수도 있다.
(유저쓰레드가 커널쓰레드에 직접적으로 연결된 것이 아닌, LWP에 매핑되는 것)
📌 본 글은 책에서 직접 인용한 내용이 아닙니다.
"The threads library uses underlying threads of control called lightweight processes that are supported by the kernel. You can think of an LWP as a virtual CPU that executes code or system calls."
LWP는 커널에서 지원하는 쓰레드이다. 가상의 CPU라고 볼 수도 있다.
출처: 오라클 공식 문서
경쟁 범위 (Contention Scope)
우선 쓰레드의 경쟁범위부터 알고 넘어가도록 하자.
유저쓰레드는 기본적으로 커널은 전혀 관여하지 않는다.
애초에 유저쓰레드가 존재하는지 조차도 알지 못한다!
그래서 유저쓰레드의 경우 쓰레드 라이브러리가 관리하게 되는데,
이 관리 방식을 Process-Contetion Scope(PCS)라고 한다.
(물론 한 프로세스 내의 쓰레드를 관리하는 경우이다)
반대로 커널쓰레드는 커널이 관리를 하게 되고,
이 관리 방식을 System-Contention Scope(SCS)라고 한다.
멀티프로세서 스케줄링 개념
프로세서가 여러개일때 각 프로세서의 역할을 나누는 것이 2종류가 있다.
하나는, 하나의 프로세서가 마스터 서버로서 관리자 역할을 하는 것이고,
나머지 모든 프로세서들이 유저 코드를 실행하는 것이다.
이러한 방식을 "Asymetric Multiprocessing"이라고 하는데,
마스터 서버가 bottleneck이 될 수 있다는 점이 큰 결점이다.
💡 The standard approach for supporting multiprocessors is symmetric multiprocessing (SMP), where each processor is self-scheduling.
모든 프로세서가 각자만의 스케줄링을 하는 방식이 표준이 되었다.
이 방식의 이름은 SMP(Symmetric Multiprocessing)라고 한다.
💬 사실상 모든 OS가 이런 SMP 방식을 선호한다.
SMP를 구현하는 방식이 다시 2가지로 나뉘게 된다.
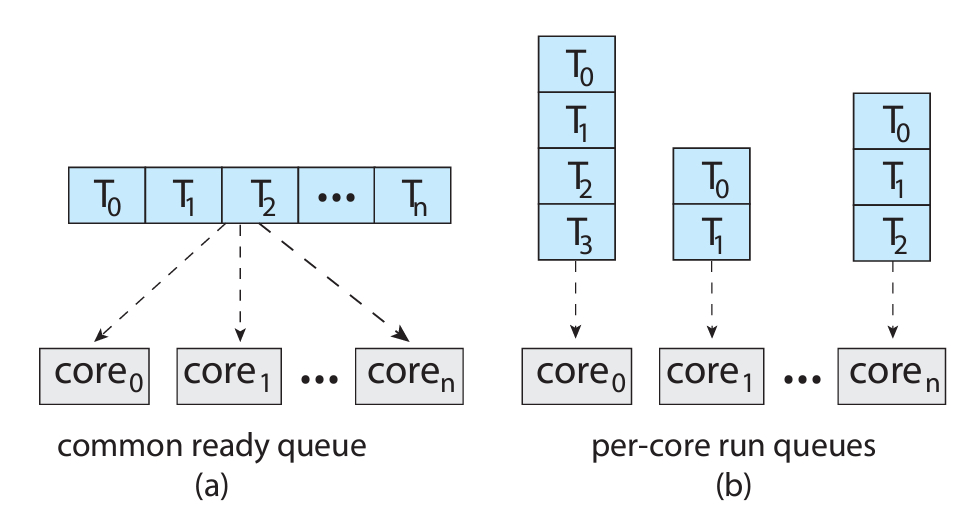
(a)는 여러 코어가 하나의 공용 큐를 사용하는 방식이다.
이 방식은 race condition (경쟁상태)가 발생할 수 있다는 단점이 있다.
(b)는 각 코어가 독자적인 큐를 가지고 있는 방식이다.
캐시 사용에 있어서 장점을 갖게 되지만, 로드 밸런싱에 문제가 생길 수 있다.
경쟁 상태는 해결하기가 쉽지 않은 반면, 로드 밸런싱은 따로 해주면 되기 때문에,
(b)와 같은 방식이 주로 사용되게 되었다.
멀티코어 프로세서
컴퓨터 기술이 발전하면서, core의 연산 속도가 정말 빨라졌다.
그에 반해, 메모리 접근 속도는 연산 속도에 비하면 너무 느리다.
이러한 속도의 차이로 인해 "memory stall"이라는 현상이 발생했다.
연산을 하다가도, 메모리의 data 접근을 위해 기다리는 시간이 길어지는 현상이다.
일단 아래의 그림을 보고, thread1만 있는 경우를 상상해보자.
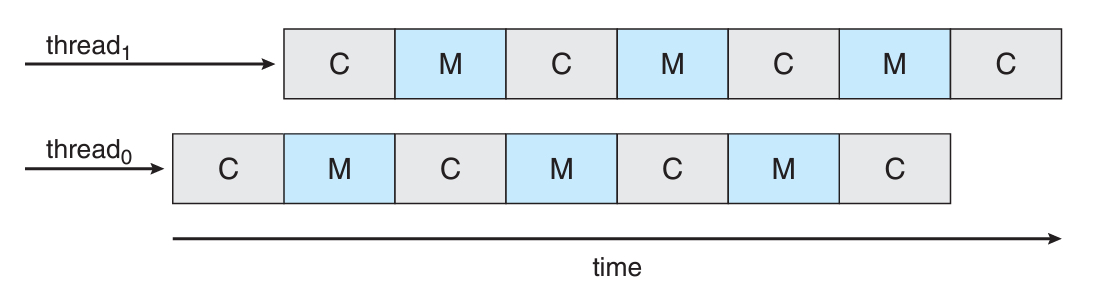
실제로 core가 일하고 있는 시간은 반밖에 없었을 것이다.
그래서 모든 코어에 쓰레드를 최소 2개씩 달게 되면서,
한 쓰레드가 data를 기다리면 다른 쓰레드가 그때 core를 차지하는 것이다.
이렇게 하면 최대한 연산 장치가 노는 일을 방지할 수 있을 것이다.
이쯤에서 core, thread, cpu, processor 등 용어가 너무 많아 헷갈릴 수 있다.
그래서 아래 그림을 보고 한번 정리하고 넘어가도록 하자.
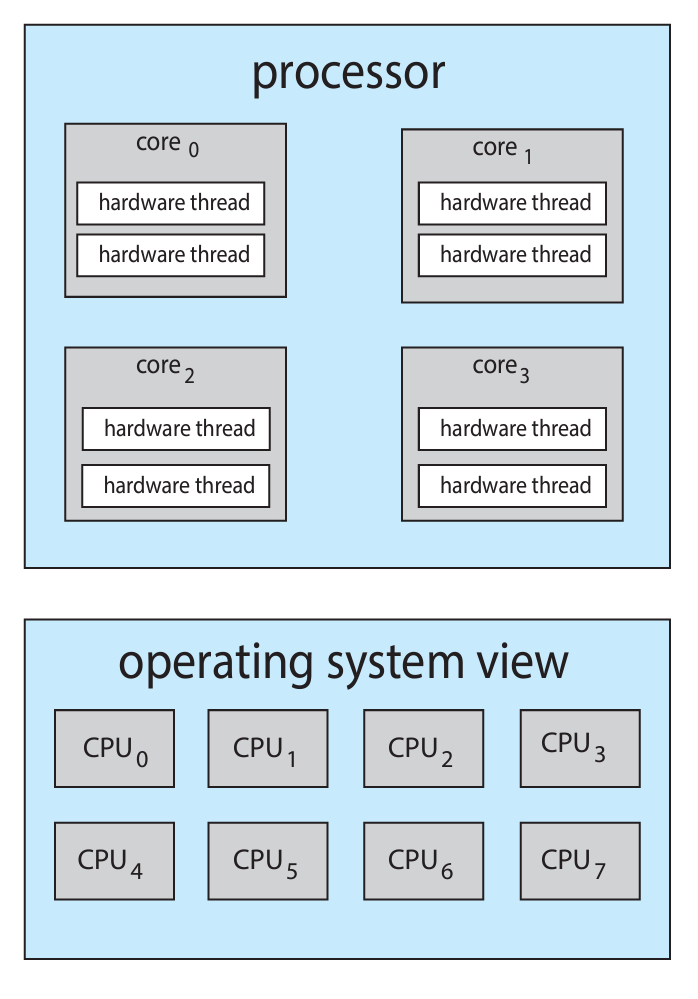
그나마 현대의 컴퓨터와 비슷한 그림이라고 볼 수 있는데,
하나의 프로세서 안에 여러 개의 코어가 있고,
각 코어가 방금 말한 것 처럼 2개씩 쓰레드를 가지고 있다.
이 모든 것들이 결국 OS 입장에서는 8개의 CPU로 보인다!
core나 processor와 관계없이, 실제로 "연산"을 하는 것은 결국 쓰레드니까.
🔍 그럼 방금의 2-쓰레드 끼리는 어떻게 스케줄링 될까?
이 부분은 컴퓨터 하드웨어의 "파이프라이닝"에 대한 이해가 필요하다.
"Coarse-grained"와 "Fine-grained" 방식이 있으니 검색해보자.
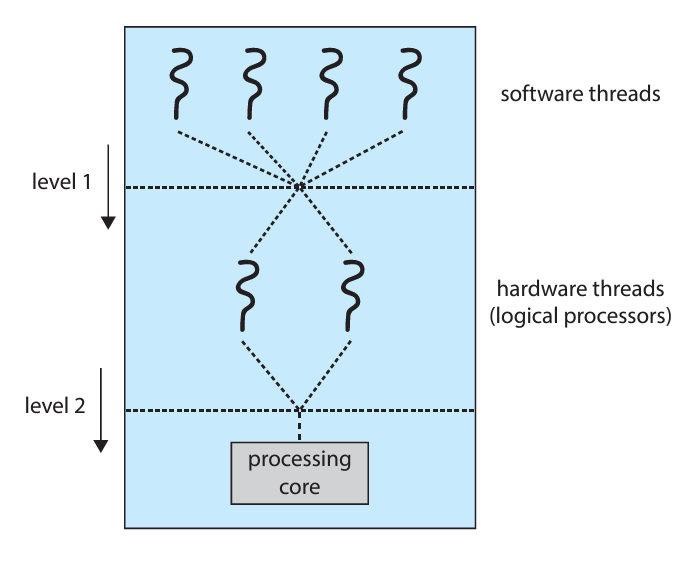
💡 Consequently, a multithreaded, multicore processor actually requires two different levels of scheduling.
멀티코어 & 멀티쓰레딩 하드웨어에서는 2단계의 스케줄링이 필요하다.
첫번째 단계는, 어떤 소프트웨어 쓰레드가 하드웨어 쓰레드에 연결될 것인지를 OS가 결정하는 것인데, 여태 봤던 알고리즘들이 여기에서 사용된다.
두번째 단계는, 각 코어가 어떤 쓰레드를 실행할 것인지를 결정하는 것이다.
여기도 여러개의 방식이 있지만, 대표적으로는 Round-Robin이 있다.
(자세히 알아보려면 Intel Itanium 방식을 검색해보자.)
정리하자면, 전체적인 스케줄링의 흐름은 아래의 그림과 같다.
로드밸런싱
앞서 SMP에 대해서 얘기했을 때, 로드밸런싱을 하면 된다고 했었다.
공용 큐를 가지는 방식에 있어서는 로드밸런싱이 필요가 없겠지만,
보통은 각 코어가 본인만의 큐를 갖고 있기 때문에 로드밸런싱이 필요하다.
💡 There are two general approaches to load balancing: push migration and pull migration.
로드 밸런싱은 push 이동과 pull 이동방식으로 나뉜다.
Push 방식은 말 그대로 본인의 일이 너무 많을 때 밀어내는 방식이다.
주기적으로 본인의 큐 상태를 확인하면서, 너무 많다고 판단하는 경우에
다른 코어들의 큐를 보면서 가장 일이 적은 큐에 일을 나눠주는 것이다.
Pull 방식은 본인의 일이 없는 경우에 다른 코어의 일을 뺏어오는 것이다.
다른 코어들을 보면서 바쁜 코어 하나를 골라서 일들을 훔쳐와서 실행한다.
프로세서 선호 (Affinity)
쓰레드가 특정 프로세서 위에서 열심히 일을 했다고 치자.
그렇다면 캐시가 그 쓰레드가 사용하는 자원들로 채워져있을 것이다.
그리고 그 쓰레드가 다시 올라왔을 때 필요한 자원들이 남아 있는 경우도 있을텐데,
이렇게 쓰레드의 재방문시에 활용가치가 있는 상태를 Warm Cache라고 한다.
그리고 모든 쓰레드는 warm cache를 원할테니,
본인이 일했던 프로세서에서 다시 일하는 것을 선호하게 된다.
💡 This is known as processor affinity - that is, a process has an affinity for the processor on which it is currently running.
이 개념을 프로세서 선호(또는 프로세서 바인딩)라고 한다.
프로세스는 본인이 동작한 프로세서에 대한 선호도를 가지게 된다.
앞서 언급했던 공용 큐의 구조로 되어있다면,
프로세스는 랜덤한 코어로 가서 일하게 될테니 캐시를 다시 사용한다는 보장이 없다.
대신, 코어마다 개인 큐를 가지는 경우에는 바인딩을 해버리면 된다.
프로세스가 특정 코어에서 일했다면, 그 코어의 큐로 다시 들어가면 되는 것.
하지만 그 바인딩도 억지로 할 수는 없는 노릇이다.
그래서 바인딩의 강도에 따라 2가지 방식으로 다시 나뉜다.
Soft binding을 하게 되면, 기본적으로 프로세스의 선호도를 인정해주지만,
로드 밸런싱이 발생할 경우 제재 없이 다른 프로세서로 보내줘야 한다.
Hard binding은 프로세스마다 선호하는 프로세서의 subset을 갖는다.
직접 명시한 프로세서들 안에서만 이동이 일어나게 제한하는 것이다.
마지막으로 프로세스의 선호에 미치는 요소를 한가지 더 확인해보자.
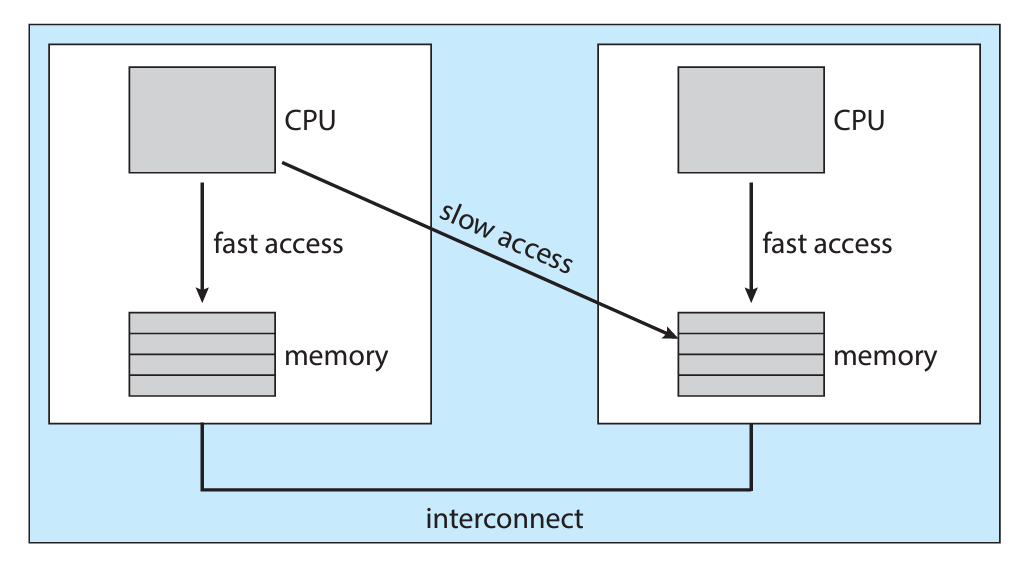
위 그림은 NUMA 아키텍처의 간단한 그림이다.
🔍 NUMA란?
NUMA는 Non-Uniform Memory Access의 줄임말이다.
코어마다 독자적인 메모리 공간을 가지고 있는 구조를 뜻한다.
위 아키텍처의 특징은, CPU마다 작은 메모리를 가지고 있어서 빠르게 접근이 가능하다.
단, 다른 CPU에 붙어있는 메모리로 가는 경우에는 보다 오래걸린다.
다시 돌아와서, 위의 구조에서 프로세스가 특정 CPU에서 일했다면,
프로세스의 선호도는 당연 해당 CPU겠지만, 다시 못돌아가는 상황이 생길 수 있다.
그렇게 되면 그나마 근처에 있는 다른 CPU들이 높은 선호도를 가지는 것이다.
그래도 완전 다른 CPU라 slow access마저 불가능한것 보다는,
적어도 slow access라도 메인메모리까지는 안가는데 더 빠를테니까.
💡 Interestingly, load balancing often counteracts the benefits of processor affinity.
흥미롭게도, 로드밸런싱과 프로세서 선호는 서로 달갑지 않은 특성이다.
로드 밸런싱은 CPU 가동률을 올리고 싶은 뿐이고,
프로세서 선호는 캐시 메모리를 극대화 하고자 할 뿐이다.
적당한 융합이 되었을 때에는 멀티코어 환경을 잘 활용할 수 있을 것이다.
🎯 마치며
프로세스와 쓰레드에 대한 개념이 드디어 다 잡힌 것 같다.
여기까지만 배워도 프로세스와 쓰레드 관련해서는 많이 알게 된 것 같다.
출처
Abraham Silberschatz, 『Operating System Concepts Ed.10』
