셀프주요소가 정말 저렴한가요?
<이전 프로젝트와 다른 코드와 데이터를 얻을 때의 시행착오>
- 목표 데이터
- 주유소명, 주소, 브랜드, 휘발유 가격, 경유 가격,
셀프, 충전소, 경정비, 편의점 , 24시간 운영 여부 - 구, 위도, 경도
- 주유소명, 주소, 브랜드, 휘발유 가격, 경유 가격,
- 엑셀 파일 다운로드가 아닌, 크롤링 코드로 데이터를 수집
# selenium
# 서울 선택(서울만 선택하면 되기에 다른과정 생략)
driver.find_element(By.CSS_SELECTOR,'#SIDO_NM0 > option:nth-child(2)').click()
# 구, 갯수 확인(25)
gu_raw = driver.find_element(By.ID,'SIGUNGU_NM0') #부모 태그
gu_list = gu_raw.find_elements(By.TAG_NAME,'option') #자식 태그
gu_names = [gu.get_attribute('value') for gu in gu_list if gu.get_attribute('value')] #if문 공백 제거
len(gu_names),gu_names
- 시행착오 1> 강남구에 있는 각 주유소 정보를 해당 웹페이지에서 얻으려고 함
- sampling(강남구)
- 주유소 이름이 제대로 안나오고 셀프여부 등 부가정보를 얻을 수 없음
- 해결> 각 주유소를 클릭하여 하위페이지에서 데이터를 얻음
: 솔직히 이렇게 하면 복잡하고 실행시간이 너무 오래걸릴 거라고 나의 해결 방법이 오답이 아닌가 고민함. 그래서 해설 강의를 보고 힌트를 얻을까 했지만 결론은 나의 방법이 맞음."나를 믿자!"
- sampling
# 하위 페이지(각 주유소 클릭)
first_content = driver.find_element(By.CSS_SELECTOR,'#body1 > tr:nth-child(1) > td.rlist > a')
action = ActionChains(driver)
action.click(first_content)
action.perform()
# BeautifulSoup 해당 페이지 html가져오기
contents = soup.select('#os_dtail_info > div.inner')
type(contents),contents # type: bs4.element
# 주유소명, 주소, 브랜드, 휘발유 가격, 경유 가격
title = contents[0].find('label',id="os_nm").text
# 셀프 여부(self 변수명은 Python 내부 예약어)
self_ch = 'Y' if contents[0].find(id="self_icon") else 'N'
# 세차장 여부, 충전소 여부, 경정비 여부, 편의점 여부, 24시간 운영 여부
wash = 'Y' if not contents[0].find(id="cwsh_yn").get('src').endswith('_off.gif') else 'N'
- 시행착오2> != '*_off.gif'
wash ='Y' if contents[0].find(id="cwsh_yn").get('src') != '*_off.gif' else 'N'
- 해결> if not ~ .endswith()
wash = 'Y' if not contents[0].find(id="cwsh_yn").get('src').endswith('_off.gif') else 'N'
- 하위페이지 반복문
- 시행착오3> selenium으로 각 주유소 선택 후 find_element(By,CSS)를 이용하여 바로 정보를 찾으려고 함.
하지만 time.sleep을 아무리 줘도 자꾸 "TimeoutException"-> selenium의 시간문제!- 해결> BeautifulSoup을 사용하여 직접 페이지 소스를 파싱
- 시행착오4-1> fomat안하고 바로 반복문 사용
- 시행착오4-2> 위에서 부가정보 가져오는것처럼 contents[0]사용
for i in range(1,11): contents = driver.find_elements(By.CSS_SELECTOR,'#body1 > tr:nth-child(i) > td.rlist > a') # 각 주유소 클릭 action = ActionChains(driver) action.click(contents) action.perform() # html가져오기(BeautifulSoup으로 soup변수에 넣음) contents = soup.select('#os_dtail_info > div.inner') title = contents[0].select_one('#os_nm').text wash = 'Y' if not contents[0].find(id="cwsh_yn").get('src').endswith('_off.gif') else 'N': contents에는 inner 클래스를 가진 여러 요소들이 리스트로 들어가게 되며, 이후에 contents[0]을 통해 첫 번째 요소에 접근하고 있습니다. 그러나 예상한 대로 첫 번째 요소가 아닌 경우에는 해당 코드에서 에러가 발생할 수 있습니다.
- 해결1> selector=f ' { } '
- 해결2> soup.select_one으로 하나만 가져오기
for i in range(1:11): selector=f'#body1 > tr:nth-child({i}) > td.rlist > a' contents = drive.find_elements(By.CSS_SELECTOR,selector) action = ActionChains(diver) action.click(contents) action.perfornm # html가져오기(BeautifulSoup으로 soup변수에 넣음) contents = soup.select_one('#os_dtail_info > div.inner') title = contents.select_one('#os_nm').text wash = 'Y' if not contents.find(id='cwsh_yn')['src'].endswith('_off.gif') else 'N'
- 전체 반복문
- 시행착오5> titles=[]을 반복문 안에 넣고 시행하여 리스트 안 내용이 리셋이됨
- 해결> 제일 바깥에 빈 리스트 지정 후 append
# 구 선택
titles=[]; brands=[]; address_s=[]; gasolines=[]; diesels=[]; selfs=[]
washs=[]; charges=[]; repairs=[]; stores=[]; all_times=[]
for gu in tqdm(range(2,len(gu_names)+2)): # 구 갯수
gu_selector= f'#SIGUNGU_NM0 > option:nth-child({gu})'
driver.find_element(By.CSS_SELECTOR,gu_selector).click()
time.sleep(2)
station_cnt = len(driver.find_elements(By.CSS_SELECTOR,'#body1 > tr'))
# 각 구마다 주유소 수 확인
# 각 주유소 부가정보 데이터 얻어오기
for i in range(1, station_cnt+1): # 주유소 갯수
content_selector = f'#body1 > tr:nth-child({i}) > td.rlist > a'
content_click = driver.find_element(By.CSS_SELECTOR, content_selector)
action = ActionChains(driver)
action.click(content)
action.perform()
time.sleep(3)
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
contents = soup.select_one('#os_dtail_info > div.inner')
# 주유소명, 주소, 브랜드, 휘발유 가격, 경유 가격, 셀프, 세차장, 충전소, 경정비, 편의점, 24시간 운영 여부
title = contents.select_one('#os_nm').text
brand = contents.select_one('#poll_div_nm').text
address = contents.select_one('#rd_addr').text
gasoline = contents.select_one('#b027_p').text
diesel = contents.select_one('#d047_p').text
self_status = 'Y' if contents.find(id='self_icon') else 'N'
wash = 'Y' if not contents.find(id='cwsh_yn')['src'].endswith('_off.gif') else 'N'
charge = 'Y' if not contents.find(id='lpg_yn')['src'].endswith('_off.gif') else 'N'
repair = 'Y' if not contents.find(id='maint_yn')['src'].endswith('_off.gif') else 'N'
store = 'Y' if not contents.find(id='cvs_yn')['src'].endswith('_off.gif') else 'N'
all_time = 'Y' if not contents.find(id='sel24_yn')['src'].endswith('_off.gif') else 'N'
titles.append(title)
brands.append(brand)
address_s.append(address)
gasolines.append(gasoline)
diesels.append(diesel)
selfs.append(self_status)
washs.append(wash)
charges.append(charge)
repairs.append(repair)
stores.append(store)
all_times.append(all_time)
driver.quit()- len()으로 리스트 아이템 수 확인
- DataFrame
- 주소를 기준으로 구 뽑아 반복문'gu'컬럼 생성(+unique() 확인)
시행착오6 & 해결> 가격이 object(0,000)로 되어있어
: station['Price']= station['Price'].str.replace(',', '')후에
-> astype(int)로 바꿈
- google API(위도, 경도) 'lat','lng'컬럼
- 완성!
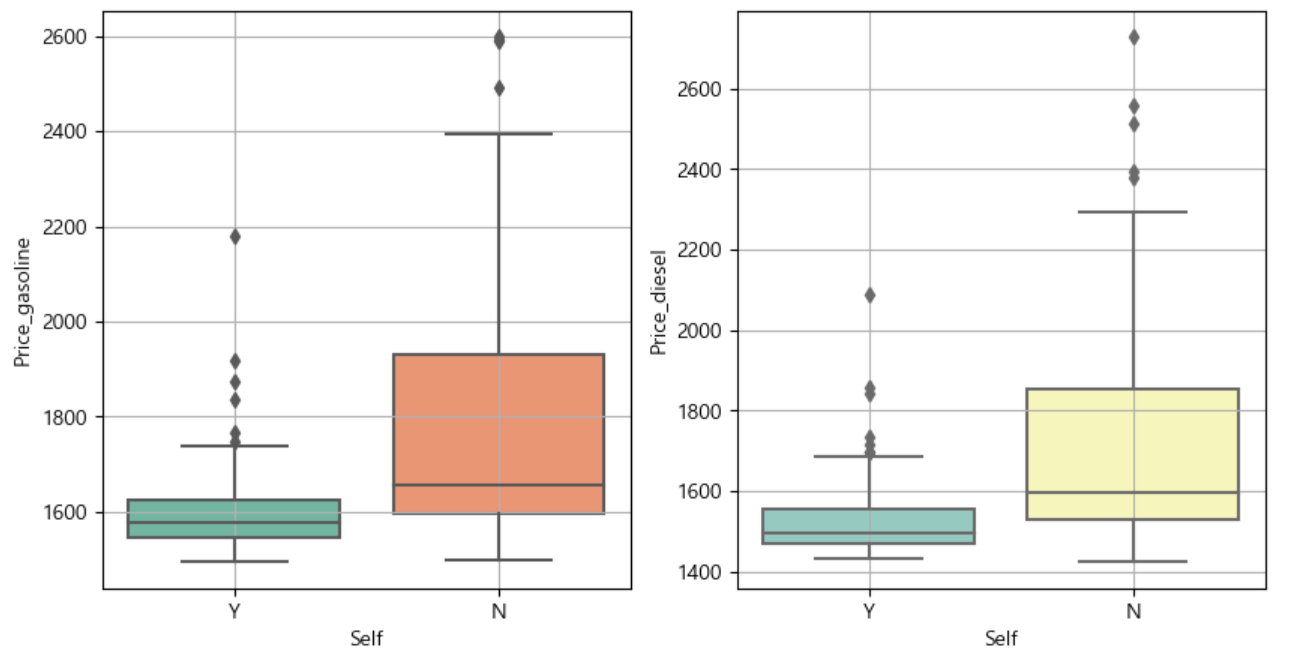
휘발유와 경유 가격이 셀프 주유소에서 정말 저렴한지 분석 결과
느낀점:
- 나 자신의 방법을 믿을것
- 코드는 오픈북, 남의 코드를 보고 쓰는 것은 안 좋은 게 아니다 모방은 나쁜 게 아니다 습득을 위한 모방을 필수!
- 데이터분석가의 직업을 생각하면 첫째도 분석 둘째도 분석이다. 또한 남에게 내가 찾은 분석결과를 잘보여줘야 된다. 그러기위해서 그래프는 필수!
실컷 데이터 전처리하고 막상 분석을 하려고 보니 무슨 그래프를 그려줘야 될지 모르겠다..

Hello