위코드 기업 협업에 참여하며 배운 내용을 정리 & 회고 한 내용입니다. (너무 깁니다. 보지 마세요)
하나의 서비스를 선정해 NoSQL 데이터 모델링을 해보고 현실적인 시간을 고려해 도메인 모델을 재 설정하고 직접 만들어 보는 미션을 받았다. 데이터 모델링에 2-3일, 실제 코드 작성에 2-3일 정도의 시간이 주어졌다. 직감적으로 완성은 어렵다는 생각이 들었지만 일단 모델링 방법부터 찾아보면서 차근차근 진행을 해보았다. 아래는 그 모델링 과정과 멘토님의 코멘트등이 뒤 섞여 있다. 결과물(코드)을 계속 개선해야 하지만 이런 과정 자체를 잘 기억하고 싶어 긴 글을 남긴다.
내가 선정한 사이트는 '뭐라고 할까' 라는 서비스로, 디자이너와 개발자 2명이 사이트 프로젝트로 만든 사이트다. 뭐라고 할까라는 이름처럼, 각종 상황에서 뭐라고 쓰면 좋을지 고민되는 각종 문장들을 템플릿처럼 등록하고 복사해서 사용할 수 있는 곳으로, 위코드 팀 프로젝트 사이트로 추천했다 리젝된 곳이다. (여러명이 헙업하기에 적합하지 않아서) 아무튼 결과적으로 나 혼자 이 사이트를 만들 게 되었다니, 뭔가 돌고 돌아 나에게 왔다는 생각이 들었다.
NoSQL 의 데이터 모델링은 구조가 아닌 쿼리부터 짠다는 것을 이전 학습으로 알았고, 조금 더 찾아보니 그 앞단에 서비스 도메인 모델을 파악하고 다룰 데이터 타입을 이해해야 한다는 것을 알았다. 그리고 80은 계획서 작성, 20은 코드 작성의 비율을 적용하기 위해 쿼리문을 작성하며 해당 쿼리에서 사용할 각종 코드를 대략 정리해보는 과정인 줄 알았으나 역시나 놓치는 게 많았다.
1차 데이터 모델링
1차 접근 때는 쿼리문을 짠다는 것에 대한 감이 없어서, 일단 짠 것을 바탕으로 피드백을 받고 이후에 코드를 붙여볼 생각이었다. 대략 아래처럼 쿼리를 통해 보여줄 기능을 서비스 기준으로 선정하고 이대로 살을 붙여 2차 모델링을 시작했다.
1. 사이트 선정
- "뭐라고 할까" - https://whattosay.kr/templates
2. 도메인 모델 파악 (서비스 및 데이터 타입 파악?)
- 각종 상황에서 뭐라고 해야 할지 고민하는 사람을 위한 handy pick 템플릿 아카이브. 각종 상황에 맞는 문장을 복붙해서 사용할 수 있다.
- 템플릿 데이터는 사용자가 직접 입력한다.
ㄴ (필수) 어떤 상황에서 쓰는 템플릿인지 (키워드 설정)
ㄴ (필수) 템플릿 내용 작성 (텍스트)
ㄴ (선택) 태그 추가
3. 쿼리문, 쿼리 결과 디자인
메인
- 방문자, 등록된 템플릿 수, 복사 횟수를 보여준다.
템플릿
- 지금까지 등록된 전체 템플릿 갯수를 보여준다.
- 가장 많이 등록된 템플릿 키워드를 5개만 노출하고 클릭하면 하단에 해당 키워드 템플릿만 리스트업한다.
- 단, 로그인 후 템플릿을 등록한 유저에게만 전체 템플릿 리스트를 보여준다. 그전에는 아래쪽은 블러처리 됨 => 템플릿 등록 유도
- 템플릿 카드에는 해당 키워드와 템플릿 텍스트, 태그 내용을 보여주고 새로 올라온 글이나 내가 쓴 글에는 마크가 찍힌다.
- 키워드 검색을 통해 키워드를 탐색하고 클릭시 해당 키워드만 리스트업 한다.
- 인기순 필터는 템플릿 복사 갯수에 따라 리스트업한다. 리스트 순서가 전환된다.
- 시간순 필터는 가장 최근 등록된 템플릿 순서대로 리스트업한다.
- 한글, 영어, 기타 필터를 통해 해당 언어을 인식하고? 필터링해서 리스트업해서 보여준다.
커뮤니티
- 템플릿 Q&A 게시글에는 작성자 프로필, 작성 시간, 주제별 태그, 제목, 내용, 반응, 조회수, 댓글 수의 데이터가 담긴다.
- ..
2차 데이터 모델링
1차를 바탕으로 각 쿼리에 맞는 파이어베이스 코드를 찾아서 넣어봤다. 이런 쿼리에서는 이런 코드를 쓴다고 미리 정해두면, 이후 코드 작성 효율이 올라간다. 다만 쿼리문을 짜는 것과 사용하는 것 모두 경험해보지 않아서 이게 맞는지 잘 몰라 억지로 끼워 맞춘 느낌이 많았다.(아래 코드들은 참고하면 안됨) 그리고 무엇보다 이런 쿼리를 바탕으로 어떤 데이터 구조를 만들면 좋을지까지 나아가야 했는데 그러지 못했다. 어떻게 하겠다는 있지만 왜 그렇게 해야 하는지, 근거나 논리가 더 채워져야 한다는 피드백을 받았다.
1. 사이트 선정
- "뭐라고 할까" - https://whattosay.kr/templates
2. 도메인 모델 파악
- 각종 상황에서 뭐라고 해야 할지 고민하는 사람을 위한 handy pick 템플릿 아카이브. 각종 상황에 맞는 문장을 복붙해서 사용할 수 있다.
- 템플릿 데이터는 사용자가 직접 입력한다.
- 커뮤니티 탭은 도메인 모델과 맞지 않는 느낌이다.
ㄴ 사이트 타겟은, 당장 문장을 가져다 써야 하는 급한 사람들
ㄴ 여류롭게 커뮤니티에 들려 질문을 남기고 답장을 기다릴 일은 없을 것, sns 처럼 일상톡을 할 이유가 없을 것. 실제로도 거의 사용하지 않는 느낌
ㄴ 주요 공지사항이 있다면 상단에 작게 표시하면 되지 않을까 생각
3. 쿼리문, 쿼리 결과 디자인
메인
- 방문자, 등록된 템플릿 수, 복사 횟수를 보여준다.
// 실시간 업데이트 수신, 컬렉션의 여러 문서 리슨
db.collection("cities").where("state", "==", "CA")
.onSnapshot((querySnapshot) => {
var cities = [];
querySnapshot.forEach((doc) => {
cities.push(doc.data().name);
});
console.log("Current cities in CA: ", cities.join(", "));
});템플릿 (필수)
- 템플릿 등록하기
ㄴ (필수) 템플릭 키워드 설정
ㄴ (필수) 템플릿 내용 작성 (텍스트)
ㄴ (선택) 태그 추가
// 단일 문서 만들기
db.collection("cities").doc("LA").set({
name: "Los Angeles",
state: "CA",
country: "USA"
})
// 키워드 설정 페이지와 템플릿 작성 페이지가 나뉘어져 있다면, 각 페이지에서 따로 set을 실행한다?- 지금까지 등록된 전체 템플릿 갯수를 보여준다.
// 실시간 업데이트 가져오기
db.collection("cities").doc("SF")
.onSnapshot((doc) => {
console.log("Current data: ", doc.data());
});
// 아니면 리렌더링될 때 다시 데이터를 불러온다?- 가장 많이 등록된 템플릿 키워드를 5개만 노출하고 클릭하면 하단에 해당 키워드 템플릿만 리스트업한다. (단, 로그인 후 템플릿을 등록한 유저에게만 전체 템플릿 리스트를 보여준다. 그전에는 아래쪽은 블러처리 됨 => 템플릿 등록 유도)
// 상위 키워드 다섯개 노출
citiesRef.where("population").orderBy("population").limit(2);
// 키워드 클릭 시 해당 키워드 템플릿 리스트업
db.collection("cities").where("capital", "==", true)
.get()
.then((querySnapshot) => {
querySnapshot.forEach((doc) => {
// doc.data() is never undefined for query doc snapshots
console.log(doc.id, " => ", doc.data());
});
})
.catch((error) => {
console.log("Error getting documents: ", error);
});
-
템플릿 카드에는 해당 키워드와 템플릿 텍스트, 태그 내용을 보여주고 새로 올라온 글이나 내가 쓴 글에는 마크가 찍힌다.
-
키워드 검색을 통해 키워드를 탐색하고 클릭시 해당 키워드만 리스트업 한다.
// 키워드 검색 리스트 가져와서 보여주기
var docRef = db.collection("cities").doc("SF");
docRef.get().then((doc) => {
if (doc.exists) {
console.log("Document data:", doc.data());
} else {
// doc.data() will be undefined in this case
console.log("No such document!");
}
}).catch((error) => {
console.log("Error getting document:", error);
});
// 해당 키워드 리스트 업
db.collection("cities").where("capital", "==", true)
.get()
.then((querySnapshot) => {
querySnapshot.forEach((doc) => {
// doc.data() is never undefined for query doc snapshots
console.log(doc.id, " => ", doc.data());
});
})
.catch((error) => {
console.log("Error getting documents: ", error);
});
- 인기순 필터는 템플릿 복사 갯수에 따라 리스트업한다. 리스트 순서가 전환된다.
- 시간순 필터는 가장 최근 등록된 템플릿 순서대로 리스트업한다.
- 한글, 영어, 기타 필터를 통해 해당 언어을 인식하고? 필터링해서 리스트업해서 보여준다. (기타는 제거)
커뮤니티(선택)
- 템플릿 Q&A 등록, 키워드, 제목, 내용을 입력하고 사진도 첨부할 수 있다.
- 템플릿 Q&A 리스트는 반응순, 조회순, 댓글순, 시간순으로 정렬을 바꿀 수 있다.
- 템플릿 Q&A 카드에는 작성자 프로필, 작성 시간, 키워드, 제목, 내용, 반응, 조회수, 댓글 수의 데이터가 담긴다.
- 템플릿 Q&A 카드 상세 페이지, 게시글 하단 반응 아이콘을 눌러서 카운트를 변경한다.
- 댓글을 달면 해당 포스팅에 댓글로 등록되는데, 이때 '템플릿 등록'을 체크하면 해당 키워드의 템플릿으로도 등록된다.
맨토 코멘트
- 템플릿 갯수를 보여주고 싶다면 갯수를 세기위해 전체 데이터를 불러오지 말고 템플릿 갯수만 따로 저장해서 관리하는 게 효율적일 것
- 키워드 기준으로 서브 컬랙션을 나눠 포스트를 저장하면 필요한 것만 선택해서 가져올 수 있다. 혹은 해당 포스트에 키워드를 담아서 where 절을 사용해 가져올 수 도 있다. 어떤 것이 더 좋은 선택일지 고민해보는 거싱 좋다.
- 어떤 데이터 구조를 만들지에 대한 생각이 더 필요하다. 이 쿼리는 이런 걸로 짜야한다에 서 그치지 말고 그 쿼리로 짠다면 어떤 구조가 필요할지까지 가야 한다.
- 이런 생각들을 충분히 하고 그것을 함축해서 작성하는 것이 개발 계획서다. 그 정리에 일정이나 플랜이 들어가야 한다.
- 이런 생각이나 근거 없이 작성한 계획서는 대부분 추축이다. 생각 못한 부분이 많을 수 밖에 없다.
- 기획서를 쓴 논리가 중요하다. 어떤 논리로 이런 기획서가 나왔는지 설명할 수 있어야 한다. 기준이 틀릴 수는 있지만 논리 구성 흐름이 얕으면 안된다. 틀리더라도 깊게 고민한 결과를 얘기하는 게 중요하다.
3차 데이터 모델링 + 개발 계획서
3차 데이터 모델링을 하면서는 현실적인 작업 시간을 고려한 도메인 모델 재설정, 실제 개발 계획서(모델링 과정을 압축해서 정리하고 시간을 고려한 계획 세우기)까지 작성해보았다. 앞선 피드백을 바탕으로 데이터 구조도 짜 보았으나, 각 구조의 관계를 정확히 설명하지 못해 해맸다. 어떤 분명한 이유가 있기 보다는 파이어베이스의 컬렉션 - 문서 - 컬렉션 순의 구성이라 그냥 그렇게 만든, 계층을 만들어버린 부분이 있었다.
1. 사이트 선정
- "뭐라고 할까" - https://whattosay.kr/templates
2. 도메인 모델
- 각종 상황에서 뭐라고 해야 할지 고민하는 사람을 위한 템플릿 아카이브
- 각종 상황에 맞는 문장(템플릿)을 복사해서 사용
- 템플릿 데이터는 사용자가 직접 입력
3. 구현 사항 재설정 (일정 고려)
- 템플릿 페이지 메인 기능위주로 구현
ㄴ 템플릿 등록, 템플릿 복사, 템플릿 리스트업, 키워드별 솔팅, 인기순 솔팅(복사 카운트 수 기반)
ㄴ 사용자 입장에서 기존 도메인에서 가장 유용했던 기능들 위주로 선정 - 그 외 메인, 커뮤니티 페이지는 제외
ㄴ 메인은 단순 정보성 페이지
ㄴ 커뮤니티는 도메인 모델과 어울리지 않는 페이지 (불필요한 사용자 참여 유도)
4. 쿼리 결과 디자인
템플릿 등록하기
-
템플릿 키워드, 내용 데이터 문서에 업로드하기
ㄴ 이 후 정렬을 고려해 작성 시간과 복사 카운트 값도 같이 세팅 -
템플릿 등록하면서 숫자 카운트해서 별도 테이블로 저장
ㄴ전체 템플릿 데이터를 불러와 갯수를 세지 않고 해당 숫자만 불러와서 사용하기 위함 (불필요한 정보를 다 받아 오느라 비효율적 => 비용증가)
ㄴ 등록된 템플릿 수는 어느정도 템플릿이 쌓이면 노출하는 게 효과적(이 만큼 많이 쌓였다는 것을 보여주는 용도) 그래서 초반에는 노출하지 않지만, 이후에 노출할 예정이므로(1000개 정도 되면..) 별도 테이블을 만들어서 관리, -
템플릿 계층 구조는 이렇게, temCon(c) - temDoc(d) - templates(c) - template1(d)
ㄴ temCon 컬렉션 안에 temDoc 문서가 있고 그 아래 하위 컬렉션으로 tempates 를 만들고 그 안에 template1, 2, 3.... 순으로 문서를 생성하는 계층구조. 데이터에 쉽게 엑세스 할 수 있게 계층구조로 관리 -
카운트 테이블 계층 구조는.. temCon(c) - temCount(d)
ㄴ 템플릿처럼 문서가 계속 늘어나는 것이 아니므로 두번째 문서 층에 생성해서 관리 -
데이터 계층 구조
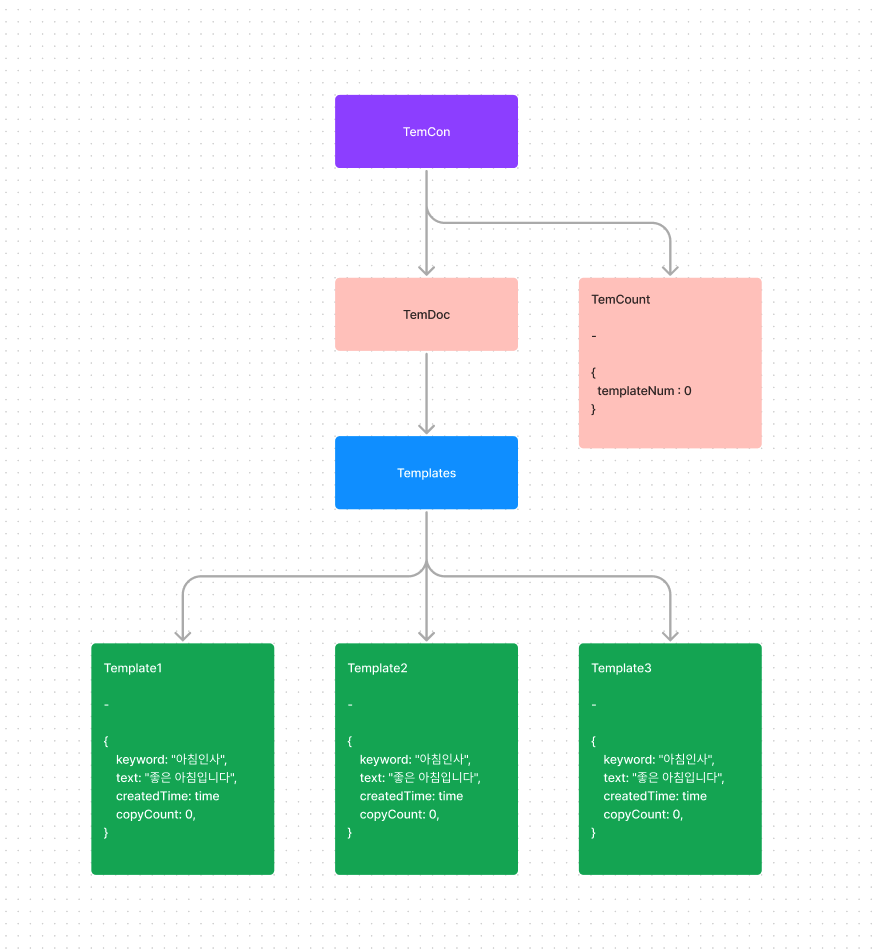
-
쿼리문
// 템플릿 내용 업로드
db.collection("temCon").doc("temDoc").collection("templates").add({
keyword: "아침인사",
text: "좋은 아침입니다",
createdTime: time.. // 등록된 시간 순서대로 정렬?
copyCount: 0, // 이후 복사 카운트할 값도 세팅
})
// 템플릿 카운트 업데이트
db.collection("temCon").doc("temCount").update({
templateNum : (cur) => {cur + 1},
})템플릿 복사하기
- 복사한 템플릿 카운트는 해당 template 문서에 업데이트
ㄴ 인기순 솔팅을 할 때 해당 복사 카운트 숫자를 기준으로 정렬
ㄴ 복사 후 바로 적용된 복사 카운트 숫자는 다시 데이터를 불러오지 않고 프론트 단에서 처리하고 이후 리렌더링시 저장된 데이터 값 가져와서 사용, 데이터 읽어오는 것을 줄이기 위함 - 쿼리문
// 복사 카운트 업데이트
db.collection("temCon").doc("temDoc").collection("templates").doc("template").update({
copyCount: (cur) => {cur + 1},
})
// 업데이트 된 숫자 리렌더링
db.collection("temCon").doc("temDoc").collection("templates").doc("template").get({
copyCount: 숫자,
})템플릿 불러오기 (리스트 업)
- 신규 등록된 15개 템플릿만 불러오고 이후 더보기로 추가 데이터 불러오기
ㄴ 어느정도 스크롤을 내려 확인할 정도의 갯수
ㄴ 첫 렌더링 때 모든 데이터를 다 불러오는 것은 비효율적,
ㄴ 첫 방문자가 비교적 유용한 템플릿을 바로 볼 수 있게 복사수가 많은 기준으로 리스트업
하려고 했으나, 이럴 경우 '새해인사' 처럼 특정 키워드만 도배될 가능성이 있으므로 신규 순으로 변경 - 이후 키워드 선택하면 해당 키워드만 나열
- 이후 인기순 솔팅하면 복사 카운트 순서대로 나열
- 쿼리문
// 생성된 순서대로 나열 (키워드 선택전, 인기순 솔팅 전)
db.collection("temCon").doc("temDoc").collection("templates").
orderBy("createTime", "desc").limit(15)
// 키워드 선택하면, where 추가?
db.collection("temCon").doc("temDoc").collection("templates")
.where("keyword", "==", "아침인사")
.orderBy("createTime", "desc").limit(15)
// 인기순 솔팅하면, 복사 카운트 순서대로 나열
db.collection("temCon").doc("temDoc").collection("templates")
.where("keyword", "==", "아침인사")
.orderBy("copyCount", "desc").limit(15)위 내용을 바탕으로 아래처럼 개발 계획서를 만들어 보았다.
개발 계획서
할일 리스트 업
- 전체 기획안 수정 (멘토 피드백 반영) - 1h+@
- 전체 레이아웃 재구성 (간단한 스케치) - 0.5h
- 리액트 프로젝트 세팅 및 기본 레이아웃 구현 (html, css) - 2h+@
- 파이어베이스 세팅 (config.js 만들고 통신 테스트) - 2h
- 템플릿 등록하기 기능 구현 - 3h+@
- 템플릿 복사하기 기능 구현 - 3h+@
- 템플릿 불러오기, 리스트업, 솔팅 - 4h+@
- 리팩토링 - @
주요 기능별 구현방법
템플릿 등록하기
// 템플릿 내용 업로드
db.collection("temCon").doc("temDoc").collection("templates").add({
keyword: "아침인사",
text: "좋은 아침입니다",
createdTime: time.. // 등록된 시간 순서대로 정렬?
copyCount: 0, // 이후 복사 카운트할 값도 세팅
})
// 템플릿 카운트 업데이트
db.collection("temCon").doc("temCount").update({
templateNum : (cur) => {cur + 1},
})템플릿 복사하기
// 복사 카운트 업데이트
db.collection("temCon").doc("temDoc").collection("templates").doc("template").update({
copyCount: (cur) => {cur + 1},
})
// 업데이트 된 숫자 리렌더링
db.collection("temCon").doc("temDoc").collection("templates").doc("template").get({
copyCount: 숫자,
})템플릿 불러오기
// 생성된 순서대로 나열 (키워드 선택전, 인기순 솔팅 전)
db.collection("temCon").doc("temDoc").collection("templates").
orderBy("createTime", "desc").limit(15)
// 키워드 선택하면, where 추가?
db.collection("temCon").doc("temDoc").collection("templates")
.where("keyword", "==", "아침인사")
.orderBy("createTime", "desc").limit(15)
// 인기순 솔팅하면, 복사 카운트 순서대로 나열
db.collection("temCon").doc("temDoc").collection("templates")
.where("keyword", "==", "아침인사")
.orderBy("copyCount", "desc").limit(15)일정 관리
(희망 사항)
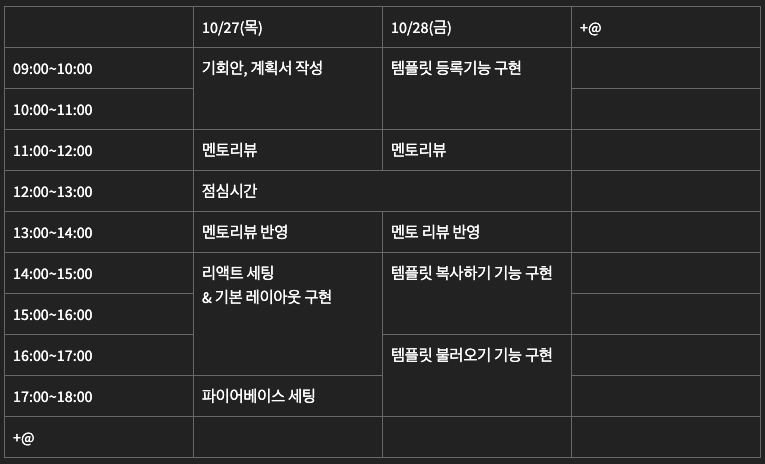
멘토 리뷰
- temCon, temDoc 같은 약어 사용은 지양해야 한다. 서로 약속한 것이 아니라면 누가 보더라도 알 수 있게 길게 작성하는 게 좋다. 요즘 에디터들이 좋아져서 그런 긴 변수명도 자동 완성이 가능하다.
- 도큐먼트에 하위 컬렉션을 둔다고 하며 그 이유가 있어야 한다. 폴더 안에 파일이 있고 또 폴더가 있다면 그 이유가 무엇인지 그런 경로를 왜 선택했는지. 굳이 계층 구조를 만들었다는 그 이유가 분명해야 한다.
- 어떤 것을 분류한다는 것은 비슷한 류를 묶는 것인데 temDoc 과 temCount 를 같은 계층으로 묶는 것이 맞을까. 그럼 temCon 은 너무 브로드한 개념이 아닐까. 싶다. temCount 속성을 루트수준으로 뺀다면 어떨까.
- 숫자 카운트 하나 때문에 계층이 하나 만들어지는 게 오버 스펙이긴 하다. 다른 방법이 있다면 등록되는 템플릿 데이터 안에 넘버링을 하고 마지막 등록한 템플릿을 넘버를 가져올 수 있다. 이 값은 삭제를 고려하지 않는 부정확한 숫자 일 수 있는데 서비스 단에서 그렇게 사용할 수 있다는 결정이 필요하다.
- fieldvalue, increment 를 사용하면 id 값을 1씩 증가시킬 수 있으니 참고
- 콜렉션에서 add 하면 그 문서의 id 가 그 문서의 이름이 되는데 그 값을 프론트에서 실제 데이터와 id 값으로 추가해서 사용한다.
- 15개 보여주고 또 15개 보여주고 싶다면 페이지네이션 개념을 알아야 한다.
- 계획서 시간에 +@는 잘못된 것. 시간 산정은 +@까지 고려한 맥시멈 시간을 정해야 한다. 이 시간 안에서는 내가 하려고 했던 것들이 다 구현되고 생각처럼 돌아가야 한다.
개발 구현
이후 작업은 아래처럼 변경해 진행했고, 남은 작업은 피드백을 바탕으로 각자 해보게 되었다. 코드에 대한 구체적인 피드백도 있었느데 그 부분은 따로 올릴 예정이다. 위코드에서도 이론을 배우긴 하지만, 그보다는 how 에 초점을 맞추어서 코드를 치는 행위에 집중하는 느낌이었다. 여기서는 그런 작업에 앞서 what 을 충분히 고민하고 계획을 설계하는 연습을 해보고 있다. 기업협업이 끝나고 혼자 공부를 하게 된다면 이런 과정을 경험한 게 매우 큰 도움이 될 것 같다.
변경사항
- templates를 루트 층위로 올려서 templates - template 로 구성
- 숫자 카운트는 별도 계층을 생성하지 않고 템플릿 생성 순 넘버를 붙여서 구성
ㄴ 최근 생성 템플릿의 해당 넘버를 가져와서 카운트 확인
ㄴ 숫자가 비교적 부정확해도 됨 (템플릿이 이만큼 많다만 어필하는 목적)
ㄴ 삭제나 동시 생성 이슈를 감안하고 - 템플릿이나 복사 숫자 카운트는 fieldValue.increment(1) 적용해보기
- 템플릿 등록 시 등록된 키워드를 나열해서 보여주어야 하므로 별도 키워드 콜렉션 생성
- 데이터 구조 예시
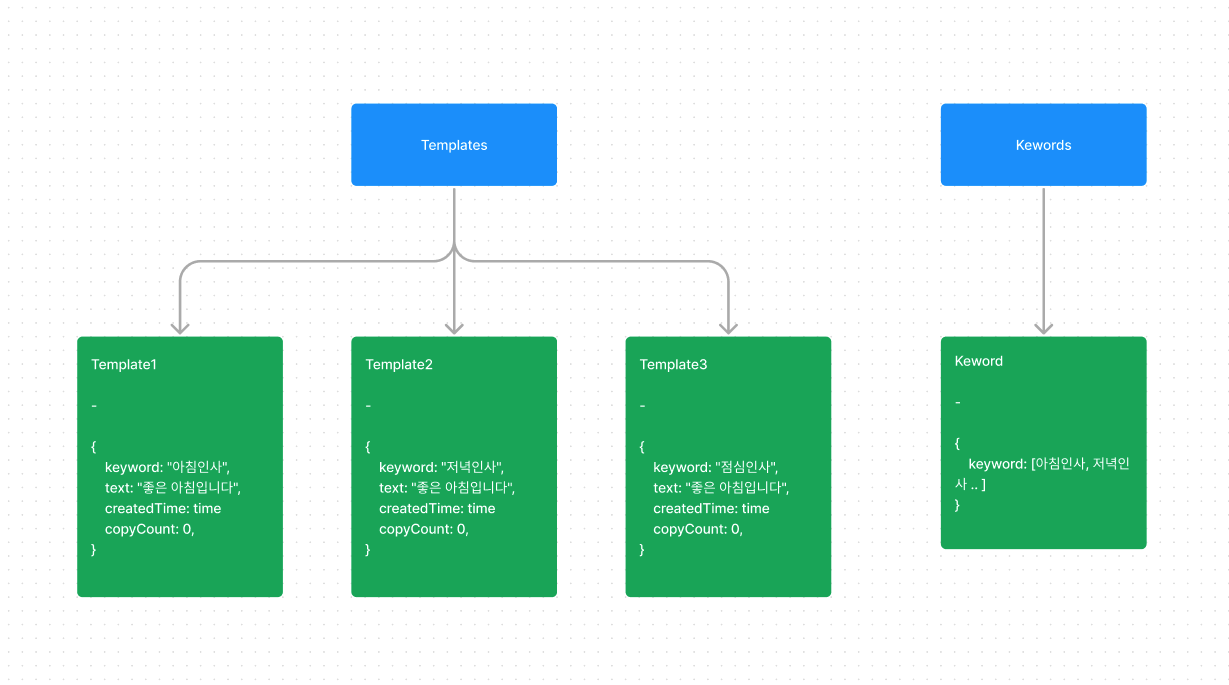
실행순서
- 전체 기획안 수정 (멘토 피드백 반영)
- 전체 레이아웃 재구성 (간단한 스케치)
- 리액트 프로젝트 세팅 및 기본 레이아웃 구현 (html, css)
- 파이어베이스 세팅 (config.js 만들고 통신 테스트)
- 템플릿 등록하기
- 템플릿 불러오기
- 데이터 솔팅하기
- 템플릿 복사하기
깃허브 링크
앞으로 할 것
- 전반적으로 데이터 생성시 key 값으로 사용할 id 값을 넣어야 함, fieldValue.increment 적용방법 찾아봐야 함
- 템플릿 등록시 키워드를 추가 저장하는 데 이때 키워드가 중복 저장되지 않게 해야함.
- 템플리 등록 후 팝업창이 닫혔을 때 화면에 해당 내용이 바로 반영되도록 해야 함. 리렌더링이 비효율적이라면 입력한 값을 바로 넣어주는 방식으로.. state 를 전역으로 사용해야 가능할까? 아니면 콜백?
- 등록한 템플릿을 시간순 정렬하기 위해 timestamp 찍어야 함
- 키워드별로 솔팅되는 것 구현해야 함, 해당 키워드를 클릭할 때 해당 함수를 실행시키는 방식? 아니면 키워드 스테이트가 변경되면 useEffect 가 동작하게 하는 방식?
- 복사기능 구현하고 카운트 증가도 되도록 해야 함
