기본형태
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
from urllib.request import urlopen,Request # 또는 import requests
# 필요시 req =
response =
soup = BeautifulSoup(response, "html.parser")간단히 < html > check!
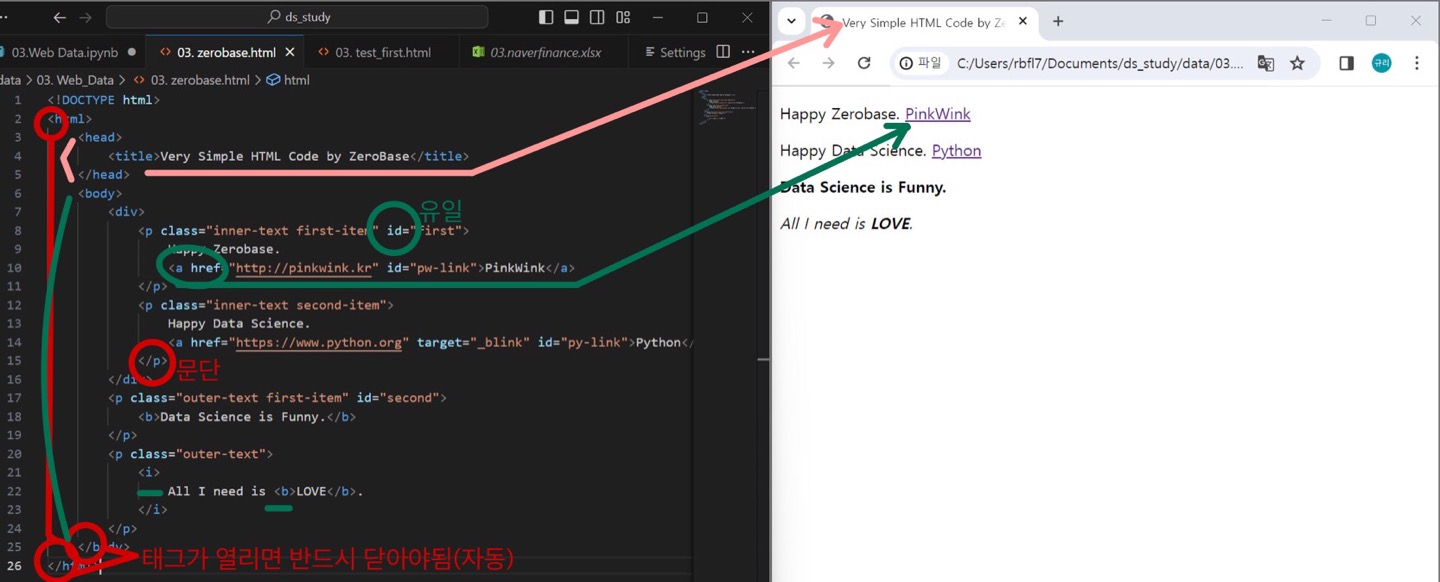
- 태그가 열리면 닫아야함
- p태그: 문단
- a태그: href속성-링크
- id는 웹페이지만든사람이 부여 -> id속성은 유일 ->찾기 편함
from bs4 import BeautifulSoup
: 태그로 된 문서(ex. HTML)를 해석하는 모듈로 웹크롤링(웹데이터를 수집&정리)할때 유용하게 쓰임 BeautifulSoup
- install: conda install -c anaconda beautifulsoup4
html 불러오기 및 기본형태
- urllib: http프로토콜에 따라서 서버의 요청/응답을 처리하기 위한 모듈
- urllib.request: 클라이언트의 요청을 처리하는 모듈
- urllib.parse: url 주소에 대한 분석
http상태코드-위키백과 - 상태코드 확인: response.getcode(), response.code, response.status
- print(soup.prettify()) 생략가능
# 내가 만든 html
response =
soup = BeautifulSoup(response, "html.parser") #html 해석해주는 엔진:parser 多用
print(soup.prettify())# 다른데서 불러올 'url'
from urllib.request import urlopen,Request #Request: 한글url, user_agent사용
request = urllib.request.Request(url) # 요청 객체를 생성 (.format,header)
response = urlopen(url) # 변수명으로 response나 res 이용
# .read()함으로써 바로 읽어옴
response.status # 200(정상응답받음) : http상태코드
soup = BeautifulSoup(response, 'html.parser')
print(soup.prettify())
# 또다른 'url' 방법 : - !pip install requests필요!!
(requests 라이브러리는 요청 객체를 별도로 생성하지 않고도 간단히 요청을 보낼 수 있는 편리한 API를 제공)
import requests
response = requests.get(url) # requests.post()
response # status확인
# response.text, response.content로 해야됨
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())
# from urllib.request.Request- requests와 urllib.request은 모두 Python에서 HTTP 요청을 만들고 처리하는 데 사용되는 라이브러리 및 모듈 < chatGP검색 >
태그 확인 및 찾기
soup.head
soup.body
# p태그 찾기
soup.p
soup.find('p') #맨처음 하나만 찾아줌
soup.find_all('p') #전체를 찾아줌-리스트list형태
# p태그에서 class 찾기
soup.find('p', class_='') #class_주의!(예약어이기에)
soup.find('p',{'class':""})
soup.find('p','바로 클래스명')
soup.find('p',{'class':"",'id':""}) #다중조건
# class로만 찾기가능
soup.find_all(id='') #id는 유일해서 하나만 나오지만 이렇게 많이 사용
# 이외
soup.find_all(class_='')[0].text
soup.find_all('a')[0].get('href')
# text뽑기
soup.find('p','바로 클래스명').text.strip() #text만 뽑아서 공백지우기
soup.find_all(id='pw-link')[0].text #list이기에 offset & 반복문 & len()가능
soup.find_all('p')[0].string
soup.find_all('p')[0].get_text()
#예시
for each in soup.find_all('a'): #변수에 넣어서 사용가능
href = each['href'] #each.get('href')속성 추출가능
text = each.get_text()
print(text + ' => ' + href)
- soup.find_all('p')[0].string
: 첫 번째 문자열만 반환. 직접적인 텍스트만을 고려, 자식 요소들의 텍스트는 무시.
따라서, 자식 요소 여러 개 or 텍스트가 없는 경우: None으로 반환.
find() / select_one() 차이 find_all() / select() 차이
- find_all( ): 메서드의 첫 번째 인자로 찾고자 하는 태그 이름이나 속성을 지정
- select( ): CSS 선택자를 사용하여 요소
- 둘다 리스트로 반환
- 다만, select 메서드는 하나의 문자열로 CSS 선택자를 받아야 함!!
- soup.find_all('li','on') = soup.select('li.on')- class면 '.', id면 '#'
<크롬 개발자도구 활용>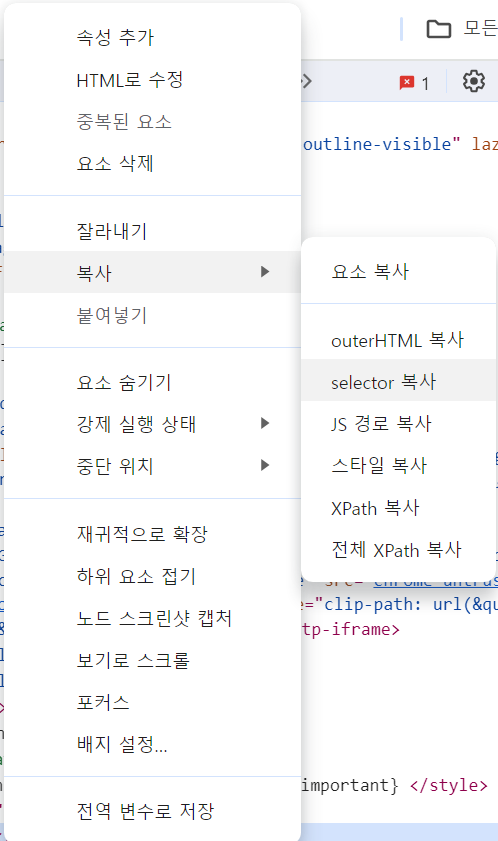
# select()
exchangeList = soup.select('#exchangeList > li')
len(exchangeList),exchangeList
exchangeList[0].select_one('.h_lst').text
# find()
findMethod = soup.find_all('ul',id='exchangeList')
findMethod[0].find_all('span','blind')[0].text
exchangeList[0].select_one('.head_info.point_dn > .blind').text
# 띄어쓰기가 되어있는것은 속성값이 2개라는 뜻 "class=head_info point_dn"
# > 가 없으면 모든 하위태그 중 첫번째 만난
# 좀 더 자세하고 싶으면 'div.head_info.point_dn > .blind' 확실하게 데이터를 가져옴
# link
link = exchangeList[0].select_one('a').get('href')
baseUrl = 'www.~'
baseUrl + linkurl이 한글이 포함된 경우
: 한글로 된 주소는 인코딩이 깨져서 나오기에 인코딩을 맞춰준다
-
방법1: url decode를 검색 이용
-
방법2: formating하기(quote()함수)
- from urllib.request import Request 하거나 import urllib한뒤!
html = 'https://~/{search_words}'
req = Request(html.format(search_words= urllib.parse.quote("한글")))
#한글 URL로 인코딩
response = urlopen(req)response = urlopen(url) -> 403 error(인가실패)
: 이 페이지 접속하기 위해 하나의 정보(페이지에따라 다름) 필요. (접근하고자 하는 사이트에서 사용자가 일반적인 이용자인지, 아닌지 확인하기 때문)
- 내가 직면한 문제는?
'어떤 웹브라우저를 써서 이 페이지를 접속하는지'에 대한 정보 필요! - 방법1:개발자도구-Network-Headers에 User-Agent:확인
#User-Agent(정석)쓰거나 쓰고있는 웹브라우저'Chrome'간단히 쓰면됨!
req = Request(url,headers={'User-Agent':'Chrome'})
response = urlopen(req)- 방법2:랜덤 사용 !pip install fake-useragent
from fake_useragent import UserAgent
ua=UserAgent()
ua.ie
req = Request(url,headers={'User-Agent':ua.ie})
response = urlopen(req)프로젝트_시카고 샌드위치, 프로젝트_셀프 주유소
참고: https://finance.naver.com/marketindex/
“이글은제로베이스데이터취업스쿨의강의자료일부를발췌하여 작성되었습니다.”

Hello