머신러닝이란?
명시적 프로그래밍없이 컴퓨터(머신)가 데이터로부터 학습할 수 있는 능력을 부여하는 것
로젠블롯의 퍼셉트론(Perceptron)-최조의 인공신경망
민스키-XOR 문제
머신러닝을 이해하기 위해 일단 <휴먼러닝으로 발돋음!>
Iris Classification 아이리스 품종 분류 문제
1. 데이터 관찰
from sklearn.datasets import load_iris
iris = load_iris()
#from sklearn.datasets의 대부분은 ['DESCR'] 키를 가지고 있음 : 데이터설명
#class-> 맞춰야될 분류대상 #features 특성이름
=> 데이터의 특성 파악
sns.boxplot(x='sepal length (cm)', y='species', data=iris_pd, orient='h'); #수평 orient='h'
#3종이 다 겹치는 부분이 있고 아웃라인이 있는 점 등 확인 -> sepal로는 품종 구분 어려움
sns.boxplot(x='petal length (cm)', y='species', data=iris_pd, orient='h');
#하나는 확실히 구분가능하나 나머지 2개는 구분이 어려움 -> boxplot의 컬럼 하나로는 어려움
sns.pairplot(iris_pd, hue='species');
#아웃라인은 대응이 힘들겠지만 3종이 어느정도 구분이 가능하다-
Decision Tree(결정나무) 알고리즘으로 품종구분
Decision Tree
조건에 따라 분기를 하는 모양이 우리가 직관적으로 알기 쉬움
데이터 전처리 전후의 성능 차이가 별로 안남 -> 코드 간결
앙상블 알고리즘 계열의 기본base -
클래스를 나누는 경계선(직선)이 어디에 있으면 최고일까?
수치적인 근거 필요!Decision Tree의 분할기준(split criterion)
정보의 가치: 확률이 작을수록 정보의 가치가 커짐
정보 이득: 어떤 속성을 선택함으로 데이터를 더 잘 구분하게 되는것
정보 엔트로피(-p*np.log2(p)의 합)
entropy: 얼마만큼의 정보를 담고 있는가? 또한 확률 분포의 무질서나 불확실성 상황을 수치적으로 묘사
- low entropy 예> 획일적인 정보구성 시 '질서 정연' => 정보 균일, 무질서 해소
엔트로피는 정보의 종류가 적을 수록 낮은 값을 가짐- medium entropy
- high entropy => 정보가 가장 무질서한 상태
BUT 옛날에 컴퓨터가 로그계산이 어려웠음
-> 지니계수(불순도율) 사용(역시 낮을수록 좋음)
=> 분할하니깐 엔트로피(지니계수)가 내려갔으므로 분할하는 것이 좋다
But 10년전까지만 해도 낮은 지니계수를 찾으려면 일일이 코드작성 후 계산
-> 최근에 sw개발도구의 확산과 공유등으로 공개적인 Frame Work으로발전하기 시작
=> 바로 sklearn 사이킷런!!!(현재 파이썬에서 가장 유명한 기계학습 오픈소스 라이브러리)
<본격적 머신러닝 배우기> :sklearn을 이용한 Decision Tree의 구현
- 지도학습: 특성 한 세트마다 라벨(정답)을 붙여 모델 학습
from sklearn.tree import DecisionTreeClassifier
# 결정나무알고리즘으로 된 분류기
iris_clf = DecisionTreeClassifier()
# 각각의 데이터가 [] 형태로 묶여있음
#학습하기(데이터와 정답알려주고 - 지도학습)
iris_clf.fit(iris.data[:,2:], iris.target) # patal특성만 feature로 이용
# 성능 확인하기(예측 - 추론)
from sklearn.metrics import accuracy_score
y_pred_tr = iris_clf.predict(iris.data[:,2:])
y_pred_tr
# 퍼센트로 확인하기
accuracy_score(iris.target, y_pred_tr)
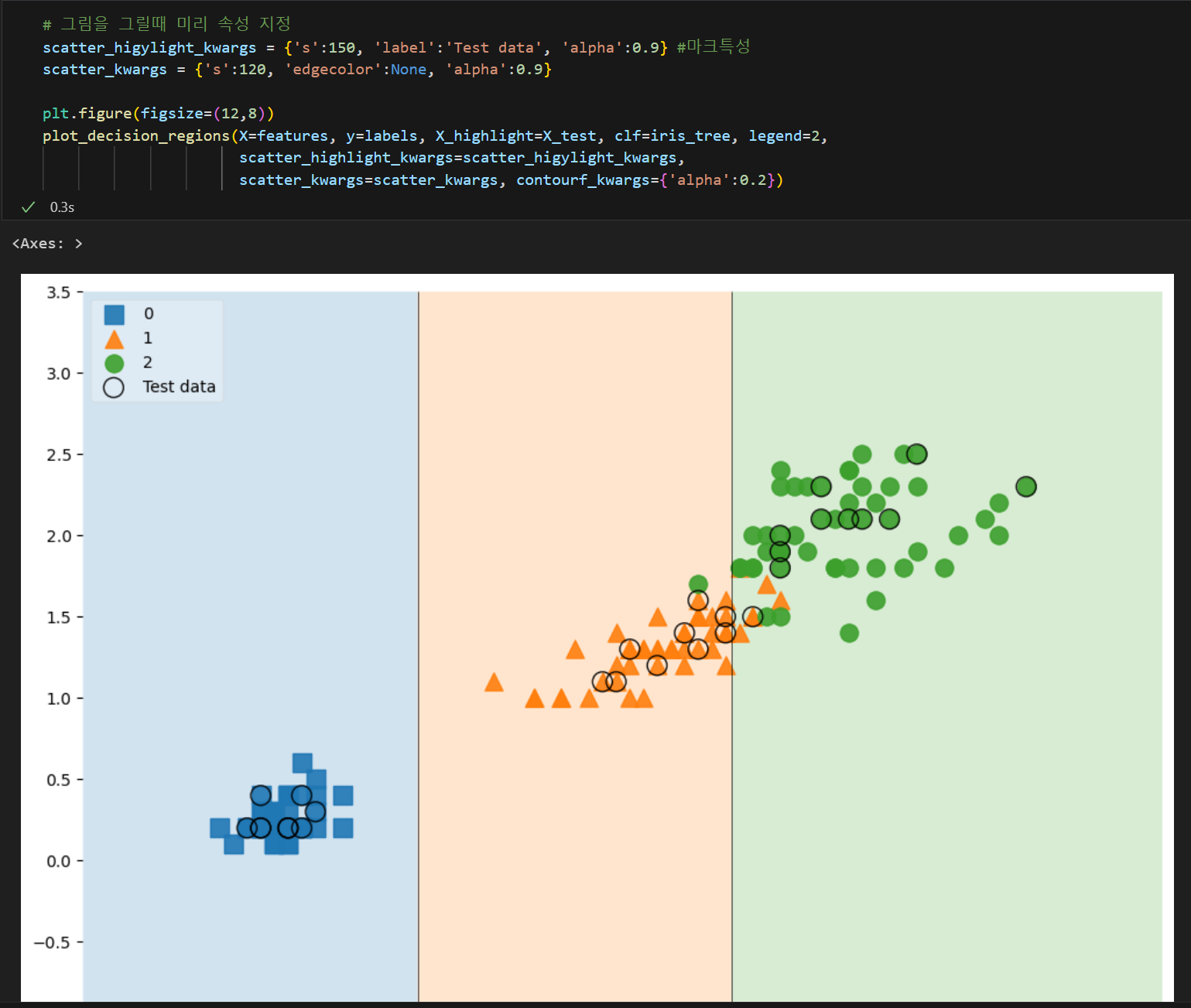
#!pip install mlxtend
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14,8))
plot_decision_regions(X=iris.data[:,2:], y=iris.target, clf=iris_clf, legend=2)
plt.show()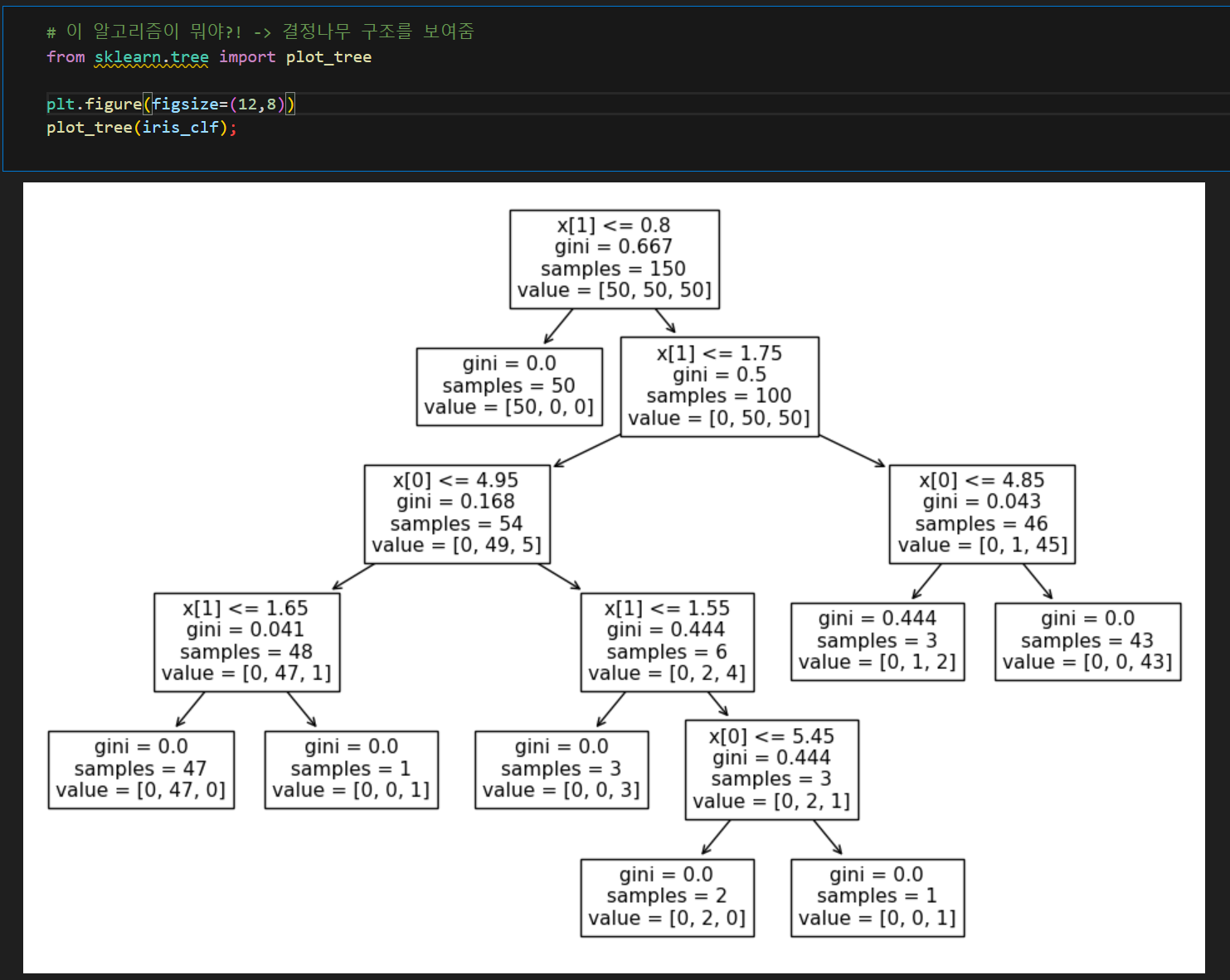
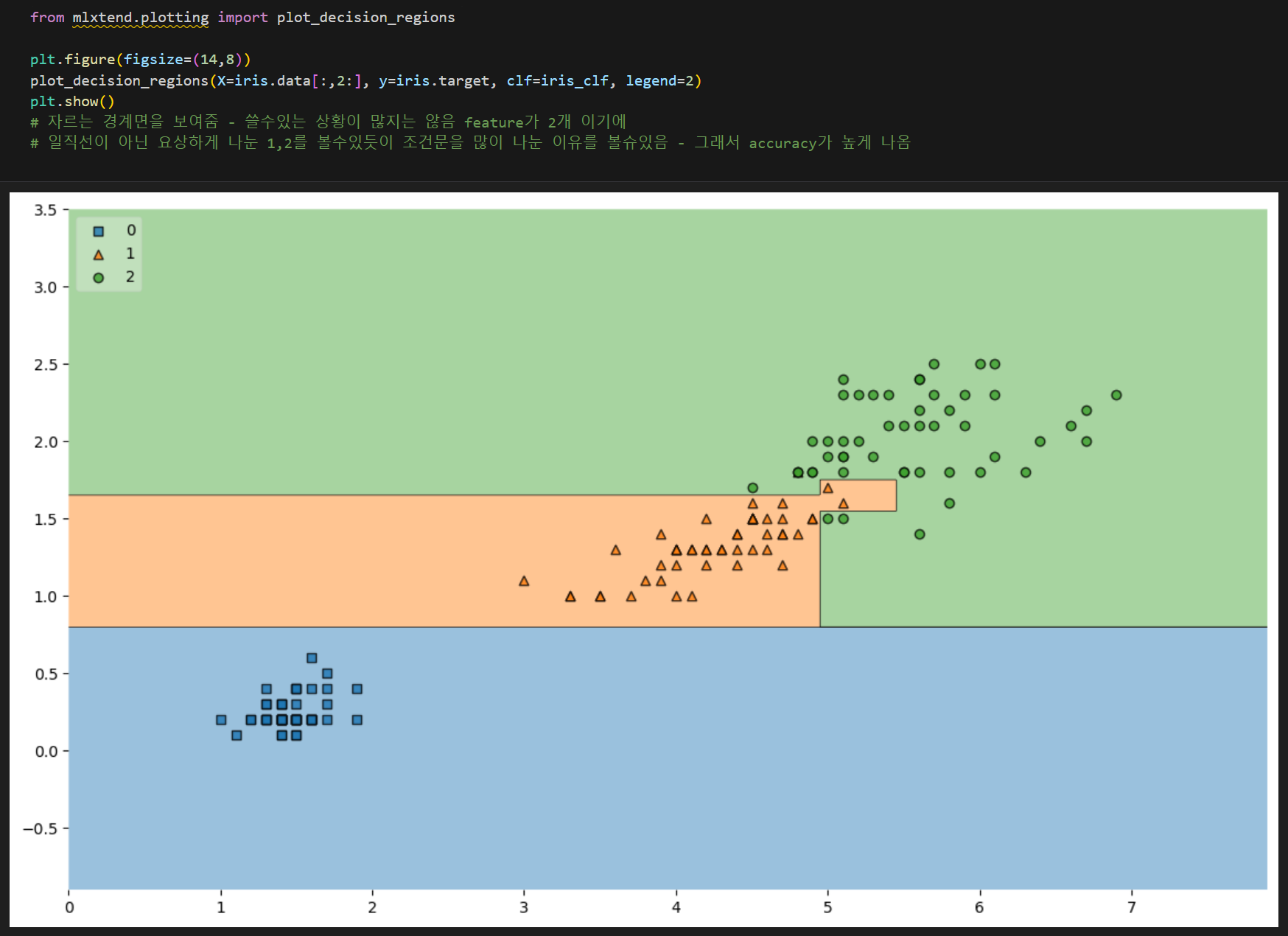 - 내가 가지고 있는 데이터에 너무 최적화 fit => 과적합
- 내가 가지고 있는 데이터에 너무 최적화 fit => 과적합
과적합 over fitting
- 샘플의 편향성이나 아웃라이너로 인해 샘플이 전체를 표현한다고 하기 어려움
즉, 성능이 아무리 좋다고 해도 일반적인 데이터에서 성능이 좋을지는 모름
=> 일반화 성능 확보하려면 내가 가진 정보의 성능이 너무 좋아도 안됨
(그렇다고 과적합인지 아닌지 정확한 수치가 없음)
일반화 성능 확보하기
1. 데이터 분리(데이터 나누기) train/test -> 과적합 여부 판정
from sklearn.model_selection import train_test_split
features = iris.data[:,2:] # feature를 여러 개 줘도 똑같이 판단해 petal 이용
labels = iris.target #정답
X_train, X_test, y_train, y_test = train_test_split(
features, labels,
stratify=labels, # 비율에 맞춰 분리
test_size=0.2,
random_state=필요시)- 특히 분류문제에서 class가 여러개일경우 각 클래스별 분포확인 필요- unique함수 이용
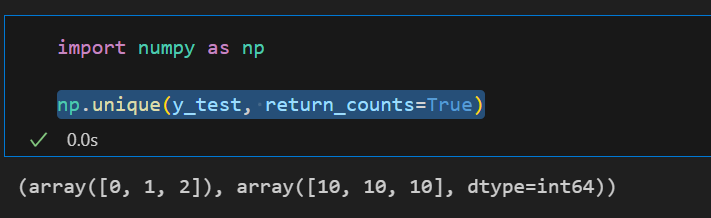
- 각 클래스 비율이 엇비슷해도 되는데 일반적으로는 클래스의 비율을 맞추는게 좋음
stratify= 기준
2. 성능 제한(규제)
- Decision Tree에서 max_depth를 조절하여 성능제한
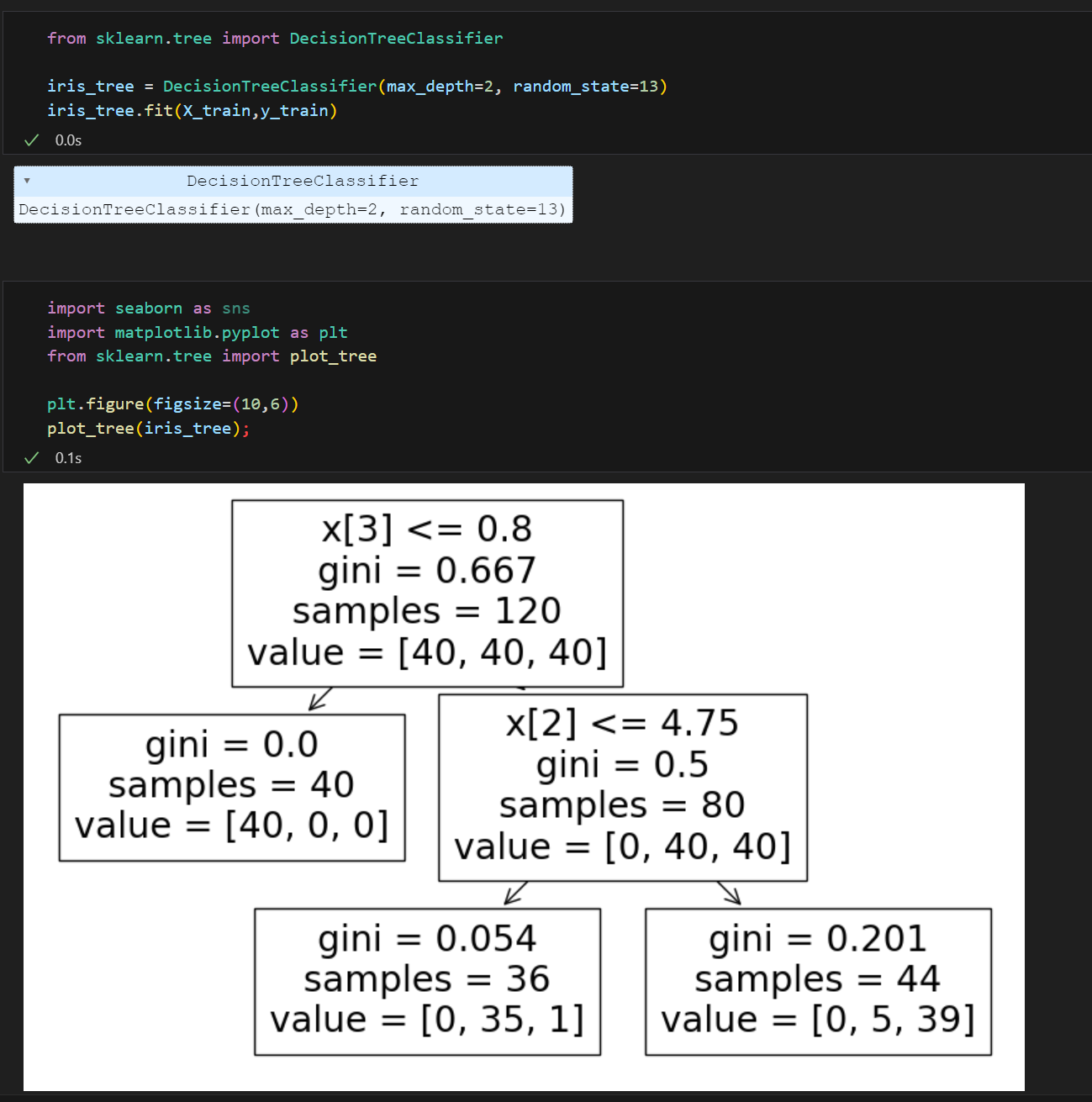 - accuracy_score 확인 결과 성능이 낮춰짐
- accuracy_score 확인 결과 성능이 낮춰짐
3. 추론
test_data = [[4.3, 2., 1.2, 1.]] #np.array([[4.3, 2., 1.2, 1.]])
iris_tree.predict(test_data) #결과값 -> array([1])np.array([4.3, 2., 1.2, 1.]) 행렬의 연산이 안됨. 그냥 array일뿐
- 보너스(이쁘게)
# 각각 확률로 추론
iris_tree.predict_proba(test_data)
# 결과값을 이름으로 마스킹
iris.target_names[iris_tree.predict(test_data)]
# 각각 확률로 추론시 결과값을 이름으로 마스킹
dict(zip(iris.feature_names, iris_tree.feature_importances_))zip() 짚핑과 언패킹
- 기본으로 리스트를 튜플로 짚핑됨
- 언패킹(:언패킹 연산자) x,y = zip(pairs)

Hello