합성곱 신경망(convolutional neural network)
= 컨브넷(Convnet)
- 대부분의 컴퓨터 비전 애플리케이션에 사용
- 함수형 API사용
- 데이터의 특징을 추출하여 특징들의 패턴을 파악하는 구조
- CNN 알고리즘은 Convolution과정과 Pooling과정을 통해 진행
- 컨브넷은 배치차원을 제외하고(height, width, channel)텐서 사용
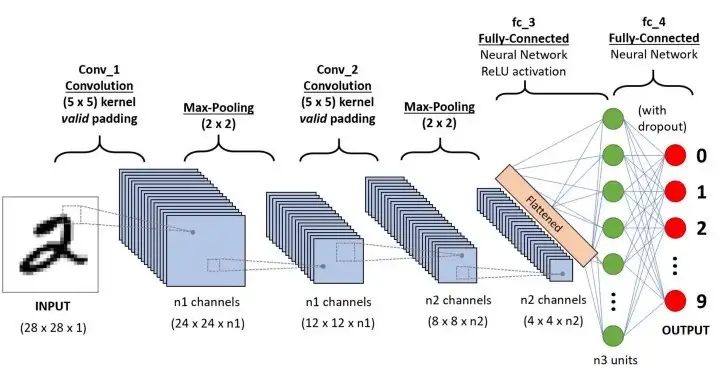
🔸 mnist로 컨브넷(+풀링) 살펴보기
import keras
from keras.datasets import mnist
from keras import layers
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype("float32") / 255
#----------------------------------#
inputs = keras.Input(shape=(28, 28, 1))
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(inputs) # == kernel_size=(3,3)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x)
x = layers.Flatten()(x)
outputs = layers.Dense(10, activation="softmax")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
#----------------------------------#
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
model.fit(train_images, train_labels, epochs=5, batch_size=64)model.summary()
- height, width는 모델이 깊어질수로 작아짐
- 채널의 수는 전달된 filter(첫번째 매개변수)수에 따라 조절
- 출력이 랭크-3텐서이므로 Dense 층 이전에 Flatten층으로 변환
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f"Test accuracy: {test_acc:.3f}")
Test accuracy: 0.992
합성곱 연산(Convnet)
-
Dense는 전역패턴(global)학습, Convnet은 지역패턴(local) 학습
-
학습된 패턴은 평행이동 불변
-
공간적 계층구조 학습
- 특성맵-응답맵:
- 입력(height,width,channel)에서 특성
- 출력(height,width,filter)으로 응답
- 특성 맵에 커널(kernel) 혹은 필터(Filter)라 불리는 정사각 행렬을 적용하며 합성곱 연산을 수행
- 입력과 출력의 높이,너비는 다를 수 있음(패딩으로 대응, 스트라이드 사용여부)
- 특성맵-응답맵:
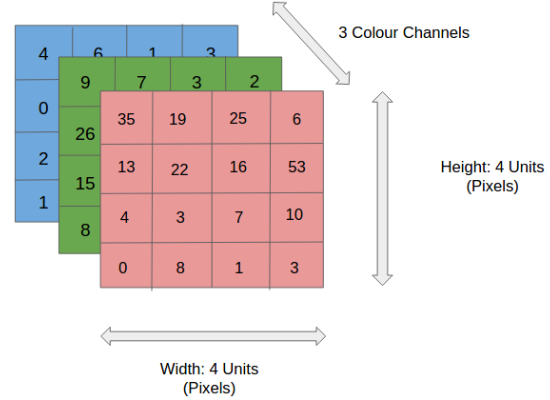
🔸 특성맵 입력
🔸 특성맵 출력 = 응답맵
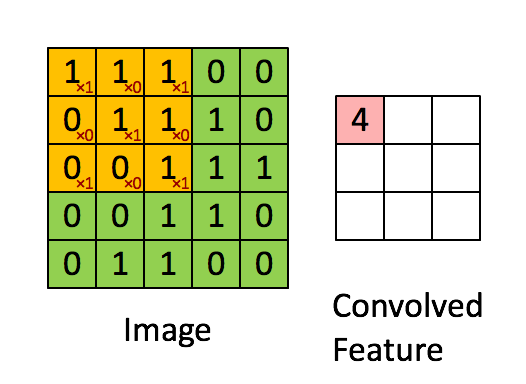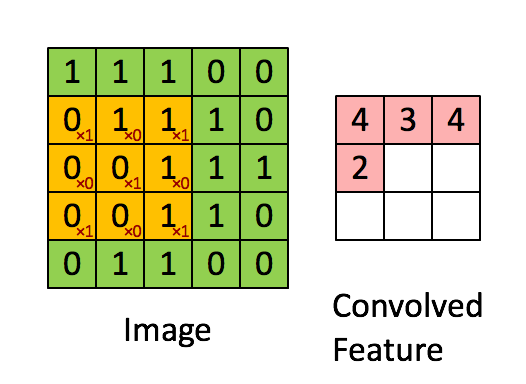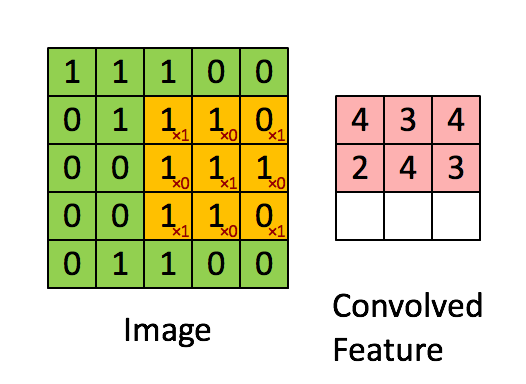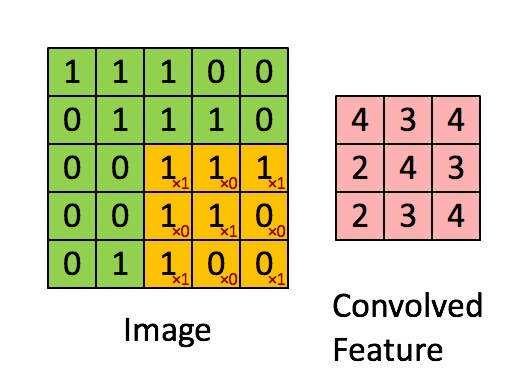
-
합성곱으로 특성추출(위의 화면에서 convolved feature)한 filter가 model의 Conv2D에서 설정한 개수만큼 존재 = 합성곱커널(convolution kernel)
-
패치: 3x3 혹은 5x5의 크기의 윈도우가 특성맵 위를 슬라이딩하면서 특성을 추출할 때, 추출 값을 지닌 한 장의 필터
🔸 Conv2D층
layers.Conv2D(
filters,
kernel_size,
strides=(1, 1),
padding='valid',
activation=None,
use_bias=True,- filters: 패치 개수
- kernel_size: 패치(윈도우) 사이즈
- padding: [valid,same]
- activation: 활성화 함수
- use_bias: 편향사용여부[True, False]
필터
- 커널
- 필터의 사이즈는 '거의 항상 홀수'
- 짝수이면 패딩이 비대칭이 되어버림
- 중심위치가 존재, 즉 구별된 하나의 픽셀(중심 픽셀)이 존재 = 위치정보
- 필터의 학습 파라미터 개수는 입력 데이터의 크기와 상관없이 일정, 따라서 과적합을 방지할 수 있음
패딩
- 위의 그림에서는 합성곱연산을 통해 높이와 너비가 줄어드는 것을 확인할 수 있다.
- 이를 방지하고 입력과 동일한 높이와 너비를 가진 출력특성맵을 얻고 싶다면 패딩(padding)을 추가하면 된다.
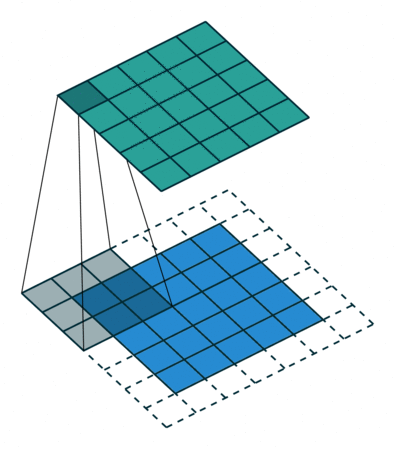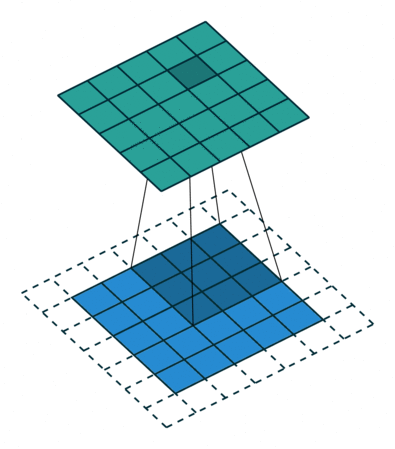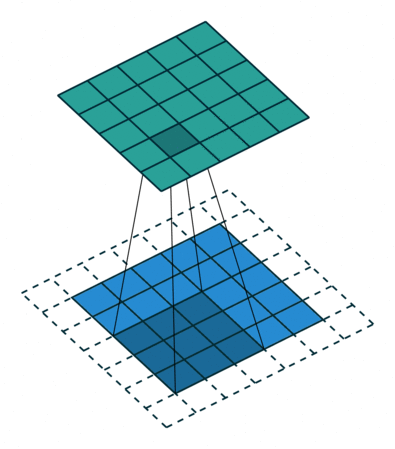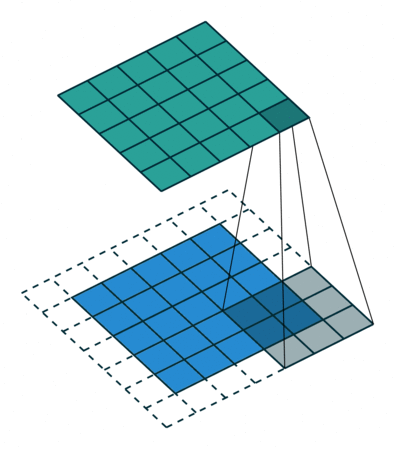
- model의 Conv2D층에서 매개변수로 설정 가능
- valid : 패딩사용x
- same : 입력과 동일한 높이, 너비를 위해 패딩
스트라이드
두 번의 연속적인 윈도우 사이의 거리

- 커널(패치사이즈)과 스트라이드의 경우 크기가 클 수 록 좀 더 빨리 이미지를 처리할 수 있지만, 넓은 특성을 큰 보폭으로 이동하는 만큼 주요 특성을 놓칠 수 있다는 단점이 존재
참고: Relu 활성화 함수
- Sigmoid 함수의 경우:
- 값을 0 ~ 1사이로 정규화
- 레이어가 깊어질수록 0.xxx의 값이 계속 미분되게 되면 값이 점차 0으로 수렴할 수 있음
- weight값이 희미해지는 그레이디언트 소실( gradient vanishing ) 문제가 발생가능.
- ReLU의 경우:
- 0미만의 값은 0으로 출력하고 0이상의 값은 그대로 출력
- 깊은 레이어에서도 효율적인 역전파(Back Propagation)가 가능
이러한 이유로 합성곱 연산을 통해 출력된 특성맵(feature map)의 경우 일반적으로 ReLU 활성화 함수를 거치게 되며, ReLU 함수가 양의 값만을 활성화하여 특징을 좀 더 두드러지게 표현한다.
Pooling
합성곱층(Convolutional Layer)과 유사하게 특성맵(feature map)의 차원을 다운 샘플링하여 연산량을 감소시키고 주요한 특징 벡터를 추출하여 학습을 효과적으로 하는 것
🔸 pooling을 하지 않으면?
- 공간적 계층 구조를 학습하는 데 도움이 되지 않는다. 초기입력의 윈도우 영역에 대한 정보만 가짐
- 최종 특성맵의 가중치 파라미터가 너무 많아져 심각한 과대적합 가능
🔸 pooling 종류
- Max Pooling: 각 커널에서 다루는 이미지 패치에서 최대값을 추출
- 보통 윈도우 2x2, 스트라이드 2
- Average Pooling: 각 커널에서 다루는 이미지 패치에서 모든 값의 평균을 반환
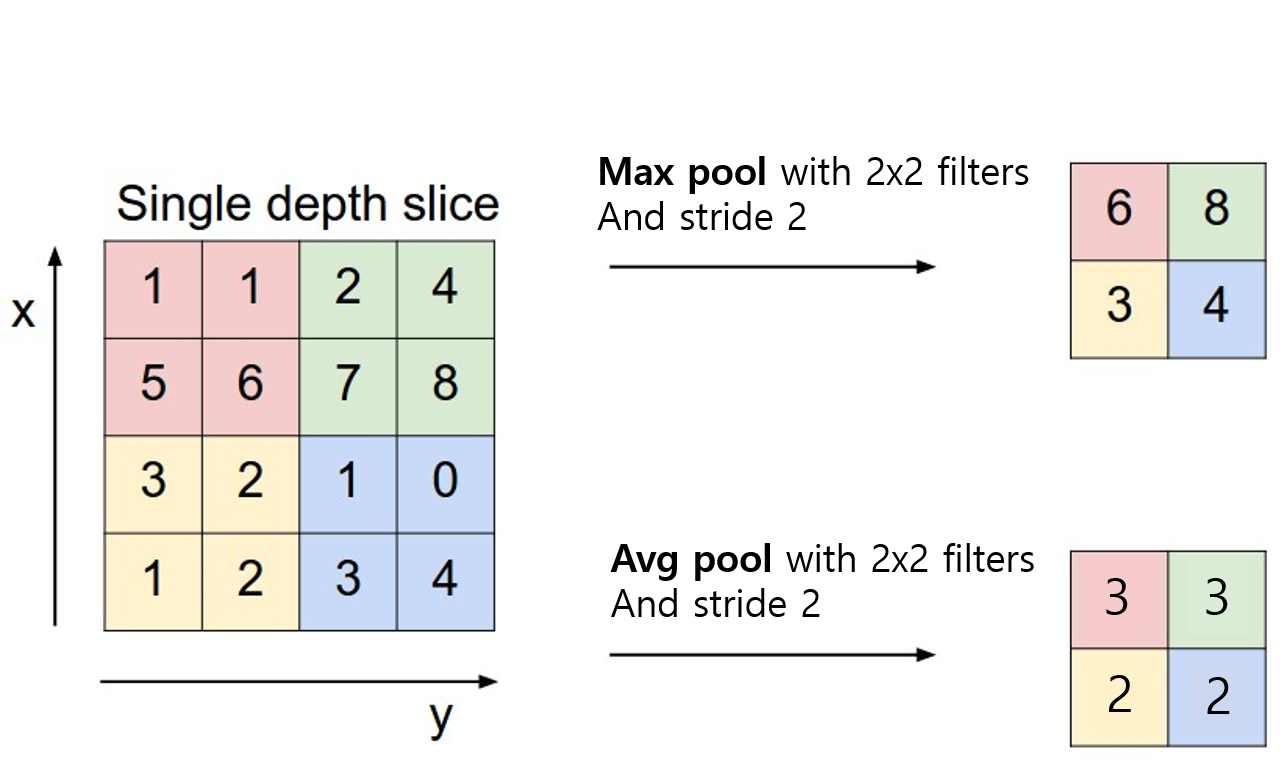
🔸 대부분의 ConvNet에서는 Avg Pooling이 아닌 Max Pooling 사용: 평균으로 할 경우 주요한 가중치를 갖는 value의 특성이 희미해질 수 있음
Fully Connected Layer연결
- 차원이 축소 된 특성맵(feature map)은 최종적으로 Fully Connected Layer라는 완전 연결 층으로 전달
- Flatten: 3차원 벡터를 1차원으로
소규모 데이터셋으로 컨브넷 훈련예제(이미지 분류): cat vs dog
1. 데이터 내려받기
https://www.kaggle.com/competitions/dogs-vs-cats/data
🔸 colab 이용
- 다운로드
import gdown
url = "https://drive.google.com/uc?id=1ipzN9okFFT3oieklsrfr6iUHzjPAbT9i"
gdown.download(url, "cats_and_dogs.tar")
!tar -xvf cats_and_dogs.tar- 캐글 API로 다운로드
# 1. 캐글사용하기
!pip install kaggle --upgrade
# 2. 캐글사이트>Account>API>Create New API Token( 참고로 약관동의가 필요하므로 www.kaggle.com/c/dogs-vs-cats/rules에서 약관동의 후 API 다운로드하기)
# 3. API 다운로드한거 코랩에 업로드: 파일선택
from google.colab import files
files.upload()
# 4. (!mkdir).kaggle폴더만들기 (!cp)파일복사 (!chmod 600)보안설정
!mkdir ~/.kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
# 5. 데이터 내려받기 실행
!kaggle competitions download -c dogs-vs-cats
# 6. 압축 해제
!unzip -qq dogs-vs-cats.zip
!unzip -qq train.zip2. 데이터를 각각의 디렉터리로 분리(훈련/검증/테스트)
- pathlib 모듈
- 파일, 디렉토리의 경로를 객체로서 조작하거나 처리
- 파일명 혹은 부모 디렉토리를 알아내거나 경로의 목록을 얻어내거나 파일을 작성하거나 삭제하는 등 대략적인 파일 관련된 처리가능
import os,shutil,pathlib
original_dir = pathlib.Path('./data/train')
new_base_dir = pathlib.Path('./data/cats_vs_dogs')def make_subset(subset_name, start_index, end_index):
for category in ('cat','dog'):
dir = new_base_dir / subset_name / category
os.makedirs(dir)
fnames = [f'{category}.{i}.jpg' for i in range(start_index, end_index)]
for fname in fnames:
shutil.copyfile(src= original_dir / fname, dst= dir / fname)- 'cats_vs_dogs'폴더에 'subset_name'의 폴더 생성
- 그 아래 'cat','dog'폴더 생성
- 원본파일에서 파일 이름이 (ex)cat.123, dog.1234 것을 복사하여 각각의 폴더 카테고리에 맞춰 저장
make_subset('train', start_index = 0, end_index = 1000)
make_subset('validation', start_index = 1000, end_index = 1500)
make_subset('test', start_index = 1500, end_index = 2500)🔸 다른 방법
train_dir = './cats_and_dogs/train'
validation_dir = './cats_and_dogs/validation'
test_dir = './cats_and_dogs/test' import os
# 훈련용 고양이 사진 디렉터리
train_cats_dir = os.path.join(train_dir, 'cats')
# 훈련용 강아지 사진 디렉터리
train_dogs_dir = os.path.join(train_dir, 'dogs')
# 검증용 고양이 사진 디렉터리
validation_cats_dir = os.path.join(validation_dir, 'cats')
# 검증용 강아지 사진 디렉터리
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
# 테스트용 고양이 사진 디렉터리
test_cats_dir = os.path.join(test_dir, 'cats')
# 테스트용 강아지 사진 디렉터리
test_dogs_dir = os.path.join(test_dir, 'dogs')3. 데이터 전처리: keras.utils.image_dataset_from_directory
- 사진 파일을 읽기
- JPEG를 RGB 픽셀값으로 디코딩
- 소수점타입 텐서변환
- 동일크기 이미지로 전환
- 배치로 묶음
from keras.utils import image_dataset_from_directory
train_dataset = image_dataset_from_directory(new_base_dir / 'train',
image_size=(180,180),
batch_size=32)
validation_dataset = image_dataset_from_directory(new_base_dir / 'validation',
image_size=(180,180),
batch_size=32)
test_dataset = image_dataset_from_directory(new_base_dir / 'test',
image_size=(180,180),
batch_size=32)
🔸 다른 방법
import keras
import scipy
from keras import layers
from keras.preprocessing.image import ImageDataGenerator
# 모든 이미지를 1/255 부동소수점으로 스케일을 조정
train_datagen = ImageDataGenerator(rescale=1./255)
validation_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir, # 타깃 디렉터리
target_size=(150, 150), # 모든 이미지를 150 × 150 크기로
batch_size=20, # 20개씩 배치로 생산
class_mode='binary') # 이진 레이블. 만약 다중클래스라면 'categorical'
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')4. 모델생성
inputs= keras.Input(shape=(180,180,3))
x = layers.Rescaling(1./255)(inputs) #스케일 조정
x = layers.Conv2D(filters=32, kernel_size=3, activation='relu')(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation='relu')(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation='relu')(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation='relu')(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation='relu')(x)
x = layers.Flatten()(x)
outputs = layers.Dense(1, activation='sigmoid')(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])model.summary()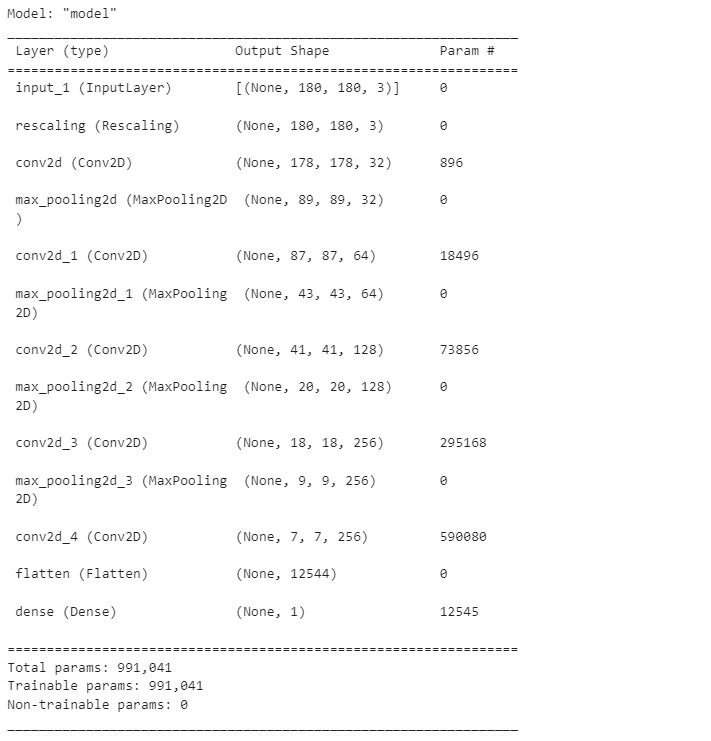
5. 모델훈련(콜백사용)
callbacks = [keras.callbacks.ModelCheckpoint(
filepath='convnet_from_scratch.keras',
save_best_only=True,
monitor='val_loss')]
history = model.fit(train_dataset, epochs=30,
validation_data=validation_dataset,
callbacks=callbacks)🔸 그래프로 확인
import matplotlib.pyplot as plt
accuracy = history.history["accuracy"]
val_accuracy = history.history["val_accuracy"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(1, len(accuracy) + 1)
plt.plot(epochs, accuracy, "bo", label="Training accuracy")
plt.plot(epochs, val_accuracy, "b", label="Validation accuracy")
plt.title("Training and validation accuracy")
plt.legend()
plt.figure()
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.legend()
plt.show()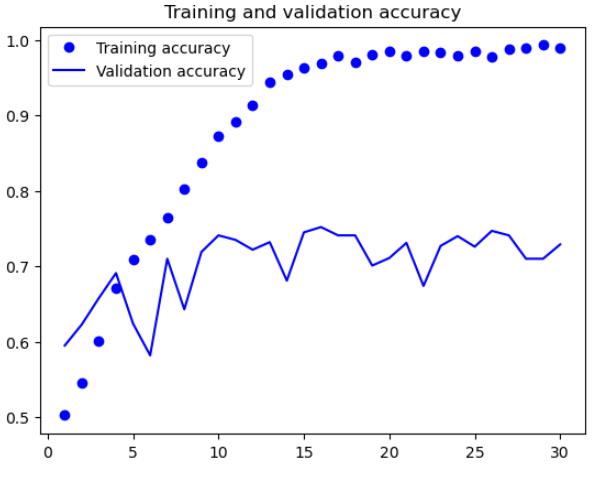
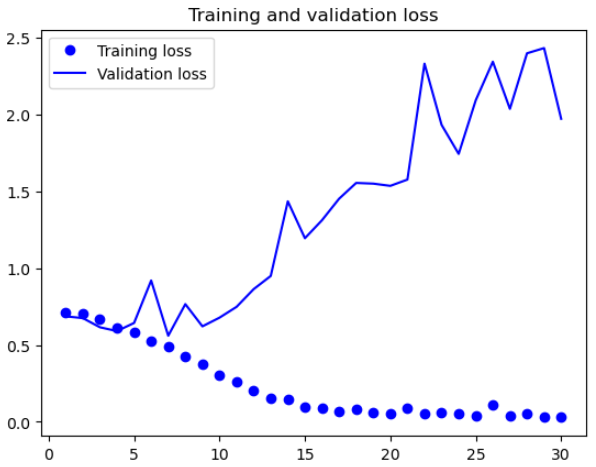
🔸 모델평가
test_model = keras.models.load_model('convnet_from_scratch.keras')
test_loss, test_acc = test_model.evaluate(test_dataset)
print(f'정확도: {test_acc:.3f}')
정확도: 0.702
6. 과대적합 피하기: 데이터 증식하기
- 비교적 훈련샘플의 개수가 적기 때문에 과대적합이 가장 중요한 문제
- 이미지를 다룰때 사용하는 방법: 데이터 증식
- 데이터 증식층(data augmentation layer) 추가
🔸 Sequential모델로 데이터 증식층 정의
data_augmentation = keras.Sequential([
layers.RandomFlip('horizontal'),
layers.RandomRotation(0.1),
layers.RandomZoom(0.2)
])- RandomFlip('horizontal'): 랜덤하게 50% 이미지를 수평으로 뒤집기
- RandomRotation(0.1):-10%,+10% 범위 안에서 랜덤한 값만큼 입력이미지 회전
- RandomZoom(0.2): -20%,+20% 범위 안에서 랜덤한 비율만큼 이미지 확대,축소
- 참고: 사진 확인
plt.figure(figsize=(10,10))
for image, _ in train_dataset.take(1):
for i in range(9):
a_image = data_augmentation(image)
ax = plt.subplot(3,3,i+1)
plt.imshow(a_image[0].numpy().astype('uint8'))
plt.axis('off')
🔸 모델 재 정의(데이터증식+Dropout)
inputs= keras.Input(shape=(180,180,3))
x = data_augmentation(inputs) #데이터증식
x = layers.Rescaling(1./255)(inputs)
x = layers.Conv2D(filters=32, kernel_size=3, activation='relu')(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation='relu')(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation='relu')(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation='relu')(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation='relu')(x)
x = layers.Flatten()(x)
x = layers.Dropout(0.5)(x) #과대적합 더 억제
outputs = layers.Dense(1, activation='sigmoid')(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])🔸 모델 재 훈련
callbacks = [keras.callbacks.ModelCheckpoint(
filepath="convnet_from_scratch_with_augmentation.keras",
save_best_only=True,
monitor="val_loss")]
history = model.fit(
train_dataset,
epochs=40, #교재는 100
validation_data=validation_dataset,
callbacks=callbacks)🔸 모델 평가
test_model = keras.models.load_model('convnet_from_scratch_with_augmentation.keras')
test_loss, test_acc = test_model.evaluate(test_dataset)
print(f'정확도: {test_acc:.3f}')
정확도: 0.729
→ 참고: epochs=100으로 했을때(교재), 약 90%
** 이미지 출처
