Abtract
이제까지의 SOTA의 Computer vision 시스템들은 미리 정의된 카테고리의 데이터셋에 대해서 예측하도록 훈련되어 왔다.
이런 supervision방식은 generality와 usability를 한정짓게 된다. 다른 visual concept을 특정화지으려면 추가적인 라벨링된 데이터가 필요하기 때문이다.
이에 대한 대안으로는 Raw text로부터 바로 이미지에 대해 러닝하는 것이 있다.
이 논문의 방식이 그러한데, 어떠한 캡션이 어떠한 이미지에 붙여지는 지를 예측하는 간단한 사전 학습 task(웹상의 (image,text) 4억개의쌍을 이용)가 SOTA image representation을 학습하는데에 효과적이며 확장가능한 방법임을 보여준다.
사전 학습 후에, 자연어는 학습된 visual concept을 참고하는데 사용되어 downstream task로 zero-shot transfer 하는 것을 가능하게 한다. 이 논문에서는 이러한 접근법을 검증하기 위해 30개의 다른 datasets을 사용하였고 이를 이용하여 OCR, action recognition 등의 task로 확장이 가능하였다.
모델은 대부분의 task에 transfer가 가능했고 기존의 모델보다 때때로 나은 성능을 보여주기도 했다고 한다.
Introduction and Motivating Work
기존의 Raw text로부터 바로 사전학습하는 방식은 NLP분야에서 지난 몇년간 혁신을 보여줘왔다. (BERT가 그 대표적인 예)
Autoregressive와 masked language modeling과 같은 task-agnostic(task와 관계없는) objectives는 컴퓨팅, 모델 용량 및 데이터의 다양한 순서로 확장되어 성능을 꾸준히 향상시켰는데, Text-to-text의 발달은 커스터마이징 등이 필요없이 task-agnostic 구조가 downstream dataset으로의 zero-shot transfer이 가능하도록 했다. 대표적인 예로, GPT-3와 같은 시스템은 특수한 학습데이터가 필요없이 많은 task에서 좋은 성능을 보여주고 있다.
이러한 결과들이 의미하는 바는 자연어분야에서는 (웹에서 모을 수 있는 텍스트를 이용한) 사전학습 모델이 기존의 라벨링된 고퀄의 NLP 데이터셋을 이용한 모델을 능가한다는 것이다.
하지만, 자연어 외의 분야들, 예를 들어 비전분야에서는 아직까지 기존의 라벨링된 데이터셋에서(ex. ImageNet) 사전학습하는 것이 표준방식이였다. 그렇다면, 웹 텍스트로 사전학습하는 방식이 컴퓨터 비전에서도 좋은 결과를 낼까? 이 논문을 읽고나면 이에 대한 답을 어느정도 찾을 수 있을 것이다.
아직 자연어를 이미지 representation learning에 사용하는 것은 여전히 드물다. 이유로는, 측정된 성능이 다른 대안들보다 훨씬 낮기 때문이다.
예를 들어, 한 논문에서는 zero-shot setting에서(즉 라벨링 되지 않은 데이터 상태) ImageNet 데이터셋에 대해 11.5%의 성능을 보였는데 이는 현재 88.4%의 성능을 보이는 모델에 비해 정말 부족한 수치이기 때문이다. 심지어 기존의 classic vision 접근법의 성능인 50%보다도 낮다.
대신에, weak supervision(라벨링의 비율이 낮은 세팅이라고 생각)은 성능을 향상시켜오긴 했다. 2018년의 논문에서는 인스타그램 이미지에서 ImageNet과 관련된 해쉬태그를 예측하는 것이 효과적인 사전학습임을 보였다. ImageNet에 대해 fine-tuning할 때 이러한 사전학습 모델은 5%넘게 정확성을 높이고 당시의 SOTA모델의 성능을 뛰어넘었기 때문이다.
이러한 연구들은 제한된 gold labels의 데이터셋으로 학습하는 것과 라벨링되지 않은 무한한 텍스트로부터 학습하는 것 사이의 현재 위치를 보여준다. 두 방법 모두 static softmax classifiers를 예측에 사용하였기에 동적인 output이 부족하다. 이로인해 유연함이 떨어지고, zero-shot 능력을 제한시키게 된다.
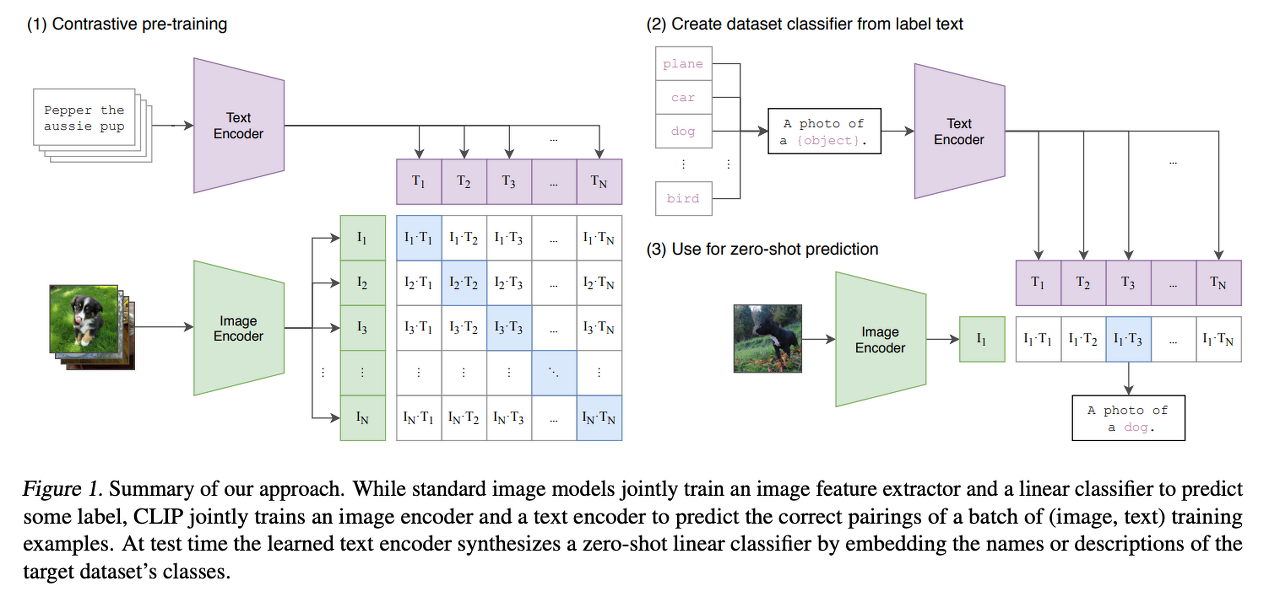
이 논문에서는 CLIP이라는 모델을 통해 두 방법(weakly supervised approach & zero shot learning using raw text)간의 차이를 줄였다. 인터넷에 공개되어 있는 많은 데이터셋을 통해 4억개 쌍(이미지, 텍스트)의 새로운 데이터셋을 만들었으며 CLIP은 또한 ConVIRT의 간단한 버전이라 칭할 수 있다.
CLIP은 앞서 언급했듯이 기존의 task-specific supervised model들과 성능이 비슷할뿐만 아니라 몇몇의 경우에서는 뛰어넘는 성능을 보여주었다. 또한 zero-shot CLIP은 같은 정확도의 다른 모델들보다 강력한 것을 보여주었는데 이는 task-agnostic model의 zero-shot이 모델의 capability를 더 잘 표현한다고도 할 수 있다.
Approach
1. Natural Language Supervision, 왜 자연어 supervision?
CLIP의 핵심은 자연어에 포함된 supervision으로부터 학습하는 것이라 할 수 있다. Introduction에서도 언급된 내용이지만, 이러한 학습방식은 기존에도 존재했다. 이전의 많은 논문들이 이미지와 짝지어진 텍스트로부터 visual representation을 학습하였지만 이를 unsupervised, self-supervised, weakly supervised 등등 각각 다르게 묘사했다.
이 논문의 모든 접근방식은 natural language supervision 로부터 나왔는데, 기존의 연구들이 자연어의 complexity로 어려움이 있었지만, 점점 개선이 됨에 따라 효과적으로 이러한 자원을 이용할 수 있게 되었다.
자연어를 이용하여 학습하는 것은 다른 학습 방법들보다 몇가지 잠재적인 능력을 가지고 있다.
첫째로는, 기존의 image classification에 사용된 라벨링에 비해 scaling이 쉽다. Annotation이 classic "ML compatible format"에 있지 않아도 되기 때문이다. 즉, 기존의 라벨링 방식은 사람이 직접 표기를 해서 "gold" label"이라는 것을 만들어야 했었는데 자연어를 이용하게 되면 그러한 과정이 필요없다. 자연어를 이용한 학습은 인터넷의 방대한양의 텍스에 포함된 supervision으로부터 수동적으로 학습이 가능하다.
둘째로는, 자연어를 이용한 학습은 기존의 대부분의 unsupervised or self-supervised 학습 방식보다 중요한 장점을 가지는데, 바로 모델이 단지 representation만을 학습하는 것이 아니라 언어에 대한 reprentation 또한 학습한다는 것이다. 이는 좀 더 유연한 zero-shot transfer를 가능하게 한다.
2. Creating a Sufficiently Large Dataset, 어떤 Data로 학습?
기존의 연구는 주로 세가지 데이터셋을 사용해왔다. (MS-COCO, Visual Genome 그리고 YFCC100M)
MS-COCO dataset과 Visual Genome dataset이 고퀄의 라벨링된 데이터셋임에도 현대의 기준에서는 사실 적은 양이다.
다른 computer vision시스템은 35억개의 인스타그램 사진으로 학습되기 때문이다. 1억개의 사진인 YFCC100M이 대안이 될 수 있지만, 각 이미지에 대한 메타데이터가 sparse하고 일관된 품질이 아니기에 훌륭한 대안은 아니다.
자연어 supervision에 대한 주요한 Motivation은 인터넷에 공개된 데이터셋이 방대하기 때문이다. 기존의 데이터셋이 이러한 방대한 데이터셋을 충분히 반영하지 않았기 때문에, 결과를 적절하게 비교하기는 쉽지 않다. 이러한 문제를 해결하기 위해,논문의 저자들은 새로운 4억개의 데이터셋 (이미지, 텍스트)쌍을 만들어 사용했다.
3. Selecting an Efficient Pre-Training Method, 어떻게 사전학습?
SOTA CV 시스템은 많은 데이터셋을 이용한다. 이 논문의 저자는 이러한 방대한 데이터셋을 이용한 효과적인 학습이 성공적으로 자연어 supervision을 스케일링하는것에 대한 핵심임을 강조했다.
처음의 접근법은, VirTex와 유사하게, 이미지 캡션을 예측하기 위해 Image CNN과 Text Transformer에서 학습하는 식이였다. 하지만,이러한 방법은 스케일링을 효과적으로 하는데에 어려움이 있었는데 아래의 그림을 보자.
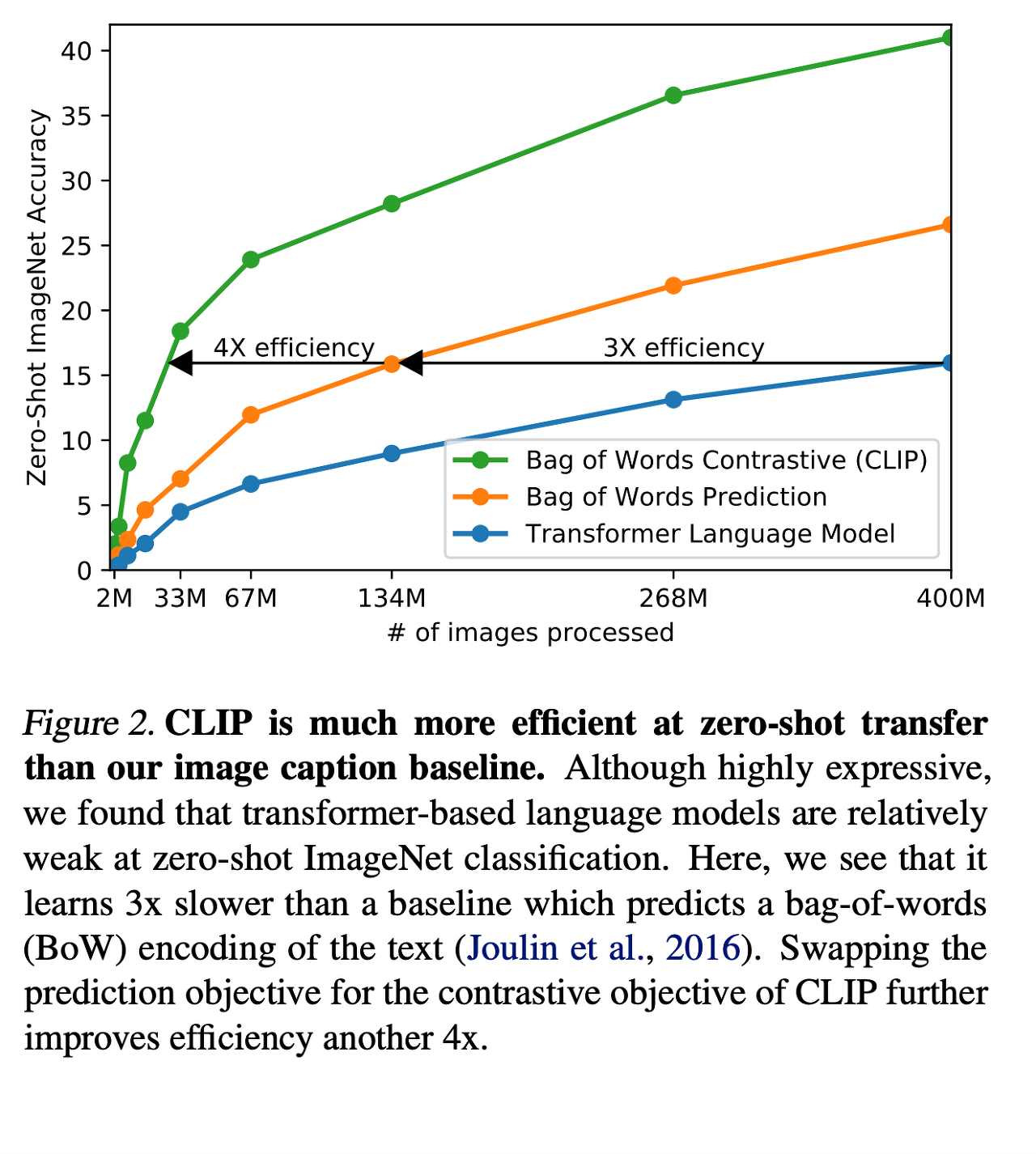
ResNet-50 image encoder 계산량 두배의 6300만개의 파라미터의 transformer 언어모델은 간단한 모델들보다 3배나 느린 것을 볼 수 있다. 이러한 방식들은 유사성을 가지는데 이미지에서 "정확한"단어를 예측하고자 한다는 것이다. 하지만 이러한 방식은 묘사하는 방식과 코멘트 등의 다양함때문에 쉽지 않다. 이러한 문제점 때문에 이 논문에서는 한 단어가 아닌 텍스트 전체로 짝지어지도록 학습시켰다. Bag-of-words 인코딩 방식을 사용하여 위의 그래프에서도 확인할 수 있듯이 ImageNet에서의 zero-shot transfer에서 4배의 효율성을 확보했다.
N개의 (이미지, 텍스트) 쌍의 배치가 주어졌을 때, CLIP은 NXN개의 가능한 (이미지, 텍스트) 쌍을 예측하도록 학습된다. 이를 위해, CLIP은 N개의 실제 쌍의 이미지 임베딩과 텍스트 임베딩의 코사인 유사도를 최대화하고 N^2-N개의 잘못된 쌍의 코사인 유사도는 최소화하도록 이미지 인코더와 텍스트 인코더를 같이 학습함으로써 multi-modal 임베딩 공간을 학습한다. (아래의 그림 참조)
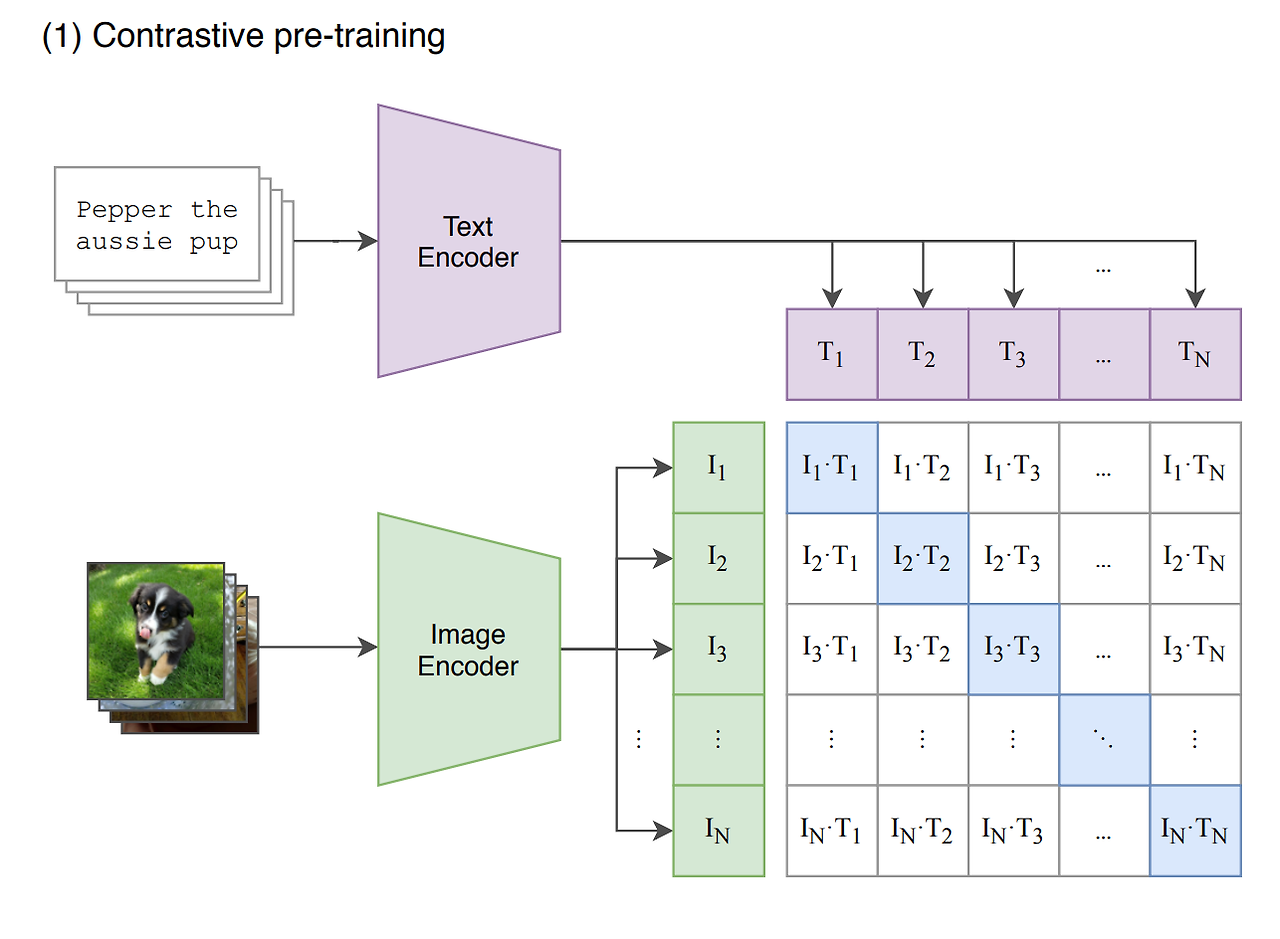
CLIP은 pre-trained weights이 아닌 아예 랜덤값으로 초기화되어 학습된다. 또, Representation과 contrastive embedding 공간사이의 non-linear projection을 사용하지도 않았다. 대신에, 각 인코더의 representation에서 multi-modal 임베딩 공간으로의 linear projection만을 사용했다. 추가로 text transformation과정도 제거하였으며(데이터셋이 single 문장이 대부분이기 때문) 이미지 transformation 함수도 단순화하였다.
Data augmentation은 이미지 사이즈 변환만을 사용했다. 마지막으로, softmax의 logit을 제어하는 temperature 파라미터 τ는 하이퍼파라미터로 튜닝되는 것을 피하기 위해 학습과정에서 바로 최적화된다.
4. Choosing and Scaling a Model
앞서서 모델 학습의 효율성이 핵심이라고 했는데 어떻게 모델을 선택하고 스케일링했을지 알아보자.
[Image Encoder]
CLIP의 저자들은 이미지 인코더로 두 개의 구조를 고려했는데,
- ResNet-50
- Vision Transformer(ViT)
1) ResNet-50
오리지날 ResNet에 조금 수정된 버전을 사용했는데, ResNet-D버전을 사용했으며 rect-2 blur pooling을 사용했다. 또한, global average pooling 레이어를 attention pooling 메커니즘으로 대체했다. Attention pooling은 하나의 "Transformer-style"의 multi-head QKV attention의 하나의 층으로 실행되는데 여기서 Q(Query)는 global average-pooled 이미지 representation에서 조건화된다.
2) ViT
최근 소개된 Vision Transformer로도 실험을 했는데 하나의 추가적인 layer normalization을 추가하는 것 외에 거의 기존의 모델을 수정하지 않고 사용했다.
[Text Encoder]
텍스트 인코더로는 Transformer를 사용했는데 텍스트의 BPE representation을 이용했다.
계산 효율성 측면때문에 max sequence length는 76로 제한했고 텍스트 시퀀스는 SOS와 EOS토큰과 함께 묶였으며 EOS토큰 위치의 highest laeyrs의 activations은 text의 representation으로 다뤄진다. Masked self-attention이 기존에는 사용되었지만 여기서는 사용하지 않았다.
5.Training
이 논문에서는 5개의 ResNet과 3개의 Vision Transformer 시리즈를 학습했다. ResNet으로는 ResNet-50, ResNet-101 그리고 EfficientNet 스타일의 모델 3개를 더 학습했고 대략적으로 4배, 16배, 64배의 계산을 사용하게 되었다. (RN50x4, RN50x 16 그리고 RN50x64로 각각 칭하자.)
ViT로는 ViT-B/32, ViT-B/16 그리고 ViT-L/14를 학습했고 모두 32 epoch만큼 학습했다.
Optimizer로는 Adam을 사용했으며 cosine schedule을 이용하여 learning rate를 점차 감소시켰다.
초기 하이퍼파라미터는 1 epoch 학습시에 grid search, random search 그리고 ResNet-50에서의 manual tuning의 조합을 사용했다. 하이퍼파라미터는 그다음 계산효율성을 위해 휴리스틱하게 조정이 되었다.
