Project5. Population_제로베이스 강의
.is_copy = False.items()Cartogramfillnaimport warningsnp.abs()plt.annotate( )setsplit( ),splitlines( )stackzip(*path)지역별 ID
EDA Project
목록 보기
7/7
인구현황과 인구소멸위험도 분석
-
인구 소멸 위기 지역이란? 젊은 여성 인구 < 노인 인구 50%
- '한국의 지방소멸'에 관한 7가지 분석 보고서(이상호 연구의원)의 분석 방법으로 65세 이상 노인 인구와 20-39세 여성 인구와 비교. -
카르토그램 Cartogram(지리적 배치 유지 + 지역별 인구현황과 비례)
: 각 시도별 경계선json(LucyPark님) + 다른 Cartogram 참고(혜식Hyeshik 블로거의 버거 지수) + 각 지역 고유한 ID부여(제로베이스 강의)
1. 목표
- 인구 소멸 위기 지역 파악
- 인구 소멸 위지 지역의 지도 표현
- 지도 표현에 대한 카르토그램
(cf. 사실 Folium이 경각심을 더 높여줌)
- 지도 표현에 대한 카르토그램
2. 데이터 개요
1. 데이터 확보
https://kosis.kr/index/index.do (KOSIS 국가통계포털)
- 본 프로젝트는 강의 data 사용
2. 데이터 확인 및 전처리
Python에서 경고 메시지를 무시
import warnings warnings.filterwarnings(action='ignore') 또는 warnings.simplefilter(action='ignore', category=FutureWarning)fillna( ) : Nan값 채우기
- 옵션 method : {'backfill', 'bfill' / 'ffill' / None}, default None Method
# fillna_df.fillna(value=0) #기본형태로 Nan값을 '0'으로 fillna_df.fillna(method='pad') #nan값을 앞의 값 #pad = ffill fillna_df.fillna(method='backfill') #nan값을 뒤의 값 #자료에 따라 axis=0옵션도 활용가능
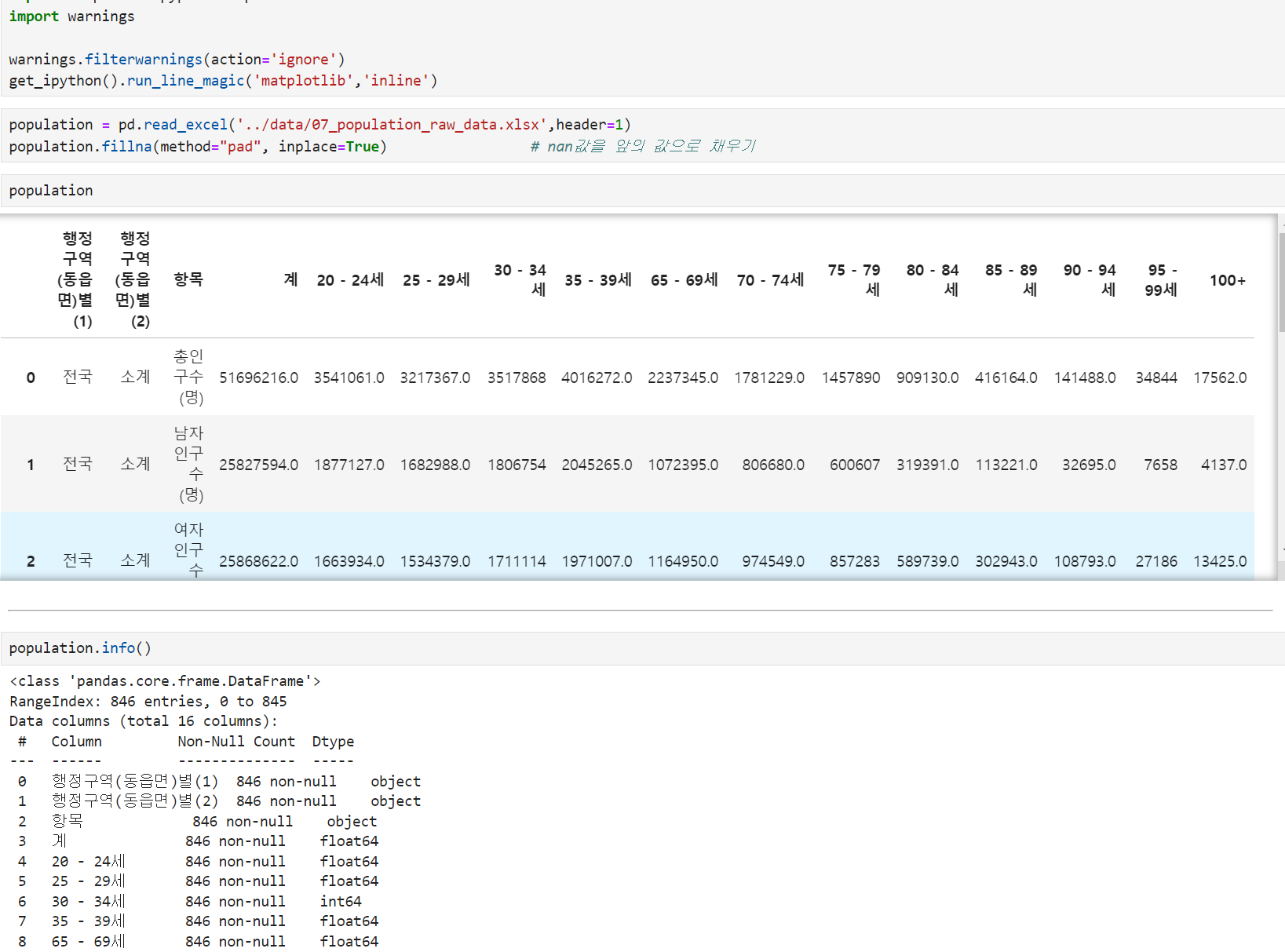
# warningX 해당 데이터가 실제로 원본 데이터를 복사. 원본 데이터 영향X
population.is_copy = False
# 컬럼 이름 변경(광역시도, 시도, 구분, 인구수)
population.rename(columns={~},inplace=True)
# 필요없는 줄 삭제
population = population[population['시도'] != '소계']
# 특정값 지정 후 수정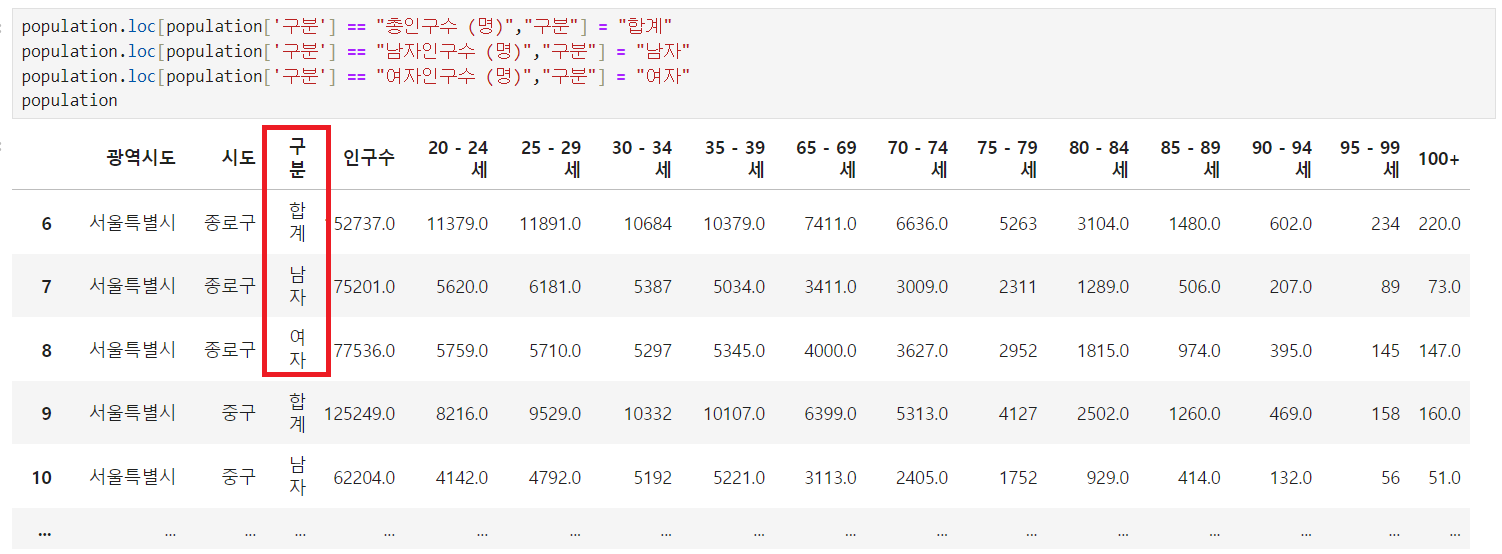
- 소멸 위기 지역을 조사하기 위한 데이터 추가
-population['20-39세'] 여성 인구 / population['65세이상'] 인구 - pivot table
pop = pd.pivot_table(
data=population,
index=['광역시도','시도'],
columns='구분',
values=['인구수','20-39세','65세이상']
)
# 소멸 비율 계산 (= 20-39세 여자 / (65세이상 합계/2))
# 소멸위기 지역 컬럼 생성
pop['소멸위기지역'] = pop['소멸비율'] < 1.0
pop[pop['소멸위기지역'] == True] #마스킹
# reset_index후 columns.get_level로 컬럼명 수정
3. 지도 시각화를 위한 지역별 ID 추가
- 만들고자 하는 ID의 형태: 서울 중구, 서울 서초, 통영, 포항 북구, 인천 남동, 안양 만안, 안양 동안, 안산 단원 ...
si_name = [None] * len(pop) # [264개의 None]
# iterrows활용
pop['ID'] = si_name
# 점검시 ID는 유일한것이기에 중복값이 없고 그러면 len이 264개
len(pop['ID'].unique())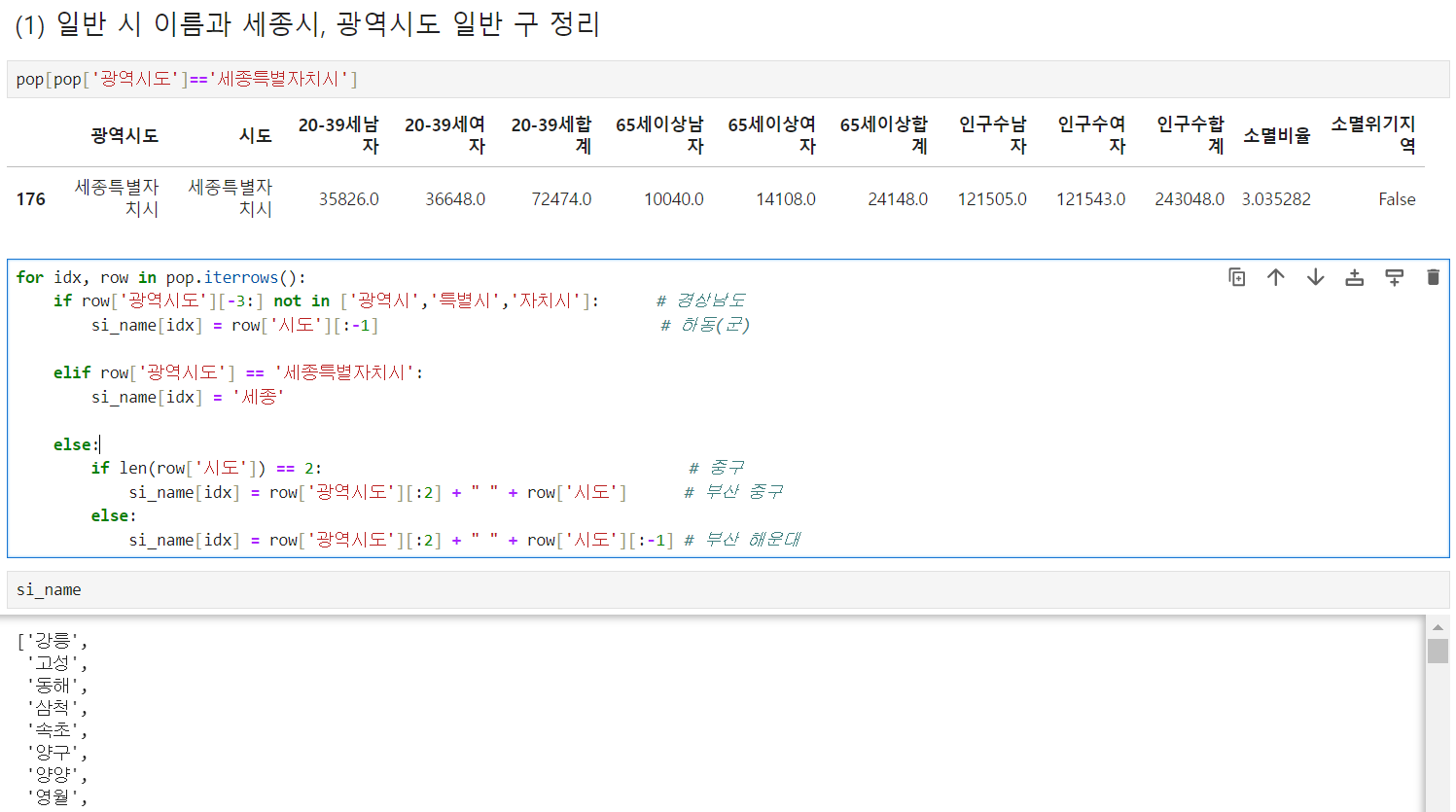
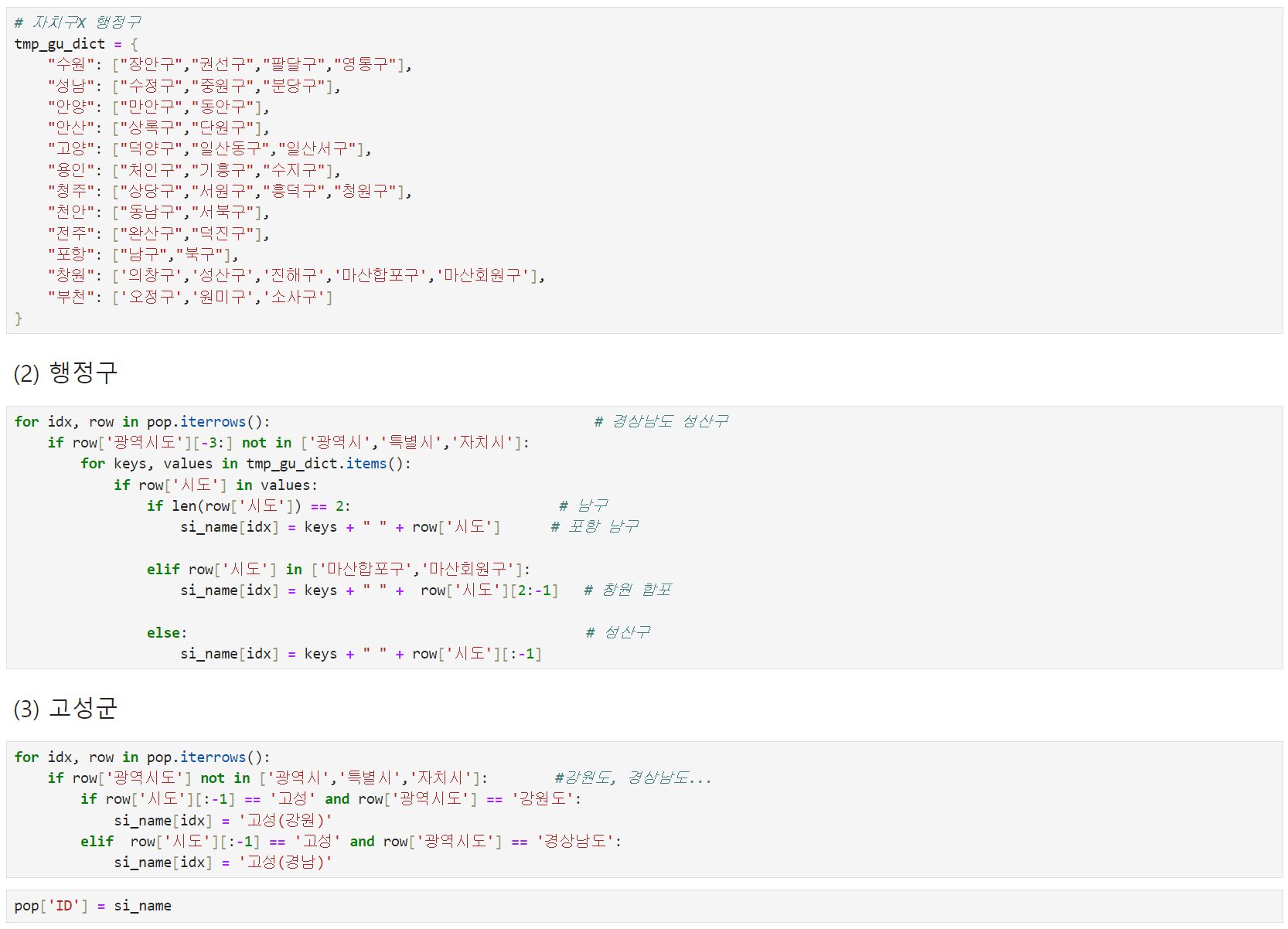
- 최종 데이터
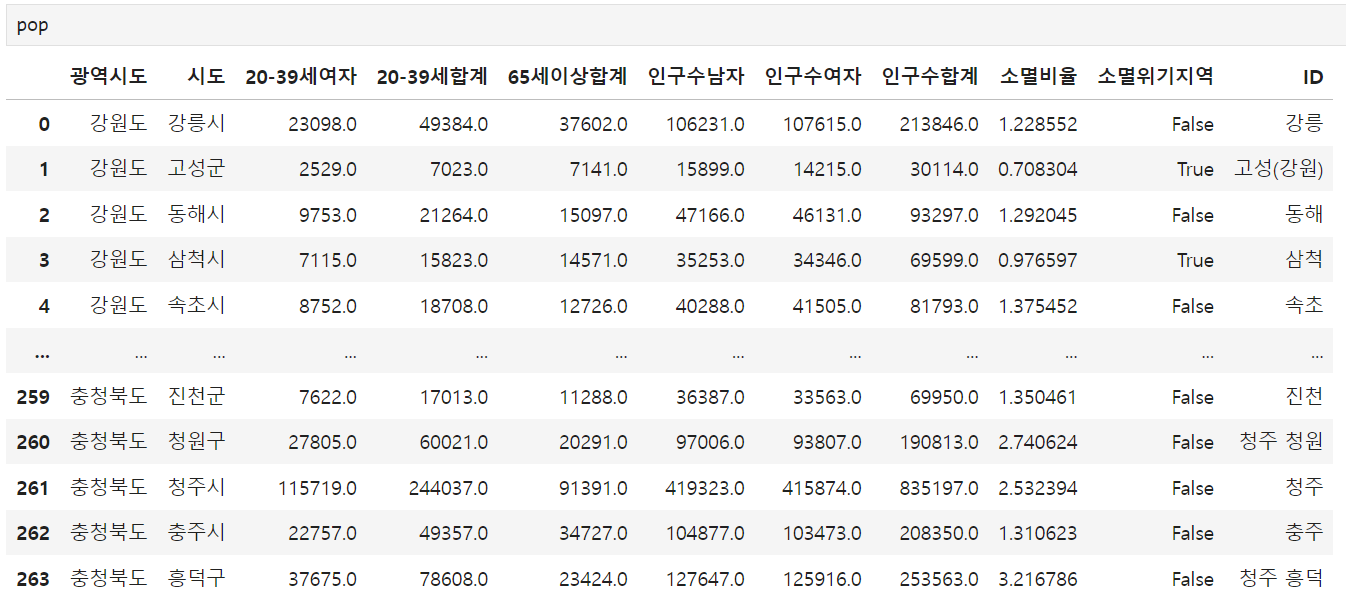
3. 시각화
1. 지도 그리기(카르토그램) :엑셀과 pivot_table(stack) 활용
- 엑셀 활용(제로베이스 강사님 자료)
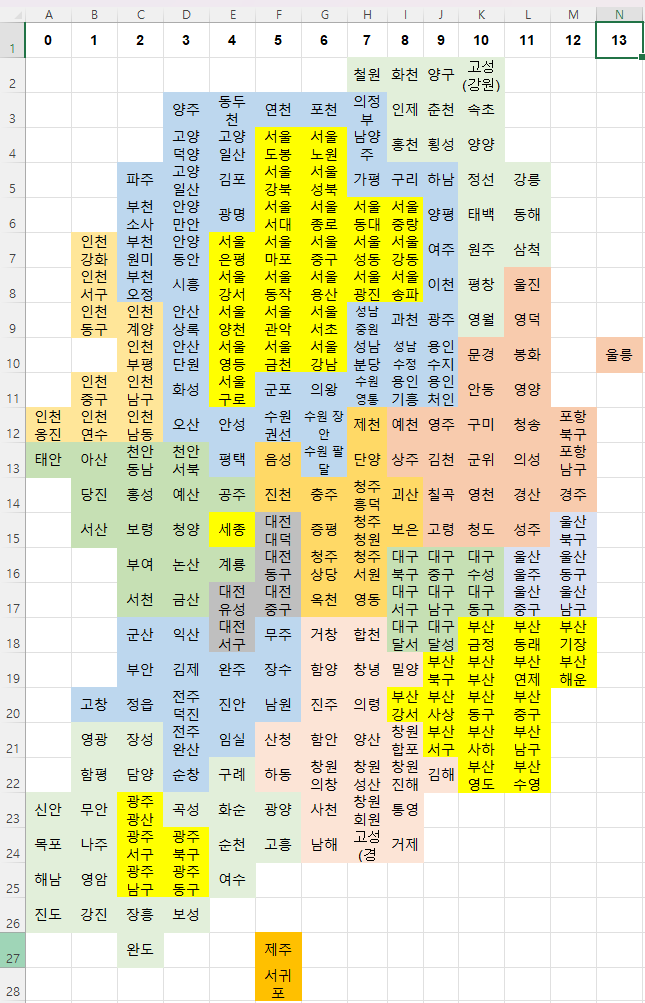
- stack( )
: pivot_table의 반대라고 생각할 수 있음. 데이터를 분해해서 알려줌(엑셀의 좌표)
그로인해, plt그릴때 (x,y)좌표와 각 지역의 이름을 구할 수 있음
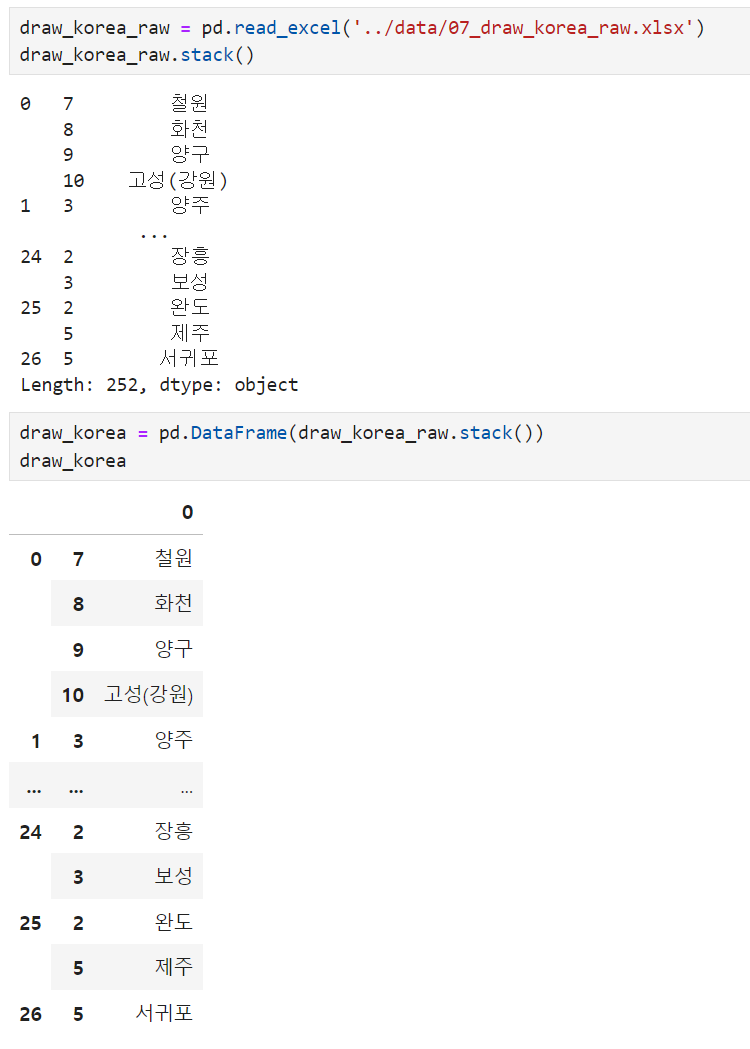
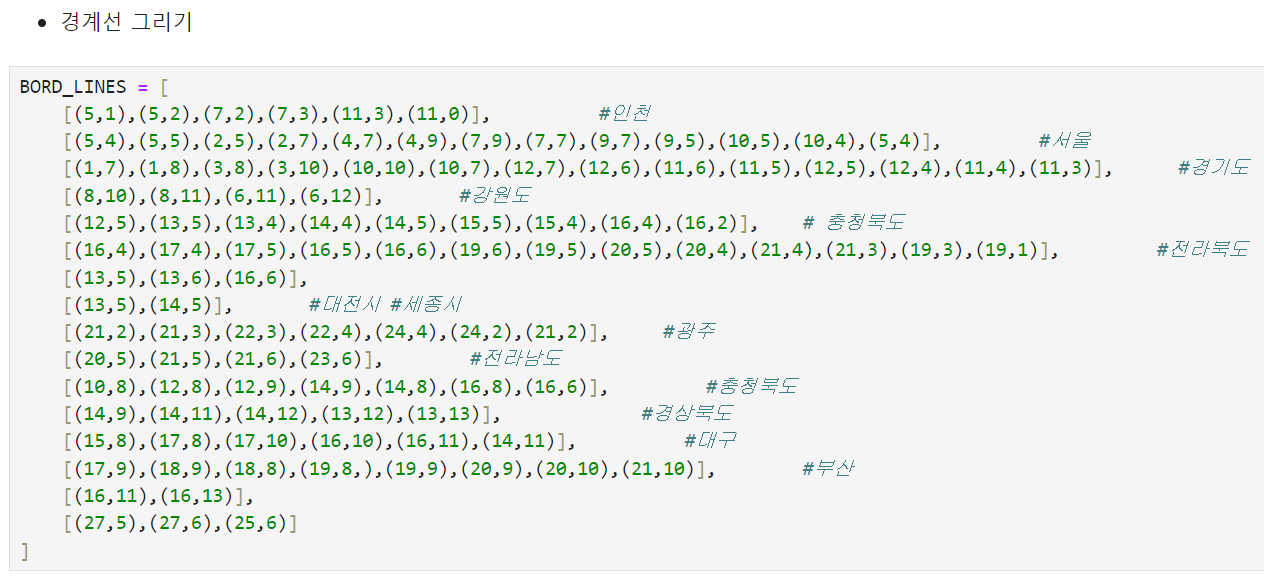
- reset_index후 rename(x,y,ID)
- 경계선
(1) 밑그림 그리기
- def함수로 만들기 -> plot_text_simple(draw_korea)
# 지도 위에 시도의 이름(dispname) 표현
for idx,row in draw_korea.iterrows():
if len(row['ID'].split()) == 2: # 서울 서대문
dispname = '{}\n{}'.format(row['ID'].split()[0],row['ID'].split()[1])
elif row['ID'][:2] == "고성": #지도상에서 강원 고성과 경남 고성 구분X
dispname = "고성"
else:
dispname = row['ID']
# 폰트사이즈
if len(dispname.splitlines()[-1]) >= 3: # 3글자면 서귀포
fontsize, linespacing = 9.5, 1.5
else:
fontsize, linespacing = 11, 1.2
plt.annotate( # 그래프에 주석달기
dispname,
(row['x'] + 0.5, row['y'] + 0.5), # 조금 떨어져서
weight='bold',
fontsize= fontsize,
linespacing= linespacing,
ha='center', # 수평정렬
va='center' # 수직정렬
)-split( ),splitlines( )
- def함수 simpleDraw(draw_korea)
# 지도 경계선과 시도이름
plt.figure(figsize=(8,11))
plot_text_simple(draw_korea)
for path in BORD_LINES:
ys, xs = zip(*path) # x좌표, y좌표 모아서 집합(plot그리려면 필요)
plt.plot(xs, ys, c= "black", lw=1.5)
plt.gca().invert_yaxis() # y축 거꾸로
plt.axis("off") # 축의 선 없애기
plt.tight_layout() # 표들이 넓혀짐
plt.show()
(2) ID 검증 작업(차집합이 없어야 됨)과 merge(on='ID')
- 차집합은 교환법칙이 성립하지 않는다! => 반대의 경우도 확인
# set() 집합 기능(정렬 기능도 있음)
set(draw_korea['ID'].unique()) - set(pop['ID'].unique()) # set()
set(pop['ID'].unique()) - set(draw_korea['ID'].unique()) # {'고양','부천','창원'...}
-> 차집합 확인(tmp): 이 값들은 '창원=성산구+마산+진해'처럼 합계인 것으로 확인
-> 지우기_for문(pop.drop(pop[pop["ID"] == tmp].index))-set( ) : 집합을 만들어주는 함수로 정렬의 기능도 있음
(3) 본 그림 그리기
- 위치에 값을 씌운뒤 colormap으로 변환
- 색상을 만들 때, 최소값을 흰색
- 인자(blockedMap: 인구현황(pop)/targetData: 그리고싶은 컬럼)
글자 색상 정의 함수
# 지도 위의 각 지역 이름 색상 정의
def get_data_info(targetData, blockedMap):
# 글자색깔이 흰색으로 바뀌는 구분값
whitelabelmin = (
max(blockedMap[targetData]) - min(blockedMap[targetData])
) * 0.25 + min(blockedMap[targetData])
vmin = min(blockedMap[targetData])
vmax = max(blockedMap[targetData])
#x,y좌표값에 시도 이름 대신 target컬럼의 값이 들어감
mapdata = blockedMap.pivot_table(index='y',columns='x', values=targetData)
return mapdata, vmax, vmin, whitelabelmin# 음수 양수 둘다 있을시 0을 센터(화이트색상이 센터기준으로 몰리기에)
def get_data_info_for_zero_center(targetData, blockedMap):
# 글자가 하얀색으로 바뀌는 기준 새로 잡기
whitelabelmin = 5
# 값이 음수일 수 있기에 절대값으로 잡기
tmp_max = max(
[np.abs(min(blockedMap[targetData])), np.abs(max(blockedMap[targetData]))]
)
vmin, vmax = -tmp_max, tmp_max
mapdata = blockedMap.pivot_table(index='y',columns='x', values=targetData)
return mapdata, vmax, vmin, whitelabelmin카르토그램 함수
# 지도 위에 시도의 이름(dispname) 표현(위랑 같음)
def plot_text(targetData, blockedMap, whitelabelmin):
for idx,row in blockedMap.iterrows():
if len(row['ID'].split()) == 2:
dispname = '{}\n{}'.format(row['ID'].split()[0],row['ID'].split()[1])
elif row['ID'][:2] == "고성":
dispname = "고성"
else:
dispname = row['ID']
if len(dispname.splitlines()[-1]) >= 3:
fontsize, linespacing = 9.5, 1.5
else:
fontsize, linespacing = 11, 1.2
# 글자 색깔을 지정
annocolor = 'white' if np.abs(row[targetData]) > whitelabelmin else 'black'
# 그래프에 주석달기
plt.annotate(
dispname,
(row['x'] + 0.5, row['y'] + 0.5),
weight='bold',
color = annocolor, #흰, 검으로
fontsize= fontsize,
linespacing= linespacing,
ha='center',
va='center'
)# 지도 경계선과 시도이름,
def drawKorea(targetData, blockedMap, cmapname, zeroCenter=False):
# 디폴트로 잡음
if zeroCenter: # 0이 중심(음,양수가 있는)
masked_mapdata, vmax, vmin, whitelabelmin = get_data_info_for_zero_center(targetData, blockedMap)
if not zeroCenter: # 0이 중심이 아닌 최소값
masked_mapdata, vmax, vmin, whitelabelmin = get_data_info(targetData, blockedMap)
plt.figure(figsize=(8,11))
# 각 그리드의 색상채우기(컬럼 값에 대비한 색상)
plt.pcolor(masked_mapdata, vmin=vmin, vmax=vmax, cmap=cmapname, edgecolor="#aaaaaa", linewidth=0.5)
# 시도 이름
plot_text(targetData, blockedMap,whitelabelmin)
# 경계선
for path in BORD_LINES:
ys, xs = zip(*path)
plt.plot(xs, ys, c= "black", lw=1.5)
plt.gca().invert_yaxis() # y축 거꾸로
plt.axis("off") # 축의 숫자 없애기
plt.tight_layout() # 표들이 넓혀짐
cb = plt.colorbar(shrink=0.1, aspect=10)
cb.set_label(targetData)
plt.show()(4) 적용

drawKorea("인구수합계", pop, "Blues")
pop['소멸위기지역'] = [1 if con else 0 for con in pop['소멸위기지역']] # True면 1 False면 0
drawKorea("소멸위기지역", pop, "Reds")
pop['여성비'] = (pop['인구수여자'] / pop['인구수합계'] -0.5) *100; drawKorea("여성비", pop, "RdBu",zeroCenter=True)
pop['2030여성비'] = (pop['20-39세여자'] / pop['20-39세합계'] -0.5) *100; drawKorea("2030여성비", pop, "RdBu",zeroCenter=True)2. 지도 그리기(folium)
# 인덱스 ID로 다시 데이터프레임 정리
pop_folium = pop.set_index("ID")
geo_path = '경로.json'
geo_str = json.load(open(geo_path, encoding='utf-8'))
# 소멸위기지역 지도 시각화
my_map = folium.Map([36.2002,127.054], zoom_start=7)
folium.Choropleth(
geo_data = geo_str,
data=pop_folium['소멸위기지역'],
key_on='feature.id',
columns= [pop_folium.index,pop_folium['소멸위기지역']],
fill_color= 'PuRd'
).add_to(my_map)
my_map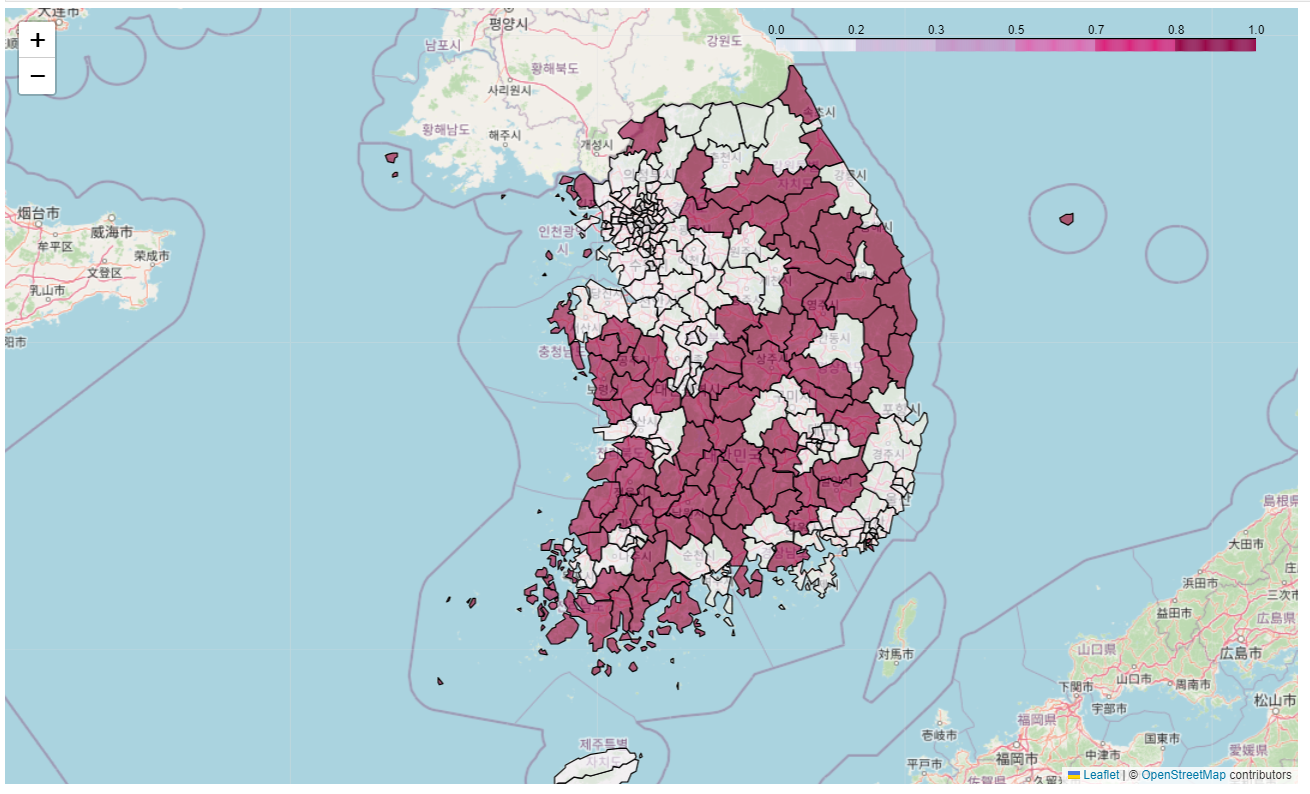
< 새로 배운 함수 >
import warnings
fillna( )
.is_copy = False
.items()
.stack()
np.abs() 절대값
zip(*path) 집합 기능(정렬 기능도 있음)
split( ) / splitlines( )draw_korea['ID'][13].split() : ['고양', '일산동'] draw_korea['ID'][13].splitlines() : ['고양 일산동']< 새로 배운 코드 >
population.loc[population['구분'] == "총인구수 (명)","구분"] = "합계" population.loc[population['구분'] == "남자인구수 (명)","구분"] = "남자" population.loc[population['구분'] == "여자인구수 (명)","구분"] = "여자"

Hello