텐서플로로 MNIST 다시 구현
모델생성하기
1) 단순한 Dense클래스
class NaiveDense:
def __init__(self, input_size, output_size, activation):
self.activation = activation
w_shape = (input_size, output_size)
w_initial_value = tf.random.uniform(w_shape, minval=0, maxval=1e-1)
self.W = tf.Variable(w_initial_value)
b_shape = (output_size,)
b_initial_value = tf.zeros(b_shape)
self.b = tf.Variable(b_initial_value)
def __call__(self, inputs):
return self.activation(tf.matmul(inputs, self.W)+self.b)
@property
def weights(self):
return [self.W, self.b]- @: annotation,decorator
- @property
- 변수를 변경 할 때 어떠한 제한을 둘 수 있음
- get,set 함수를 만들지 않고 더 간단하게 접근(좀 더 간결하고 읽기 편하게 작성)
- 하위호환성에 도움
- 이해를 돕기위한 코딩 다른 방법
self.W = tf.Variable(tf.random.uniform(shape=((input_size, output_size)), minval=0, maxval=1e-1))
self.b = tf.Variable(tf.zeros(shape=((output_size, ))))2) 단순한 Sequential클래스
class NaiveSequential:
def __init__(self, layers):
self.layers = layers
def __call__(self, inputs):
x=inputs
for layer in self.layers:
x = layer(x)
return x
@property
def weights(self):
weights = []
for layer in self.layers:
weights += layer.weights
return weights3) 모델 생성
model = NaiveSequential([
NaiveDense(input_size=28*28, output_size=512, activation=tf.nn.relu),
NaiveDense(input_size=512, output_size=10, activation=tf.nn.softmax)
])
assert len(model.weights) == 4- assert (가정 설정문)은 어떤 조건이 True임을 보증하기 위해서 사용하는 것
- assert [조건], [오류메시지]
4) 참고: __call__()의 역할
class Test:
def __call__(self, num):
if num == 1:
print('hello')
else:
raise
test = Test()
test(1)
hello
배치 제너레이터
import math
class BatchGenerator:
def __init__(self, images, labels, batch_size=128):
assert len(images) == len(labels)
self.index = 0
self.images = images
self.labels = labels
self.batch_size = batch_size
self.num_batches = math.ceil(len(images) / batch_size)
def next(self):
images = self.images[self.index : self.index + self.batch_size]
labels = self.labels[self.index : self.index + self.batch_size]
self.index += self.batch_size
return images, labels훈련스텝 실행
1) optimizer인스턴스 사용
from tensorflow.keras import optimizers
optimizer = optimizers.SGD(learning_rate=1e-3)
def update_weights(gradients, weights):
optimizer.apply_gradients(zip(gradients, weights))2) GradientTape을 활용한 그래이언트 계산과 손실값계산
def one_training_step(model, images_batch, labels_batch):
with tf.GradientTape() as tape:
# 1. 이미지 예측 계산
predictions = model(images_batch)
# 2. 실제레이블로 손실값 계산
per_batch_losses = tf.keras.losses.sparse_categorical_crossentropy(
labels_batch, predictions)
average_loss = tf.reduce_mean(per_batch_losses) # (y)loss_value
# 3. 손실의 그레이디언트 계산
gradients = tape.gradient(average_loss, model.weights) # (x)model.weight에 있는 가중치 리스트
# 4. 가중치 업데이트
update_weights(gradients, model.weights)
return average_loss3) 참고: 가중치 업데이트 함수화 (수동 구현)
각 가중치 - (gradient * learning_rate)
def update_weights(gradients, weights):
for g, w in zip(gradients, weights):
w.assign_sub(g * learning_rate) # assign_sub는 -=과 동일전체 루프 훈련
1) 훈련 함수
def fit(model, images, labels, epochs, batch_size=128):
for epoch_counter in range(epochs):
print(f"Epoch {epoch_counter}")
batch_generator = BatchGenerator(images, labels)
for batch_counter in range(batch_generator.num_batches):
images_batch, labels_batch = batch_generator.next()
loss = one_training_step(model, images_batch, labels_batch)
if batch_counter % 100 == 0:
print(f"loss at batch {batch_counter}: {loss:.2f}")2) mnist데이터 훈련
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype("float32") / 255
fit(model, train_images, train_labels, epochs=10, batch_size=128)모델 평가
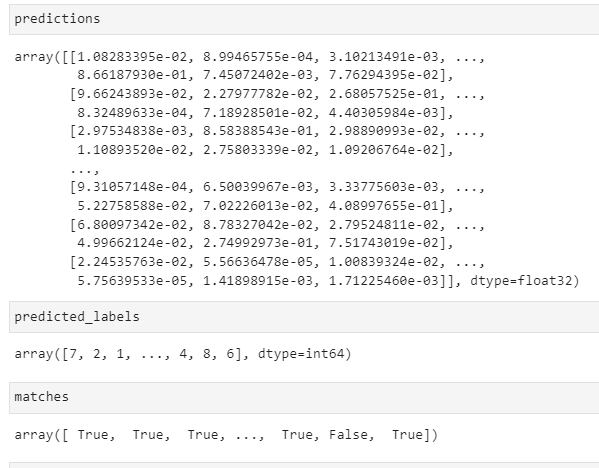
predictions = model(test_images)
predictions = predictions.numpy()
predicted_labels = np.argmax(predictions, axis=1)
matches = predicted_labels == test_labels
print(f"accuracy: {matches.mean():.2f}")
accuracy: 0.82
🔸 참고