강의 중 잡담?
데이터과학? 가정(또는 인식)을 검증하는것
나이팅게일의 로즈다이어그램
나폴레옹의 행진
파이썬 자주 변할 수 있기에 결과위주로 공부할것
시스템모델 시뮬레이션\현상을 표현하는 도구-수학 mat lab
디지털 필터 디자인(주파수) OIS
오픈소스 3D프린터
<사이킷런 대표적인 절차>
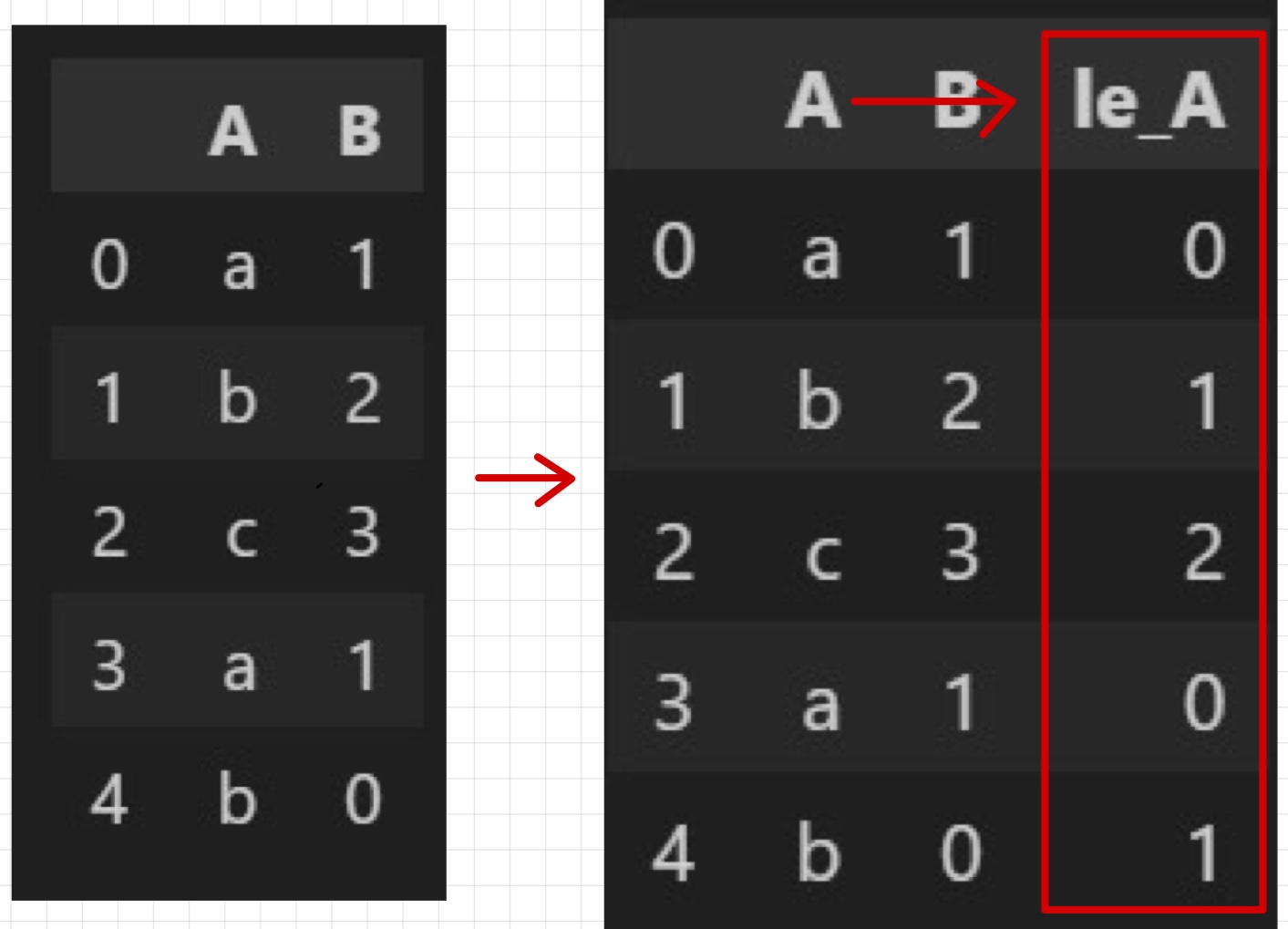
label_encoder
알고리즘을 돌리기 위해선 문자 -> 숫자로 변환이 필요
from sklearn.preprocessing import LabelEncoder
le=LabelEncoder()
le.fit(df['A'])
le.classes_ #array(['a', 'b', 'c']
df['le_A'] = le.transform(df['A'])
#동시에
le.fit_transform(df['A'])
#하나씩 조회 가능
le.transform(['a']) #array([0])
#역변환
le.inverse_transform(df['le_A']) #array(['a', 'b', 'c', 'a', 'b']scaler
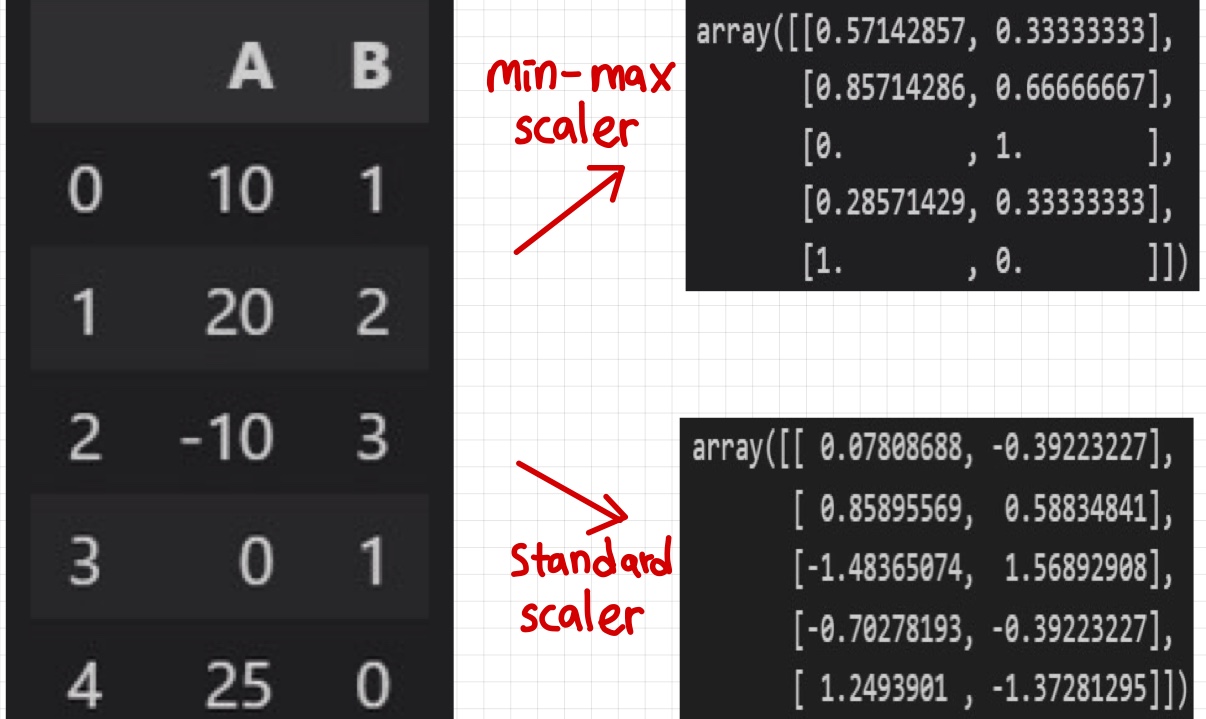
from sklearn.preprocessing import MinMaxScaler,StandardScaler,RobustScalermin-max scaling
- x-min / max-min
- 정규화시키는 방법과 동일
- '-min' 함으로 '0'으로 만들기
- 'max-min'함으로써 크기를 1로 만듬
mms = MinMaxScaler()
mms.fit(df)
df_mms = mms.transform(df)
#min,max,크기 조회 가능
mms.data_max_, mms.data_min_, mms.data_range_
#역변환 가능
mms.inverse_transform(df_mms)
한번에 적용
# mms.fit_transform(df)Standard scaler
- z = X- 평균 / 표준편차
- 표준화 (평균 0, 표준편차 1)
ss = StandardScaler()
df_ss = ss.transform(df)
#평균,표준편차 조회 가능
ss.mean_,ss.scale_Robust scaler
- z = X- 중앙값Q2 / Q3-Q1(데이터의 50% 길이) -> 사분위수 활용
- 표준화 (평균 0, 표준편차 1)
< sns.boxenplot >
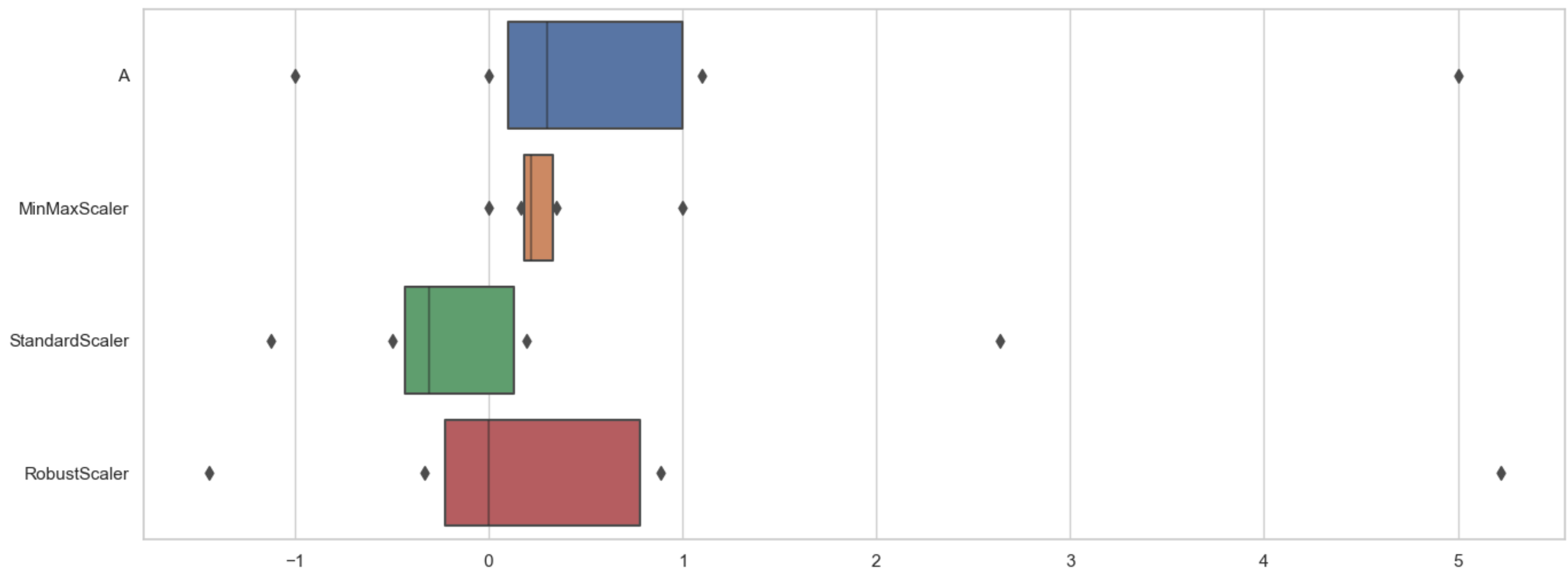
- MinMaxScaler의 문제: 아웃라이너에 영향을 많이 받는 편 -> 만약 아웃라이너(5.0)이 실제 정말 아무 의미없는 잘못된 값이였다면 문제
- StandardScaler의 문제: 역시 아웃라이너에 영향(평균을 빼는 것이기에)
- RobustScaler는 위 2문제 보완 -> 중앙값을 이용하기에
Pipeline
- pipeline(파이프라인)은 class,def와 같은 기능을 하는 것으로 sklearn에서 제공.
- 여러 단계의 데이터 전처리 및 모델링 과정을 연결하는 등의 반복 실행을 해야 할 때 '혼란을 방지하고 순차적으로 실행할 수 있도록 도와주는 도구' -> 코드 간결화, 전체 작업 흐름 단순화
<예시>
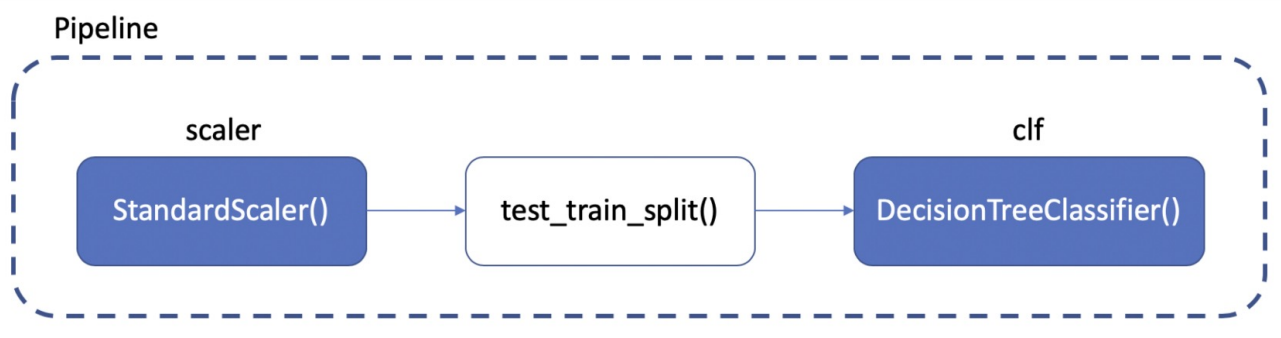
- pipeline 생성
from sklearn.pipeline import Pipeline #다른게 import 되어있다는 가정하에
estimators= [
('scaler', StandardScaler()), #import ss필요
('clf', DecisionTreeClassifier()) #import decision clf필요
]
pipe = Pipeline(estimators)- pipeline 조회 및 속성지정
pipe.steps #[('scaler', StandardScaler()), ('clf', DecisionTreeClassifier())]
#따로 객체 호출해 사용가능
pipe.steps[0]
pipe['scaler']
#속성지정 (__)
pipe.set_params(clf__max_depth=2)
pipe.set_params(clf__random_state=13) - pipeline 적용(train / test split후(순서는 무관))
wine_tree= pipe.fit(X_train, y_train)
-> 이후 accuracy_score 가능Cross Vaildation(교차검증)
- 과적합을 방지하고자 일반화 성능 확보하는 방법 중 또다른 하나로,
모델의 성능을 정확히 표현하기 위해서도 유용. - 단지 train-test 총2등분: holdout
- train에 또 나눠 총3등분 train-vaildation(검증) / test
=> 검증 validation이 끝난 후 test용 데이터로 최종 평가
k-fold cross validation
예> k가 5이라면(5를 많이 사용) train을 5등분 나눔
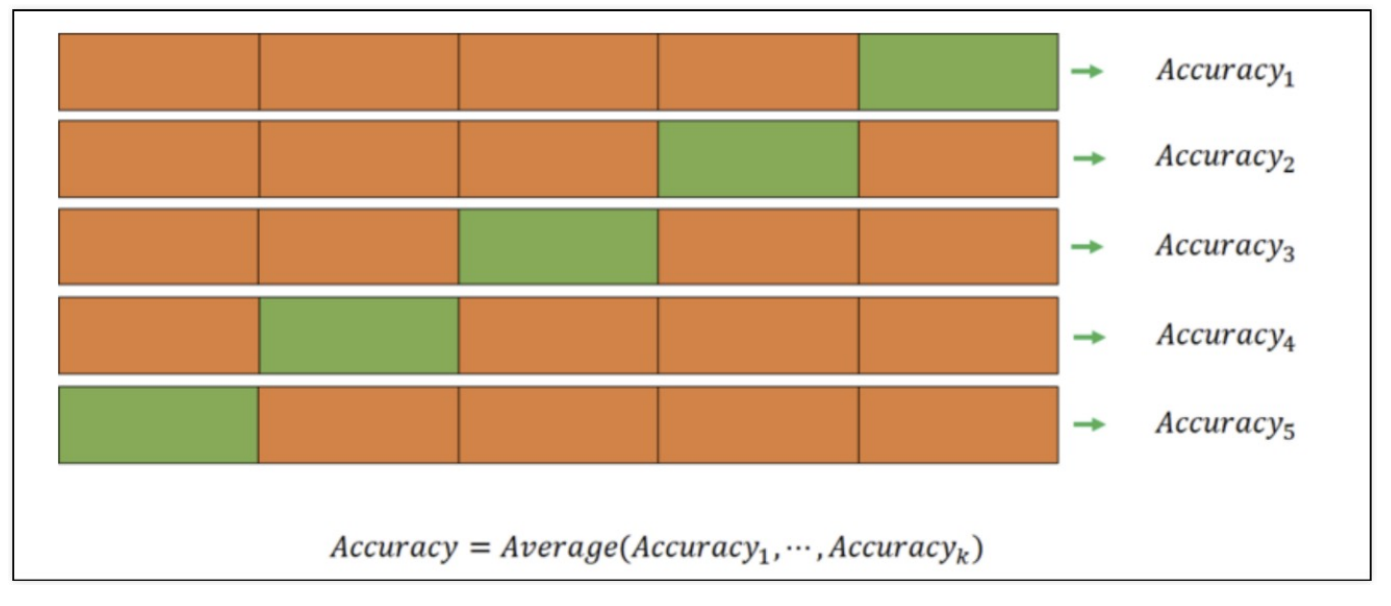
- 이렇게 총 5번 실험, 검증하여 train 평균=train accrancy, vaildation 평균=vaildation accrancy
from sklearn.model_selection import KFold
kf = KFold(n_splits=2)
print(kf.get_n_splits(X)) #2
print(kf) #KFold(n_splits=2, random_state=None, shuffle=False)예> X= np.array([[1,2],[3,4],[5,6],[7,8]])
for train_idx, test_idx in kf.split(X): #test라고 써있지만 vaildation
print('--- idx')
print(train_idx,test_idx)
print('--- train data')
print(X[train_idx])
print('--- vaildation data')
print(X[test_idx])
cv_accuracy = []
for train_idx, test_idx in kfold.split(X):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
df_cv = DecisionTreeClassifier() #다른 알고리즘 가능
df_cv.fit(X_train,y_train)
pred = df_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
cv_accuracy
# 각 acc의 분산이 크지 않다면 평균을 대표값
np.mean(cv_accuracy)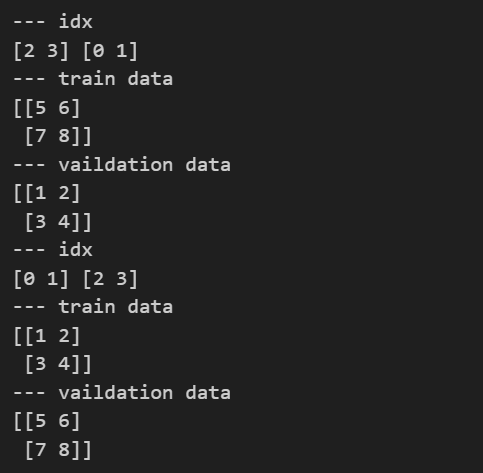
stratified k-fold cross validation
: 그 각각의 1/5이 클래스 비율 맞춰 교차검증
from sklearn.model_selection import StratifiedKFold
skfold = StratifiedKFold(n_splits=5)
...<중간 생략>...
for train_idx, test_idx in skfold.split(X, y) #여기선 y언급 필요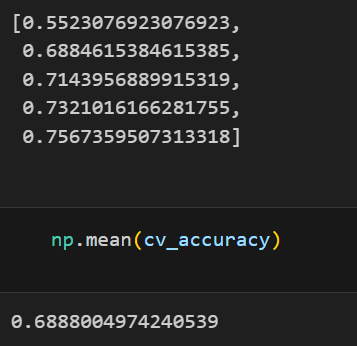
더 간단한 코드
# validation score 확인
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5)
cross_val_score(df_cv, X, y, cv=skfold) #df_cv명시 후
# train score도 같이 확인하려면?
from sklearn.model_selection import cross_validate
cross_validate(df_cv, X, y, cv=skfold, return_train_score=True)하이퍼파라미터 튜닝: GridSearchCV
- 하이퍼파라미터: 내가 손으로 '직접' 수정해 넣을 것들
- GridSearch가 알아서 train,test splict을 함
- 튜닝대상: 결정나무에서는 max_depth
- n_jobs옵션: cpu의 코어 갯수 지정 (-1:전체)
from sklearn.model_selection import GridSearchCV
params = {'max_depth':[2,4,7,10]} #DecisionTreeClassifier기준
df_clf = DecisionTreeClassifier()
gridsearch = GridSearchCV(estimator=df_clf, #알고리즘(분류기)
param_grid=params, #파라미터
cv=5) #교차검증
gridsearch.fit(X, y)
# 결과
# 각 하이퍼파라미터에 따른 test_score등 확인 가능
import pprint
pp= pprint.PrettyPrinter(indent=4)
pp.pprint(gridsearch.cv_results_)
# 조회
gridsearch.best_estimator_ #best 모델 조회
gridsearch.best_score_ #best test 점수 조회
gridsearch.best_params_ #best 파라미터 조회Pipeline에 GridSearchCV
pipe = Pipeline(estimators)
param_grid = [{'clf__max_depth':[2,4,7,10]}]
GridSearch = GridSearchCV(estimator=pipe, param_grid=param_grid, cv=5)
GridSearch.fit(X, y)DataFrame에 넣기
score_df = pd.DataFrame(GridSearch.cv_results_)
#필요한 것만
score_df[['params','rank_test_score','mean_test_score','std_test_score']]Feature Engineering: 특성을 관찰하고 특성을 머신러닝들이 보다 잘 학습할수있도록 특성을 바꾸거나 새로운 특성을 찾아내는 작업

Hello