기본형태
from selenium import webdriver
driver = webdriver.Chrome('경로chromedriver.exe') #크롬 드라이버 위치
driver.get("https://접속하려는 사이트 url/")
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
action = ActionChains(driver)
action.동적 기능.perform()
import time #time.sleep() 필요
from bs4 import BeautifulSoupinstall(Window, Chrome기준)
- conda install selenium
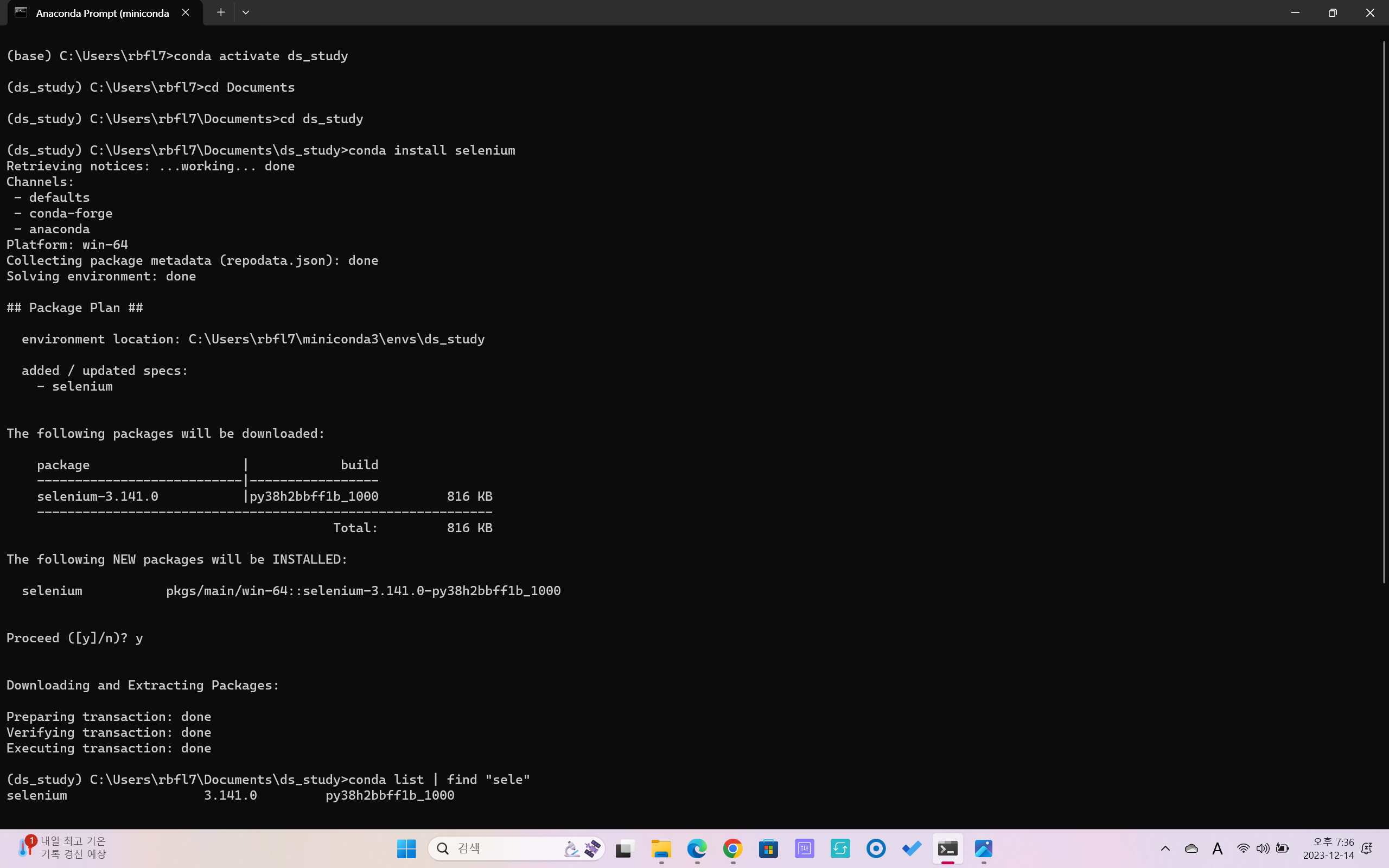 - cf. list확인할 때 conda(또는 pip) list | find '찾으려는 것'(mac: greb)
- cf. list확인할 때 conda(또는 pip) list | find '찾으려는 것'(mac: greb)
- cf. 디렉토리 목록 및 용량 확인 dir(mac: ls) - 현재 사용중인 chromedriver 크롬 버전정보 확인 후 크롬 드라이버 설치
(.exe파일 필요)
from selenium import webdriver
'웹브라우저를 원격조작하는도구'로 웹브라우저를 test하기 위해 만들어진 모듈이지만, 그중 동적 페이지 기능(ActionChains)을 응용하여 웹크롤링에 활용
또한, BeautifulSoup으로 해결할수없는 때(ex.접근할웹주소를알수없을때)사용
- 웹 브라우저 =/= 웹 드라이버 (셀레니움으로 웹 드라이버를 코드로 제어)
- 참고 사이트: selenium, action_chains / 예시 사이트:pinkwink

웹브라우저 불러오기 및 Basic
from selenium import webdriver
#크롬 드라이버 위치(정석)
driver = webdriver.Chrome(executable_path='경로/chromedriver.exe')
driver.get("https://pinkwink.kr/") # 창 켜기
driver.quit() # 창 끄기
driver.maximize_window() # 화면 최대 크기 설정
driver.minimize_window() # 화면 최소 크기 설정
driver.set_window_size(600,600) # 화면 사용자설정 크기 설정
driver.refresh() # 새로고침
driver.back() # 뒤로 가기
driver.forward() # 앞으로 가기
driver.switch_to.window(driver.window_handles[-1]) # 탭 이동 : 인덱스 번호로 이동
len(driver.window_handles) # 탭 handles할 수 있는 길이 확인
driver.close() # 탭 하나씩 닫기 : 닫으려는 탭 이동 후 닫기(아니면 오류)
# 브라우저를 끌 때는 close()보다 quit()으로 완전 닫기할 것
driver.save_screenshot('경로&이름.png') # 현재 보이는 화면 스크린샷 저장 : 위치생략 가능driver.find_element(By.~,'~')
from selenium.webdriver.common.by import By
# CSS_SELECTOR이용
first_content = driver.find_element(By.CSS_SELECTOR,'경로') # 카피한 셀럭터를 하나씩 줄여보면서 실행될때까지 줄여 코드간단화 필요
first_content.click() # 클릭
- By.CSS_SELECTOR
- By.XPATH
- XPATH는 BeautifulSoup에는 없는, Selenium에만 사용가능
- XPATH값이 " " 로 되어 있는 경우가 있으니깐 처음에 묶을때 ''를 묶고 붙여넣을것 (반대의경우도 있을수있으니깐 확인해보고 반대로 할것))`
# '//' : 최상위 # '*' : 자손 태그 # '/' : 자식 태그 # 'div[1]' : div 중 1번째 태그 # 예) '//*[@id="main_pack"]/section[2]/div/ul/li[1]/div'
action_chains 동적 페이지 기능
from selenium.webdriver import ActionChains
action = ActionChains(driver)
# 특정 태그 지점까지 스크롤 이동
action.move_to_element(driver.find_element(By.~,'경로')).perform()
# 동적 페이지 기능(서버 내부에서 변화)인 있는 검색창 클릭
action.click(driver.find_element(By.CSS_SELECTOR,'.search'))
action.perform()
자바스크립트 코드 이용
# 새로운 탭 생성
driver.execute_script('window.open("https://~")')
# 스크롤 가능한 높이(길이) 확인
driver.execute_script('return document.body.scrollHeight')
# 화면 스크롤 하단 이동
driver.execute_script('window.scrollTo(0,document.body.scrollHeight);')
# 화면 스크롤 상단이동
driver.execute_script('window.scrollTo(0,0);')검색어 입력
keyword = driver.find_element(By.CSS_SELECTOR,'검색창 경로')
keyword.clear()
keyword.send_keys('검색어')
search_btn = driver.find_element(By.CSS_SELECTOR,'버튼 경로')
search_btn.click()
BeautifulSoup + Selenium
from bs4 import BeautifulSoup
# 현재 화면의 Html코드 가져오기
driver.page_source
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
# -> 이제 soup으로 find(),select()다 가능프로젝트_셀프 주유소
“이글은제로베이스데이터취업스쿨의강의자료일부를발췌하여
작성되었습니다.”

Hello