<Pandas as pd>
- python에서 R만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용가능한 엑셀로 받아들여도 됨
- 누군가 스테로이드를 맞은 엑셀로 표현함
- Series가 모여 DataFrame(index, column, values)
- series :index & value(키와 값으로 표현가능), 한 가지의 데이터타입
numpy as np
- dataframe 수학 연산에 좋은 모듈
- axis = 0 세로, axis = 1 가로
np.random.randn(6, 4) # 표준정규분포에서 샘플링한 난수 생성
np.arange(a,b,s) # a부터 b까지 s의 간격으로 데이터 생성
np.sin()/cos()
np.array # array 행렬형태로 데이터 생성
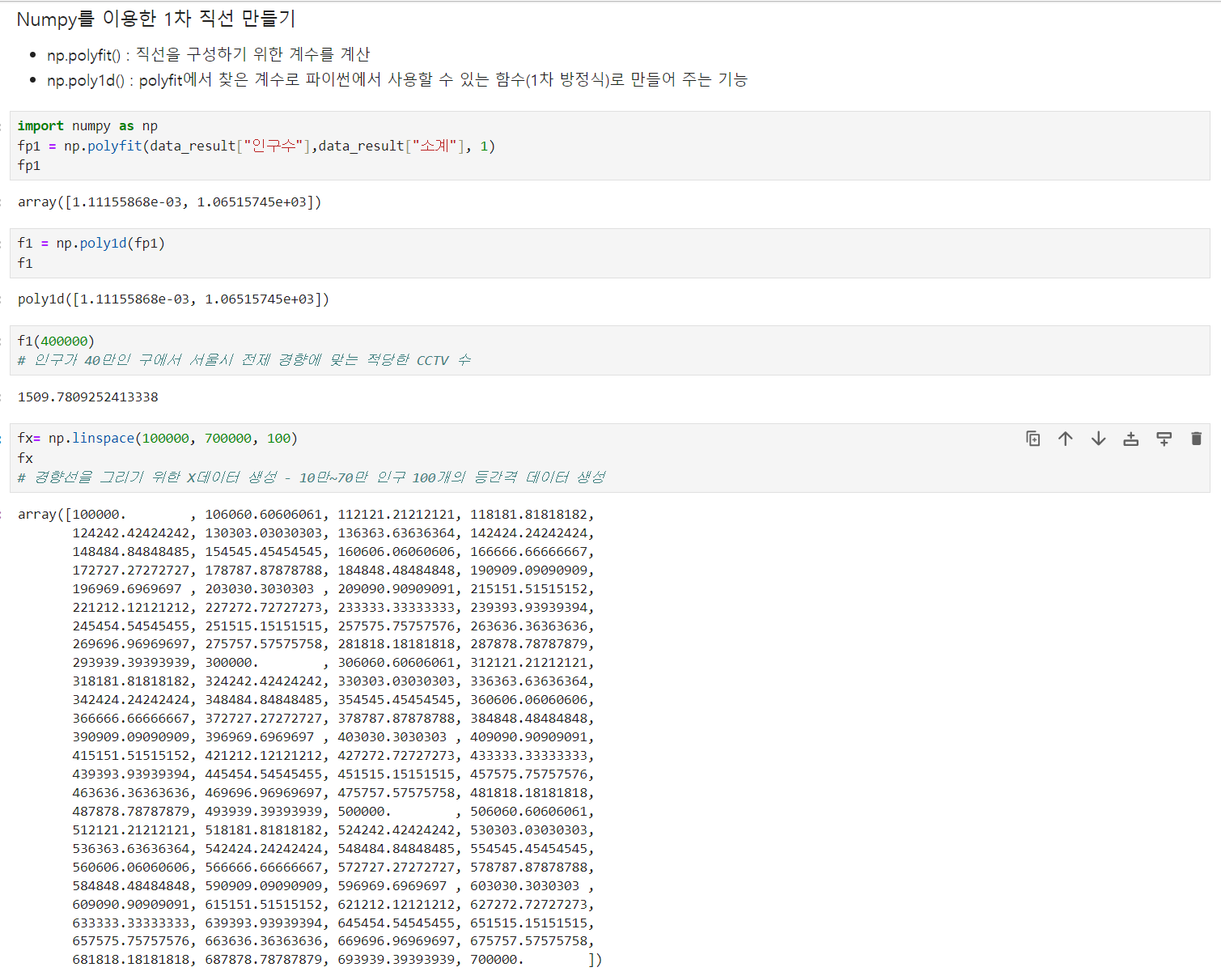
np.linspace()-
np.polyfit() : 직선을 구성하기 위한 계수를 계산
-
np.poly1d() : polyfit에서 찾은 계수로 파이썬에서 사용할 수 있는 함수(1차 방정식)로 만들어 주는 기능
pandas 데이터 읽기
pd.read_csv('경로',
encoding = 'utf-8' # 한글 파일 엔코딩 / 'euc-kr'
thousands=','
# 콤마가 있는 숫자로 보이는 문자열 데이터가 숫자형 데이터로 자동으로 변환됨
sep='' # 구분자
index_col= # (숫자나 컬럼명) 특정 컬럼을 인덱스로 지정
names=['a','b'] # 컬럼명 설정('a','b')해서 읽어올 때
pd.read_excel('경로',
header=2, # 2번째 줄부터 가져기
usecols='B,D,G,J,N' # 원하는 컬럼만pd.date_range 날짜 데이터
: 시작날짜 지정, 날짜, 시간의 데이터를 생성, 간격을 일(day) 간격으로 지정
pd.date_range('20210101',periods=6, freq='D') # 21-01-01 ~ 21-01-06
pd.to_datetime(df['ds'], format= '%y. %m. %d.')
# ds컬럼에 값이 17.6.30. 이런식이였음pd.DataFrame 정보탐색
df
df.head() # 디폴트로 5
df.tail()
df.index # 리스트형태로 나오기에 하나만 뽑을때 [0]가능
df.columns #마찬가지
df.values
df.info() # 기본정보확인
df.describe() # 기술 통계 정보 확인
df[컬럼명].unique()
# 중복 제외 value값 확인(이상한 데이터를 확인,nan값 포함) array로 반환
pd.DataFrame 만들기
pd.Series([data,],dtype=) # 예)dtype=str
pd.DataFrame(data,index=,columns=
pd.DataFrame({ # 딕셔너리 안의 리스트 형태
"key":["K0","K4","K2","K3"],
"A":["A0","A1","A2","A3"],
"B":["B0","B1","B2","B3"]
})
pd.DataFrame([ # 리스트 안의 딕셔너리 형태
{"key":"K0","C":"C0","D":"D0"},
{"key":"K1","C":"C1","D":"D1"},
{"key":"K2","C":"C2","D":"D2"},
{"key":"K3","C":"C3","D":"D3"}
])pd.DataFrame 데이터 정렬, 추가 및 수정, 삭제
df.sort_values(by='기준 컬럼', # 또는 바로 ['기준 컬럼']
ascending=, # True(디폴트) 오름차순, False 내림차순
inplace=True) # df에 자료 업데이트한 것을 저장
df['컬럼명'] = [val1,val2..] # 기존 컬럼이 없으면 추가 / 있으면 수정
df['컬럼명'] = np.nan # values를 Nan값으로 추가
del df['컬럼명']
df.drop([''], # inplace 필요
axis=) # axis = 0 가로, axis = 1 세로pd.DataFrame 데이터 선택
df.A # 컬럼명이 문자일경우 []안해도 됨
그냥 숫자거나 '숫자'일경우에는 df['A']
df.A[0]
df[['A','B']] # 2개이상일 경우 [[ ]]
df[n:m] # n ~ (m-1) / 인덱스명일 경우 ~m까지
df.loc(행,열) # index이름(레이블)으로 특정 행,열
df.iloc # 컴퓨터가 인식하는 index값으로
# 열을 생략할 수 있다(columns X /index줄 확인)
# offset으로도 찾을 수 있다.
df[df['A'] > 0] # condition(조건)으로 데이터 선택 가능
df[df['A'] > 0] = 0 으로 0값으로 바꿀수도 있음
pd.DataFrame apply()
: 데이터프레임에 일괄적으로 어떤 함수 기능을 적용
: np함수 가능(np.sum 등)
df['A'].apply('sum')
df['B'].apply('mean')
# 2개의 apply
df['B'].apply('min'), df['B'].apply('max')
# 두 컬럼
df[['A','B']].apply('sum'), df[['A','B']].apply('mean')
# def함수 만드걸로 적용가능(물론 lambda도 가능)
def plusminus(num):
return 'plus' if num > 0 else 'minus'
df['A'].apply(plusminus)
# lambda함수
df['A'].apply(lambda x: 'plus' if x>0 else 'minus')Pandas 데이터 병합
pd.concat() #형식이 동일하고 연달아 붙이기만 하면 될 때
#예) [DataFrame]
pd.join()
pd.merge(left Data,
right Data,
on='' # 병합시 기준 컬럼명
how='' # 디폴트값으로 how="inner"(교집합)
) "left","right""outer"(합집합)그외 pd.DataFrame

# 인덱스 변경
df.set_index("컬럼명", inplace=True) # 선택한 컬럼을 인덱스로 지정
df.reset_index(drop=True,inplace=True)# 새로운 인덱스 부여
# 상관계수 (연산가능한 int,float데이터만 가능(object는 안됨)
:correlationd의 약자로 상관계수가 0.2이상이면 상관이 어느정도있는 것으로 봄
df.corr()
# 컬럼명 변경
pf.rename(colums={'원래':'new'}) # inplace 필요
pf.columns = [col1,col2,...]
df['컬럼명'].isin(['찾는']) # isin(): 특정 요소가 있는지 확인 T/F
# Nan값 정리
df[df['col'].isnull()] # Nan값만 찾기
df[df['col'].notnull()] # Nan값 없애기
df['col'] = df['col'].fillna('Nan값 대신 채우려는 것')
# project5 참고할것!!!
df.dropna() # Nan데이터 삭제
# 특정 value 변경
df['col'] = df['col'].replace('new', '원래값')
# 다수의 컬럼을 다수 컬럼으로 나누기 div()
df[['col1'].div(df['col2'].values)
# 타입변경
df['col'].astype(np.int64)
# 컬럼 순서변경
df = pd.DataFrame(data, columns=['Rank','Cafe','Menu',"URL"])
df = df.loc[:, ["Rank", "Cafe", "Menu", "Price", "Address"]]Pandas pivot table
- index, columns, values, aggfunc
pd.pivot_table(df,
index='', # 멀티 [ , ]
values='', # 멀티 [ , ]
aggfunc=,
# 디폴트값으로 평균이 연산 / np.sum,len등 가능 / 멀티 []가능
fill_value=0, # Nan값 지정, True도 가능
columns='' # 필수값X, 멀티 [ , ]
# 컬럼의 값이 숫자일경유 따로 values 지정안해도 나옴
margins=True) #총계(ALl) 추가- 멀티인덱스로 인해 컬럼명이 복잡할 수 있음 ->특정 컬럼 삭제 droplevel()
예) MultiIndex([('sum', '건수', '강간', '검거')]
-> ('강간', '검거')
pivot_table.columns = pivot_table.columns.droplevel([0,1])- 다중 컬럼명 하나씩 확인 후 바꾸기(get_level_values)
예) ('강간', '검거') -> '강간검거'
df.columns.get_level_values(0)[2] + df.columns.get_level_values(1)[2]
tmp = [
df.columns.get_level_values(0)[n] + df.columns.get_level_values(1)[n]
for n in range(0, len(df.columns.get_level_values(0)))
]
df.columns = tmp- df.stack(): project5 확인
pandas에 맞는 반복문 명령 iterrows()
- Pandas df은 대부분 2차원
- 이럴때 for문을 사용하면 n번째라는 지정을 반복해서 가독률이 떨어짐
- df으로 반복문을 만들때 iterrows() 옵션을 사용하면 편리함
- 받을 때, 인덱스와 내용으로 나누어 받는 것만 주의
- for문 한줄로: list comprehension라고 함 : [n*2 for n in range(0,10)]
for idx, rows in df.iterrows():
pd.DataFrame 저장
df.to_csv("경로.csv",
sep=",",
encoding="utf-8")
df.to_excel('경로.xlsx')프로젝트_서울 CCTV, 프로젝트_서울 범죄1
“이글은제로베이스데이터취업스쿨의강의자료일부를발췌하여
작성되었습니다.”

Hello