📖 본 글은 모든 내용을 "Operating System Concepts Ed.10"에서 인용합니다.
👋 가상 메모리는 무엇일까?
💡 Virtual memory is a technique that allows the execution of processes that are not completely in memory.
가상메모리는 메모리에 다 올라오지 않은 프로세스를 실행시키는 기술이다.
💡 One major advantage of this scheme is that programs can be larger than physical memory. Further, virtual memory abstracts main memory into an extremely large, uniform array of storage, separating logical memory as viewed by the programmer from physical memory.
주요 이점은 프로그램의 크기가 메모리보다 커질 수 있다는 것이다.
또한, 가상메모리는 메인메모리를 추상화하여 하나의 거대한 배열로 가지고 있다.
이로써 개발자는 물리주소와 관계없이 논리주소만 인지하면서 작업할 수 있다.
우선 가상메모리가 등장하게 된 배경에 대해서 알아보자.
과연 프로그램이 메모리에 올라간다고 했을 때, 모든 데이터가 사용될까?
그럴 수도 있겠지만 현실적으로는 그렇지 않다.
100x100 크기로 선언된 배열이 있다고 해서 전부 사용되는 것이 아니기도 하고,
오류 처리 코드도 사실 오류가 발생하지 않는다면 호출될 일이 아예 없을 것이다.
만약에라도 위의 것들이 다 사용된다고 하더라도, 적어도 동시에 사용되진 않을 것이다.
이처럼 메모리에 당장 올라올 필요가 없는 영역은 굳이 메모리에 올라올 필요가 없다!
그러면 구체적으로 가상메모리가 어떠한 이점들을 가져다 줄까?
- 프로그램이 더이상 메모리의 크기에 신경쓰지 않아도 된다.
- 보다 많은 프로세스가 동시에 실행되어 CPU 사용률이 증가한다.
- I/O가 적게 발생하여 각 프로그램이 빠르게 실행될 수 있다.
이제 가상메모리가 어떻게 생겼는지 아래 그림으로 보자.
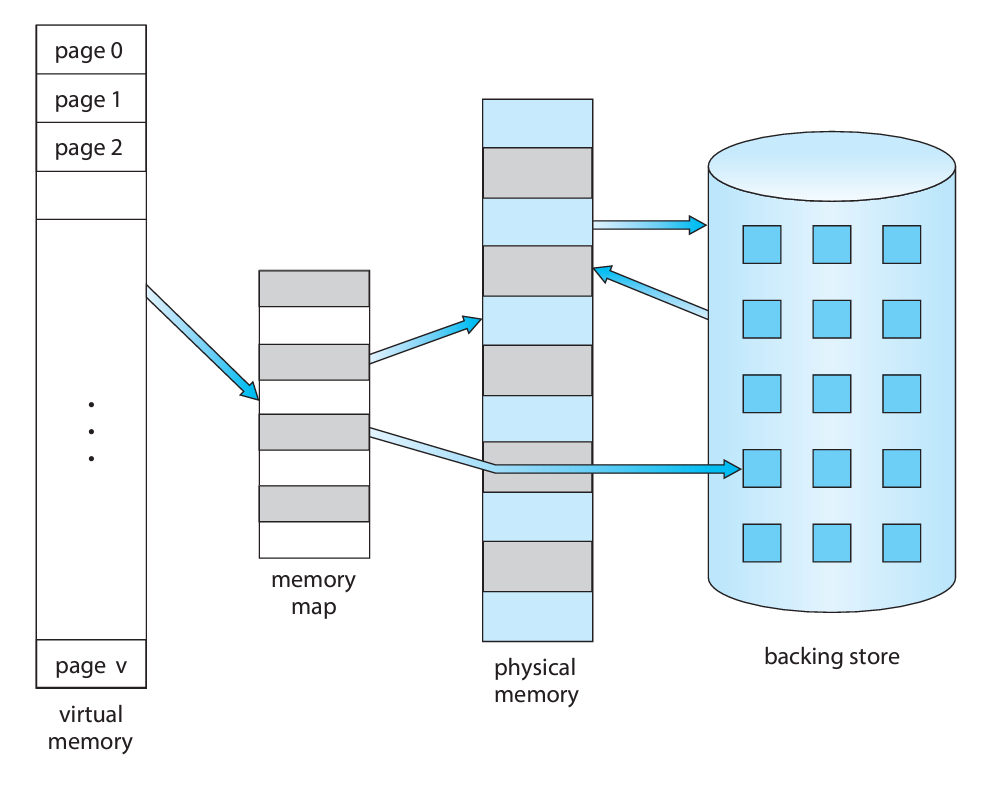
총 4개의 공간 중 오른쪽 2개는 우리가 여태 공부해왔던 메인메모리와 백업저장소이다.
가장 왼쪽이 가상메모리라고 불리는 실존하지 않는 주소체계이다.
그리고 가상메모리와 메인메모리 간의 주소를 매핑해주는 메모리맵이 추가로 필요하다.
구체적인 동작 과정은 이 챕터에서 전반적으로 다루게 될 예정이다.
이 챕터에서는 가상주소와 물리주소를 계속 왔다갔다 해야 해서 헷갈릴 일이 많으니,
아래 그림을 복습하면서 페이지 공유 기법에 대해서 먼저 알아보자.
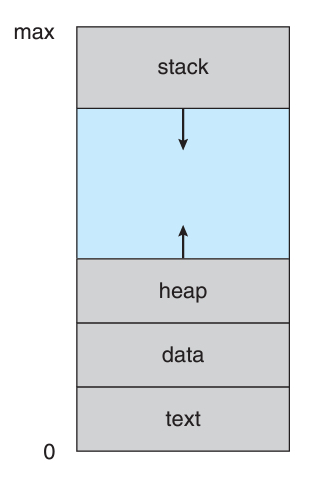
우리는 원래 위의 그림을 "프로그램이 메모리를 어떻게 사용하는지"로 공부했다.
그런데 가상메모리를 사용해도 그 사실에는 전혀 변함이 없다.
프로그램 입장에서는 OS가 무슨 짓을 해도 본인의 메모리를 위의 그림처럼 인식한다.
💡 The virtual address space of a process refers to the logical (or virtual) view of how a process is stored in memory.
이처럼 프로세스가 인식하는 메모리 공간을 "가상 주소 공간"이라고 한다.
가상주소공간에서, 스택과 힙이 서로를 향해 덩치를 키우거나 줄이기 마련인데,
가상메모리를 사용하면 이 사이의 공간을 특별하게 사용할 수 있다.
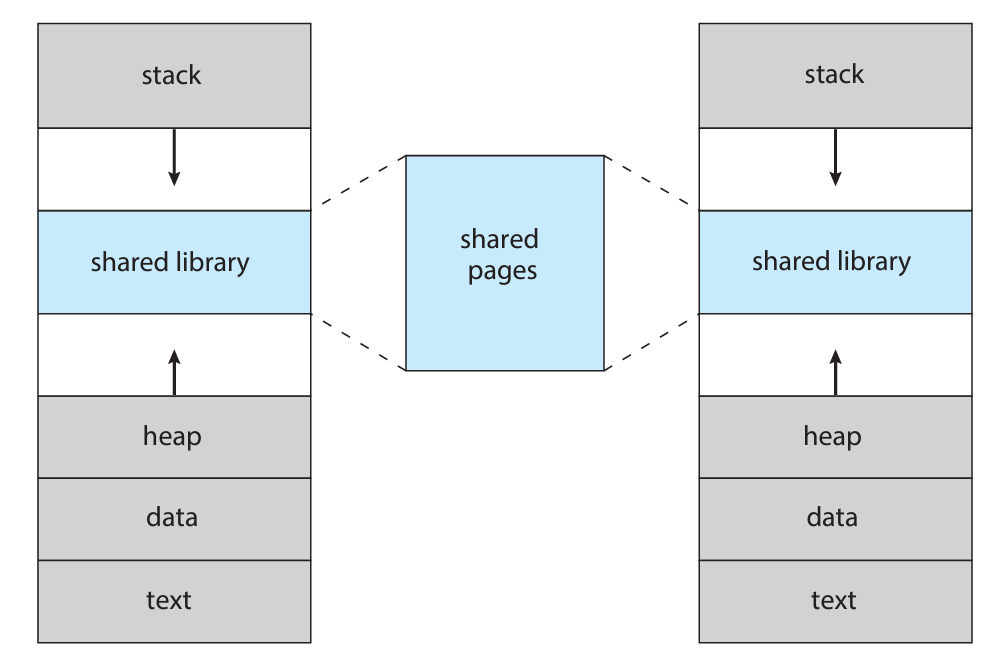
사이 공간을 "sparse 주소 공간"라고 하는데, 여기에 공유 라이브러리를 활용할 수 있다.
프로세스 입장에서는 해당 공유 라이브러리를 자신만 가지고 있다고 생각하겠지만,
사실은 여러 프로세스가 동시에 한 주소로 접근하여 사용하고 있게 만들 수 있다!
특히, standard C 라이브러리는 굉장히 많은 프로세스가 공유를 하게 될것이다.
1. 요구 페이징 (Demand Paging)
이제 조금 구체적으로 어떻게 가상메모리가 쓰이는지 알아보자.
우선 하나의 프로그램을 실행시키려면 어떻게 해야 할까?
당연히 컴파일→링킹→로딩을 통해 메모리로 올려서 프로세스가 되게 하면 된다.
그런데 굳이 프로그램 전체를 올릴 필요가 있을까?
💡 An alternative strategy is to load pages only as they are needed. This technique is known as demand paging and is commonly used in virtual memory systems.
또 다른 방법은 당장 필요한 페이지만을 메모리에 올리는 방식이다.
이는 "요구 페이징"으로 알려져있고, 가상메모리 시스템에서 흔히 사용된다.
필요한 페이지"만" 올리기로 했으니, 필요없는 페이지는 평생 올라오지 못할수도 있다.
동작 과정
가장 먼저 필요한 정보는 특정 페이지가 현재 메모리에 올라와있는지이다.
이는 이전 챕터에서 배운 페이지 스와핑 방식을 사용하면 되지만, 살짝 다른 점이 있다.
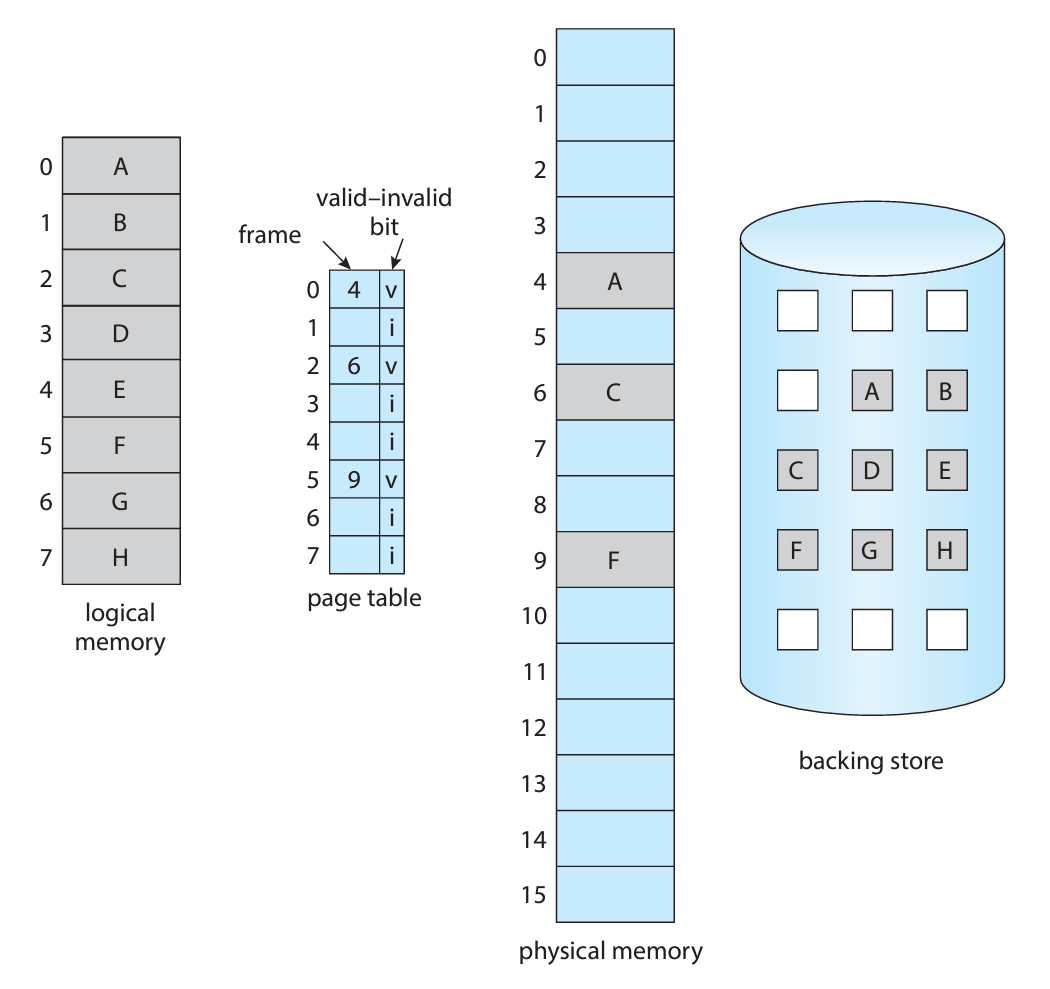
우선 위의 그림이 좋은 예시가 될 수 있는데, 프레임 번호 옆에 valid bit가 있다.
만약 valid라고 체크되어 있는 경우, 페이지가 legal 하면서도 메모리에 존재하는 상태이다.
💬 legal은 페이지 테이블 내의 해당 페이지가 사용되고 있음을 나타낸다.
여기서 그냥 페이징 기법을 사용하는 점과 다른 부분이 헷갈릴 수 있는데,
페이징은 새로운 프로그램을 올릴 때, 전체를 올리되 다른 프로세스의 페이지를 내리는 것이고,
가상메모리는 애초에 일부의 페이지만 올리기 때문에 어떤 페이지가 올라가있는지 모른다!
그러면 valid 비트가 꺼져있는 경우는 invalid한 상태라고 할 수 있는데,
페이지가 legal하지 않거나, 해당 페이지가 메모리에 올라가지 않은 상태라는 뜻이다.
위의 그림을 보면 모든 페이지가 백업저장소에는 (당연히) 존재하고 있고,
그 중 현재 사용 중인 페이지인 A, C, F만 올라가 있는 상황이다.
A, C, F만 legal한 동시에 메모리에 올라와있기 때문에 valid 비트가 켜져있다.
반면에 다른 페이지는 데이터가 존재하는 legal 페이지이지만,
단지 메모리에 올라가 있는 상태가 아니기 때문에 invalid한 상태라고 보는 것이다.
정리하자면, 가상메모리의 포인트는 페이지가 현재 메모리에 올라와있는지를 체크하는 것이다.
여기서 계속 상기시켜야할 부분이, 프로그램 입장에서는 본인의 주소공간 전체가 메모리에 있다고 생각하는데,
D는 현재 invalid인데 D 내의 데이터가 갑자기 필요해서 접근하려고 하면 어떻게 될까?
💡 Access to a page marked invalid causes a page fault.
invalid 페이지에 접근하면 페이지 폴트를 발생시킨다.
폴트 자체가 예상되지 않은 상황이라는 뜻이기 때문에 상황을 해결해야만 한다.
페이지 폴트를 해결하는 방식은 복잡해보이지만 아래 그림을 이해하면 생각보다 단순하다.
(진짜 생각보다 어렵지 않으니 꼭 화살표를 따라가보는 것을 추천한다!)
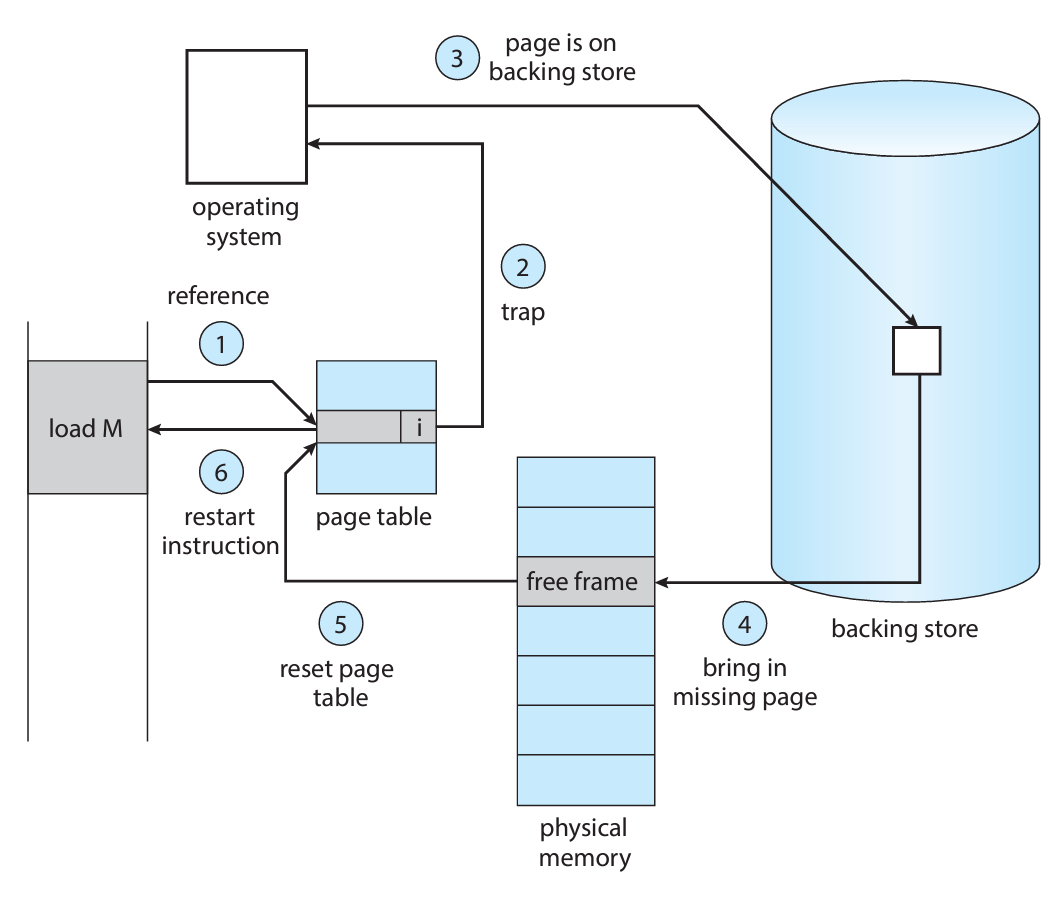
- 우선 내부 테이블(보통 PCB 안)에 접근하여 레퍼런스(메모리주소)를 체크해서 해당 접근이 유효한 메모리 접근이었는지 확인한다.
- 만약 접근 자체가 유효하지 않다면 프로세스를 종료시킨다. 접근은 유효하지만 단순히 메모리에 올라오지 않은 상태라면 page in을 진행해야 한다.
- 페이지를 할당하기 위한 빈 프레임을 찾는다. (ex. free-frame list)
- 2차 저장장치를 스케줄링하여 페이지를 읽어서 새 프레임에 써준다.
- 아까 레퍼런스를 확인한 그 내부 테이블에 돌아가서 정보를 (valid로)업데이트 해준다.
- 트랩이 걸렸던 그 명령어를 재실행한다.
이렇게 하면 해당 페이지가 마치 처음부터 메모리에 있었던 것 처럼 연기할 수 있다.
조금 극한 상황으로 끌고 가서, 프로세스를 실행할 때 아무런 페이지도 올리지 않았다면?
명령어를 실행할 때마다 페이지 폴트가 계속해서 발생할게 뻔하다.
대신, 페이지폴트가 발생할 때마다 해당 페이지는 실제로 메모리에 올라오게 된다.
이렇게 처음부터 모든 페이지가 올라와있다고 사기를 치는게 요구페이징이다.
💬 이렇게 아무 페이지도 올리지 않고 실행하는 것을 "순수 요구 페이징"이라고 한다.
그런데 이론적으로는 하나의 명령어만으로 여러 페이지를 접근할 수도 있다.
그러면 동시에 여러개의 페이지가 폴트가 나서 성능에 악영향을 줄 수도 있는데,
다행히도 실제로는 "참조 지역성" 덕분에 잘 발생하지 않는다.
💬 "locality of reference"라는 이름의 참조 지역성은 스레싱 파트에서 다룰 것이다.
당장은 참조 지역성 덕분에 요구 페이징 기법이 효율적으로 동작한다는 사실이 중요하다.
Free-Frame List
위애서 페이지 폴트 해결하는 단계에서 free-frame list라는 단어를 봤을텐데,
이는 빈 프레임을 빠르게 찾기 위해 OS가 들고 있는 자료구조이다.
💡 Operating systems typically allocate free frames using a technique known as zero-fill-on-demand. Zero-fill-on-demand frames are "zeroed-out" before being allocated, thus erasing their previous contents.
OS는 일반적으로 빈 프레임을 할당할 때 "zero-fill-on-demand" 기법을 사용한다.
이는 프레임을 할당하기 전, 해당 프레임 내의 모든 내용을 0으로 밀어버리는 것이다.
어떻게 보면 당연하지만, 만약 0으로 밀지 않았을 때를 생각하면 굉장히 끔찍하다.
그리고 빈 프레임들의 목록을 가지고 있는 것이기 때문에,
언젠가는 빌 수도 있는 거고, 때로는 특정 threshold 아래로 떨어질 수도 있다.
이 경우에 페이지 재배치가 일어날 수 있는데, 아래 챕터에서 다룰 예정이다.
💬 요구페이징에 대한 성능측정도 구체적으로는 할 얘기가 많지만, 넘어가겠다.
2. COW (Copy-on-Write)
상기시키자면, fork()는 부모 프로세스의 모든 페이지를 복사해서 새로운 프로세스를 생성한다.
하지만 요구페이징을 사용하게 된다면 굳이 모든 페이지를 복사해야하나 하는 의문점이 생긴다.
한가지 짚고 넘어가야 할 점이, 자식 프로세스는 보통 생성과 동시에 exec()을 실행하는데,
그렇다면 복사를 미리 하지 말고 실행 시에 필요한 페이지를 그때그때 복사하면 어떨까?
💡 Instead, we can use a technique known as a copy-on-write, which works by allowing the parent and child processes initially to share the same pages.
copy-on-write는 부모와 자식 프로세스가 처음에 같은 페이지를 공유하게 하는 기법이다.
둘 중 어떤 프로세스가 하나의 페이지에 쓰기 작업 시에 페이지의 복사본이 생성된다.
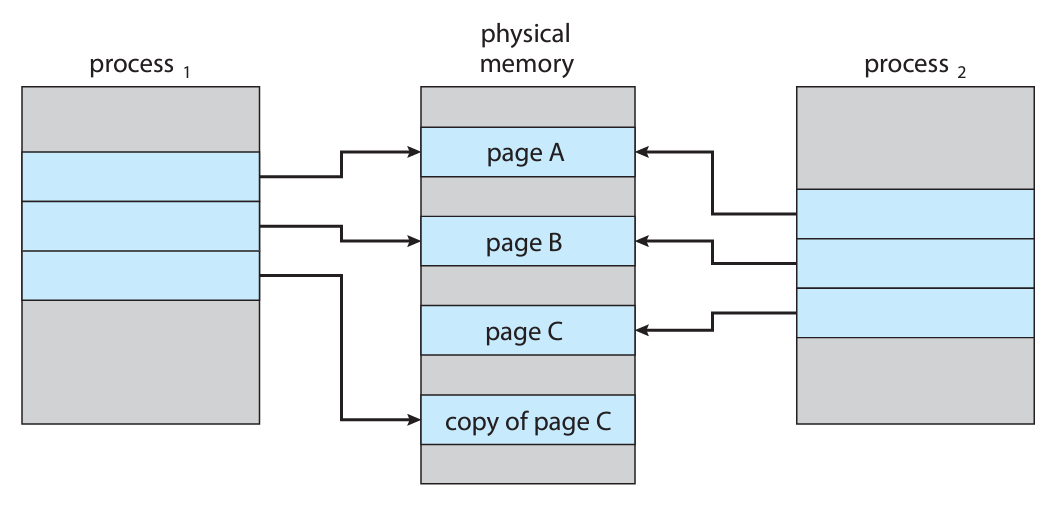
위 그림을 보면, 프로세스 1이 page C에 쓰기 작업을 했을 때 벌어지는 일이다.
원래는 A, B, C 3개의 페이지만 있다가, C에 쓰기를 했으니 C만 새로 복사해서 페이지를 만든다.
💬 실제로 이 기술은 Windows, Linux, macOS 등의 운영체제에서 사용된다.
별개로, Linux 계열의 운영체제 (Linux, macOS 등)은 fork()의 변형 함수들도 제공한다.
그 중에서도 vfork() (virtual memory fork)는 쓰기가 없는 프로세스에게 효율적이다.
vfork()는 메모리 복사도 안하고, COW도 지원하지 않는다.
대신, 호출 시에 부모 프로세스를 정지시키고 자식 프로세스가 실행된다.
자식 프로세스는 부모 프로세스의 주소 공간을 그대로 가져다 쓴다.
그래서 사용 시에 조심해야 하지만, 아무런 복사가 없다는 점에서 속도가 굉장히 빠르다.
3. 페이지 교체
멀티프로그래밍 차수 (degree of multiprogramming)가 높아지다보면,
메모리는 초과 할당 (over-allocating)을 하게 되는 꼴이다.
예를 들어, 10페이지짜리 프로세스가 총 6개가 메모리에 올라갔는데,
메모리의 총 프레임이 40개라면 전부 올라가있는건 불가능하다.
그런데 애초에 모든 페이지를 동시에 올리지 않으려고 가상메모리를 사용하는 것이 아닌가?
문제는 메모리를 프로세스만 사용하는 것이 아니라는 점이다.
시스템 I/O를 위한 버퍼도 있어야 하고, 각종 커널 코드도 올라가 있어야 한다.
또한, 갑자기 여러 프로세스가 여러 페이지에 걸친 데이터를 접근하려고 한다면?
메모리 공간은 턱없이 부족하다고 느껴질 수 밖에 없다.
그러면 갑자기 메모리가 미어터지는 상황에서는 프로세스를 종료하면 되지 않을까?
💡 Users should not be aware that their processes are running on a paged system - paging should be logically transparent to the users.
사용자는 프로세스가 페이지 시스템으로 돌아간다는 사실을 절대 알면 안된다!
1장에서 다룬 내용이지만, OS는 끝까지 유저의 편의성을 위해 일해야 한다.
그렇기 때문에 페이지와 다른 페이지를 바꿔치기 하는 "페이지 교체" 방식이 생기게 되었다.
동작 과정
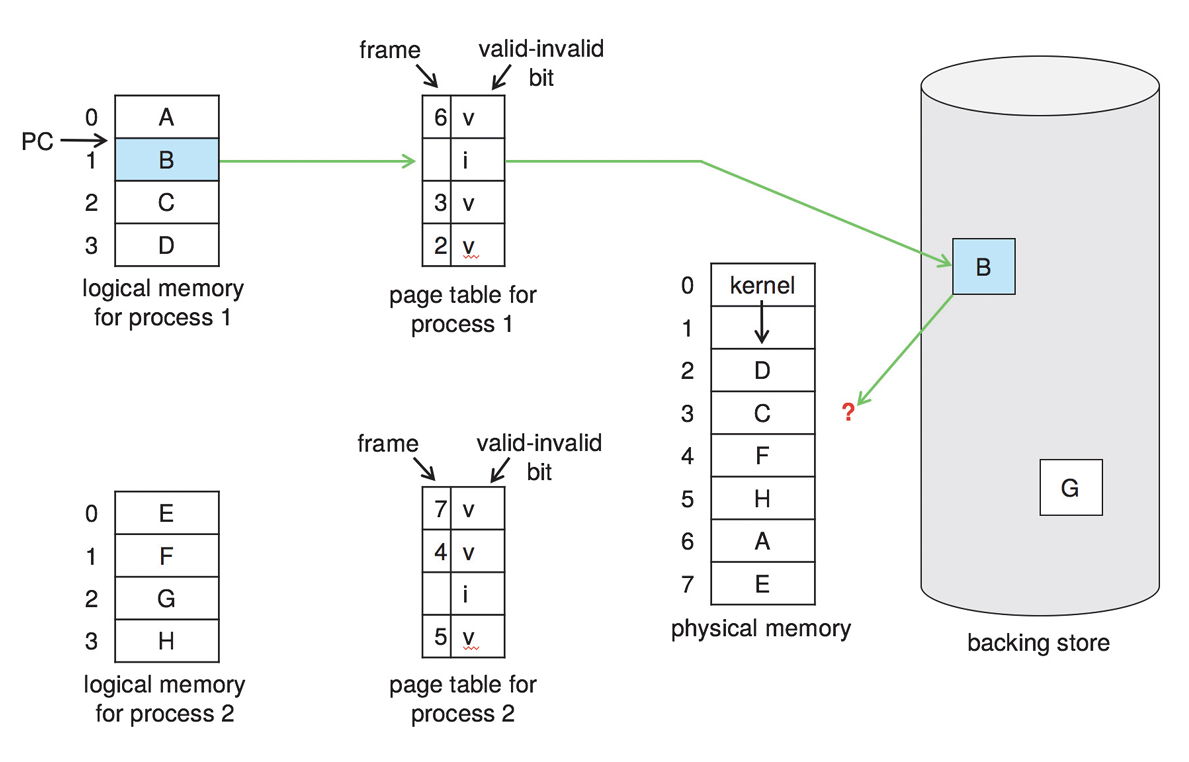
위의 그림은 프로세스 1이 실행중에 PC가 페이지 B에 도달했을 때의 경우이다.
그럼 이제 초록색 화살표를 천천히 따라가보자.
첫 화살표를 따라가면 프로세스 1은 페이지 B가 invalid하다는 사실을 알게된다.
그러면 즉시 페이지 폴트가 발생하게 되고, 본격적인 페이지 교체가 시작된다.
다음 화살표를 따라가면, 백업 저장소로 가서 B의 위치를 찾는다.
그러면 이제 실제 메모리 주소로 가서 비어있는 프레임을 찾는다.
그러나 위의 그림에서는 현재 비어있는 프레임이 하나도 없는 상태이다!
이제 그림은 그만 보고, 앞으로 어떻게 해야 할지 생각해보자.
사실 발생할 수 있는 상황은 2개 밖에 없다.
a) 만약 빈 프레임을 찾았다면 그냥 거기에다 올리면 된다.
b) 빈 프레임이 아예 없다면 "페이지 교체 알고리즘"을 통해 희생 프레임을 찾는다.
이후에는 희생 프레임 내의 페이지를 백업 저장소에 써주고, 필요한 페이지를 그 프레임에 써주면 된다.
마지막으로 폴트가 발생한 시점의 코드를 "재실행"해준다.
💬 코드를 실행한다고 안하고 꼭 재실행한다고 쓰는 이유는 "재"실행이 중요하기 때문이다.
OS의 책임은 페이지라는게 존재하지 않는 것처럼 프로세스를 실행시켜야 하기 때문에,
폴트 발생시에 재빨리 페이지를 올려둔 다음에 처음부터 있었던것처럼 행동해야 한다.
만약 재실행이 아니고 다음 명령어부터 실행한다면 페이지를 사용한다는 사실이 들통난다.
여기서 한가지 재밌는 점은, 페이지 하나를 올리기 위해 총 2개가 이동한다는 사실을 알 수 있다.
페이지를 교체하는 것이기 때문에, 하나는 밖으로, 다른 하나는 안으로 이동해야 한다.
사실 2차 저장장치까지 가는 시간이 결코 짧지 않기 때문에, 해결할 필요가 있어보인다.
그래서 modify-bit (또는 dirty-bit)을 사용하면 괜찮은 효율을 챙길 수가 있다.
이 비트는 수정되지 않은 페이지는 굳이 백업할 필요가 없다는 사실을 이용한 것이다.
동작도 간단한게, 메모리에 올라온 페이지가 수정이 됐다면, bit를 켜주기만 하면 된다.
만약 교체 알고리즘에 의해서 bit가 꺼져있다면 백업 저장소에 굳이 다시 써줄 필요가 없다.
마지막으로 페이지 교체 과정의 순서를 정리를 해보자. (폴트 발생시부터)
- 희생 페이지를 결정하고 page out을 한다.
- 해당 페이지의 페이지 테이블에 invalid 비트를 켜준다.
- 요구 페이지를 page in 해준다.
- 해당 페이지의 page table의 정보를 갱신해준다.
앞선 그림에서의 예제에서도 봤듯이, 우리는 희생 페이지를 결정해야 하는데,
이 결정하는 방식은 특정한 페이지 교체 알고리즘에 따른다.
💡 We must solve to major problems to implement demand paging: we must develop a frame-allocation algorithm and a page-replacement algorithm.
요구 페이징을 구현하기 위해서는 크게 2가지의 문제를 해결해야만 한다.
프레임 할당 알고리즘과 페이지 교체 알고리즘이 필요하다.
프레임 할당은 바로 다음 챕터에서 자세히 다룰 예정이다.
그러면 페이지 교체 알고리즘을 본격적으로 알아볼껀데, 한가지 전제를 깔고 가야한다.
앞으로의 모든 예제는 특정한 reference string을 기준으로 확인할 예정이다.
참조 문자열은 쉽게 말해 앞으로 접근하게 될 페이지 번호의 리스트이다.
예를 들어, {1, 0, 5, 3}이라고 한다면, 1→0→5→3 순서로 페이지를 접근할 예정이란 뜻이다.
실제로는 어떤 페이지가 접근될지 모르지만, 어디까지나 알고리즘의 성능 확인을 위해 사용할 뿐이다.
돌아와서, 우리는 메모리가 총 3개의 프레임만을 가지고 있고,
아래의 참조 문자열을 가지고 뒤의 알고리즘을 테스트해보면 된다.
{7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1}
FIFO
FIFO (First-In-First-Out)은 스케줄링의 FCFS와 같다.
💬 스케줄링에서는 CPU를 "사용"하는 순서라서 "served"라는 단어를 사용했지만,
이번에는 말 그대로 메모리에서 나가는 페이지를 선택하는 거라 "out"을 사용한다.
말그래도 페이지가 들어온 순서를 linked-list로 들고 있을건데,
들어온 페이지를 tail에다가 넣고, 희생 페이지는 무조건 head에서 뽑으면 된다.
그러면 참조 문자열에 다라 아래의 그림과 같이 프레임이 바뀌게 될 것이다.
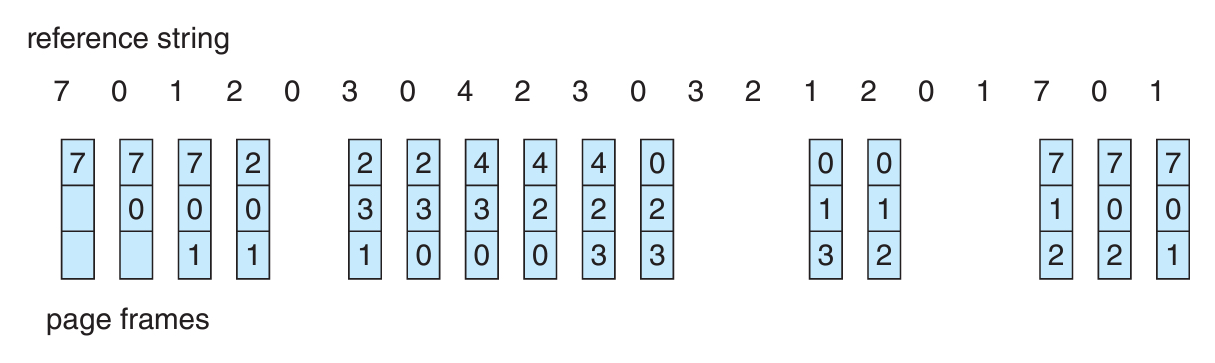
이 알고리즘에서는 총 15번의 페이지 폴트가 발생하게 된다.
사실 FIFO가 단순한 만큼, 아무래도 효율은 뒤에서 볼 알고리즘보다 떨어진다.
벨라디의 이상 현상
그리고 FIFO 알고리즘 관련해서는 한가지 재밌는 특징이 있다.
프레임의 수가 늘어나면 페이지 폴트가 무조건 더 적게 발생할까?
직관적으로는 당연히 프레임 수가 늘어나면 페이지 폴트가 적게 발생할 것 같다.
그러면 N개의 프레임에 대한 새로운 참조 문자열을 하나만 살펴보자.
{1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5}
프레임 개수가 N개 일 때, 페이지 폴트가 각각 몇번 발생하는지 세어보자.
직접 셀 생각이었다면 그만두고 아래 표를 보자
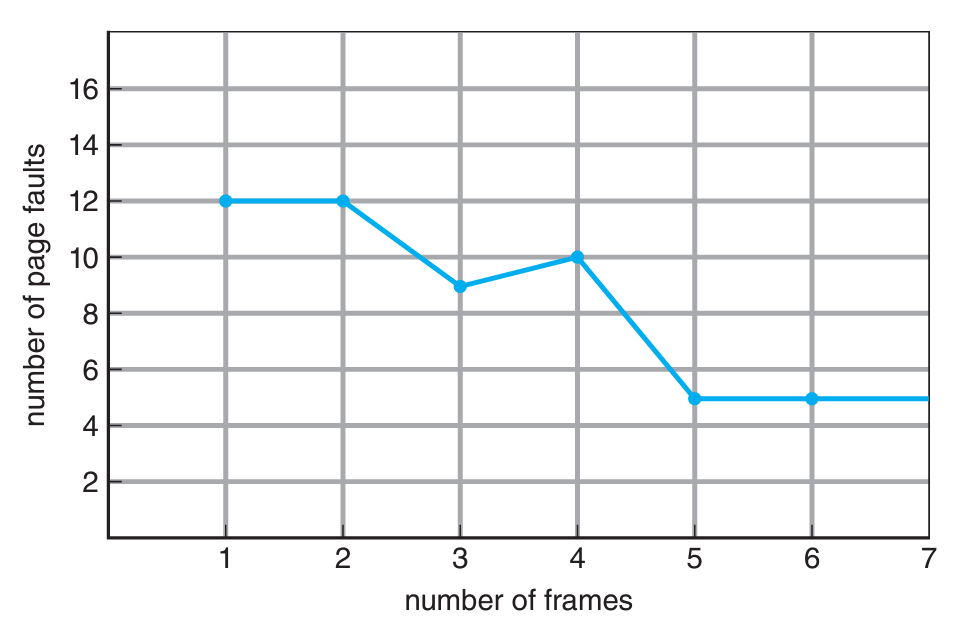
놀랍게도 프레임의 개수가 4개일 때가 3개일 때보다 페이지 폴트가 더 많이 발생했다!
💡 This most unexpected result is known as Belady's anomaly: for some page-replacement algorithms, the page-fault rate may increase as the number of allocated frames increases.
이렇게 예상과 다른 결과를 "벨라디의 이상 현상" (Belday's Anomlay)이라고 부른다.
몇 페이지 교체 알고리즘은 프레임 개수가 늘어남에도 페이지 폴트 횟수가 늘어날 수 있는 현상이다.
Optimal
CPU 스케줄링에서 SRTF가 이론적으로는 완벽하다는 사실을 알 수 있었다.
마찬가지로 페이지 교체에도 Optimal, 즉 "최적"의 알고리즘이 존재한다.
이름부터 optimal인 만큼, 앞서 본 벨라디의 이상현상이 절대로 발생하지 않는다.
알고리즘 자체도 정말 간단한데, 앞으로 제일 오랫동안 안쓰일 페이지를 교체하는 거다.
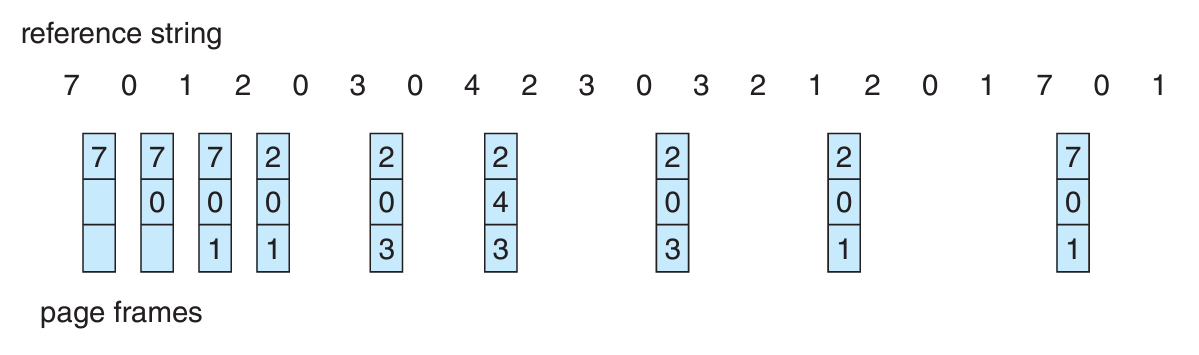
그림대로 진행된다고 쳤을 때, 총 9번의 페이지 폴트가 발생한다.
그리고 실제로 이보다 적게 발생하는 알고리즘은 존재할 수가 없다!
단, 앞서 얘기했듯이 어디까지나 최적의 경우를 보여주는 알고리즘이기 때문에,
실제로는 사용하기가 굉장히 힘들다. (미래를 예측할 수는 없으니)
그럼에도 새로운 알고리즘을 고안했을 때, 비교 대상으로 쓰이기에는 용이하다.
LRU
Optimal 알고리즘이 현실가능성이 없다면, 적어도 비슷하게 알고리즘을 고안해내면 된다.
💡 The key distiction between the FIFO and OPT algorithms is that the FIFO algorithm uses the time when a page was brought into memory, whereas the OPT algorithm uses the time when a page is to be used.
FIFO 알고리즘이 페이지가 메모리로 들어온 직후에 실행되었다면,
OPT 알고리즘은 페이지가 사용되려고 할 때 실행된다는 주요 차이점이 존재한다.
💡 If we use the recent past as an approximation of the near future, then we can replace the page that has not been used for the longest period of time. This approach is the least recently used (LRU) algorithm.
가까운 미래에 대한 예측을 가까운 과거에 기반한다면, 가장 오랫동안 사용되지 않은 페이지를 고른다는 뜻이다.
이를 "Least Recently Used" LRU 알고리즘이라고 한다.
(개인적으로도 LRU가 중요한 접근법이라 생각해서 발췌를 길게 해봤다)
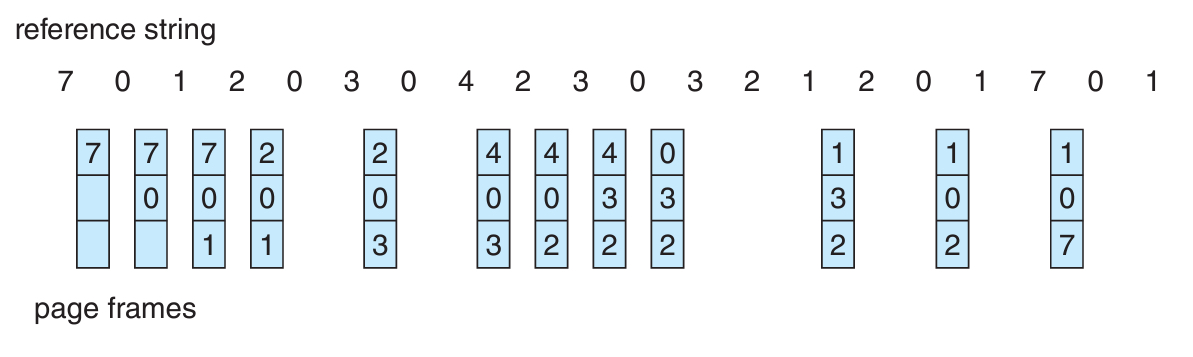
실제로도 위 그림에서 페이지 폴트가 총 12번만 발생한다는 사실을 알 수 있고,
심지어 그 중에서도 첫 5개는 optimal 알고리즘과 같은 시점이다.
LRU는 그만큼 강력하면서도, 벨라디의 이상 현상도 발생하지 않는다!
대신, LRU는 구현을 어떻게 하느냐가 가장 큰 문제다.
FIFO는 순서만 기억하면 되었기에 Queue로 구현 가능하지만,
LRU는 모든 메모리 접근에 대해서 어떤 방식이로든 정보를 남겨야만 한다.
일단 구현 가능한 방법을 생각해보면, 크게 2가지로 나뉠 수 있다.
-
카운터
간단하게 생각해서 CPU 클럭을 이용하면 된다.
매번 메모리에 접근이 발생할 때마다, 해당 프레임에 시간을 적어둔다.
페이지 교체가 필요하면 그 중에서 가장 오래된 시간을 고르면 된다. -
스택
메모리 접근 시마다 해당 프레임 번호를 스택의 위로 올린다.
이렇게 하면 접근이 가장 오래동안 안된 프레임이 가장 아래에 있게 된다.
사실 스택은 임의접근이 안되는 자료구조이기 때문에 양방향 연결 리스트로 구현하게 된다.
하지만 어느 방법을 선택하든간에 오버헤드가 굉장히 크다.
카운터와 스택 모두 커널 코드에서 접근해야 하기에, 매 메모리 접근마다 interrupt가 발생한다.
이에 대한 해결 방안을 알아보기 전에 LRU 알고리즘의 부모 클래스에 대해 알아보자.
스택 알고리즘 클래스
LRU 알고리즘은 "스택 알고리즘"이라고 하는 페이지 교체 알고리즘 클래스에 속한다.
💡 A stack algorithm is an algorithm for which it can be shown that the set of pages in memory for frames is always a subset of the set of pages that would be in memory with frames.
스택 알고리즘은 n개의 프레임에 속하는 페이지들의 집합이 n+1개의 프레임을 사용하는 경우의 부분집합이 된다는 것을 증명할 수 있는 알고리즘이다.
스택이라는 자료구조 자체가 특정한 기준으로 정보가 "최신화" 되어있기 때문에,
가장 최근에 사용된 N개의 페이지가 프레임이 많아져도 그대로 존재할 수 밖에 없다.
LRU-Approximation (근사)
매번 타이머나 스택에 접근하는 대신에, reference bit (참조 비트)를 사용하는 방법이 있다.
참조 비트는 각 페이지 테이블 엔트리에 저장되어 손쉽게 접근할 수 있다.
참조 비트의 크기와 사용 방법에 따라서 다양한 알고리즘이 창출될 수 있다.
Additional-Reference-Bits
하나의 방법은 8-bit 바이트를 사용해서 시간을 측정하는 것이다.
어떤 페이지가 접근되면 가장 왼쪽 비트를 1로 바꿔준다.
그리고 특정 시간 인터벌마다 모든 비트를 오른쪽으로 shift해준다.
예를 들어, 시간 인터벌이 100ms라고 가정하고 어떤 페이지가 접근되었다고 치자.
그러면 초기 값인 00000000이 10000000으로 바뀌게 되고,
그 상태에서 한 인터벌이 지나면 01000000으로 비트가 이동하게 된다.
이렇게 400ms가 더 지났다고 치면 00000100으로 바뀌게 되는 식이다.
그래서 페이지 테이블의 비트열들을 비교할 때 unsigned_int로 취급하여,
가장 수치가 낮은 비트열을 가진 페이지를 교체하면 된다!
다시 예를 들어, 01100010을 가진 페이지와, 10000110을 가진 페이지가 있다고 치면,
2번째 페이지가 가장 최근에 접근되었기 때문에 1이 더 왼쪽에서 등장한다.
그리고 이를 unsigned_int로 보면 왼쪽은 98, 오른쪽은 134이다.
그러니 더 작은 왼쪽 페이지를 교체하면 딱 들어맞는다.
Second-Change (Clock)
클럭 알고리즘은 8개의 비트 대신 하나의 참조 비트만을 사용하는 방식이다.
(편의상 second-chance의 다른 이름인 클럭 알고리즘이라 지칭하겠다)
💡 The basic algorithm of second-chance replacement is a FIFO replacement algorithm.
클럭 알고리즘은 FIFO 교체 알고리즘에 기반한다.
쉽게 말해 FIFO인 대신에, 최근에 사용되었는지 확인하는 비트만 하나 추가된 형태이다.
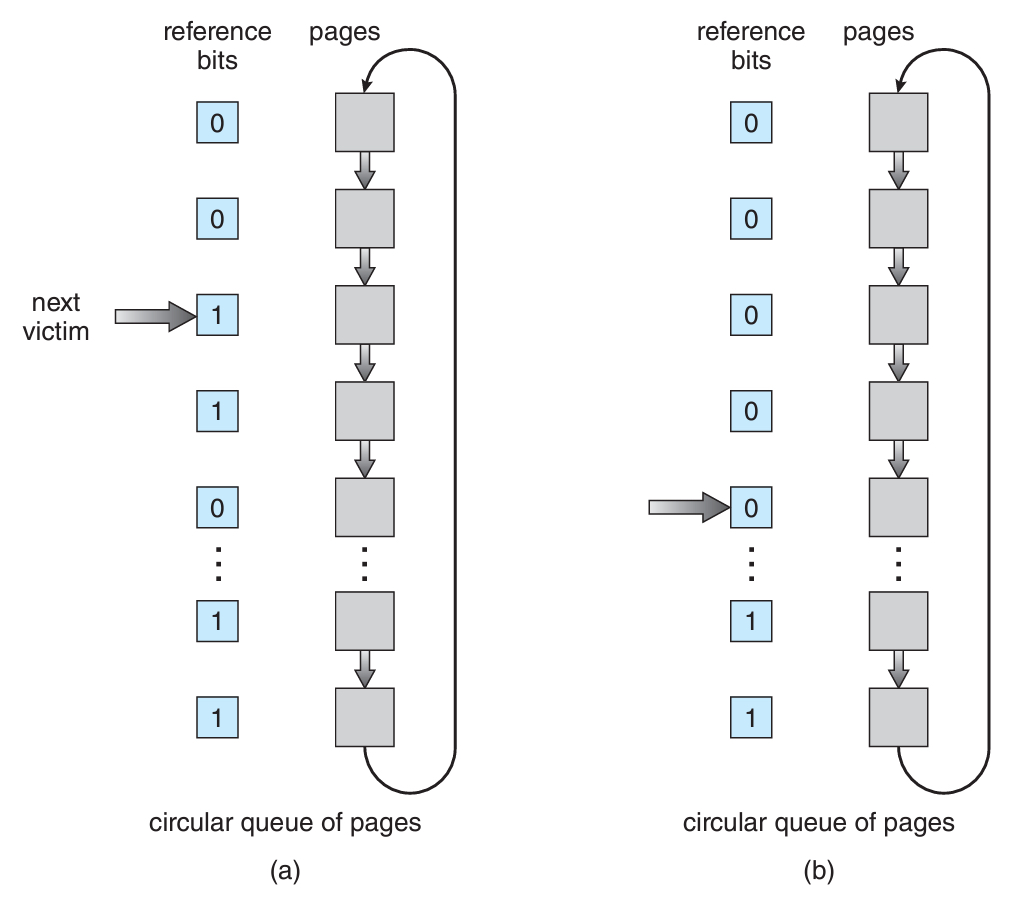
우선 클럭 알고리즘의 특성상 모든 페이지가 하나의 원형큐에 들어가게 된다.
작동방식을 먼저 이해하게 된다면 원형큐를 사용하는 이유와 알고리즘의 이름까지 납득하게 된다.
우선 하나의 페이지를 가리키는 포인터 하나가 필요하다.
해당 포인터는 희생 페이지를 찾을 때까지 원형큐를 순회하면서 비트를 확인하는 용도이다.
만약 비트가 0으로 설정되어있다면, 해당 페이지를 희생시켜서 교체하면 된다.
문제는 비트가 1인 경우인데, 이 경우에는 비트를 0으로 초기화하고 다음 페이지로 넘어간다.
한마디로 비트가 0인 페이지를 찾을 때까지 순회한다고 보면 된다.
그리고 포인터와 별개로, 어떤 페이지가 접근되면 알아서 본인의 비트를 1로 올린다.
포인터는 페이지를 죽이려고 하고, 페이지는 살려고 발버둥치는 꼴이다.
정리하자면, 포인터는 교체할 페이지를 찾으려고 계속해서 원형큐를 순회하고,
페이지는 접근될때마다 비트를 1로 설정하여 희생 페이지가 되는 것을 피한다.
이런식으로 최근에 접근된 페이지에게는 한 번의 기회를 더 주기 때문에 second-chance라고 한다.
또한, 포인터는 계속해서 원형큐를 빙글빙글 돌기 때문에 clock이라고 부르기도 한다.
💬 이 외에도 {참조 비트, 수정 비트} 쌍으로 판단하는 변형도 존재한다.
Counting-Based
여태까지 본 알고리즘의 공통점은 "시간"을 기준으로 판단했다는 것이다.
이와 반대로 "횟수"를 기준으로 교체하는 알고리즘도 존재한다.
LFU라고 불리는 "Least Frequently Used" 알고리즘이 있는데,
이 친구는 말그래도 최근에 가장 적게 사용된 페이지를 교체하는 방식이다.
이를 사용하는 이유는 적게 사용된 만큼 앞으로도 적게 사용될 것이라는 예측 때문이다.
반대로 MFU라고 불리는 "Most Frequently Used" 알고리즘도 존재한다.
위 알고리즘과 완전 반대로, 최근에 가장 많이 사용된 페이지를 교체하는 것이다.
적게 사용되었다는 것은 이제 막 올라온 페이지일 확률이 높다는 주장 때문이다.
4. 프레임 할당
고정된 개수의 메모리 프레임을 N개의 프로세스에게 몇개씩 할당해야 할까?
예를 들어 128개의 프레임이 있는 메모리가 있다고 하자.
OS가 35개를 고정적으로 가져간다고 치면, 나머지 93개가 유저 프로세스에게 가야 한다.
그러면 이 93개의 프레임을 개수가 유동적인 프로세스에게 어떻게 할당할까?
순수 요구 페이징은 어느 프레임도 주인을 정하지 않고 페이지폴트에만 맡기는 것을 보았다.
하지만 당연히 이러한 방식도 여러가지가 있을 수 있다.
OS 페이지 중 당장 사용하지 않는 페이지를 유저 프로세스에게 빌려줄 수도 있고,
최소 3개의 페이지를 여유분으로 두어서 페이지 교체 반응성을 올릴 수도 있다.
이 외에도 다양한 변형들이 존재할 수 있지만, 한가지 사실만 지키면 된다.
유저 프로세스는 빈 프레임만 할당받으면 된다.
최소 프레임 개수
프로세스에게 할당될 수 있는 프레임의 개수에 대한 2가지 제약조건을 정리하고 가자.
우선, 할당될 수 있는 프레임의 최대 개수는 당연히 메모리 프레임 개수를 넘을 수 없다.
이는 메모리가 고정 사이즈이기 때문에 물리적으로 당연한 얘기이다.
그러면 반대로 할당되어야 할 최소 프레임 개수는 몇개일까?
물론 순수요구페이징에 따르면 하나만 할당해도 동작은 할 것이다.
하지만 그렇게 하면 시작부터 페이지폴트가 연달아 일어나기 때문에 성능이 좋지는 않다.
그래서 프로세스에게 할당할 최소 프레임 개수를 설정하는 것이 중요하다!
💡 One reason for allocating at least a minimum number of frames involves performance.
최소 프레임 개수를 할당하는 것은 성능 때문이다.
방금 얘기했듯이, 프레임이 적게 할당될수록 일반적으로 페이지폴트 발생빈도가 늘어난다.
또한, 하나의 명령어가 여러 페이지에 동시에 접근할수도 있는데,
미리 페이지들이 올라와있지 않다면 하나의 명령어가 여러번 재실행될 수도 있다.
(페이지 폴트가 일어나면 명령어를 재실행하니까)
예를 들어서, 데이터를 로드하는 임의의 명령어가 프레임 13번에 있다고 치자.
그런데 그 데이터가 프레임 5번에 존재하는 것이다.
또 막상 그 데이터를 확인해보니 다른 프레임에 있는 데이터에 대한 포인터인 것이다.
그러면 하나의 단순 load 작업에 3개의 프레임이 한번에 접근되는 것이다.
💡 The minimum number of frames is defined by the computer architecture.
최소 프레임 개수는 컴퓨터 아키텍처가 정의한다.
그러면 굳이 이걸 공부할 필요가 있을까?
Intel의 32-bit와 64-bit 아키텍처는 데이터가 메모리에서 메모리로 움직이지 못하게 제한한다.
그러니 위의 예시처럼 한번에 여러 프레임을 필요로 하는 상황을 제한하는 것이다.
마지막으로 정리하고 넘어가자면,
최대 프레임 개수는 메모리의 크기가 결정하고, 최소 프레임 개수는 아키텍처가 결정한다.
할당 알고리즘
이제 최소 프레임 개수와 최대 프레임 개수를 만족시키면서,
각 프로세스에게 몇개의 프레임을 할당해야 할지 고민하면 된다.
가장 쉬운 방법은 프레임 개수를 공평하게 할당하는 것이다.
128개의 프레임을 4개의 프로세스에게 줘야한다면, 32개씩 주는 것이다.
이 방식을 "equal allocation"이라고 부른다.
그런데 조금만 생각해봐도 이 방식이 얼마나 효율이 낮은지 알 수 있다.
당장 10Kb짜리 프로세스A와 90Kb짜리 프로세스B, 이렇게 2개가 들어온다고 치자.
그리고 할당 가능한 프레임의 크기가 10Kb이고 개수는 10개라고 치자.
그러면 A는 10Kb임에도 불구하고 프레임을 50Kb나 사용하는 것이고,
B는 90Kb인데 프레임을 50Kb밖에 못쓰니 페이지폴트가 자주 발생한다.
💡 To solve this problem, we can use proportional allocation, in which we allocate available memory to each process according to its size.
이 문제를 해결하기 위해 proportional allication을 사용할 수 있다.
각 프로세스의 사이즈에 맞게 프레임을 할당해주는 방식이다.
위의 예시를 마저 끌고 가자면, 10Kb와 90Kb의 비율은 1:9이다.
그리고 마침 프레임의 개수가 10개이니 각각 1개와 9개씩 할당하면 되는 것이다.
그러면 두 프로세스 모두 페이지폴트 없이 빠르게 동작할 수 있게 되는 것이다.
물론, 실제로는 프로세스들의 총 크기가 메모리 크기를 아득히 뛰어넘는다.
그래도 이렇게 비율로 따져서 할당하면 고정개수를 주는 것보단 효율적일 것이다.
이 방식에 우선순위를 부여하여 개수를 추가적으로 조정하는 등의 다른 방식도 있을 수 있다.
전역 할당 vs 지역 할당
프레임이 할당되는 방식에 또다른 중요한 요소는 페이지 교체 방식이다.
💡 With multiple processes competing for frames, we can classify page-replacement algorithms into two broad categories: global replacement and local replacement.
여러 프로세스가 프레임을 두고 경쟁하는 상황에서, 페이지 교체 알고리즘을 2가지 카테고리로 분류할 수 있다: 전역 할당 & 지역 할당
전역 할당이라고 하면, 페이지 교체를 프레임 전체 범위에서 선택한다는 뜻이다.
즉, 프로세스가 다른 프로세스의 페이지를 내리고 본인의 페이지를 올릴 수 있는 것이다.
지역 할당은 반대로 프로세스가 본인이 할당받은 프레임 내에서만 선택하는 것이다.
위에서 봤듯이 뭐든지 크기나 개수가 고정적인건 효율적이지 못하다.
지역할당은 프로세스별 프레임 개수가 고정인, 무조건 전역할당 방식을 사용하면 좋지 않을까?
💡 One problem with a global replacement algorithm is that the set of pages in memory for a process depends not only on the paging behavior of that process, but also on the paging behavior of other processes.
전역 할당의 문제 중 하나는 다른 프로세스의 페이징 방식의 영향을 받는다는 것이다.
예를 들어, 프로세스 A가 페이지 교체가 필요해서 프로세스 B의 페이지를 뺐다고 가정하자.
그러면 프로세스 B는 원래 있어야 할 페이지가 없으니 페이지 폴트를 발생시킨다.
즉, 프로세스 B의 명령어가 원래 예상했던 시간보다 많은 시간을 소요하게 된다.
문제는 이 현상이 순전히 "외부 요인"으로부터 발생했다는 것이다.
대신 지역 할당은 사용되지 않는 페이지가 남아있는 문제가 발생할 수 있다.
어떤 프로세스가 할당받은 프레임 5개 중 당장 3개만 사용한다고 하자.
그런데 다른 프로세스가 놀고 있는 2개의 프레임을 뺐을 수 없으니 효율이 낮아진다.
이처럼 전역 할당은 throughput이 지역 할당보다 높다!
Reaper (리퍼)
전역할당 방식에서 사용될 수 있는 전략 중 하나인 리퍼에 대해서 알아보자.
💡 With this approach, we satisfy all memory requests from the free-frame list, but rather that waiting for the list to drop to zero before we begin selecting pages for replacement, we we trigger page replacement when the list falls below a certain threshold.
모든 메모리 요청에 대해 free-frame 리스트에서 프레임을 할당해준다.
단, 페이지 교체 알고리즘을 특정 기준점에 도달한 경우에 한꺼번에 호출한다.
한마디로 페이지 교체 알고리즘을 몰아서 하는 방식이다.
메모리 요청이 들어오면, free-frame list에서 하나 찾아준다.
이 과정을 최소기준점에 도달할 때까지 페이지를 빼지 않고 할당만 해준다.
만약 최소기준점에 도달하면, 최대기준점으로 올라갈때까지 페이지를 한번에 다 뺀다.
사실 이 방식은 아래 그림을 보고 이해하는 것이 빠르다.
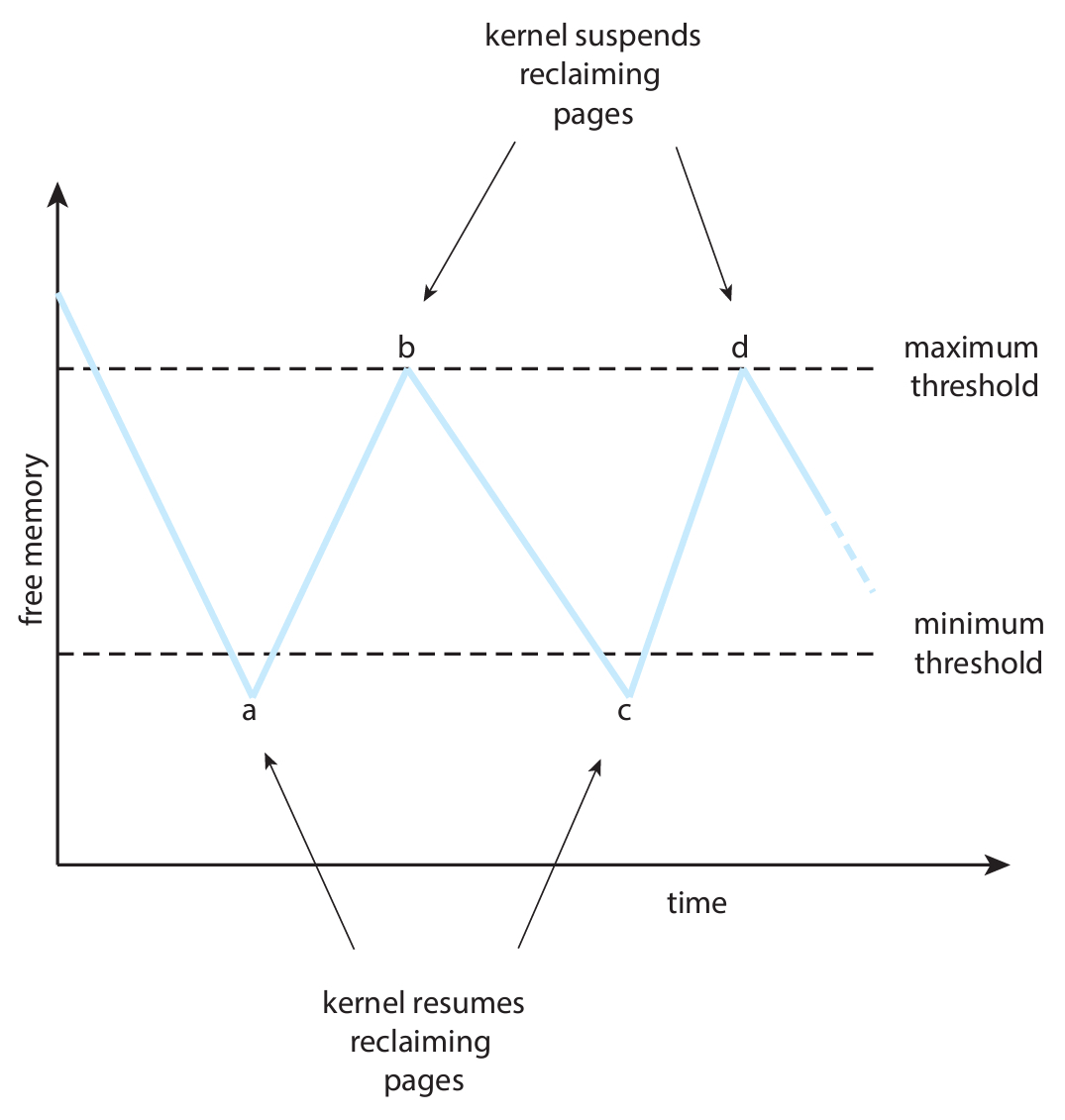
위 그림에서 maximum threshold (최대기준점)이 16이고,
minimum (최소기준점)이 4라고 하고, 총 프레임 개수는 20개라고 하자.
그러면 메모리는 처음에 20개의 프레임이 전부 비어있는 상태에서 시작을 할것이고,
페이지폴트가 발생할때마다 프레임을 하나씩 할당을 해주게 된다.
남은 프레임이 4개(최소기준점)가 될때까지 계속해서 할당만하다가, 리퍼가 동작하게 된다.
💬 리퍼는 커널 루틴의 이름으로, 페이지를 기준점 사이에서 유지시켜주는 역할을 한다.
리퍼가 이제부터 모든 프로세스로부터 프레임을 하나씩 뺏기 시작한다.
이 과정은 뺏은 총 프레임의 개수가 16개(최대기준점)가 될때까지 진행한다.
이렇게 하는 이유는, 한번에 할당해줄 수 있는 최소한의 프레임 개수를 남겨두려는 목적이다.
5. 스레싱 (Thrashing)
만약 프로세스가 충분한 양의 프레임을 할당받지 못한 상황이 있다고 하자.
현재 작업해야 할 페이지의 개수보다 적은 프레임을 할당받았다는 뜻이다.
그러면 필요한 페이지가 없어서 페이지폴트가 발생하게 될 것이고,
작업을 하다가 아까 교체당한 페이지가 다시 필요해서 또 페이지폴트가 발생하게 될 것이다.
이런식으로 작업하면 페이지폴트가 짧은 시간 내에 계속해서 발생하게 된다.
💡 This high paging activity is called thrashing. A process is trashing if it is spending more time paging than executing.
이렇게 높은 페이징 활동을 스레싱이라고 부른다.
프로세스가 실행보다 페이징에 더 많은 시간을 쏟으면 스레싱 상태라고 간주한다.
발생 원인
스레싱의 발생 원인을 한 단어로 요약하면 "악순환"이다.
우선 2가지 전제조건을 잡고 들어가야 한다.
1. OS는 CPU 사용량을 수시로 모니터링하고 있다.
2. 전역 할당 알고리즘을 사용 중이다.
일단 메모리 상황이 정상적인 상태로 시작하게 된다.
오히려 프로세스가 아직 적어서 CPU 사용량이 낮은 상태이다.
그러면 OS는 CPU 사용량이 낮으니 멀티프로그래밍 차수를 올리게 된다.
즉, 새로운 프로세스가 하나씩 진입하게 된다는 뜻이다.
그러면 점점 CPU와 메모리가 활발하게 움직이게 될 것이고,
페이지폴트도 점점 많이 발생하게 될 것이다.
그런데 문제는 어느 한 시점에서, 프로세스가 프레임을 많이 필요로 하고,
다른 프로세스의 프레임을 뺏기 시작하는데, 그 다른 프로세스도 해당 프레임이 필요한 것이다.
그러면 많은 프로세스들이 갑자기 프레임을 막 뺐기 시작하는 상황이 발생한다.
💡 These faulting processes must use the paging device to swap pages in and out. As they queue up for the paging device, the ready queue empties. As processes wait for the paging device, CPU utilization decreases.
이렇게 폴트가 발생하는 프로세스들이 페이지 교체를 위해 대기상태로 돌입한다.
CPU 스케줄링 큐 중에서 ready queue가 비게 되고, CPU 사용량은 낮아진다.
여기부터가 본격적으로 문제가 시작된다.
OS는 CPU 사용량이 낮아지는 것을 확인했으니, 새로운 프로세스를 진입시킨다.
그러면 해당 프로세스도 페이지 폴트가 발생할 것이니, 또 ready queue가 빈다.
이렇게 하다보면 프로세스 개수는 계속해서 늘어나고, 여전이 ready queue는 비어있다.
결과적으로 그 어떤 프로세스도 일을 못하고 있는데, 프로세스는 늘어나기만 하는 것이다.
여태 설명했던 상황을 그래프로 나타내면 아래와 같다.
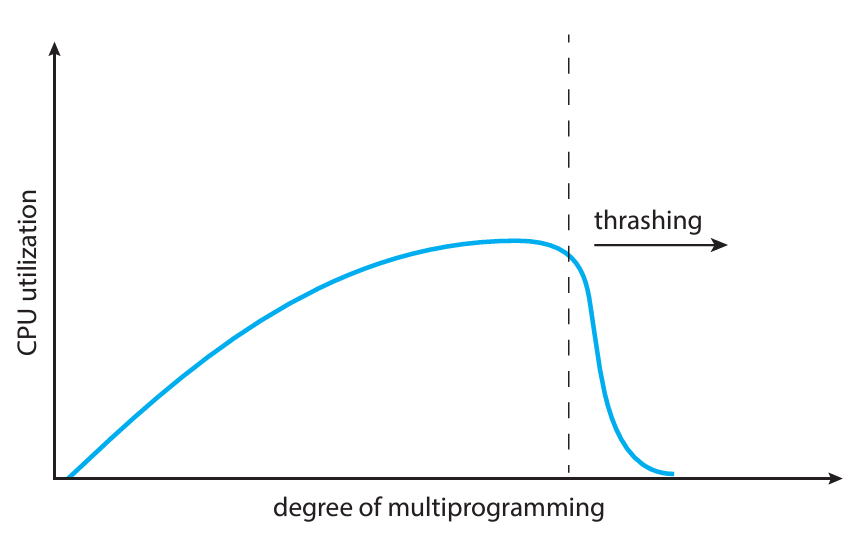
X축이 프로세스의 개수, Y축이 CPU 사용량을 나타낸다.
일반적으로 프로세스 개수와 CPU 사용량이 비례하여 증가하지만,
특정 프로세스 개수를 기준으로하여 CPU 사용량이 급격하게 감소한다.
이 현상을 지역할당방식으로 어느정도 제한할 수 있기는 하다.
남의 프레임을 뺐을수는 없으니, 전부 ready queue로 가는 불상사는 막을 수 있을 것이다.
그럼에도 "어느정도"라고 한 이유는, 다른 프로세스에게 여전히 영향을 주기 때문이다.
하나의 프로세스만 스레싱이 되어도, 페이징 장치의 대기열이 길어진다.
그러면 해당 장치에 접근하려는 다른 프로세스의 실행속도에도 영향을 미치게 된다.
💬 페이징 장치는 백업 저장소를 소유한 disk 장치를 의미한다.
결국 스레싱을 막으려면 각 프로세스에게 최대한 많은 프레임을 주는 수밖에 없다.
그런데 각 프로세스가 "필요한" 프레임의 개수를 어떻게 알 수 있을까?
지역성 모델
💡 One strategy starts by looking ay how many frames a process is actually using. This approach defines the locality model of process execution.
하나의 방법은 각 프로세스가 실제로 사용하고 있는 프레임 개수를 보는 것이다.
이 접근법은 프로세스 실행의 "지역성 모델"을 정의한다.
💡 A locality is a set of pages that are actively used together.
지역성은 주로 같이 사용되는 페이지의 집합이다.
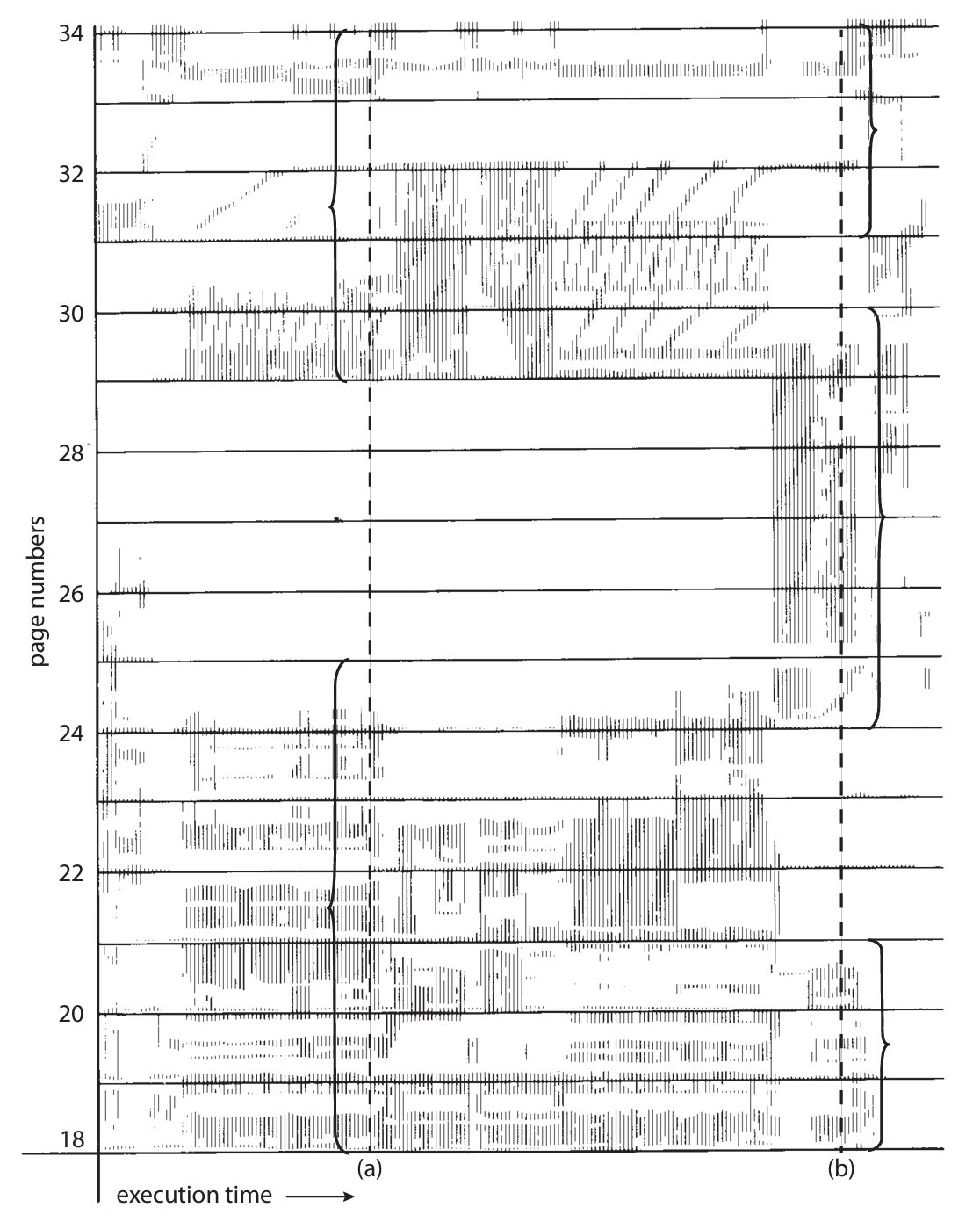
위는 한 프로세스가 실행시간에 따라서 접근하는 프레임 번호를 나타낸 그림이다.
(a) 시점에서는 {18~25, 29~34}를 함께 접근하는 모습이고,
(b) 시점에서는 {18~21, 24~30, 31~34}를 함께 접근하는 모습이다.
이렇게 한번에 접근되는 프레임의 집합을 지역성이라고 한다.
만약 프로세스에게 지역성을 고려하여 프레임을 할당해줬다고 하자.
그러면 프로세스는 지역성이 바뀔때까지 페이지 폴트를 발생시키지 않을 것이다.
Working-Set 모델
워킹셋(working-set) 모델은 지역성 추정에 기반을 둔 모델이다.
해당 모델은 (델타)를 워킹셋 윈도우로 정의한다.
가장 최근에 참조된 개의 프레임을 모아둔 것이 워킹셋이 된다.
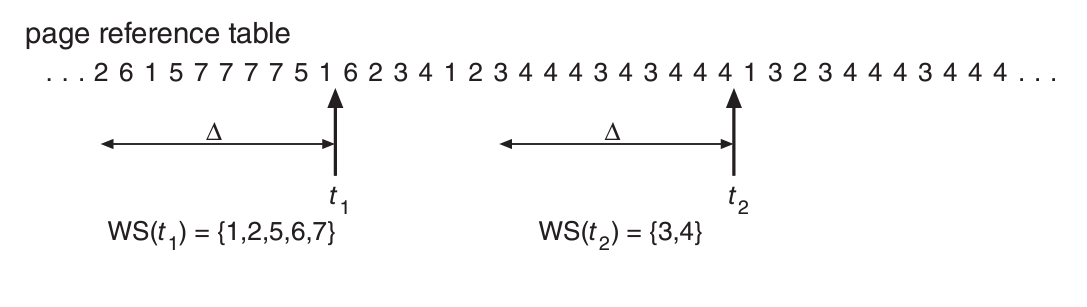
워킹셋의 정확도는 가 결정하게 된다.
너무 낮으면 지역성을 제대로 포함시키지 못하게 될 것이고,
너무 높다면 여러 지역성이 겹치게 되어서 의미가 퇴색된다.
다시 돌아와서, 우리가 아까부터 계속 찾고 있는건 스레싱을 피하는 방법이다!
그리고 워킹셋을 이용하면 스레싱이 발생할지 예측할 수 있게 된다.
프로세스 i에 대한 워킹셋을 라고 하고 아래의 수식을 보자.
여기서 는 현재 접근가능성이 높은 프레임들의 집합이 된다.
모든 프로세스의 지역성을 합친다면, 그 의외의 것이 참조될 확률은 낮으니까!
이제 OS가 해야할 일은 간단해진다.
모든 프로세스의 워킹셋을 참고하여, 해당 크기만큼 프레임을 할당해주면 된다.
그리고 아직 여유분의 프레임이 남아있다면 새로운 프로세스를 시작하면 되고,
반대로 프레임이 부족하다면 프로세스 하나를 일시정지 시키면 그만이다.
Page-Fault Frequency
워킹셋만 본다면, 구체적으로 스레싱을 컨트롤하기에는 구체적이지 못하다.
PFF(Page-Fault Frequency)를 사용하는 전략으로 보다 직접적으로 관리할 수 있다.
PFF는 아래와 같이 페이지폴트 빈도와 프레임 수의 관계도이다.
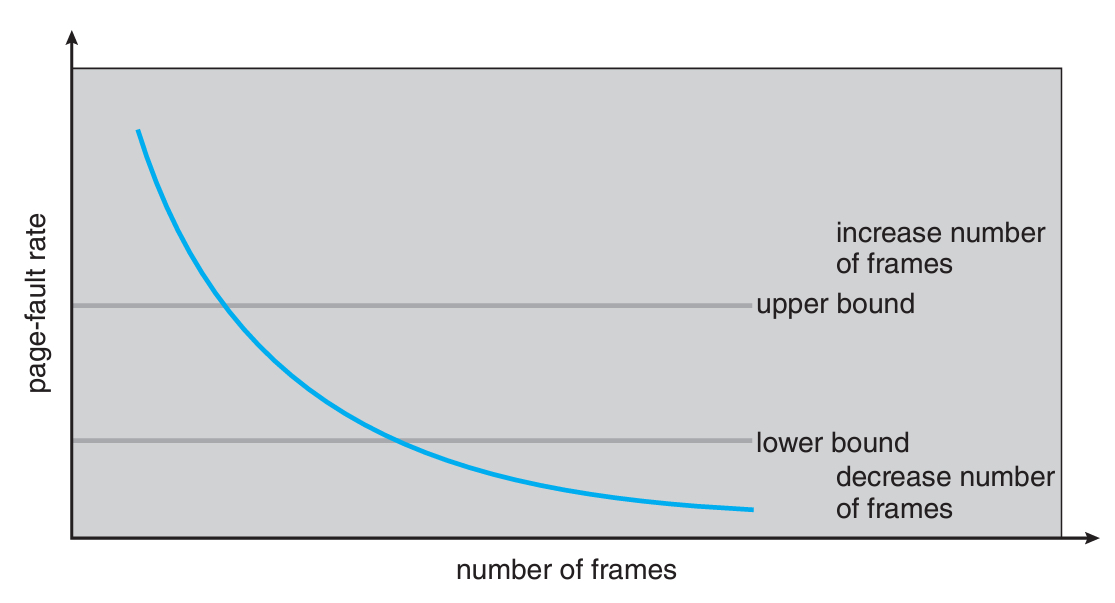
PFF를 참고하여 특정 지점에 상한선과 하한선을 지정한다.
상한선을 넘으면 페이지폴트 빈도수가 높다는 뜻이니 프로세스를 중지하면 되고,
하한선 아래로 떨어지면 프레임을 더 할당해도 문제가 없다는 뜻이다.
그러나 결국 이 모든 과정이 컴퓨터 성능에 큰 영향을 준다.
💡 The current best practice in implementing a computer system is to include enough physical memory, whenever possible, to avoid thrashing and swapping.
실질적으로 가장 좋은 방법은 충분한 메모리 공간을 확보하는 것이다.
램.. 더 많은 램이 필요하다..
6. 기타 고려사항
여태 공부한 내용들이 가상메모리의 주요 개념들이라고 보면 된다.
이 외에도 모바일 시스템에서는 "메모리 압축" 방식을 사용하기도 하고,
커널 메모리 할당은 "Buddy System"이나 "Slab Allocation"을 기용하기도 한다.
본 블로그에서는 해당 내용은 건너뛰고, 다른 고려사항들에 대해 다루고자 한다.
Prepaging
일단 요구페이징에 대한 내용부터 다시 간단하게 정리를 해볼 필요가 있다.
요구페이징은 페이지가 필요한 시점에서 해당 페이지를 위한 프레임을 할당하는 것이다.
순수요구페이징은 프로세스가 실행 시에 아무 페이지도 올리지 않고,
오로지 요구페이징에게 맡겨서 알아서 페이지가 하나씩 올라가게 냅두는 기법이다.
💡 Prepaging is an attempt to prevent this high level of initial paging. The strategy is to bring some - or all - of the pages that will be needed into memory at one time.
프리페이징은 프로세스 최초 실행 시의 페이징의 오버헤드를 줄이기 위함이다.
프로세스가 시작할 때, 페이지 전체 또는 일부를 메모리에 올리는 방식이다.
물론, 워킹셋을 활용하여 정지된 프로세스를 재실행할때에도 활용할 수도 있을 것이다.
여기서 중요한건 과연 프리페이징을 사용하는 것이 더 나은지이다.
만약 여러 페이지를 올렸는데, 그 페이지 중 대부분이 사용되지 않았다면?
물론 지역성 덕분에 단순히 주소가 비슷한 페이지를 같이 올리면 먹힐 때도 있을 것이다.
그럼에도 상황은 예측하기 힘들기 때문에 무조건 좋다고 말할 수는 없다!
💬 Linux의 readahead() 시스템콜이 대표적으로 프리페이징을 활용한다.
페이지 크기
페이지의 크기는 클수록 좋을까, 작을수록 좋을까?
(개인적으로 이 부분은 여태 공부한 OS 내용을 활용해서 직접 고민해보는 것이 좋다고 생각한다.)
그러면 본격적으로 페이지 크기에 대한 논쟁을 스토리텔링을 해보겠다.
가장 먼저 페이지의 크기가 제일 직접적으로 영향을 미치는 것은 무엇일까?
페이지가 작을수록 페이지의 개수가 늘어나는 것은 당연하다.
다시 페이지의 개수가 늘어나는 것은 결국 페이지 테이블의 크기가 커진다는 뜻이다!
한마디로 페이지 크기가 작으면 페이지 테이블 자체가 메모리를 많이 먹게 될 수도 있다.
하지만 웃기게도 페이지 크기가 작은게 메모리 사용량이 더 높다.
페이징이 사실 필수적인 기법으로 보이지만, 한가지 치명적 단점이 있다고 했다.
페이지 크기가 너무 크면 마지막 페이지에서 발생하는 내부 단편화가 커진다.
그러면 일단 페이지가 직접적인 영향을 미치는 부분에서는 1대1인걸로 마무리하자.
이제 페이지가 교체되는 속도에 대해서 생각을 해볼 차례다.
페이지가 저장되는 곳은 기본적으로 2차 저장장치인 디스크인데,
명심해야하는 사실은 디스크는 I/O 속도가 말도 안될 정도로 느리다!
당장 페이지는 원래부터 메모리에 있었던 척을 해야하는데,
그 오래걸린다는 디스크에 계속해서 왔다갔다하는 상황은 피해야 한다.
그러면 페이지 크기가 커도 디스크에서 읽는데 오래걸리는게 아닌가 싶긴 하다.
그런데 읽어야 할 페이지 크기는 읽어야 하는 페이지의 개수에 거의 영향이 없다.
그정도로 디스크 I/O는 느리다.
즉, 페이지 크기가 커야 디스크 I/O 속도를 줄일 수 있다.
물론 컴퓨터에서 전반적은 I/O 속도가 생명과도 같으니 페이지 크기를 크게 했다고 치자.
그런데 과연 페이지 크기를 크게해서 가져왔다고 해서, 그 페이지 내의 데이터를 다 사용할까?
우리는 방금 지역성에 관해서 공부했다.
페이지의 크기가 너무 크면 필요없는 내용까지 가져와서 지역성의 정확도가 떨어진다.
오히려 페이지 크기를 줄여서 지역성의 정확도를 높이는 것이 더 좋지 않을까?
지역성 정확도가 높은게 실제로 I/O 횟수를 줄이게 된다!
그러니 페이지 크기가 작아야 I/O 횟수를 줄일 수 있다.
지금까지 페이지 크기에 대한 다양한 의견들을 알아보았다.
당장 봐도 의견이 2대2이기도 하고, 어떻게든 서로 의견에 반박하는 것이 가능하다.
이처럼 최적의 페이지 크기라는 개념은 존재할 수가 없다.
💡 Nevertheless, the historical trend is toward larger page sizes, even for mobile systems.
그러나 트렌드를 살펴보면 점점 큰 페이지 크기를 추구하고 있다. (모바일 포함)
이 이유에 대해서는 직접 고민해보면 좋을 것 같다.
사실 책에 그 이유가 안써져있다
📌 본 글은 책에서 직접 인용한 내용이 아닙니다.
—
학부생 시절 교수님께 배운 대로라면, CPU의 연산속도 때문이라고 생각한다.
I/O 속도의 기술발전은 CPU 속도의 기술발전에 비교가 안될만큼 느린데,
그렇기에 차라리 큰 페이지를 가져와서 최대한 연산을 빠르게 해버리는 것이다.
TLB Reach
우리는 앞서 TLB hit ratio에 대해서 잠깐 알아보았다.
그런데 hit ratio 외에도 중요한 요소가 하나 더 있다.
💡 The TLB reach refers to the amount of memory accessible from the TLB and is simply the number of entries multiplied by the page size.
TLB reach는 TLB로부터 접근 가능한 메모리의 크기이다.
정확히는 단순히 페이지 엔트리에 페이지 크기를 곱한 숫자이다.
TLB reach는 당연히 클수록 좋을 것이다.
메모리를 2번 왔다갔다 하는 것은 어떤 관점으로 보든 비효율적이기 때문이다.
그렇다면 어떻게 TLB reach를 늘릴 수 있을까?
가장 단순한 방법은 페이지 크기 자체를 키워버리는 것이다.
그에 따라 저장할 수 있는 페이지 개수가 늘어나게 될테니까.
단, 내부 단편화가 더 커진다는 단점이 존재하기 때문에 다른 방법이 또 필요할 것 같다.
💡 Alternatively, most architectures provide support for more than one page size, and an operating system can be configured to take advantage of this support.
대신, 대부분의 아키텍처는 하나 이상의 페이지 사이즈를 지원해주는 동시에,
OS는 이러한 기능 지원에 따라 설정될 수 있다.
실제로 Linux의 기본 페이지 크기는 4Kb지만, 더 큰 크기의 페이지도 지원한다.
설정에 따라 크게는 2Mb의 페이지 크기로 설정하는 것도 가능하다.
ARMv8 아키텍처 역시 다양한 크기의 페이지를 지원하는데,
추가로 각 TBL 엔트리가 contiguous bit라고 하는 비트열을 가지고 있다.
해당 비트열이 어떤 TLB 엔트리에 세팅되어있다면, 해당 엔트리는 연속된 메모리 플록을 매핑해준다.
이러한 예시처럼 다양한 페이지크기를 지원하면 성능에 영향을 주는 것은 사실이다.
대신 더 높은 TLB hit ratio와 reach를 지원할 수 있다.
I/O Interlock & 페이지 락
요구페이징을 사용하는 경우에는 페이지에 락이 필요한 경우가 생긴다.
특히, I/O가 유저(가상)메모리에 직접 접근하는 경우가 그렇다.
예를 들어서 유저 프로세스 A가 본인의 페이지 a에 I/O를 위한 버퍼를 생성했다고 하자.
그런데 그때 다른 프로세스 B가 페이지폴트가 발생해서 페이지 a를 page out 했다면?
정확히는 a가 page out 당한것 보다는 새로운 페이지 b가 들어온게 더 문제다.
A는 I/O 과정에서 b의 특정 주소에 데이터를 받아올테니 b의 데이터가 엉망이 된다.
(계속 강조하지만, 프로세스 입장에서는 페이지의 존재를 모르니 원래 쓰던 "주소"에 써야한다)
이러한 이유로 총 2가지의 해결방안이 고안되었다.
첫번째 방식이 I/O interlock이라고 불리는 "유저 메모리 I/O 금지"법이다.
즉, 모든 I/O는 시스템 메모리를 통해서만 발생할 수 있도록 제한을 하는 것이다.
입력을 받는 경우에는 시스템 메모리에 전부 쓴 후에 유저 메모리로 옮겨야한다.
반대로 출력은 유저메모리를 시스템 메모리에 전부 복사한 후에 진행한다.
그러나 이 방식은 모든 내용을 복사하는 과정이 포함되기에 오버헤드가 크다.
그래서 두번째 방식인 page lock은 아예 페이지가 page out되지 못하게 막는다.
I/O가 발생중인 페이지가 있다면, 락을 걸어두고 다른 프로세스가 건들지 못하게 하는 것이다.
추가로 운영체제가 직접 사용하는 페이지에 lock을 거는 식으로도 활용할 수 있다.
강력해보이는 방식이지만, 어떠한 이유로 lock이 해제되지 않는 버그가 발생할 수도 있다.
그런 경우에는 해당 페이지를 영원히 쓰지 못하게 되니 치명적일수밖에 없다.
그래서 Solaris 같은 경우에는 lock 대신 hint를 주는 방식을 체택하는데,
lock hint를 보면 일단은 page out을 보류하지만, 페이지가 너무 부족한 상황에서는 무시한다.
💬 Solaris는 Oracle 사에서 만든 운영체제이다.
🎯 마치며
우리는 가상메모리를 알게 모르게 사용해왔을 가능성이 크다.
어떻게든 컴퓨터의 속도를 빠르게 하기 위해서 다양한 고민이 있었음에 감사하자.
출처
Abraham Silberschatz, 『Operating System Concepts Ed.10』
