합성곱 신경망(ConvNet, Convolutional Neural Network)

Intro
현재 ConvNet 기반의 모델은 단순 이미지 인식을 넘어 Object Detection, Semantic Segmentation 까지 딥러닝 알고리즘 중 가장 활발히 연구되고 성과를 내고 있는 분야이다. 우선 각 분야별 적용되고 있는 주요 모델을 간단히 살펴보면 아래와 같다.
Classification Image Detection Semantic Segentation VGG Net RCNN FCN GoogLeNet Fast RCNN DeepLab ResNet Faster RCNN U-Net MobileNet YOLO ReSeg ShuffleNet SDD
이 글에서는 위의 훌륭한 모델들이 가장 기본으로 하는 ConvNet의 구조 및 학습 방법에 대해 간단히 알려보려고 한다.
합성곱 신경망(Convolutional Neural Network, ConvNet)
합성곱 신경망은 합성곱 연산을 사용하는 신경망 중 하나로서, 주로 음성 인식이나 시각적 이미지를 분석하는데 사용된다. 합성곱 신경망이 일반 신경망과 다른 점은 일반적인 신경망들이 이미지 데이터를 원본 그대로 1차원 신경망인 Fully-Connected layer(FC layer 혹은 Dense layer)에 입력되어 전체 특성을 학습하고 처리하는 데 반해, 합성곱 신경망은 FC layer를 거치기 전에 Convolution 및 Poolling과 같은 데이터의 주요 특징 벡터를 추출하는 과정을 거친 후 FC layer로 입력되게 된다.
그렇기 때문에 대부분의 이미지 인식 분야는 딥러닝 기반의 합성곱 신경망이 주를 이루고 있다.
ConvNet의 구조
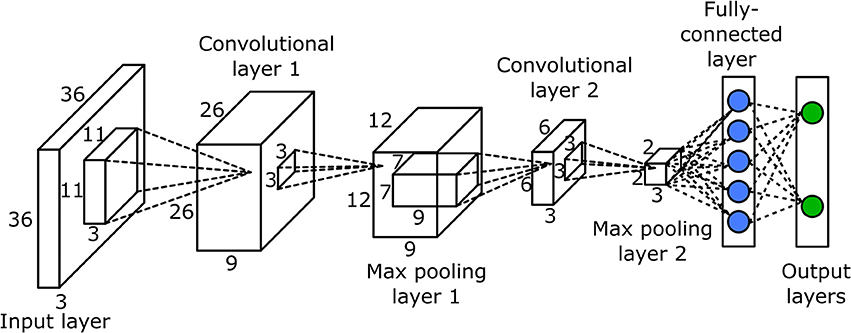
합성곱 신경망은 기본적으로 위와 같은 구조로 이루어져 있다. 위 ConvNet을 크게 3덩어리로 짤라서 보면 아래와 같다.
1. Input layer
2. Convolutional layer ~ Max pooling layer
3. Fully-connected layer ~ Output layers로
위 구조를 간단히 설명하면 위에서도 말했듯이 ConvNet은 단순 FC Layer로만 구성되어 있지 않다. Convolutional Layer와 Pooling Layer라는 과정을 거치게 되는데 이는 Input Image의 주요 특징 벡터를 추출하는 과정이라고 할 수 있다. 그 후 이렇게 추출된 주요 특징 벡터들은 그제야 FC Layer를 거치며 1차원 벡터로 변환되고 마지막 Output layer에서 활성화 함수인 Softmax함수를 통해 각 해당 클래스의 확률로 출력되게 된다. 아래에서 각 과정을 좀 더 상세히 살펴보겠다.
1. Input Layer
Input Layer는 입력된 이미지 데이터가 최초로 거치게 되는 Layer이다. 모두가 알고 있듯이 이미지는 단순 1차원의 데이터가 아니다. 이미지는 기본적으로 (높이, 넓이, 채널)의 크기를 갖는 3차원의 크기를 가지며, 여기서 채널(channels)의 경우 Gray Scale(1)이냐 RGB(3)이냐 에 따라 크기가 달라지게 된다. (채널의 컬러 공간은 Gray, RGB, HSV, CMYK 등 다양하다)
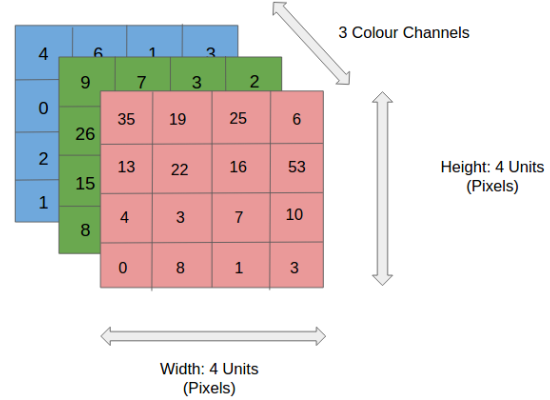
위와 같은 형태는 높이 4, 넓이 4, 채널 RGB를 갖고 있으므로 위 이미지의 shape은 (4, 4, 3)으로 표현할 수 있으며,
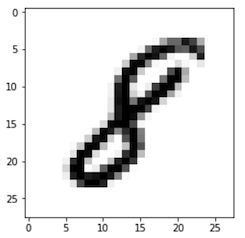
이미지 인식의 교과서라 할 수 있는 위 MNIST 손글씨 데이터 셋의 경우 높이 28, 넓이 28, 채널 Gray를 가지고 있으므로 (28, 28, 1)의 shape을 가졌다고 말할 수 있다. 또한 다른 말로 특성 맵(Feature Map)이라고도 한다.
2. Convolutional Layer
Convolutional Layer와 FC Layer의 경우 근본적은 차이가 존재하는데, Dense 층의 경우 특성 공간에 있는 전역 패턴(입력된 이미지의 모든 픽셀에 걸친 패턴)을 학습하는 반면 합성곱 층의 경우 지역 패턴을 학습하게 된다.
2.1 kernel
Convolutional Layer에서는 Input Image의 크기인 특성 맵(Feature Map)을 입력으로 받게 되는데 지역 패턴 학습을 위하여 이러한 특성 맵에 커널(kernel) 혹은 필터(Filter)라 불리는 정사각 행렬을 적용하며 합성곱 연산을 수행하게 된다.
커널의 경우 3 x 3, 5 x 5크기로 적용되는 것이 일반적이며 스트라이드(Stride)라고 불리는 지정된 간격에 따라 순차적으로 이동하게 된다.
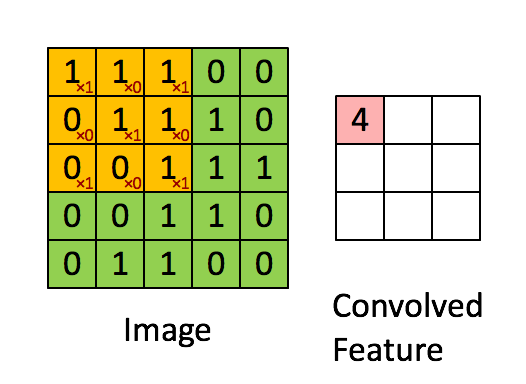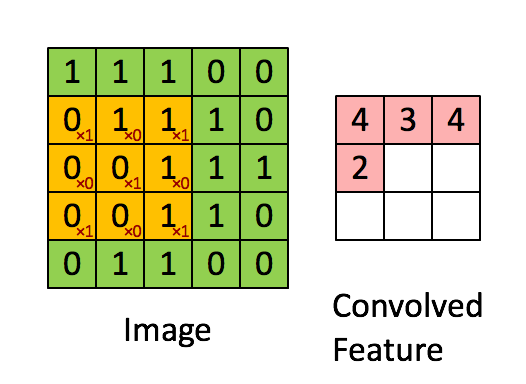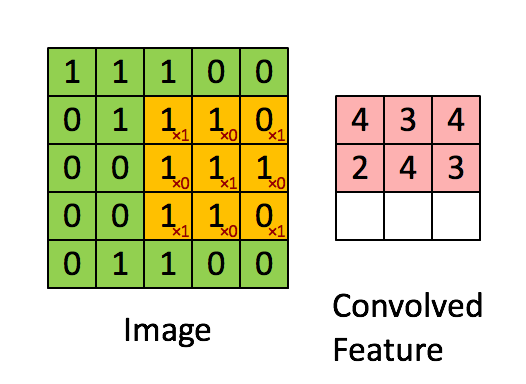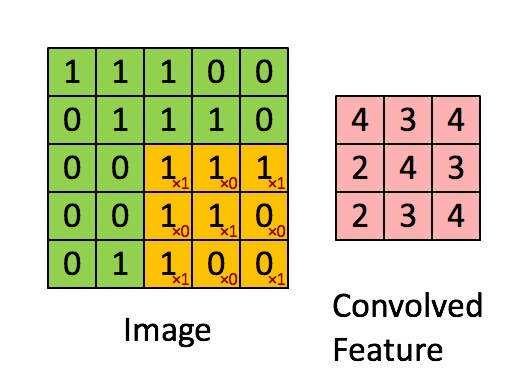
위 그림의 경우 Image의 크기는 (5, 5, 1)의 크기를 가지고 있으며, 현재 3 x 3크기의 kernel이 1 Stride의 간격으로 이동하며 합성곱 연산을 수행하는 것을 보여준다. 만약 커널이 2개의 크기만큼 이동하고 있다면 2 Stride 간격으로 이동한다고 할 수 있다.
이렇게 커널은 스트라이드 간격만큼 순회하며 모든 채널의 합성곱의 합을 새로운 특성 맵으로 만들게 되며, 결국 위 그림의 경우 커널과 스트라이드의 상호작용으로 인해 원본 (5, 5, 1) 크기의 Feature Map아 (3, 3, 1)크기의 Feature Map의 크기로 줄어들게 되었다.
커널과 스트라이드의 경우 크기가 클 수 록 좀더 빨리 이미지를 처리할 수 있지만, 넓은 특성을 큰 보폭으로 이동하는 만큼 주요 특성을 놓칠 수 있다는 단점이 존재한다.
2.2 Padding
합성곱 연산을 수행할 경우 단점이 존재하는데, 바로 위에서 살펴보았듯이 kernel과 stride의 작용으로 인해 원본 크기가 줄어든다는 것이다. 따라서 이렇게 Feature Map의 크기가 작아지는 것을 방지하기 위해서 Padding이란 기법을 이용하게 되는데, 쉽게 말해 단순히 원본 이미지에 0이라는 padding값을 채워 넣어 이미지를 확장한 후 합성곱 연산을 적용하는 것을 말한다.
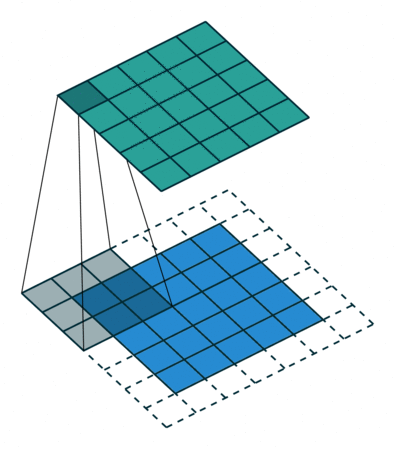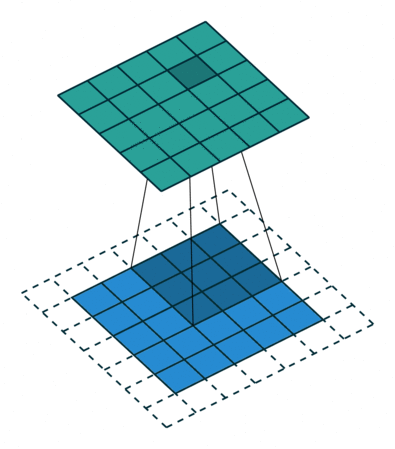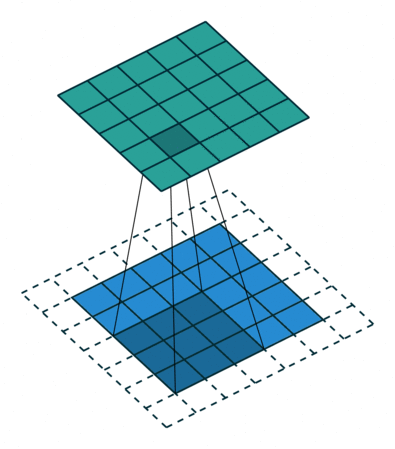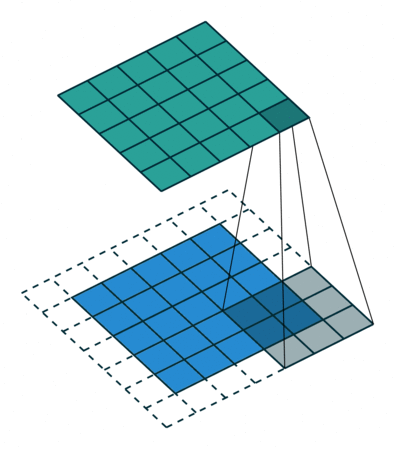
위 그림을 보면 위에서 살펴본 바와 같이 똑같은 (5, 5, 1)크기의 이미지 데이터가 놓여있다. 다른 점은 사방으로 빈 공간(0)이 1칸씩 더 채워져 있다는 것인데 이것이 바로 padding이다. 이후 위와 똑같은 3 x 3 크기의 커널을 적용하게 되는데 출력되는 feature map의 크기는 (3, 3, 1)이 아닌 원본 이미지와 똑같은 (5, 5, 1)크기의 feature map이다.
이렇듯, 원본 이미지의 크기를 줄이지 않으면서 합성곱 연산을 수행가능하게 해주는 것이 바로 padding의 역할이라고 할 수 있다.
2.3 ReLU Activation Function
합성곱 연산을 거친 Feature Map은 활성화 함수를 거치게 되는데, 많은 활성화 함수 중 가장 널리 사용되고 있는 것은 ReLU 함수 이다.
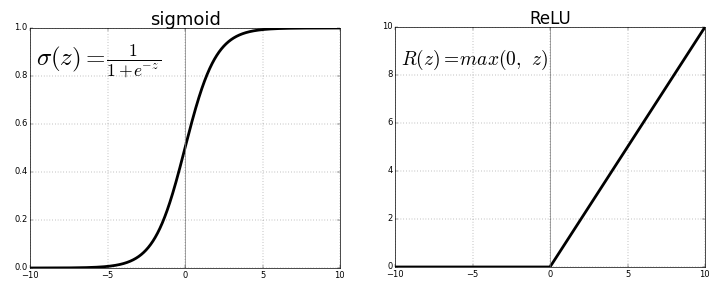
일반적으로 Sigmoid 함수의 경우 값을 0 ~ 1사이로 정규화시키는데 레이어가 깊어질 수 록 0.xxx의 값이 계속 미분되게 되면 값이 점차 0으로 수렴하게 되어 결국 weight값이 희미해지는 gradient vanishing문제가 발생하게 된다.
하지만 ReLU의 경우 0미만의 값은 0으로 출력하고 0이상의 값은 그대로 출력하기 때문에 이러한 문제에 덜 민감하고 그렇기 때문에 깊은 레이어에서도 효율적인 역전파(Back Propagation)가 가능하다.
이러한 이유로 합성곱 연산을 통해 출력된 feature map의 경우 일반적으로 ReLU 활성화 함수를 거치게 되며, ReLU 함수가 양의 값만을 활성화하며 특징을 좀 더 두드러지게 표현해주게 된다.
3. Pooling Layer
Convolutional Layer와 유사하게 feature map의 차원을 다운 샘플링하여 연산량을 감소시키고 주요한 특징 벡터를 추출하여 학습을 효과적으로 하는 것이 pooling layer의 역할이라고 할 수 있다.
풀링 연산에는 대표적으로 두 가지가 사용된다.
- Max Pooling : 각 커널에서 다루는 이미지 패치에서 최대값을 추출
- Average Pooling: 각 커널에서 다루는 이미지 패치에서 모든 값의 평균을 반환
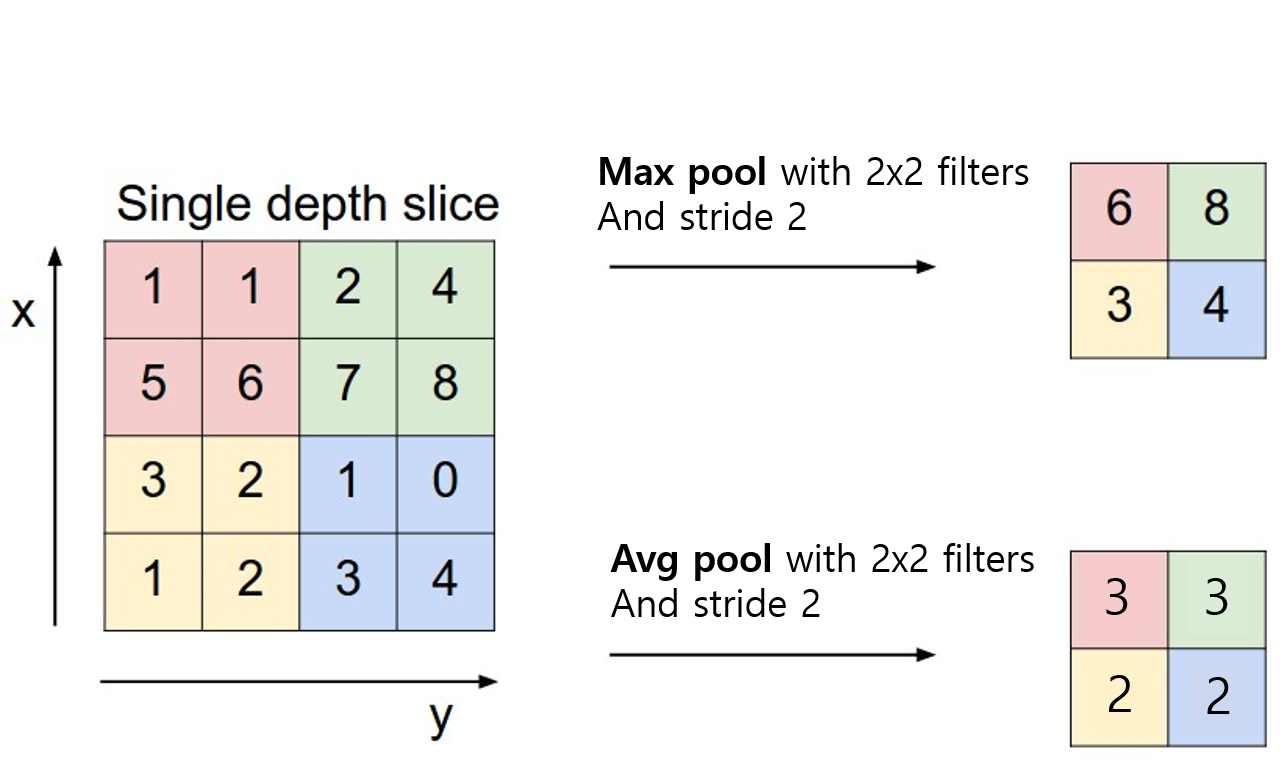
하지만 대부분의 ConvNet에서는 Avg Pooling이 아닌 Max Pooling이 사용된다. Avg Pooling의 경우 각 커널의 값을 평균화시키기 때문에 주요한 가중치를 갖는 value의 특성이 희미해질 수 있는 문제가 있기 때문이다.
또한 Pooling 사이즈의 경우 Stride와 같은 크기로 설정하여 모든 원소가 한번씩 처리되도록 하는것이 일반적이며, 보통 Max Pooling의 경우 2 x 2커널과 2 stride를 사용하여 feature map을 절반 크기로 다운샘플링하게 된다.
4. Fully Connected Layer
위에서 설명한 Convolutional Layer - ReLU Activation Function - Pooling Layer의 과정을 거치며 차원이 축소 된 feature map은 최종적으로 Fully Connected Layer라는 완전 연결 층으로 전달되게 된다.
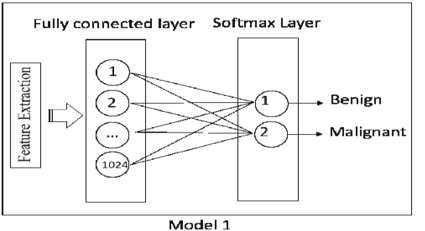
이 부분에서는 이미지의 3차원 벡터는 1차원으로 Flatten되게 되고 신경망에서 흔히 사용되는 활성화 함수(relu)와 함께 Output Layer로 학습이 진행된다.
Output Layer는 Softmax 활성화 함수가 사용되는데, Softmax 함수는 입력받은 값을 모두 0 ~ 1사이의 값으로 정규화하하고 이렇게 정규화된 값들의 총합은 항상 1이되는 특성을 가지는 함수이다.
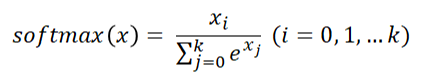
따라서 마지막 Output layer의 softmax함수를 통해 이미지가 각 레이블에 속할 확률값이 레이블마다 각각 출력되게 되고 이중 가장 높은 확률값을 가지는 레이블이 최종 예측치로 선정되게 된다.
References
- https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53
- https://sonofgodcom.wordpress.com/2018/12/31/cnn%EC%9D%84-%EC%9D%B4%ED%95%B4%ED%95%B4%EB%B3%B4%EC%9E%90-fully-connected-layer%EB%8A%94-%EB%AD%94%EA%B0%80/
- https://medium.com/dataseries/basic-overview-of-convolutional-neural-network-cnn-4fcc7dbb4f17
- https://de-novo.org/2018/05/27/convnet-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0/
- https://reniew.github.io/10/
.jpeg)