빅오 표기법과 시간 복잡도 계산, 그리고 알고리즘 개선하기 (Big-O notation, time complexity, and algorithm)
프론트엔드 개발

부트 캠프가 본격적으로 시작됐다. 지난 일주일 동안 엄청난 양을 소화하느라 정신없이 지나왔지만, 공부했던 것들 중에 가장 흥미로웠던 빅오(Big-O) 표기법과 시간 복잡도에 대한 내용을 정리해봤다. 마지막에는 실제 코드에 활용하여 의미있는 개선도 이뤄냈다.
시간 복잡도, 공간 복잡도
시간 복잡도란 내가 짠 코드의 실행 시간(Execution Time)을 예측해 얼마나 효율적인 코드인가를 나타내는 개념이다. 실행 시간은 연산(Operation)에 비례해 길어진다.
공간 복잡도는 코드가 얼마나 메모리 공간을 효율적으로 사용하는지에 대한 개념이다. 정적 배열이나 해시 테이블 처럼 공간을 미리 확보하는 자료구조에 자주 등장하는 개념이다.
일단 코드의 동작 유무가 우선 순위이지만, 중급 이상 개발자로 나아가기 위해서는 동작은 물론이고 효율도 중시해야하기 때문에 이러한 시공간 복잡도를 계산하여 효율적인 코드인지 파악하는 연습을 해야한다.
빅오(Big O) 표기법이란
빅오(Big-O)는 시공간 복잡도를 수학적으로 표시하는 대표적인 방법이다. 단, 코드의 실제 러닝 타임을 표시하는 것이 아니며, 인풋 데이터 증가율에 따른 알고리즘의 성능을 (논리적으로) 예측하기 위해 사용한다. 빅오 표기법에는 다음 2가지 규칙이 있다.
-
가장 높은 차수만 남긴다.
O(n² + n) -> O(n²) -
계수 및 상수는 과감하게 버린다.
O(2n + 3) -> O(n)
빅오 표기법으로 시간 복잡도 구분하기
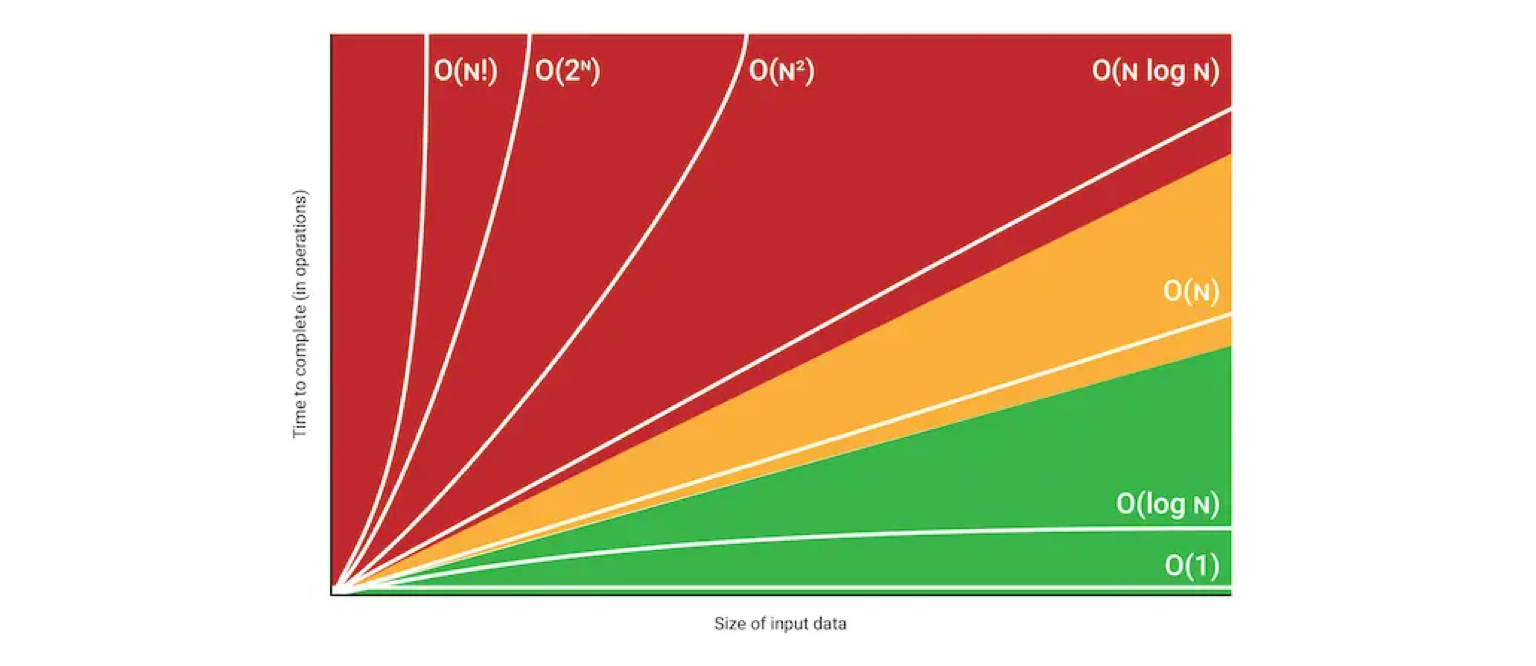
-
O(1) (Constant)
입력 데이터의 크기에 상관없이 언제나 일정한 시간이 걸리는 알고리즘을 나타낸다. 데이터가 얼마나 증가하든 성능에 영향을 거의 미치지 않는다.
-
O(log₂ n) (Logarithmic)
입력 데이터의 크기가 커질 수록 처리 시간이 로그(log: 지수 함수의 역함수) 만큼 짧아지는 알고리즘이다. 예를 들어 데이터가 10배가 되면, 처리 시간은 2배가 된다. 이진 탐색이 대표적이며, 재귀가 순기능으로 이루어지는 경우도 해당된다.
-
O(n) (Linear)
입력 데이터의 크기에 비례해 처리 시간이 증가하는 알고리즘이다. 예를 들어 데이터가 10배가 되면, 처리 시간도 10배가 된다. 선형 탐색 알고리즘이 대표적이다.
-
O(n log₂ n) (Linear-Logarithmic)
데이터가 많아질수록 처리시간이 로그(log) 배 만큼 더 늘어나는 알고리즘이다. 예를 들어 데이터가 10배가 되면, 처리 시간은 약 20배가 된다. 정렬 알고리즘 Merge sort, Quick sort의 평균 시간 복잡도이다.
-
O(n²) (quadratic)
데이터가 많아질수록 처리시간이 급수적으로 늘어나는 알고리즘이다. 예를 들어 데이터가 10배가 되면, 처리 시간은 최대 100배가 된다. 이중 루프(n² matrix)가 대표적이다. 단, m이 n보다 작을 때는 반드시 O(nm)로 표시하는것이 바람직하다.
-
O(2ⁿ) (Exponential)
데이터량이 많아질수록 처리시간이 기하급수적으로 늘어나는 알고리즘이다. 대표적으로 피보나치 수열이 있으며, 재귀가 역기능을 할 경우도 해당된다.
시간 복잡도 계산해 알고리즘 개선하기
어느 정도 개념을 알았으니, 실제 알고리즘에 적용해보자. 나는 프로그래머스의 '완주하지 못한 선수' 알고리즘에 시간 복잡도를 이용했다.
이 문제는 정렬되지 않은 참가자 배열과 완주자 배열을 비교해 완주하지 못한 사람의 이름을 도출하면 된다. 동명이인이 있을 수 있다는 조건 빼곤 그렇게(?) 복잡하지 않기 때문에, 나는 동작 여부를 넘어 얼마나 효율적인 솔루션을 도출할 수 있느냐에 집중해봤다.
다음은 처음에 작성한 코드이다.
비교할 두 배열을 정렬하고, 양쪽의 값을 차례로 비교하는 방법으로 풀었다.
function solution(starters, finishers) {
starters.sort();
finishers.sort();
for (let i = 0; i < finishers.length; i += 1) {
if (finishers[i] !== starters[i]) {
return starters[i];
}
}
return starters[starters.length - 1];
}
이후, 다른 사람들의 솔루션도 참고해봤다. 나처럼 정렬 후 비교 방식으로 푼 사람이 많이 있었다. 그런데 나는 만약 참가자가 수만 명이 되면 sort 함수가 효율적인지에 대한 의구심이 들었다. 그래서 찾아봤다.
Time & Space Complexity of Array.sort in V8
의 내용에 따르면, 자바스크립트 내장 sort는 V8 엔진에서 평균적으로 O(n log n)의 성능을 낸다고 한다.
그렇다면 충분히 개선할 여지가 있을 것 같다. 그래서 다음 시도에서는 정렬 없이 풀어보기로 했다. 물론 그렇게 한다면 두 집단을 동시에 비교할 수 없기 때문에 더 비효율적이지 않을까 고민도 했지만, 문제의 본래 의도인 해시(key-value) 방법으로 시도해보면 문제 될 게 없어 보였다.
다음은 다시 작성한 코드이다.
먼저 참가자 배열을 순회하며 이름: 동명이인 수가 담긴 객체를 만든다. 다음으로 완주자 배열을 순회하며 동명이인 수를 감소시킨다. 마지막으로, 값이 1인 이름을 찾아 반환한다.
function solution(starters, finishers) {
const list = {};
for (let starter of starters) {
if (!list[starter]) {
list[starter] = 1;
} else {
list[starter] += 1;
}
}
for (let finisher of finishers) {
if (list[finisher]) {
list[finisher] -= 1;
}
}
return Object.keys(list).find(name => list[name] > 0);
}.png)
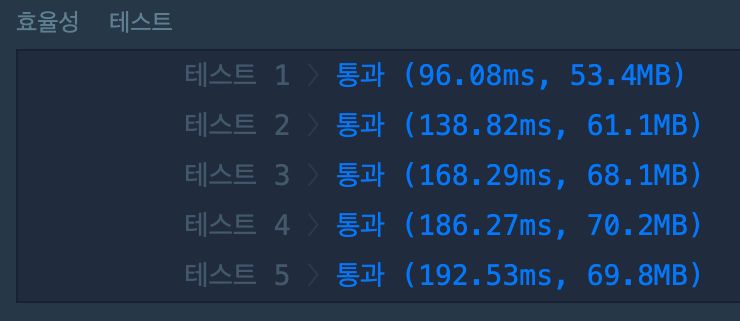
계산해보면 starters, finishers, 그리고 list를 한 번씩 순회하며 최대 3n의 연산이 필요하고, O(n)의 시간 복잡도로 나타낼 수 있다. 처음에 작성한 코드가 O(n log n)이었으니 성능이 개선되었다고 볼 수 있겠다. 실제로도 효율성 테스트 결과를 보면 모든 항목의 실행 시간이 1/3 이하로 줄어든 것을 확인할 수 있다.
그러나 기존 두 배열 외에 추가적으로 객체가 생성되면서 최대 n개의 변수(Key)가 할당 되었기 때문에, 반대로 공간 복잡도는 O(n)만큼 늘어났다. 실제로 각 테스트별 메모리 사용량(MB)이 아주 약간씩 늘어난 것을 알 수 있다.
마치며
이번 기회로 시간 복잡도라는 개념을 처음 알게 됐고, 실제 코드에도 나름대로 적용해봤다. 이전에는 코드를 개선한다 하면 그냥 문법적인 부분만 건드렸다면, 이제는 시간 복잡도 측면에서도 고려해보게 되었고, 전공자의 시각을 조금이나마 느낄 수 있었다.
혹시 내용에 "그건 그렇게 하는게 아니야!" 또는 "뭔가 잘못됐어!" 하는 부분이 있다면 따끔하게 댓글로 지적해주세요.


너무 잘 읽고 참고합니다. 감사해요!