머신러닝의 목표: 일반화
- 최적화: 훈련데이터에서 최고의 성능을 얻으려고 모델을 조정하는 과정(학습)
- 일반화: 훈련된 모델이 완전 새로운 데이터에서 얼마나 잘 수행되는가
- 머신러닝의 이슈: 최적화와 일반화 사이의 줄다리기
과소적합과 과대적합부터 이해
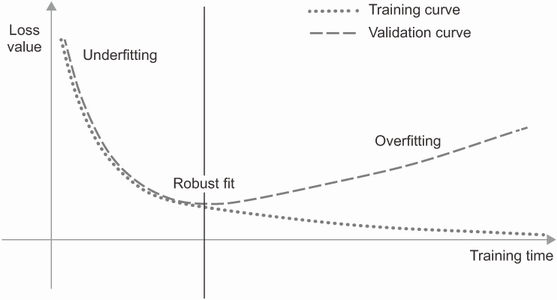
🔸 과소적합
- 네트워크가 훈련 데이터에 있는 모든 관련 패턴을 학습하지 못한 상태
- 모델의 성능이 계속 발전될 여지가 남아있음
🔸 과대적합
- 훈련 데이터에 특화된 패턴을 학습하기 시작
- 새로운 데이터와 관련성이 적고 잘못된 판단 가능
- 데이터에 잡음, 불확실성, 드문 특성 포함시 발생할 가능성 높음
- 데이터의 부정확성
- 데이터의 무작위성
- 특성이 모호한 영역에 너무 확신을 가지면 과대적합 가능
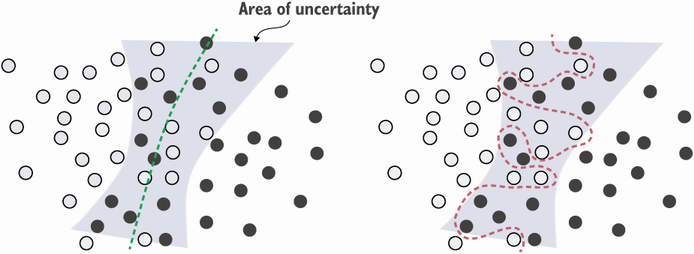
- 드문특성과 가짜 상관관계: 완전 우연적 관계를 활용할 경우
- 과대적함을 피하기위한 방법: 특성선택
어떤 특성이 얼마나 유익한 지 측정하고 일정 임계값을 넘긴 특성만을 사용
일반화 이해
🔸 매니폴드 가설
높은 차원에 존재하는 데이터들의 경우, 해당 데이터들을 아우르는 낮은 차원의 다양체(manifold)가 존재한다는 가설
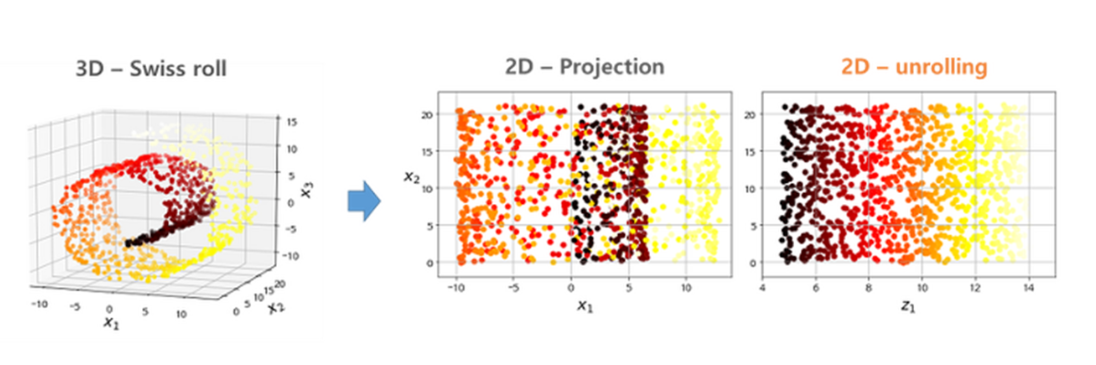
- 머신러닝의 모델은 입력 공간 안에서 비교적 간단하고, 저차원이며 매우 구조적인 공간(잠재 매니폴드)만 학습하면 된다.
- 데이터들을 사용하여 두 입력(샘플) 사이를 부드럽게 보간하는 것이 가능하게 하는 것 = 딥러닝에서 일반화 성능을 가지게 하는 열쇠
🔸 딥러닝의 작동
- 딥러닝은 입력부터 출력까지 매끄럽고 연속적인 매핑을 구현한다. 이런 매끄러움은 동일한 속성을 가진 잠재 매니폴드를 근사하는 데 도움이 된다.
- 훈련 데이터에 있는 정보의 형태를 반영하는 식으로 구조화, 이는 계층적이고 모듈 방식으로 구조화.
- = 자연적 데이터가 구성되는 방식을 반영한 것
- = 자연적 데이터가 구성되는 방식을 반영한 것
🔸 훈련데이터의 중요성
-
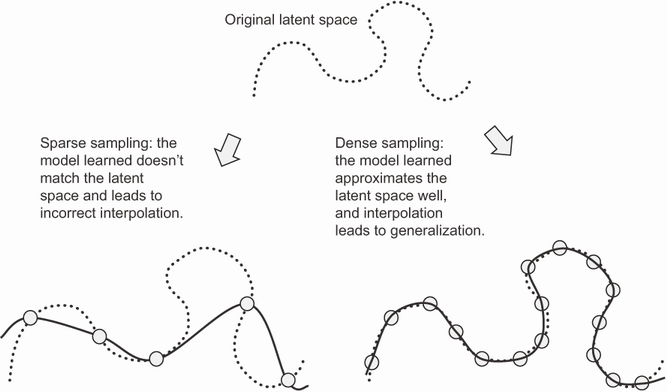
딥러닝이 곡선을 맞추는 것이기 때문에 모델이 이를 잘 수행하려면 조밀하게 샘플링하여 훈련해야한다.
-
더 좋고, 더 많은 데이터에서 훈련하는 것이 모델을 향상시키는 가장 좋은 방법.
-
단순한 보간의 이상을 기대하면 안됨: 가능한 한 쉽게 보간하기 위해 할 수 있는 모든 일을 해야한다
-
데이터 수집이 어려울 시(특정데이터에 과대적합을 피하기 위해):
- 정보량 조절
- 제약 추가 (규제)
- 가장 유익한 패턴에만 모델의 초첨을 맞추도록 함
일반화를 위한 머신러닝 모델 평가
데이터 분리
- 데이터를 항상 훈련, 검증, 테스트 (3개)의 세트로 나눈다
- 모델의 설정을 최적으로 튜닝하기 위해서 검증 데이터를 사용: 좋은 설정을 찾는 학습
- 정보누설: 하이퍼파라미터를 조정할때마다 검증 데이터에 관한 정보가 모델로 새는것
- 하이퍼 파라미터: 모델의 설정을 튜닝하는 파라미터
- 검증 세트에 과대적합될 수 있다
- 따라서, 완전 새로운 데이터로 평가하기 위해 테스트 세트를 사용 : 일반화 성능 파악
- 테스트 세트에서 모델을 튜닝해서는 안됨
- 데이터가 너무 적어 훈련과 검증, 테스트 세트로 나눌시 샘플이 너무 적을 때 해결방법: K-fold 교차검증
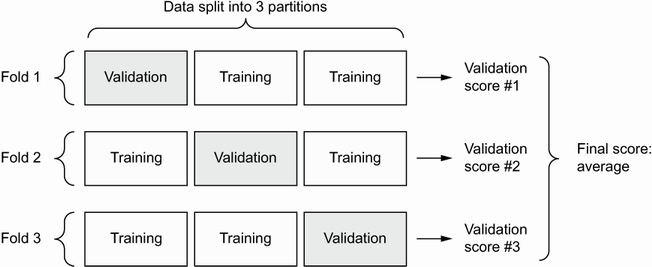
K-fold 교차검증
- 모델의 성능이 데이터 분할에 따라 편차가 클때 도움
- 데이터를 동일한 크기의 K개로 분할
- 최종점수는 K개의 점수를 평균
- 셔플링을 사용한 K-fold:
- 비교적 가용 데이터가 적고 가능한 한 정확하게 모델을 평가하고자 할 때 유용
- 분할 전 셔플을 통해 데이터를 무작위로 섞음
상식수준의 기준점 넘기
참고할 수 있는 상식수준의 기준점을 가져야 모델 평가시 적절한 점수의 범위를 알 수 있다.
모델 평가시 유의점
- 대표성 있는 데이터 사용:
- 데이터가 어느 한 쪽으로 편향 되지 않도록 데이터를 무작위로 섞는 것이 일반적
- 시간과 방향이 중요한 데이터:
- 무작위로 섞는 것 X
- 테스트 데이터는 훈련세트 데이터보다 무조건 미래의 것 사용
- 데이터 중복검증:
- 한 데이터포인트가 훈련 세트와 검증 세트에 중복되지 않게 하기 위해 항상 검증
일반화 성능 갖기+과대적합 해보기(훈련 성능 향상)
- 일반화 초기 목표: 약간의 일반화 능력 + 과대적합 가능한 모델
- 일반 상식수준의 기준점이 중요(적절한 적합치 필요)
- 문제점 발생 가능:
- 훈련이 되지 않음
- 의미있는 일반화가 되지 못함(상식수준의 기준점 도달x)
- 계속된 과소적합
- 문제 해결 방법:
1. 경사 하강법의 핵심 파라미터 튜닝
2. 모델 구조에 대해 더 나은 가정하기
3. 모델 용량 늘리기
1) 경사하강법 핵심 파라미터 튜닝
🔸 학습률과 배치크기 튜닝: mnist
- 학습률: 1
from keras.datasets import mnist
from keras.layers import Dense
import keras
(train_images, train_labels), _ = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
model = keras.Sequential([
Dense(512, activation="relu"),
Dense(10, activation="softmax")
])
model.compile(optimizer=keras.optimizers.RMSprop(1.),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
model.fit(train_images, train_labels,
epochs=10,
batch_size=128,
validation_split=0.2)
- 학습률: 0.01
model = keras.Sequential([
Dense(512, activation="relu"),
Dense(10, activation="softmax")
])
model.compile(optimizer=keras.optimizers.RMSprop(1e-2),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
model.fit(train_images, train_labels,
epochs=10,
batch_size=128,
validation_split=0.2)
- 학습률: 0.01/ 배치사이즈: 512
model = keras.Sequential([
Dense(512, activation="relu"),
Dense(10, activation="softmax")
])
model.compile(optimizer=keras.optimizers.RMSprop(1e-2),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
model.fit(train_images, train_labels,
epochs=10,
batch_size=512,
validation_split=0.2)
2) 구조에 대한 더 나은 가정하기
- 입력데이터에 정보가 충분하지 않을 수 있음
- 현재 사용하는 모델의 종류가 적합하지 않을 수 있음
- 작업의 종류에 적절한 구조가 무엇인지 모범사례 찾기
3) 모델 용량 늘리기: 과대적합해보기
- 과대적합은 항상 가능
- 과대적합이 되지 않았다면 아직 모델의 표현 능력representational power가 부족한 것
- 모델의 용량을 늘려야 함
- 층을 추가
- 층 크기를 늘리기
🔸 부족한 층과 층 크기 예시
from keras.datasets import mnist
from keras.layers import Dense
import keras
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype("float32") / 255
model = keras.Sequential([Dense(10, activation="softmax")])
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
history_small_model = model.fit(
train_images, train_labels,
epochs=20,
batch_size=128,
validation_split=0.2)import matplotlib.pyplot as plt
val_loss = history_small_model.history["val_loss"]
epochs = range(1, 21)
plt.plot(epochs, val_loss, "b--",
label="Validation loss")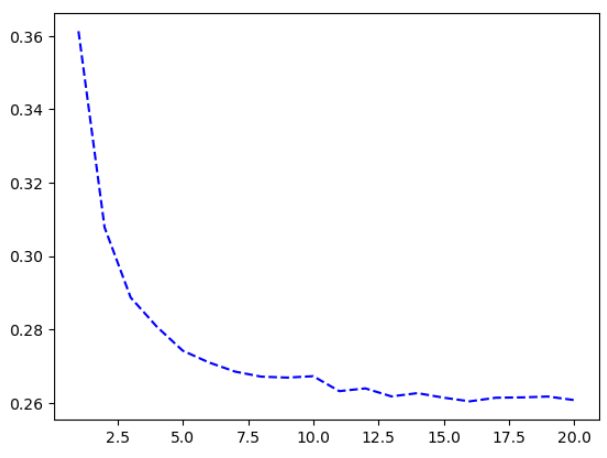
🔸 층과 층 크기 늘리기 예시
model = keras.Sequential([
layers.Dense(96, activation="relu"),
layers.Dense(96, activation="relu"),
layers.Dense(10, activation="softmax"),
])
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
history_large_model = model.fit(
train_images, train_labels,
epochs=20,
batch_size=128,
validation_split=0.2)val_loss = history_large_model.history["val_loss"]
epochs = range(1, 21)
plt.plot(epochs, val_loss, "b--",
label="Validation loss")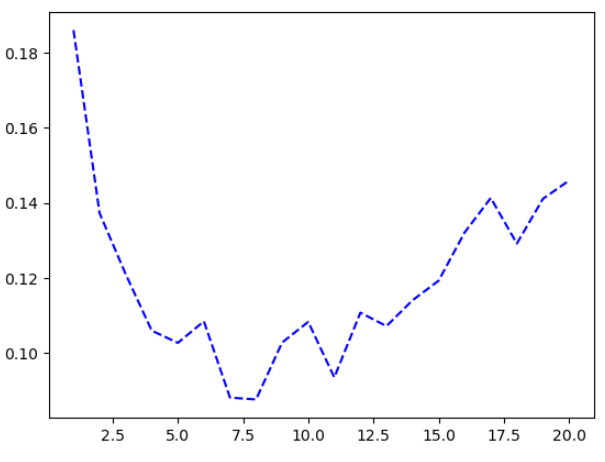
- epoch 8부터 과대적합됨
일반화 성능 향상
1) 데이터셋 큐레이션
- 입력된 데이터들을 사용하여 샘플들 사이를 부드럽게 보간할 수 있다
== 일반화 성능을 가진 딥러닝 모델 훈련 가능 - 적절한 데이터셋으로 작업하는 것이 중요!
- 조밀한 샘플링
- 대용량의 데이터셋
- 시각화로 이상치파악, 레이블 교정
- 데이터 정제와 누락값 처리
- 유용한 샘플활용을 위한 특성 선택
2) 특성공학
-
어떤 방식으로 데이터가 표현되어야 모델이 수월하게 작업할 수있는가에 대한 연구
-
특성을 더 간단한 방식을 표현하면 잠재 매니폴드를 더 매끄럽고, 간단하고, 구조적으로 만든다(문제가 쉬워짐)
-
좋은특성을 발견하면, 더 적은 지원으로, 더 적은 데이터로 충분히 문제를 잘 풀 수 있다.
3) 조기종료
- 모델을 끝까지 훈련하지 않고 훈련 중단
- 일반화 성능이 가장 높은 정확한 최적적합의 지점을 찾는 것이 중요
- 검증지표가 더이상 향상되지 않으면 훈련을 중지하고 그 전까지 최상의 검증 점수를 내 모델을 저장: 콜백(callback)사용
4) 모델 규제
- 과대적합을 피하기위해 모델의 능력 방해
- 적절한 모델의 용량이 중요
- 시작은 비교적 적은수의 층과 파라미터, 점진적으로 층과 유닛 개수를 늘림
🔸 가중치 규제 추가
L1규제: 절댓값에 비례하는 비용이 추가(영향력에 집중)
L2규제: 제곱에 비례하는 비용 추가
- 대부분의 딥러닝 모델은 파라미터가 너무 많아 가중치 값을 제어하여 큰 효과를 보기 힘들 수 있다.
🔸 드롭아웃 추가
-
모델 층(layer)에 드롭아웃 적용
-
무작위로 층의 출력을 일부 0으로 만들어 특성 제외

-
코드 예제
model = keras.Sequential([
layers.Dense(16, activation="relu"),
layers.Dropout(0.5),
layers.Dense(16, activation="relu"),
layers.Dropout(0.5),
layers.Dense(1, activation="sigmoid")
])
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
history_dropout = model.fit(
train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)정리
- 머신러닝 목적: 일반화
- 머신러닝의 문제: 최적화와 일반화 사이의 줄다리기
- 일반화 능력: 잠재 매니폴드를 근사하는 학습을 통해 보간이 가능하고 새로운 입력을 이해 가능한가
- 일반화를 위한 데이터분리: 훈련, 검증, 테스트(완전 새로운 데이터)
- 과소적합은 일반화가 가능하고 과대적합으로 갈 수 있도록 조정
- 특성공학, 조밀한 샘플링, 대용량 데이터셋, K-fold등의 방법
- 과대적합이 가능하고 일반화 성능을 보인다면 규제를 통해 일반화 성능 향상
- 조기종료, 가중치규제, 드롭아웃
