
해당 문서는 Coursera 강의 Bayesian Statistics: Techniques and Models
를 보고 공부한 것을 정리한 노트입니다.
1. Gibbs Sampling
우리는 지난 게시물에서 MCMC의 기본 개념과 Metropolis-Hastings 알고리즘을 살펴보았다.
이번 시간에 살펴볼 Gibbs Samplig 기법은 MH 알고리즘의 특별한 버전으로, 실제로 MCMC를 돌릴 때 많이 사용된다.
먼저 gibbs samplig의 알고리즘을 살펴보자.
- Initialize
- for , repeat:
a) using , draw
b) using , draw
와 가 순차적으로 조건부 확률분포에서 표집된다.
여기에서는 모수가 인 두 가지 경우만 보았지만, 여러 개의 모수를 가진 모델에도 같은 방식으로 알고리즘을 적용할 수 있다.
깁스 샘플링의 핵심은 각각의 모수의 업데이트 값을 (다른 모수들이 모두 상수로 주어진)조건부 확률분포에서 뽑는다는 것이다. 이는 MH 알고리즘에서 모든 를 accept 한다는 것과 같다.
2. JAGS
(1) What is JAGS?
JAGS는 "just another gibbs samplig"의 줄임말이다. 깁스 샘플링 기반 mcmc 알고리즘을 시뮬레이션 해 볼 수 있는 프로그램이다. 먼저 JAGS를 다운로드 한 다음 파이썬에서 실행해 보자.
pyjags 패키지는 파이썬에서 JAGS를 실행시킬 수 있는 라이브러리다. 이것도 pip로 설치해 주도록 하자.
!pip install pyjags
import pyjags(2) Implementing JAGS
seaborn의 anscombe 데이터셋을 가지고 왔다. 해당 데이터는 데이터셋 별 설명변수 X 1개, 종속변수 y 1개인 간단한 데이터셋이다.
import seaborn as sns
anscombe = sns.load_dataset('anscombe')
anscombe.head()
여기서 데이터셋 = "I"인 값만 쓰도록 하겠다.
mydf = anscombe[anscombe['dataset']=='I']
mydf.plot()
먼저 모델을 정의하자.
여기선 단순선형회귀식을 정의해 보았다.
jags_model_string = '''
model {
for (i in 1:n) {
y[i] ~ dnorm(mean[i], 1.0/sig2)
mean[i] <- int + b*X[i]
}
b ~ dnorm(0, 1e-5)
int ~ dnorm(0, 1e-5)
sig2 = 1.0
}
'''
jags_data = {'y':y, 'X':X, 'n':len(mydf)} # jags_data에 데이터 할당
parameters = ['int', 'b']
jags_model = pyjags.Model(code=jags_model_string,
data=jags_data,
chains=3)
jags_model.sample(1000, vars=[])모델 파라미터를 정의해 준 뒤 1000번의 burn-in iteration을 수행하였다.
burn-in은 추출된 표본이 수렴성을 띌 때까지 어느 정도 mcmc를 warm-up 하는 과정을 말한다.
n_iter = 3000
jags_samples_from_model = jags_model.sample(n_iter, vars=parameters)burn-in이 끝난 후 3000번의 표본추출을 실행하였다. n_chain이 3이므로 총 9000번의 표본추출이 시뮬레이션되었다.
(3) Model Summary
모델의 결과를 보기 위해서 arviz를 임포트 하고 모델을 az.from_pyjags 함수의 인풋으로 넣어 준다.
import arviz as az
idata_jags_model = az.from_pyjags(jags_samples_from_model)az.plot_trace함수로 모델의 수렴성을 볼 수 있다.
az.plot_trace(idata_jags_model)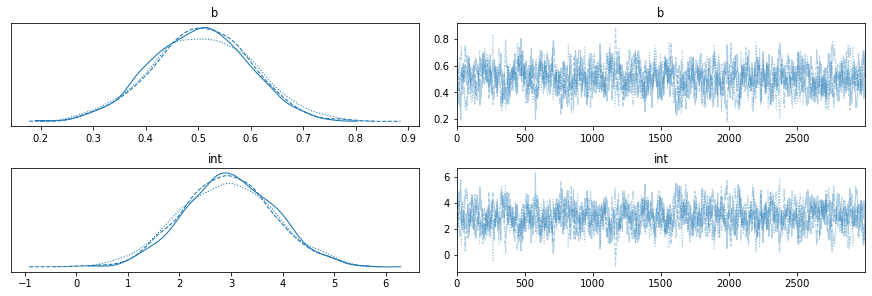
왼쪽은 각각 intercept, b값에 대한 추출된 표본의 분포이다. 둘 다 0에서 명확히 벗어나 있어 해당 모델에서 각각의 파라미터가 유의하다는 것을 암시한다. (회귀분석의 t 검정과 유사하다)
오른쪽은 step이 지나며 추출된 표본의 값이 어떻게 변화하는지 나타낸 플롯이다.
az.summary 함수로 모델을 간단하게 둘러볼 수 있다.
az.summary(idata_jags_model)
이를 OLS로 적합된 회귀식과 비교해 보면
import statsmodels.formula.api as smf
import statsmodels.api as sm
model = smf.ols(formula='y ~ x',data=mydf)
results =model.fit()
results.summary()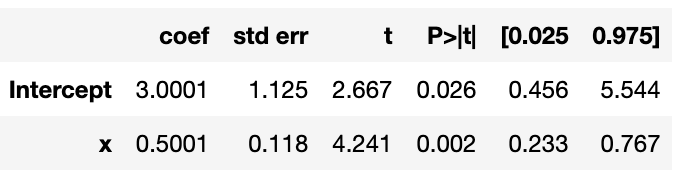
적합된 계수들과 JAGS로 추출한 표본의 평균이 비슷한 것을 확인해 볼 수 있다.
다음 게시물에서는 ESS, DIC, gelman diagnostic 등 MCMC 모델을 평가하고 개선하는 법을 알아볼 것이다.

mac os에 설치해서 pyjags 사용하셨나요? 라이브러리를 pip이용해서 설치시 오류가 계속나서 위에 설치 방법외에 가상환경을 이용하거나 다른 방법으로 설치하셨나 문의합니다~