네이버 CLOVA - STT 활용
✔ 네이버 인공지능 CLOVA

- NAVER가 개발 및 서비스하고 있는 인공지능 플랫폼 서비스
- 음성인식, 자연어 처리, 얼굴 인식 등의 기능을 제공
→ 사용자와의 상호작용을 자연스럽게 만듦
✔ STT (Speech-To-Text)
- CLOVA Speech Recognition REST API (CSR REST API)
: HTTP 기반의 REST API로 제공하는 음성인식 API - 인식에 사용할 언어와 음성 데이터를 입력받고 그에 맞는 인식 결과를 텍스트로 반환
- 입력 음성 데이터 포맷은 mp3, aac, ac3, ogg, flac, wav을 지원
▶ STT API 활용
▷ Spring boot 사용 실행예제
package com.example.myweb.ex;
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
public class Main {
public static void main(String[] args) {
String clientId = "클라이언트 ID"; // Application Client ID";
String clientSecret = "클라이언트 시크릿 키"; // Application Client Secret";
try {
String imgFile = "C:\\Users\\HP\\OneDrive\\문서\\카카오톡 받은 파일\\1.m4a";
File voiceFile = new File(imgFile);
String language = "Kor"; // 언어 코드 ( Kor, Jpn, Eng, Chn )
String apiURL = "https://naveropenapi.apigw.ntruss.com/recog/v1/stt?lang=" + language;
URL url = new URL(apiURL);
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
conn.setUseCaches(false);
conn.setDoOutput(true);
conn.setDoInput(true);
conn.setRequestProperty("Content-Type", "application/octet-stream");
conn.setRequestProperty("X-NCP-APIGW-API-KEY-ID", clientId);
conn.setRequestProperty("X-NCP-APIGW-API-KEY", clientSecret);
OutputStream outputStream = conn.getOutputStream();
FileInputStream inputStream = new FileInputStream(voiceFile);
byte[] buffer = new byte[4096];
int bytesRead = -1;
while ((bytesRead = inputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, bytesRead);
}
outputStream.flush();
inputStream.close();
BufferedReader br = null;
int responseCode = conn.getResponseCode();
if(responseCode == 200) { // 정상 호출
br = new BufferedReader(new InputStreamReader(conn.getInputStream()));
} else { // 오류 발생
System.out.println("error!!!!!!! responseCode= " + responseCode);
br = new BufferedReader(new InputStreamReader(conn.getInputStream()));
}
String inputLine;
if(br != null) {
StringBuffer response = new StringBuffer();
while ((inputLine = br.readLine()) != null) {
response.append(inputLine);
}
br.close();
System.out.println(response.toString());
}
} catch (Exception e) {
System.out.println(e);
}
}
}- 원하는 음성 파일 경로를 넣으면 text로 나옴
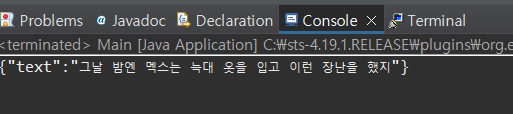
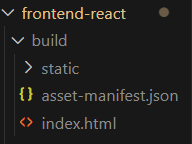
▷ React 빌드
- react에서 프로젝트 생성 후
npm run build - build 폴더의 static 폴더 확인
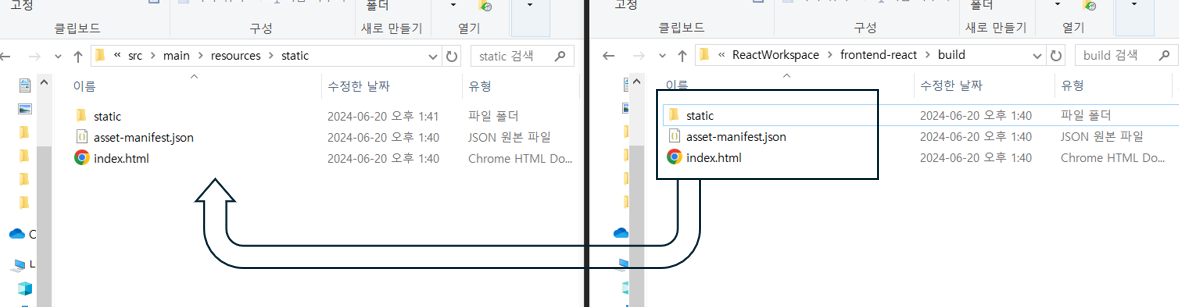
▷ Spring boot 에 빌드된 React 넣기
- Spring boot의
src/main/resources/static에 React의build폴더 붙여넣기
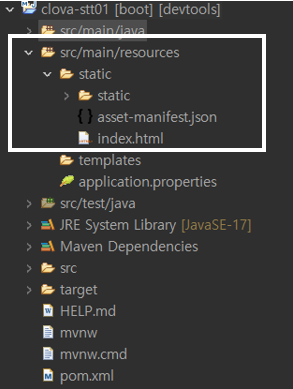
▷ Spring Boot App 실행
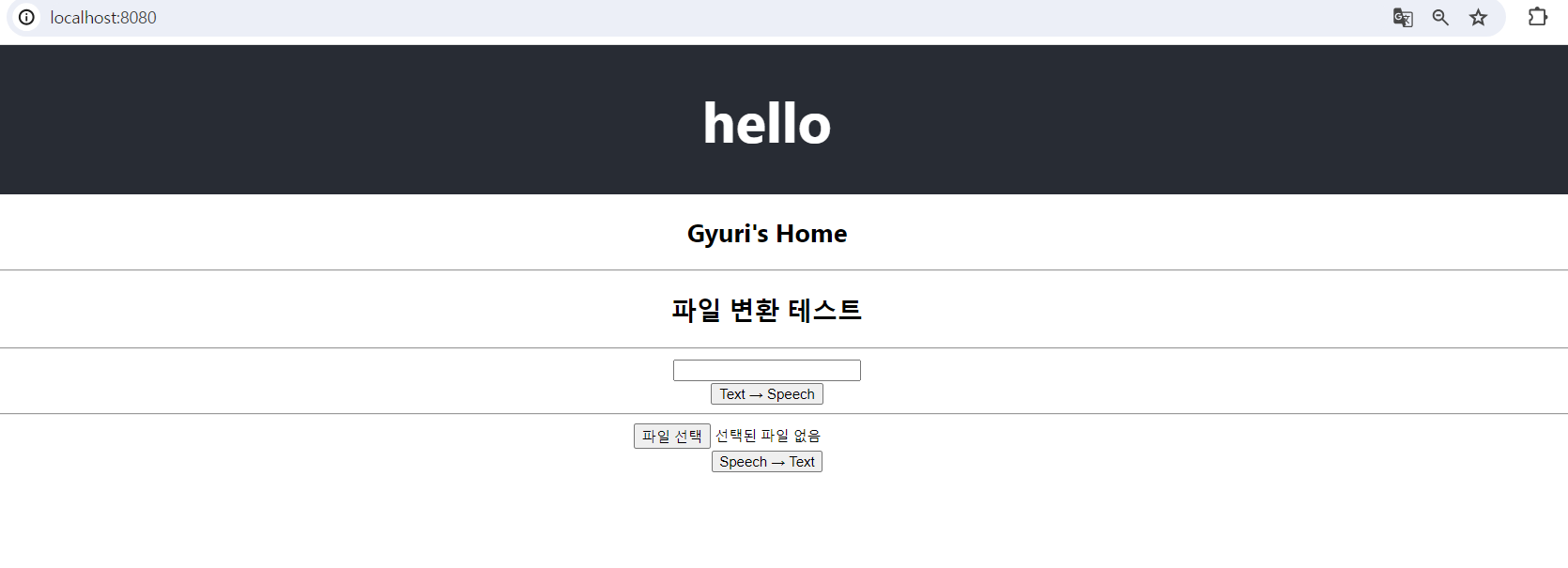
- static폴더의 index.html이 우선적으로 보여짐
- 즉, React 화면이 8080 포트로 보여짐
▷ Spring boot 빌드
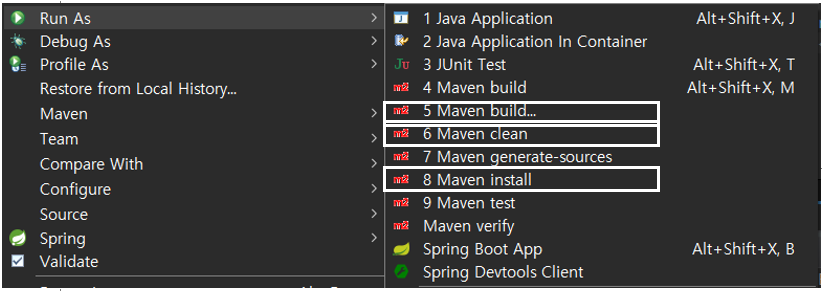
1. Maven clean
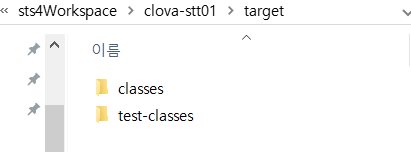
- Maven clean 하면 target 폴더가 비워짐
2. Maven Install
3. Maven Build
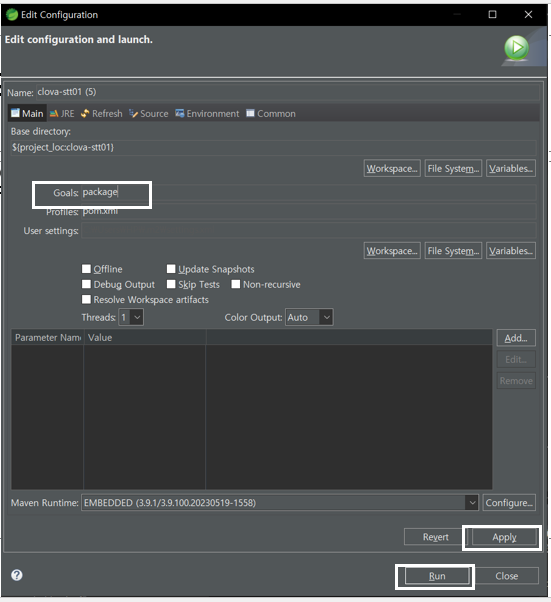
- Maven Build 하면 target 폴더에 jar파일 만들어짐
- cmd에서 jar파일 실행하면 localhost:8080에서 화면 보임!
▶ React와 Spring boot로 STT 실행
- TTS는 구현 전!!

▷ Controller (Spring boot)
@RestController
public class ClovaController {
private final String API_KEY = "어쩌고";
private final String CLIENT_ID = "저쩌고";
// 음성 인식(STT)
@PostMapping("/recognize")
public String recognizeSpeech(@RequestBody byte[] voiceData) {
String language = "Kor";
String url = "https://naveropenapi.apigw.ntruss.com/recog/v1/stt?lang=" + language;
RestTemplate restTemplate = new RestTemplate();
HttpHeaders headers = new HttpHeaders();
headers.setAccept(Collections.singletonList(MediaType.APPLICATION_JSON));
headers.setContentType(MediaType.APPLICATION_OCTET_STREAM);
headers.set("X-NCP-APIGW-API-KEY-ID", CLIENT_ID);
headers.set("X-NCP-APIGW-API-KEY", API_KEY);
HttpEntity<byte[]> entity = new HttpEntity<>(voiceData, headers);
ResponseEntity<String> response = restTemplate.postForEntity(url, entity, String.class);
return response.getBody();
}
}▷ Config (Spring boot)
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")
.allowedOrigins("http://localhost:3000")
.allowedMethods("GET", "POST", "PUT", "DELETE") // 허용할 HTTP 메서드
.allowedHeaders("*")
.allowCredentials(true);
}
}▷ React
import React, { useState } from 'react';
import axios from 'axios';
function SpeechComponent() {
const [text, setText] = useState('');
const [audioBlob, setAudioBlob] = useState(null);
const handleRecognize = async () => {
try {
const response = await axios.post('http://localhost:8080/recognize', audioBlob, {
headers: {
'Content-Type': 'application/octet-stream'
}
});
const recognizedText = response.data.text;
alert('음성 인식 결과:\n' + recognizedText);
} catch (error) {
console.error('음성 인식 요청 오류:', error);
}
};
return (
<div>
<h1>STT</h1>
<hr/>
<br/>
<input type="text" value={text} onChange={e => setText(e.target.value)} />
<button onClick={handleSynthesize}>음성으로 변환</button><br/>
<hr/>
<input type="file" onChange={e => setAudioBlob(e.target.files[0])} />
<button onClick={handleRecognize}>음성 인식</button>
</div>
);
}
export default SpeechComponent;
ByeolGyu