<와인의 화학적 성분 데이터분석>
Wine project 1. 레드 / 화이트 와인 분류기
Data 불러오기
- red wine과 white wine
- UC Irvine & PinkWink github
- 컬럼 의미 파악(나머진 생략)
-free sulfur dioxide : 자유 이산화황
-total sulfur dioxide : 총 이산화황
-quality : 0 ~ 10 (높을 수록 좋은 품질) - red,white구분 'color'컬럼 생성 후 pd.concat()으로 합치기
Algorithm
- 'color'기준으로 X / y,train / test 데이터 나누기(X_train,X_test,y_train,y_test)
# 구별이 2가지이기에 히스토그램2종류
import plotly.graph_objects as go
fig= go.Figure()
fig.add_trace(go.Histogram(x=X_train['quality'], name='Train'))
fig.add_trace(go.Histogram(x=X_test['quality'], name='Test'))
fig.update_layout(barmode='overlay') #겹치게
fig.update_traces(opacity=0.7) #투명도
fig.show()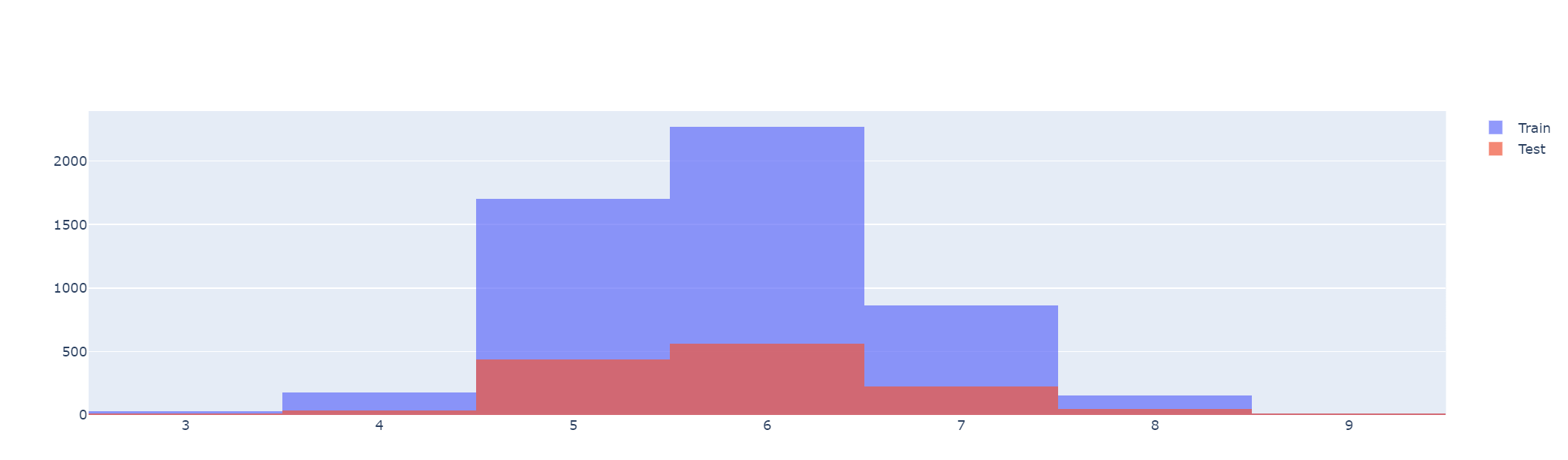
- DecisionTreeClassifier 알고리즘(max_depth=2)
wine_tree= DecisionTreeClassifier(max_depth=2, random_state=13) #fit
y_pred_tr= wine_tree.predict(X_train)
accuracy_score(y_train, y_pred_tr) #0.955
y_pred_test= wine_tree.predict(X_test)
accuracy_score(y_test, y_pred_test) #0.956
#성능이 꽤 좋음- 레드와 화이트 구분 중요특성
dict(zip(X_train.columns, wine_tree.feature_importances_))
# max_depth=2이기에 값이 있는건 2개밖에 안나옴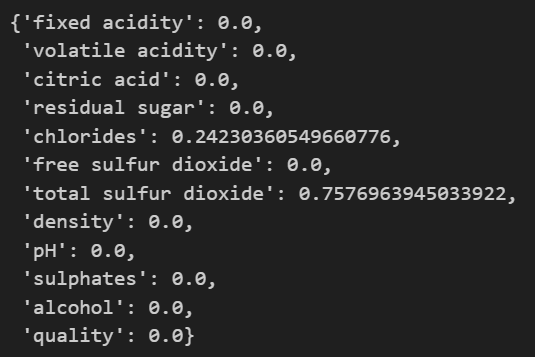
-> total sulfur dioxide(총 이산화황) 레드/화이트 와인 분류에 중유한 역할
데이터 전처리(scaler)
- 사실 DecisionTree는 scaler를 이용한 데이터전처리에 영향을 잘 받지 않음 (지니계수나 엔트로피 계산시 feature 편향에 영향을 주지 않기에)
- 머신러닝세상에서는 ficture들간의 범위의 격차가 심한경우 제대로 학습이 안될'수'도 있다!
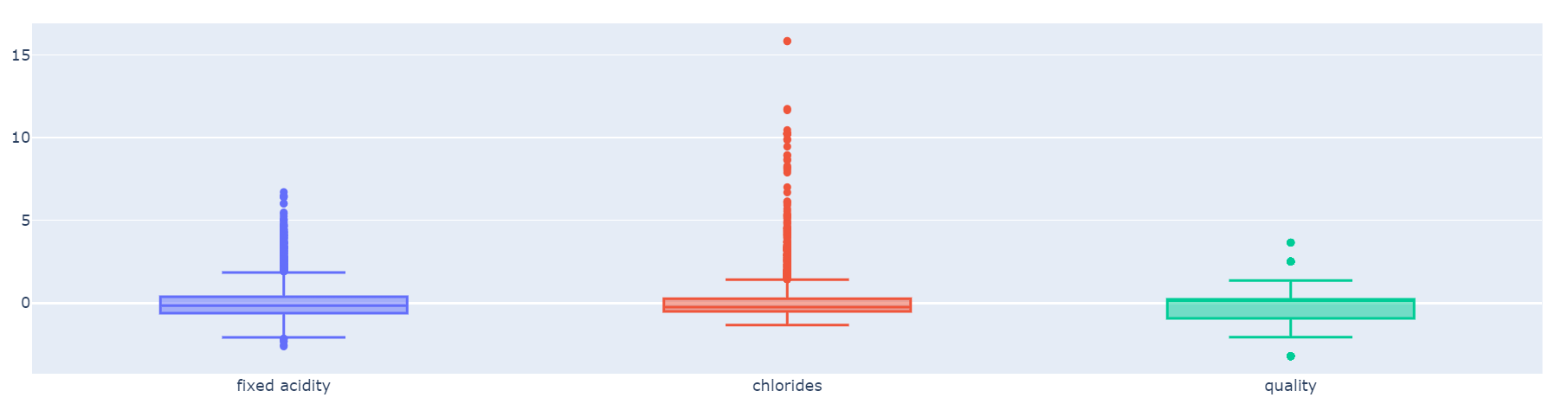
fixed acidity, chlorides, quality 컬럼만 scaling
def px_box(target_pd):
fig = go.Figure()
fig.add_trace(go.Box(y=target_pd['fixed acidity'], name='fixed acidity'))
fig.add_trace(go.Box(y=target_pd['chlorides'], name='chlorides'))
fig.add_trace(go.Box(y=target_pd['quality'], name='quality'))
fig.show()
px_box(X)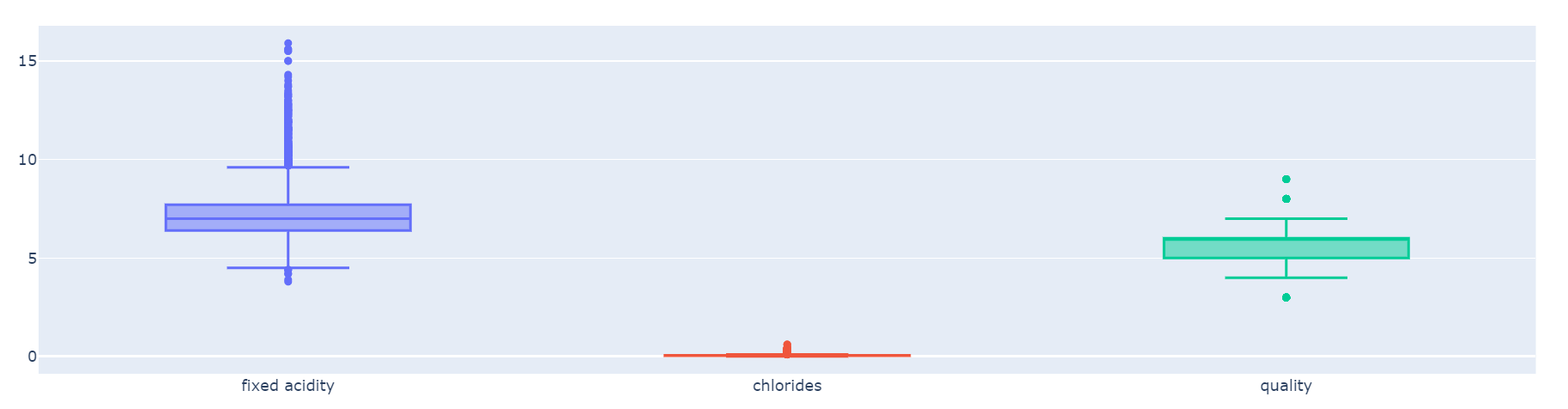
# MinMaxScaler,StandardScaler
X_mms= mms.fit_transform(X)
X_ss= ss.fit_transform(X)
X_mms_pd= pd.DataFrame(X_mms, columns=X.columns)
X_ss_pd= pd.DataFrame(X_ss, columns=X.columns)
px_box(X_mms_pd)
px_box(X_ss_pd)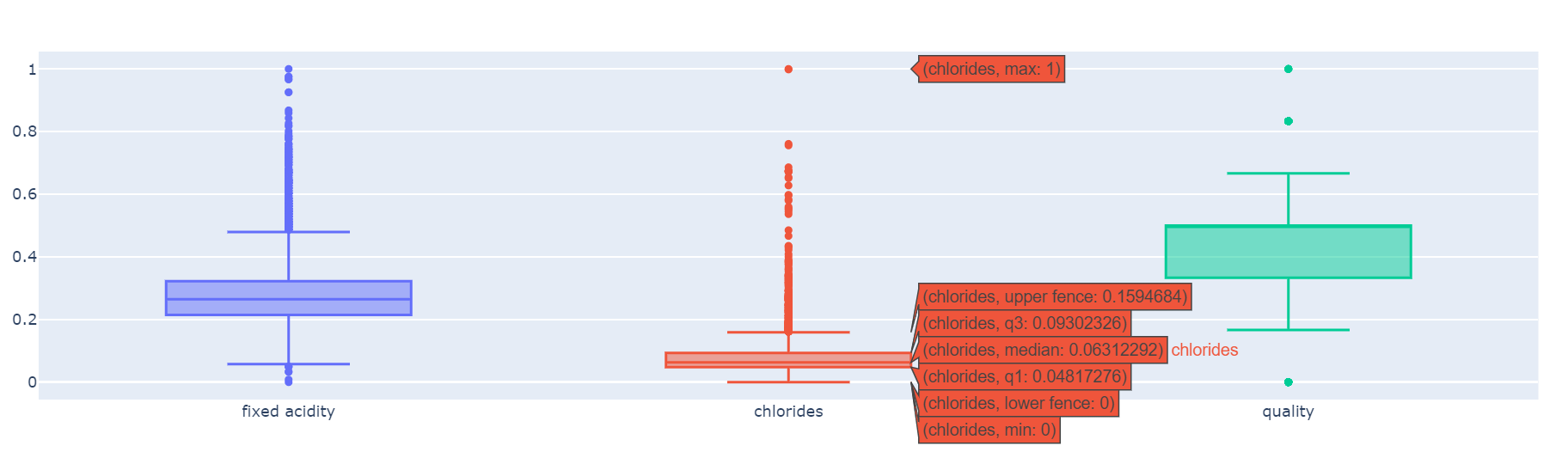
- X_mms_pd를 train/test 나눈 뒤 알고리즘 다시 돌린 결과
accuracy_score(y_train, y_pred_tr) #0.955
accuracy_score(y_test, y_pred_test) #0.956=> 역시나 성능차이는 없음
Wine project 2. 맛의 이진분류[ quality ]
Data 확인
fig = px.histogram(wine, x='quality', color='color')
fig.show()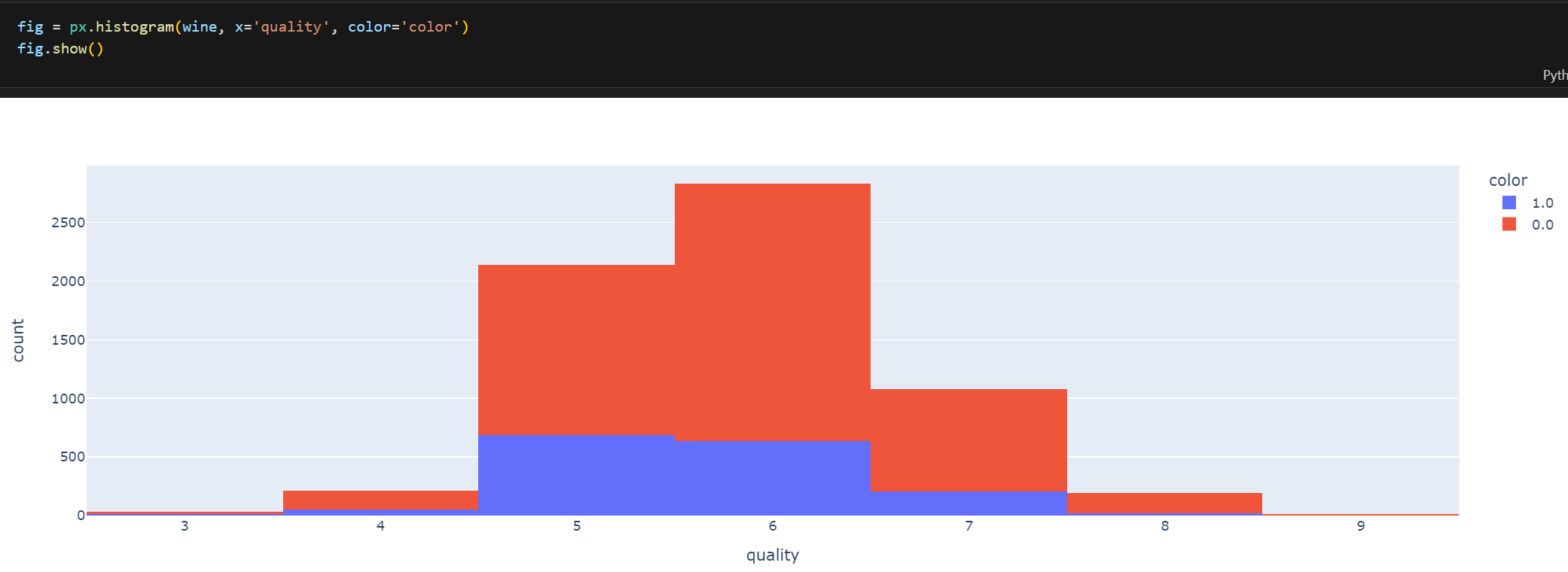
- quality별 히스토그램(color0:red wine/color:white wine)
- 데이터 비율이 quality5~6등급에 몰려있음
# 비율이 너무 뒤죽박죽이라 고침
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]Algorithm
- 'taste'기준으로 X / y, train / test 데이터 나누기(X_train,X_test,y_train,y_test)
- DecisionTreeClassifier 알고리즘(max_depth=2)
- accuracy_score => 1.0 ?!
- wine['quality']로 생각해보면 이걸 없애야 됐음 -> 이걸로 인해 정확도가 100%
X= wine.drop(['taste','quality'], axis=1)
y= wine['taste']
X_train,X_test,y_train,y_test = train_test_split(X,y, test_size=0.2, random_state=13)
..<생략>..
print(accuracy_score(y_train, y_pred_tr)) #0.729
print(accuracy_score(y_test, y_pred_test)) #0.716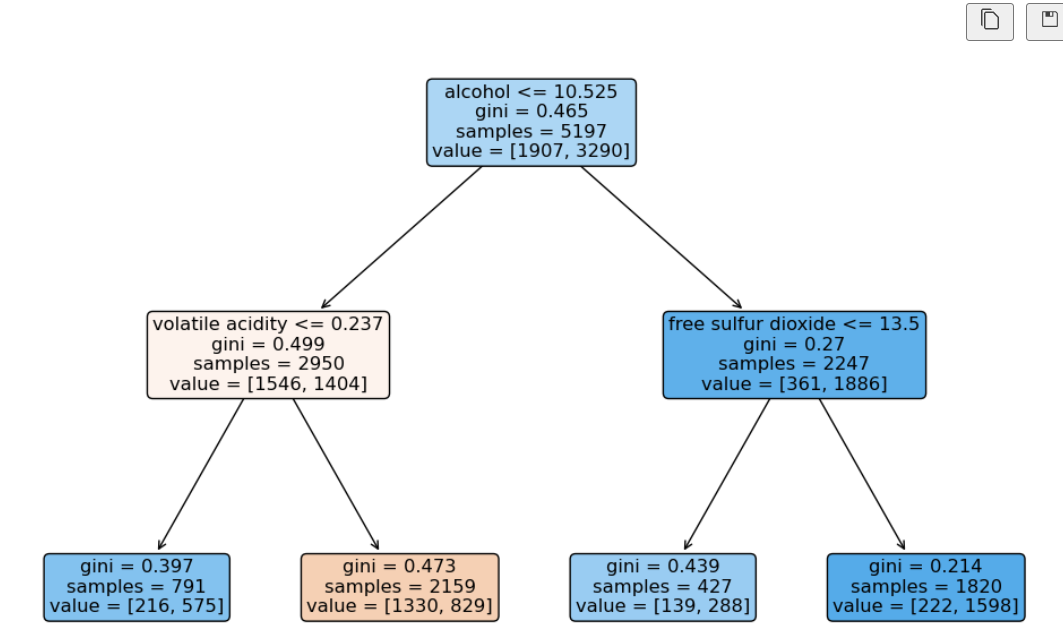
import matplotlib.pyplot as plt
import sklearn.tree as tree
plt.figure(figsize=(12,8))
tree.plot_tree(wine_tree, feature_names=X.columns.tolist(),
filled=True, rounded=True);∴ 해석: 'alcohol'이 높을수록 그 다음은 'free sulfur dioxide(자유 이산화황)'이 높은값일수록 맛의 등급이 높다!
< 다시 한번 더 accuracy에 의문! 정말 정확한가?>
k-fold cross validation
from sklearn.model_selection import KFold
kfold = KFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cv_accuracy = []
for train_idx, test_idx in kfold.split(X):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
wine_tree_cv.fit(X_train,y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
cv_accuracy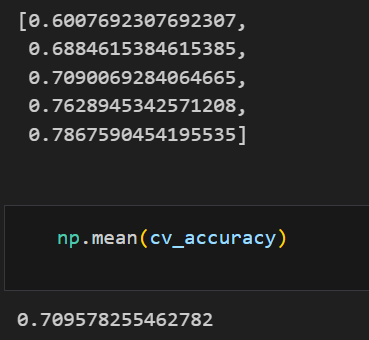
stratified k-fold cross validation
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cross_val_score(wine_tree_cv, X, y, cv=skfold)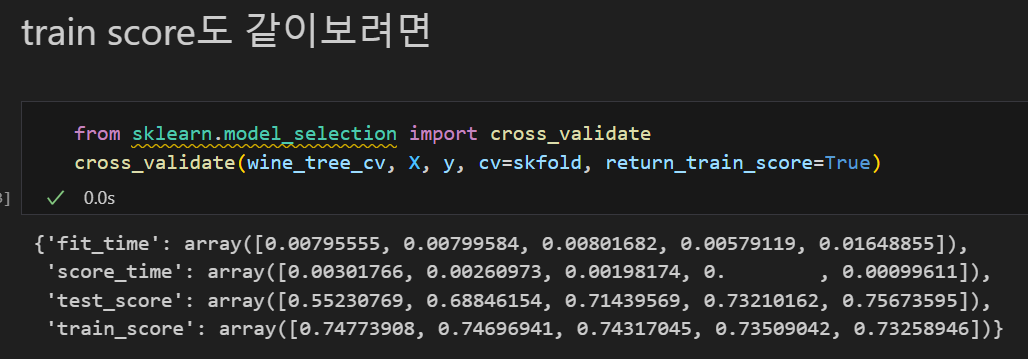
GridSearch CV
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
params = {'max_depth':[2,4,7,10]}
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
gridsearch = GridSearchCV(estimator=wine_tree, param_grid=params, cv=5)
gridsearch.fit(X, y)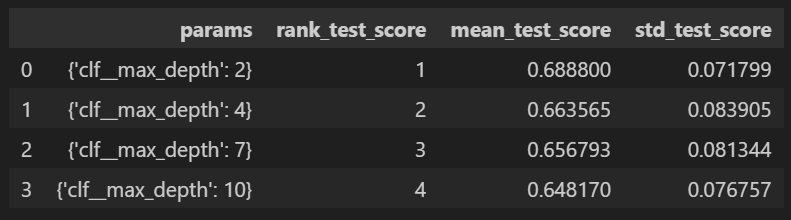

Hello