그래프 이론
그래프의 기본 정의
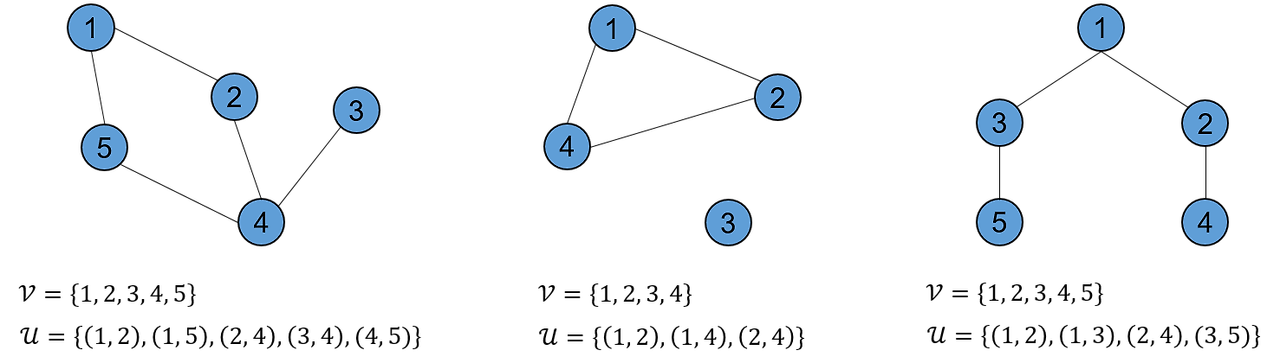
그래프(graph) : 정점과 간선의 집합으로 구성된 구조
정점 (Vertex / Node) : 그래프의 점을 나타내며, 개체를 표현함
간선(Edge) : 정점 간의 연결을 나타내며, 방향성이 있을수도 있고, 없을 수도 있음
❗vertex : 그래프 이론에서 사용되는 공식적인 용어, 수학적 문헌에서 주로 사용
❗node : 컴퓨터 과학 및 네트워크 관련 분야에서 일반적으로 사용, 데이터 구조나 네트워크의 기본 단위수학적 정의
: G=(V,E) , V는 점의 집합 E는 두 점을 잇는 선 집합
ex. 분자구조 : 개별 원자들이 노드, 결합이 엣지가 됨
Graph tasks
- Node classification
- Link prediction
- Graph classification
- Clustering
- Graph generation
그래프의 구조
그래프는 인접행렬(adjacency matrix)와 특징 행렬(feature matrix)로 표현이 된다.
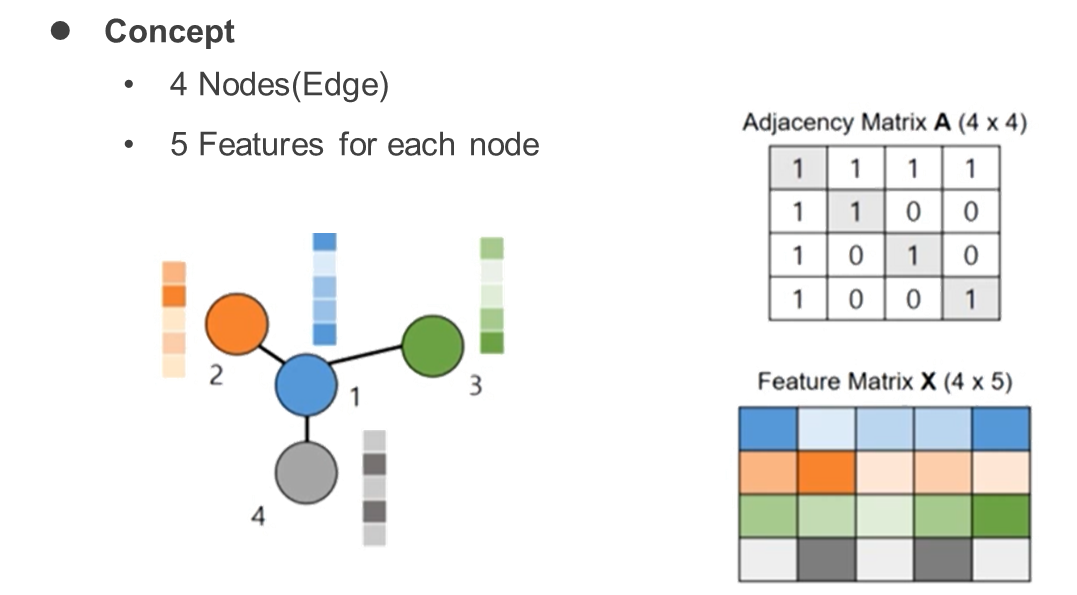
ex. molecular property prediction task 일 땐
node feature : atom type, atom charge ... (atom의 특성)
edge feature : bond type (이중결합, 삼중결합 ...) 이라고 볼 수 있음
보통 인접행렬은 주변 노듸와의 연결만 표시하기 때문에 자신의 정보는 날아감
=> 항등행렬을 이용 A+I로 사용
하지만 그래프는 분석하기 쉽지 않음
=> 그래프는 유클리드 공간에 있지 않아 우리에게 익숙한 좌표계로 표현할 수 없음
=> 그래프는 고정된 형태가 아니라 축을 회전시켰을 때 같은 분자가 다른 방식으로 표현됨
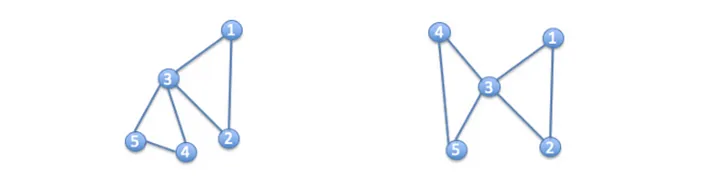
그럼에도 불구하고 그래프를 사용하는 이유는 뭘까?
1) 복잡한 관계 표현에 효과적
2) 쉽게 추가, 제거, 수정이 가능하여 동적인 데이터 구조를 유지할 수 있음 (유연성,확장성)
3) 다양한 데이터 유형을 통합해 처리 가능 (추상적인 개념, 정량적 개념..)
4) 연결된 데이터의 특성 활용
등등 ...
기존의 그래프 분석 방법
기존에는 전통적인 알고리즘 기반 방법들이 많이 쓰임
- 검색 알고리즘 (BFS, DFS)
- 최단 경로 알고리즘 (Dijkstra 알고리즘, A* 알고리즘..)
- 신장 트리 알고리즘 (Prim 알고리즘, Kruskal 알고리즘 ..)
- 클러스터링 방법 (연결 성분, 클러스터링 계수 ..)
- 문제점
: 그래프가 정적이라고 가정함 => 실제 세계에선 그래프의 구조가 지속적으로 변화
: 고차원 데이터를 다룰 때의 효율성 문제
: 그래프의 정보를 이미 알고 있어야함
등등..
따라서 그래프가 여러개 있을 때의 예측이 불가능함 해결책은 GNN
GNN
- GNN에선 인접한 노드들의 정보를 함께 이용해 embedding을 결정하는데, 정보를 수집하는 것을 aggregate, 수집한 정보를 기존 자신의 정보와 합치는 것을 concat 과정이라고 함
=> 한 노드의 feature 업데이트 과정은 aggregate 함수와 concat함수를 통해 이루어짐
=> 각 정점마다 이웃 노드가 다르므로 같은 aggregate 함수를 사용하더라도 입력의 수가 다를 순 있음
- GNN은 크게 spectral한 방법과 Spatial 한 방법으로 나눌 수 있음
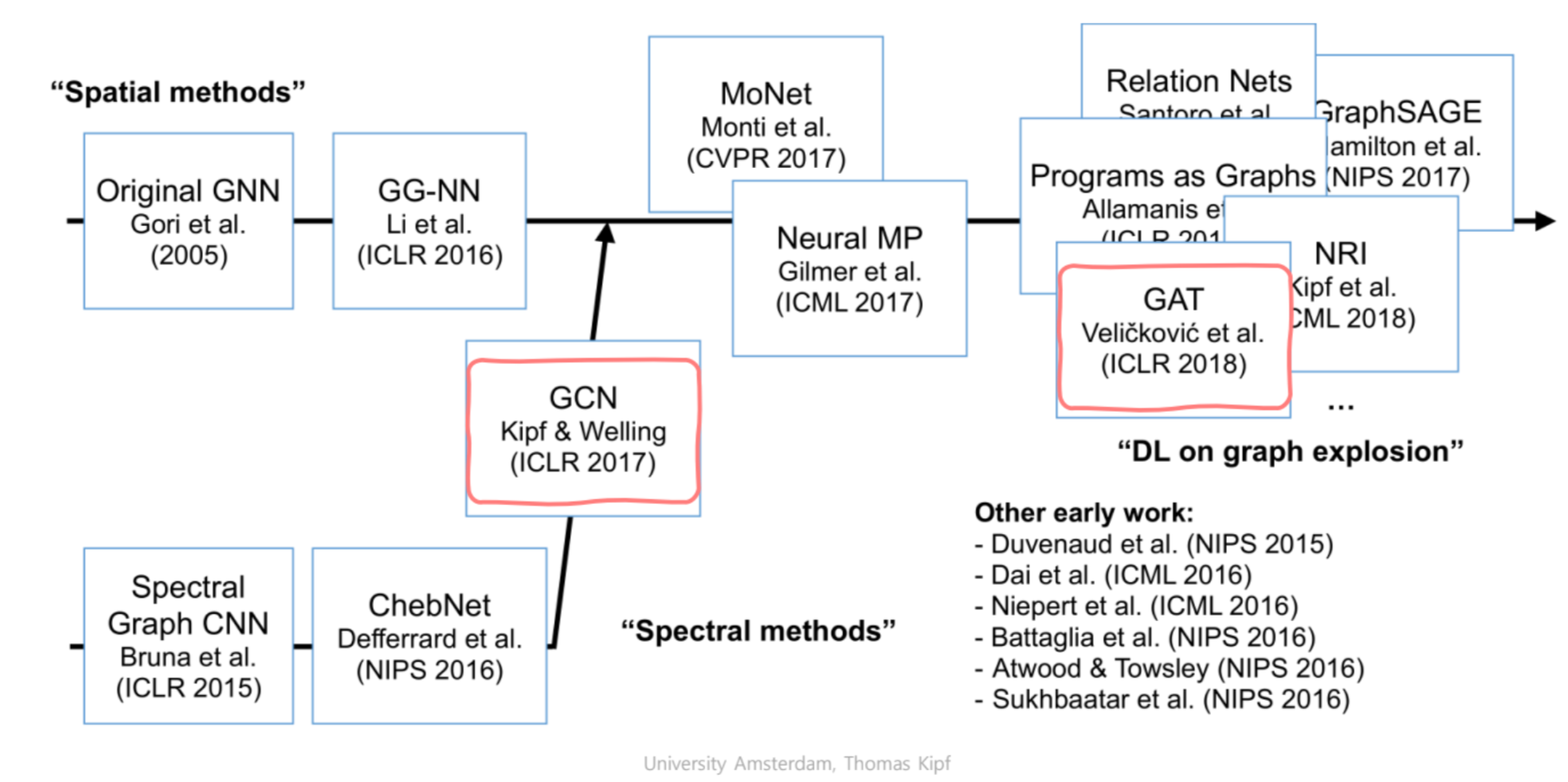
초기엔 Spectral 한 방법으로 접근했지만 GCN의 등장 후, 현재엔 대부분 Spatial한 방법론들을 사용함
GCN
-
spectral한 방법
-
input: 노드와 엣지로 구성된 그래프 ( 각 노드는 feature을 가질 수 있고 간선은 정점간의 관계를 나타냄)
-
CNN의 개념을 그래프에 확장한 거라고 생각하면 됨
-
각 노드의 특성을 이웃 노드의 정보와 결합하여 업데이트
우리가 자주 다루는 이미지, 텍스트 등의 데이터는 유클리디언 공간 상의 격자 형태로 표현이 가능하지만 그래프는 거리가 아닌 연결 여부와 연결 강도가 중요 !
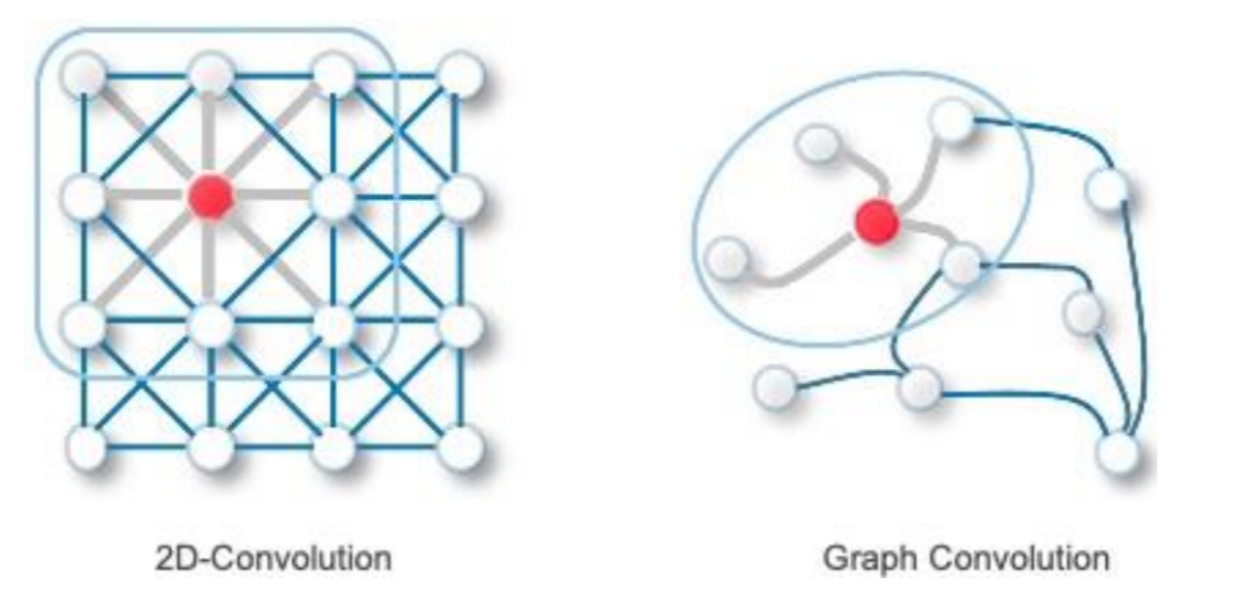
convolution 연산 : 필터를 사용하여 이미지의 특정 영역에서의 정보를 모음
=> 이와 유사하게 graph 에선 각 노드가 자신의 이웃 노드로부터 정보를 수집
(weight average: 연결강도에 따라 다르게 고려됨)
정보를 수집해서 어떻게 되는가?
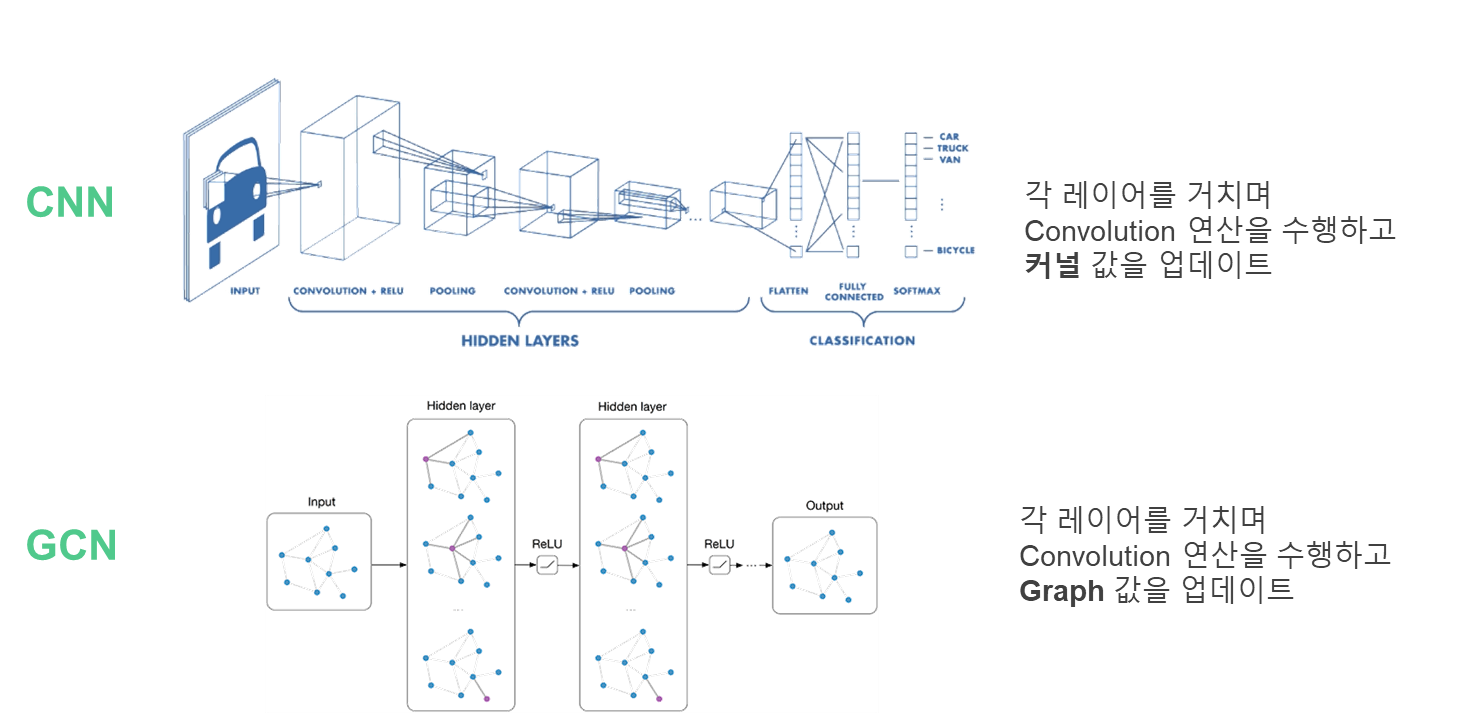
그래프의 input과 output이 언뜻 같아 보이지만 graph 값을 업데이트한다는 것은 노드의 feature(정보) 값들이 업데이트 되는 것
가중치 업데이트 과정
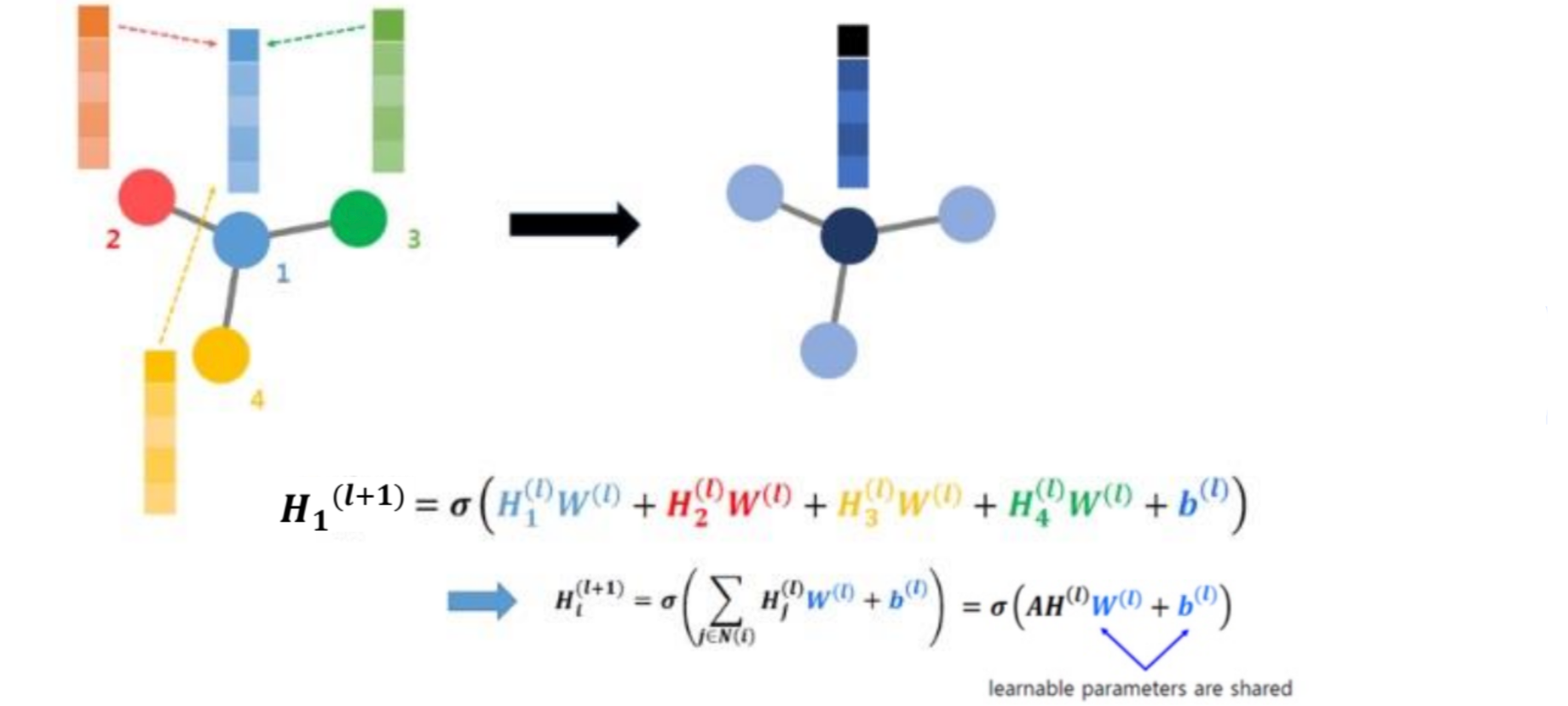
타겟 : 노드 1 / 이웃 : 노드 2,3,4 => 노드 2,3,4 의 정보를 수집해 노드1의 feature 업데이트
컨볼루션 연산
=> 노드 1이 자신의 이웃 노드들의 정보를 가중평균하여 특성을 업데이트하는 방식으로 작용
=> 가중치 행렬은 모든 노드에서 공유됨되며 GCN의 주요 특징임
하지만 이웃노드의 feature만 합치는 방식이기 때문에 자신의 정보를 포함하지 않음 !
연결이 많이 되어있는 노드는 큰 값, 적은 노드는 값이 작아 기울기 폭발, 소실 문제
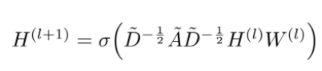
A틸다 : A+I / D 틸다 : A 틸다의 행의 값을 다 더한 행렬 => A 틸다를 정규화 시킨 것
GAT (Graph Attention Networks)
- GAT는 Spatial한 방법론을 사용하기 때문에 인접행렬 (Adj matrix) 사용 X
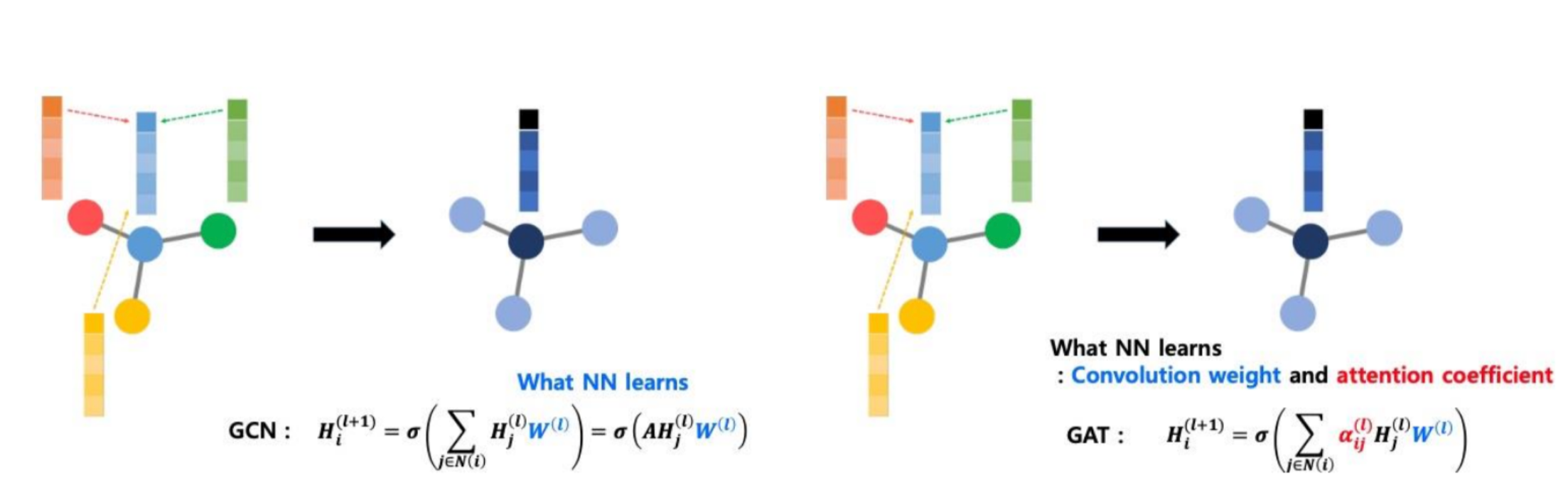
- GAT는 노드별 상이한 weight를 가지고 가중합하는 방식 ( 나한테 영향을 주는 정도까지 학습) => GCN과 달리 이웃노드마다 다른 가중치가 부여됨
1) attention score 계산
- 어텐션 레이어에선 두 노드 간의 상호작용을 펴가하기 위해 두 노드의 특징 벡터를 결합
- 결합된 벡터에 어텐션 가중치 행렬을 적용하여 선형 변환을 수행 (노드 간의 중요도 학습)
- 어텐션 가중치행렬은 학습가능한 파라미터 => 유사도를 최적화하는 방향으로 업데이트
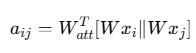

2) Activation function
비선형성을 추가해 모델이 더 복잡한 관계를 학습할 수 있도록 함
- GAT에선 Leaky Relu를 활성화함수로 사용하여 어텐션 스코어를 계산
Leaky Relu
=> ReLU의 변형으로, 입력이 0보다 작을 때에도 약간의 기울기를 허용하여, 완전히 0이 되지 않도록 함
3) Softmax normalization
- Softmax 함수는 각 어텐션 스코어를 정규화하여, 특정 노드의 이웃 노드 간 중요도 비율을 할당
- 모든 이웃 노드의 어텐션 스코어의 합이 1이 되도록하여서 상대적인 중요도를 계산할 수 있도록함
- Softmax 정규화를 거친 어텐션 스코어는 각 이웃 노드의 정보를 집계할 때 가중치로 사용됨


