신경망 훈련의 진행
- 저수준 텐서연산, 텐서플로 API변환
- 텐서
- 텐서연산(relu,덧셈,matmul 등)
- 역전파(그레이디언트 계산)
- 고수준 딥러닝, 케라스 API변환
1. 모델 구성 (layers)
- layers: 가중치와 연산을 캡슐화하고, 이런 층을 조합하여 모델 생성
2. 모델 컴파일 (model.compile)
- 손실함수(loss): 피드백 신호 정의
- 옵티마이저(optimizer): 학습 진행방법 결정
- 측정지표설정(metrics): 모델 성능평가
3. 모델 적용(model.fit)
- 훈련루프 (epochs) 설정
텐서플로란?
- 수치 텐서에 대한 수학적 표현을 적용하게 함
- 넘파이와 매우 비슷
- 추가적으로 미분가능한 어떤 표현식에 대해서도 자동으로 그레이디언트를 계산
- CPU, GPU, TPU에서 실행가능
- 확장이 쉬움
케라스란?
- 텐서플로 위에 구축된 파이썬용 딥러닝 API로 모델을 쉽게 만들고, 훈련할 수 있다.
- 일관되고 간단한 워크플로를 제공
텐서플로
텐서플로 시작
🔸 상수텐서와 변수
x_ones = tf.ones(shape=(2,1))
x_zeros = tf.zeros(shape=(2,1))
x_normal = tf.random.normal(shape=(3,1),mean=0,stddev=1.)
x_uniform = tf.random.uniform(shape=(3,1), minval=0, maxval=1)print('ones:\n', x_ones)
print('\nzeros:\n', x_zeros)
print('\nnormal(정규분포랜덤):\n', x_normal)
print('\nuniform(균등분포랜덤):\n', x_uniform)
🔸 넘파이와 차이점
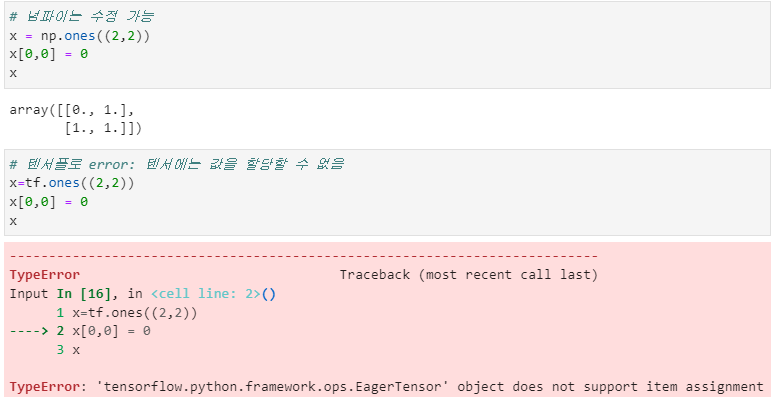
🔸 텐서플로로 변수 만들기: Variable
- Variable 만들기
v= tf.Variable(tf.random.normal((3,1)))
v
- assign으로 변수 수정
v.assign(tf.ones((3,1)))
- assign_add, assign_sub: 항상 shapem 맞추어야함
v.assign_add(np.array([[2.],[0],[0]]))
텐서플로의핵심: 그레이디언트 테이프
- 자동 미분 기능을 활용할 수 있는 API
- with문으로 GradientTape()를 사용
- tf.Variable은 변경가능한 상태를 담는 특별한 텐서(신경망의 가중치는 항상 tf.Variable)
🔸 초깃값 0으로 스칼라변수 생성
x = tf.Variable(0.)
with tf.GradientTape() as tape:
y = 2*x + 3
grad_y_x = tape.gradient(y,x)
print(grad_y_x)
tf.Tensor(2.0, shape=(), dtype=float32)
🔸 크기(2,2) 값 0
x = tf.Variable(tf.zeros((2,2)))
with tf.GradientTape() as tape:
y= 2*x + 3
grad_y_x = tape.gradient(y,x)
print(grad_y_x)tf.Tensor( [[2. 2.] [2. 2.]], shape=(2, 2), dtype=float32)
🔸 watch(): 추적한다는 것을 수동으로 알려주기
- 자원의 낭비를 막기 위해 테이프가 감시할 대상을 알아야 한다.
input_const = tf.constant(3.)
with tf.GradientTape() as tape:
tape.watch(input_const)
result=tf.square(input_const)
gradient = tape.gradient(result, input_const)
gradient
<tf.Tensor: shape=(), dtype=float32, numpy=6.0>
🔸 이계도 그래이디언트(그레이디언트의 그레이디언트 계산)
time = tf.Variable(5.)
with tf.GradientTape() as outer_tape:
with tf.GradientTape() as inner_tape:
position = 4.9 * time**2
speed = inner_tape.gradient(position, time) #4.9*2*time
acceleration = outer_tape.gradient(speed, time) #4.9*2print('speed:', speed)
print('acceleration:', acceleration)
🔸 변수 리스트 계산
W = tf.Variable(tf.random.uniform((2,2))) #가중치
b = tf.Variable(tf.zeros((2,))) #편향
x = tf.random.uniform((2,2)) #데이터
with tf.GradientTape() as tape:
y = tf.matmul(x,W) + b
grad_y_W_and_b = tape.gradient(y,[W,b])
print(grad_y_W_and_b)
텐서플로(저수준 텐서연산) 선형분류기
1) 텐서생성: inputs, targets
🔸 inputs
import numpy as np
num_samples_per_class = 1000
negative_samples = np.random.multivariate_normal(
mean=[0, 3],
cov=[[1, 0.5],[0.5, 1]],
size=num_samples_per_class)
positive_samples = np.random.multivariate_normal(
mean=[3, 0],
cov=[[1, 0.5],[0.5, 1]],
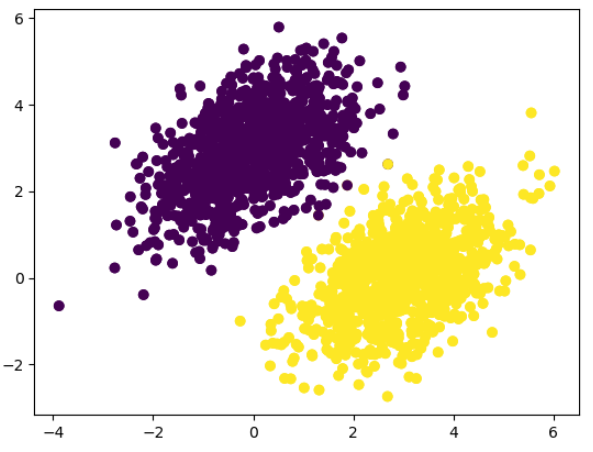
size=num_samples_per_class)- 각 (1000,2)크기의 배열을 수직 연결: inputs( 2000,2 ) 만들기
inputs = np.vstack((negative_samples, positive_samples)).astype(np.float32)🔸 targets: 0 혹은 1
targets = np.vstack((np.zeros((num_samples_per_class, 1), dtype="float32"),
np.ones((num_samples_per_class, 1), dtype="float32")))2) 텐서연산( 변수: 가중치,편향 )
input_dim = 2
output_dim = 1
W = tf.Variable(initial_value=tf.random.uniform(shape=(input_dim, output_dim)))
b = tf.Variable(initial_value=tf.zeros(shape=(output_dim,)))🔸 정방향 패스 함수: model
def model(inputs):
return tf.matmul(inputs, W) + b3) 손실함수, 그레이디언트 계산(가중치 업데이트)
# 평균제곱오차
def square_loss(targets, predictions):
per_sample_losses = tf.square(targets - predictions)
return tf.reduce_mean(per_sample_losses)learning_rate = 0.1
def training_step(inputs, targets):
with tf.GradientTape() as tape:
predictions = model(inputs)
loss = square_loss(targets, predictions)
grad_loss_W, grad_loss_b = tape.gradient(loss, [W, b])
W.assign_sub(grad_loss_W * learning_rate)
b.assign_sub(grad_loss_b * learning_rate)
return loss4) 훈련루프
for step in range(40):
loss = training_step(inputs, targets)
print(f"Loss at step {step}: {loss:.4f}")
5) 결과 시각화
import matplotlib.pyplot as plt
plt.scatter(inputs[:, 0], inputs[:, 1], c=targets[:, 0])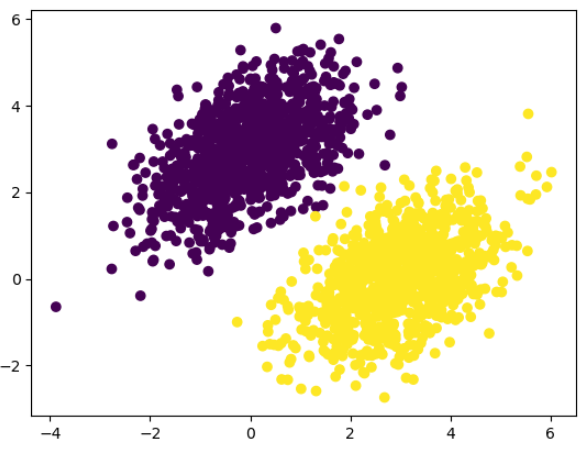
predictions = model(inputs)
#타깃이 0또는 1이므로 예측값이 0.5보다 작으면 0, 크면 1
plt.scatter(inputs[:, 0], inputs[:, 1], c=predictions[:, 0] > 0.5)