딥러닝
1.빠른 객체 탐지 알고리즘 - YOLO

2015년에 최초로 공개된 YOLO는 속도와 정확도 측면 모두에서 거의 모든 객체 탐지 아키텍처를 능가했다. 그 이후로 이 아키텍처는 몇 차례 개선됐다. 여기에서는 다음 3개의 논문을 통해 알아보겠다.You Only Look Once: Unified, real-time
2.신경망
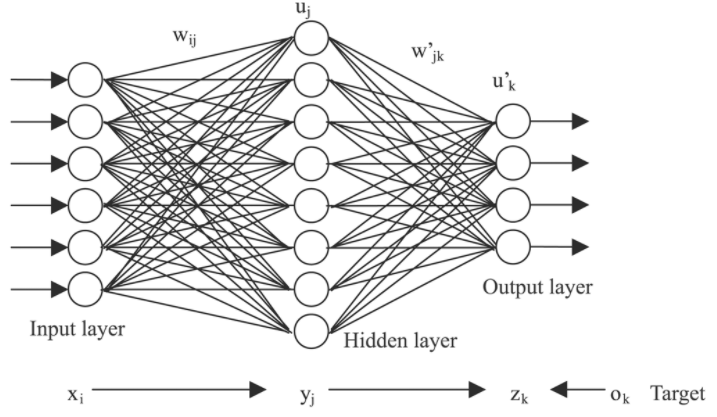
합성곱 신경망의 발견 CNN을 설명하고 이 신경망이 컴퓨터 비전 작업이라면 어디에서난 사용되는 이유를 알아보자 다차원 데이터를 위한 신경망 CNN은 초기 신경망의 단점을 해결하기 위해 도입됐다. 여기에서는 이 이슈를 해결하고 CNN이 이 문제를 어떻게 다루는지 설명한
3.[딥러닝]font classification

글자체 font를 구분하는 딥러닝 모델을 설계해보자데이터는 이미지 데이터로 된 폰트 이미지이며 분류 클래스는 굴림, 궁서, 나눔고딕, 맑은고딕, 바탕, 서울남산 총 6개의 클래스가 있다.굴림(15077개 이미지)궁서(15065개 이미지)나눔고딕(15019개 이미지)맑은
4.[딥러닝] Instance Segmentation(detectron2)

이번에는 딥러닝 기법 instance segmentation을 적용하기 위해 Detectron2를 사용해봤다. detectron2란 FAIR(Facebook Artificial Intelligence Research)에서 만든 pytorch 기반 object detec
5.[딥러닝] Semantic segmentation(U-Net)
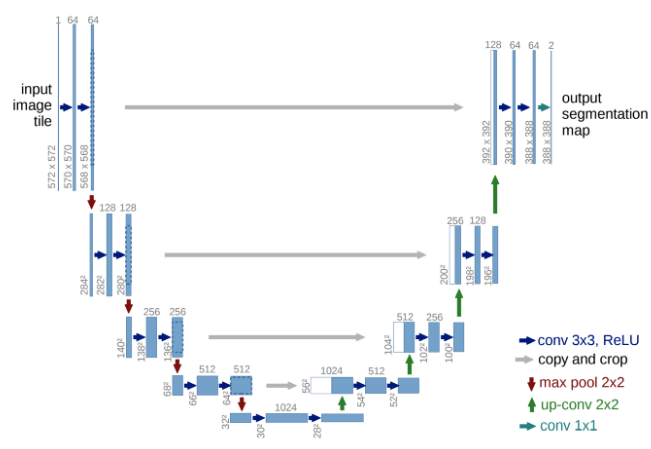
이번에는 semantic segmentation 방법 중 대표적인 모델 UNet에 대해서 알아보자의미론적 분할(의학 촬영에 적용)을 위해 개바된 이 모델은 특징 깊이를 증가시키면서 공간 차원은 축소시키는 다중블록 축소 인코더와 이미지 해상도를 복원하는 확장 디코더로 구
6.[딥러닝]시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq)

시퀀스-투-시퀀스(Sequence-to-Sequence)는 입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 다양한 분야에서 사용되는 모델입니다. 예를 들어 챗봇(Chatbot)과 기계 번역(Machine Translation)이 그러한 대표적인 예인데, 입력 시퀀스
7.[딥러닝]어텐션 메커니즘 (Attention Mechanism)
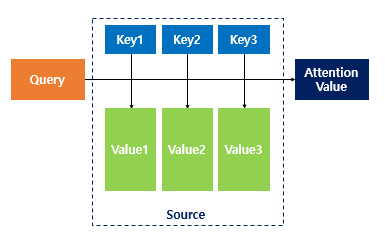
앞서 배운 seq2seq 모델은 인코더에서 입력 시퀀스를 컨텍스트 벡터라는 하나의 고정된 크기의 벡터 표현으로 압축하고, 디코더는 이 컨텍스트 벡터를 통해서 출력 시퀀스를 만들어냈습니다.하지만 이러한 RNN에 기반한 seq2seq 모델에는 크게 두 가지 문제가 있습니다
8.[딥러닝]Transformer
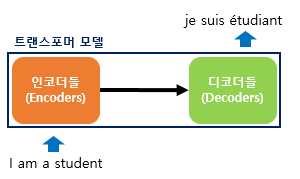
Transformer 트랜스포머(Transformer)는 2017년 구글이 발표한 논문인 "Attention is all you need"에서 나온 모델로 기존의 seq2seq의 구조인 인코더-디코더를 따르면서도, 논문의 이름처럼 어텐션(Attention)만으로 구현한
9.[딥러닝] Mask R-CNN
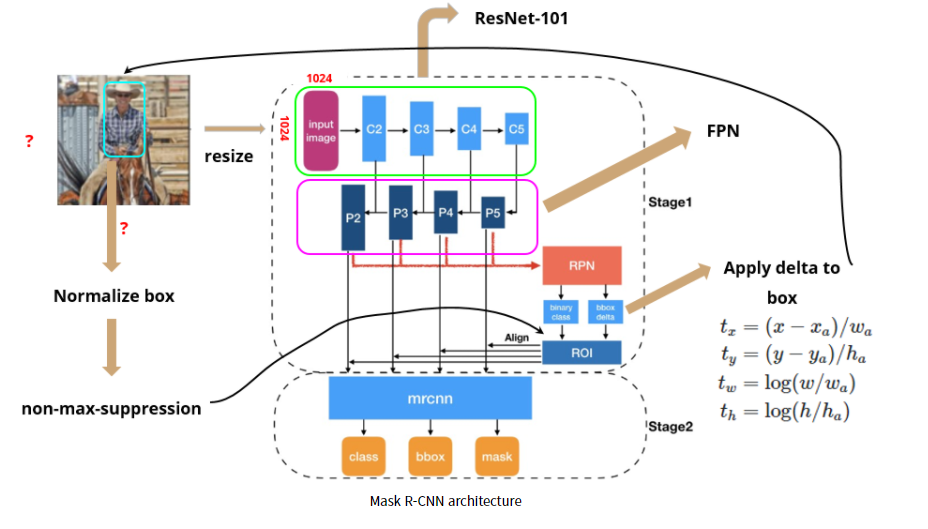
컴퓨터 비전의 주요 과제 3가지1) Classification2) Object detection3) Image segmentation중 Faster R-CNN까지는 2-stage에 기초한 특히 2) Object detection 를 위해 고안된 모델들이였다.이번에 설명
10.[딥러닝] Faster R-CNN
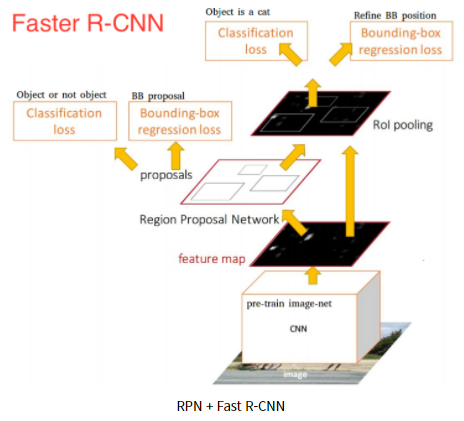
R-CNN에서는 3가지 모듈 (region proposal, classification, bounding box regression)을 각각 따로따로 수행한다.(1)region proposal 추출 → 각 region proposal별로 CNN 연산 → (2)class
11.[딥러닝]Fast R-CNN
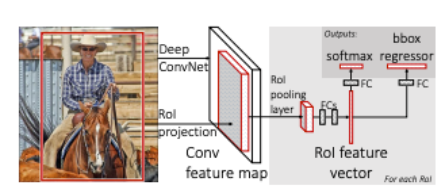
Fast R-CNN은 이전 R-CNN의 한계점을 극복하고자 나왔다. R-CNN는 다음과 같은 한계점들이 있었다.1) RoI (Region of Interest) 마다 CNN연산을 함으로써 속도저하2) multi-stage pipelines으로써 모델을 한번에 학습시키지
12.[딥러닝]Vision Transformer

Vision Transformer 개요 현재 AI계에서 화제가 되고 있는 "Vision Transformer"에 대해 다뤄보려고 한다. 이번에 제안된 Vison Transformer(이하 ViT)이라는 모델에 의해 더 이상 레이어를 겹치는 형태의 모델은 없어질지도 모른
13.[딥러닝] Fully Connected Network
FCN for semantic segmentation Fully connected network for semantic segmentation은 제목에서부터 말하듯 semantic segmentation을 위한 딥러닝 모델이다. FCN은 semantic segmen
14.[딥러닝] Feature Pyramid Network
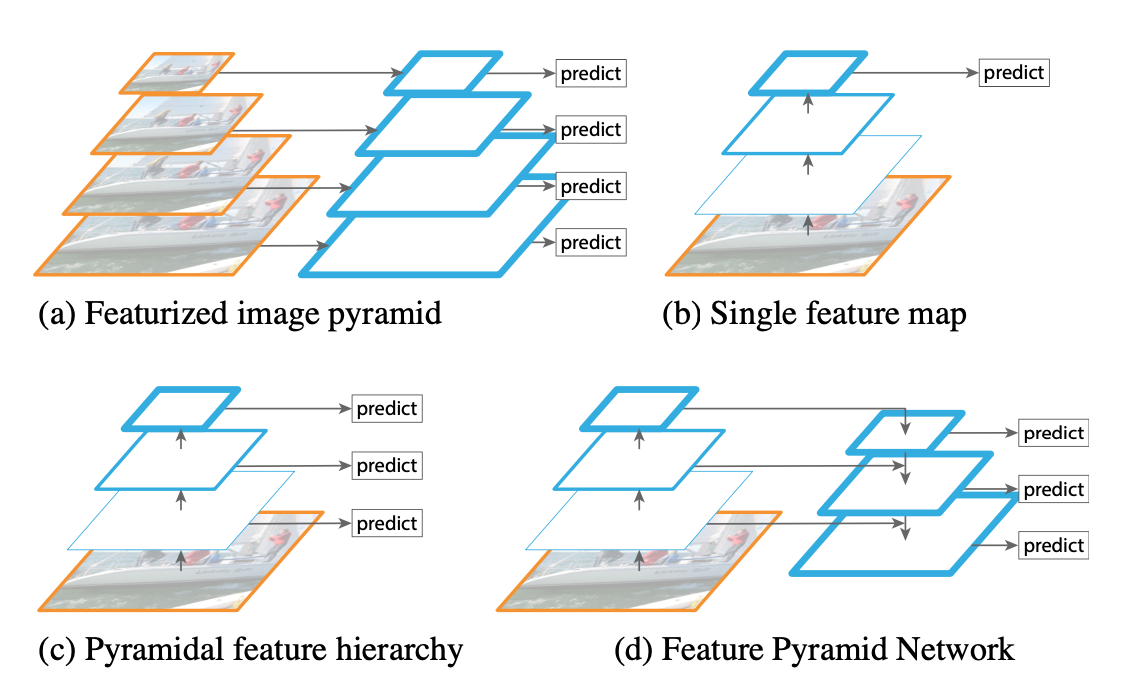
object detection 분야에서 풀리지 않았던 고질적인 난제는 작은 물체를 탐지해내기가 어렵다는 것입니다. 이를 위해서 이미지나 피쳐맵의 크기를 다양한 형태로 rescale하는 접근 방식이 있어왔습니다.(a)는 입력 이미지 자체를 여러 크기로 resize 한 뒤
15.[딥러닝] YOLO v4
YOLO v4 논문 리뷰 이번 포스트는 yolo v4에 대한 리뷰를 하고자 한다. 사실 v3까지만 하더라고 이미 시간이 지났기도 하고 많은 분들이 리뷰도 해주셔서 어떻게든 따라갈 수 있었는데 v4는 갑자기 처음 보는 알고리즘 들과 기술들이 너무 많이 나와서 솔직히 힘들
16.[딥러닝] SSD : Single Shot Multibox Detector
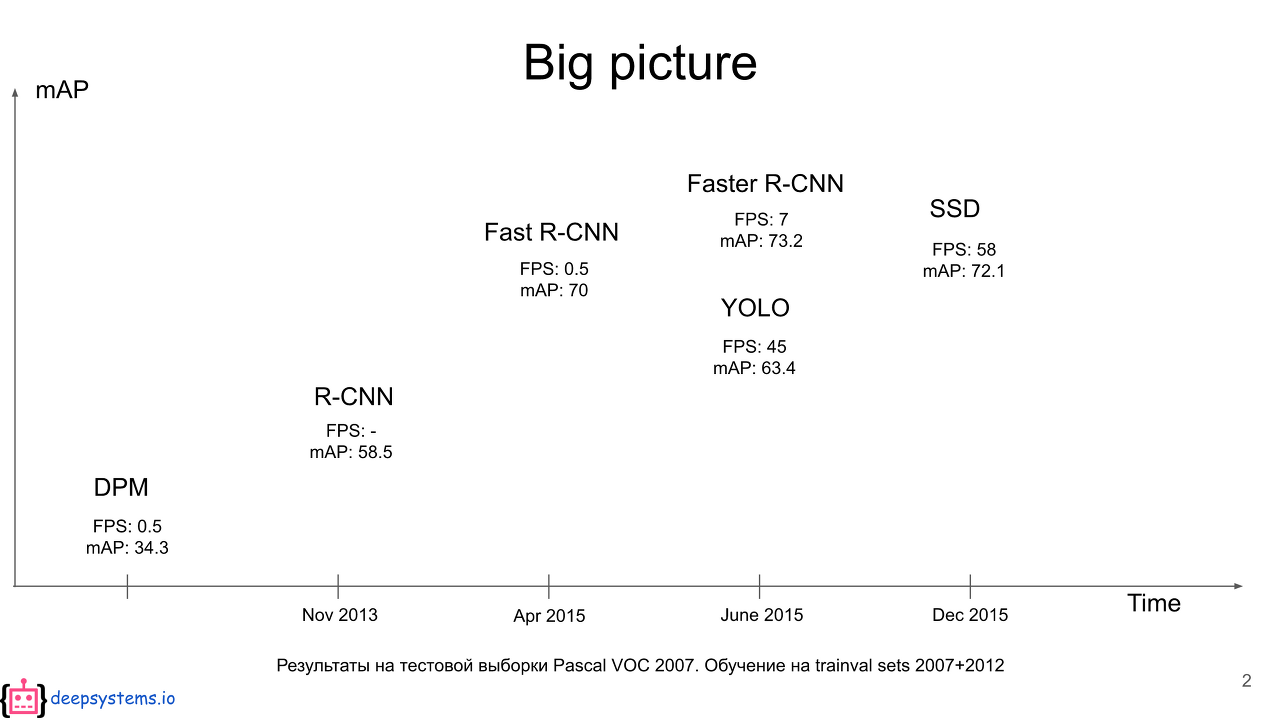
오늘 리뷰할 논문은 yolo의 뒤를 잇는 1 Step object detection 알고리즘, SSD입니다.Yolo는 속도 측면에서 당시 Faster R-CNN이 7FPS이었던 것을 45FPS까지 끌어올리는 비약적인 발전을 이루었습니다. 하지만 정확도 측면에선 다소 한
17.딥러닝 모델 경량화
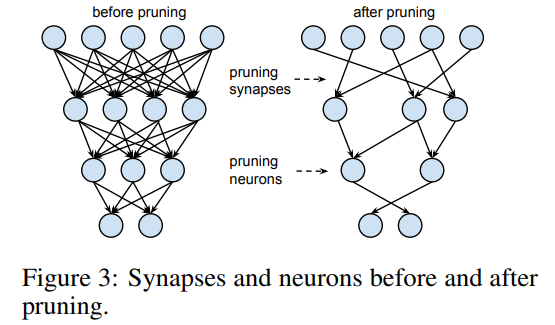
딥러닝 모델은 영상분석 분야에서 좋은 성능을 보여주고 있습니다. 하지만 많은 메모리 공간과 연산량을 필요로 하여 효율이 떨어지는 문제점을 가지고 있습니다.실제 딥러닝을 이용해 영상분석을 해야하는 로봇, 자율자동차, 스마트폰과 같은 모바일 환경에서는 하드웨어 성능(메모리
18.DETR (End-to-End Object Detection with Transformers)
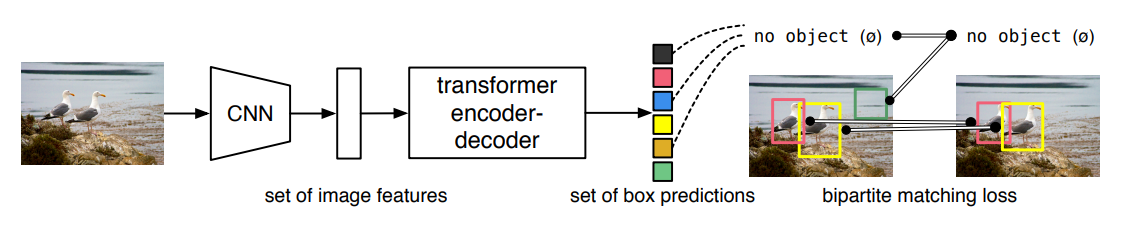
이번에는 ECCV 2020년에 발표된 DETR 논문(End-to-End Object Detection with Transformers)을 읽고 리뷰해도록 하겠습니다. DETR은 Transformer 구조를 활용하여, end-to-end로 object detection을
19.[딥러닝]Swin Transformer
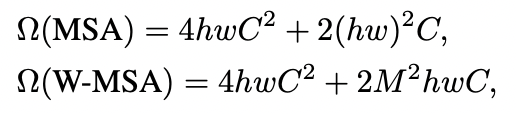
swin transformer 논문에 대하여 알아보겠습니다. 논문의 전체 이름은 Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 입니다. shifted window를 이용한다는 점과 계층적
20.[딥러닝]Stable Diffusion
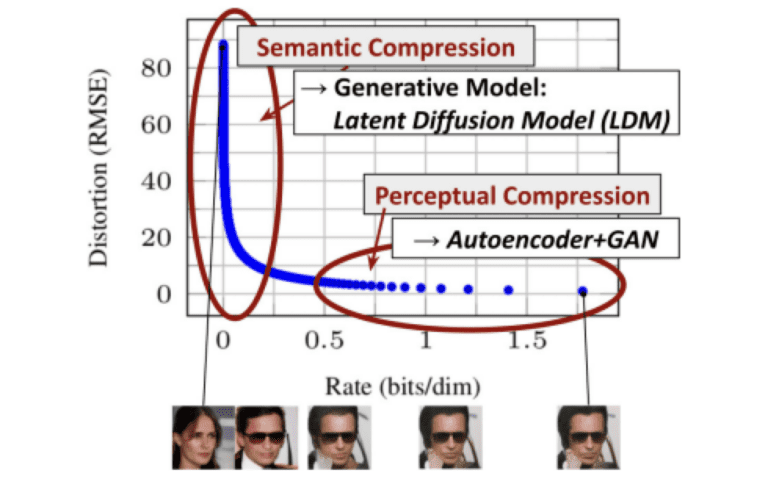
이번 글에서는 2022년 CVPR에 발표된 High-Resolution Image Synthesis with Latent Diffusion Models 논문을 리뷰합니다. 이 논문은 Stable Diffusion이라고 불리며, 이번 글에서도 Stable Diffusio
21.[딥러닝] GLIGEN - Open-Set Grounded Text-to-Image Generation

이번 글에서는 2023년 CVPR에 발표된 GLIGEN: Open-Set Grounded Text-to-Image Generation 논문을 리뷰합니다. 이 논문은 GLIGEN이라고 불리며, 이번 글에서도 GLIGEN이라고 지칭하겠습니다최근 몇 년 사이에 다양한 Dif
22.[딥러닝]Diffusion model from scratch in pytorch

해당 포스트에서는 자동차 이미지로 간단한 diffusion 모델을 생성하는 방법을 포스팅 할 것이다. 상세 소스코드와 설명은 아래 링크를 참조하면 될 것이다.SourcesGithub : https://github.com/lucidrains/denoising-d
23.[딥러닝] DiffusionDet: Diffusion Model for Object Detection
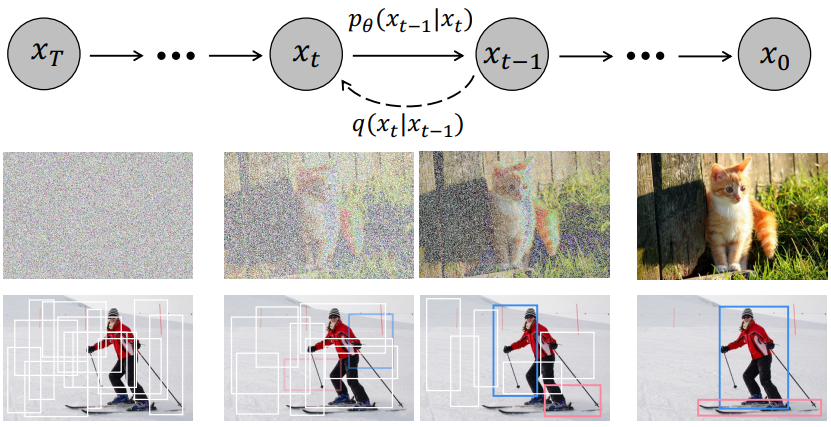
ICCV 2023 (Oral). Paper githubShoufa Chen, Peize Sun, Yibing Song, Ping LuoThe University of Hong Kong | Tencent AI Lab | Fudan University | Shanghai
24.YOLO v9 리뷰
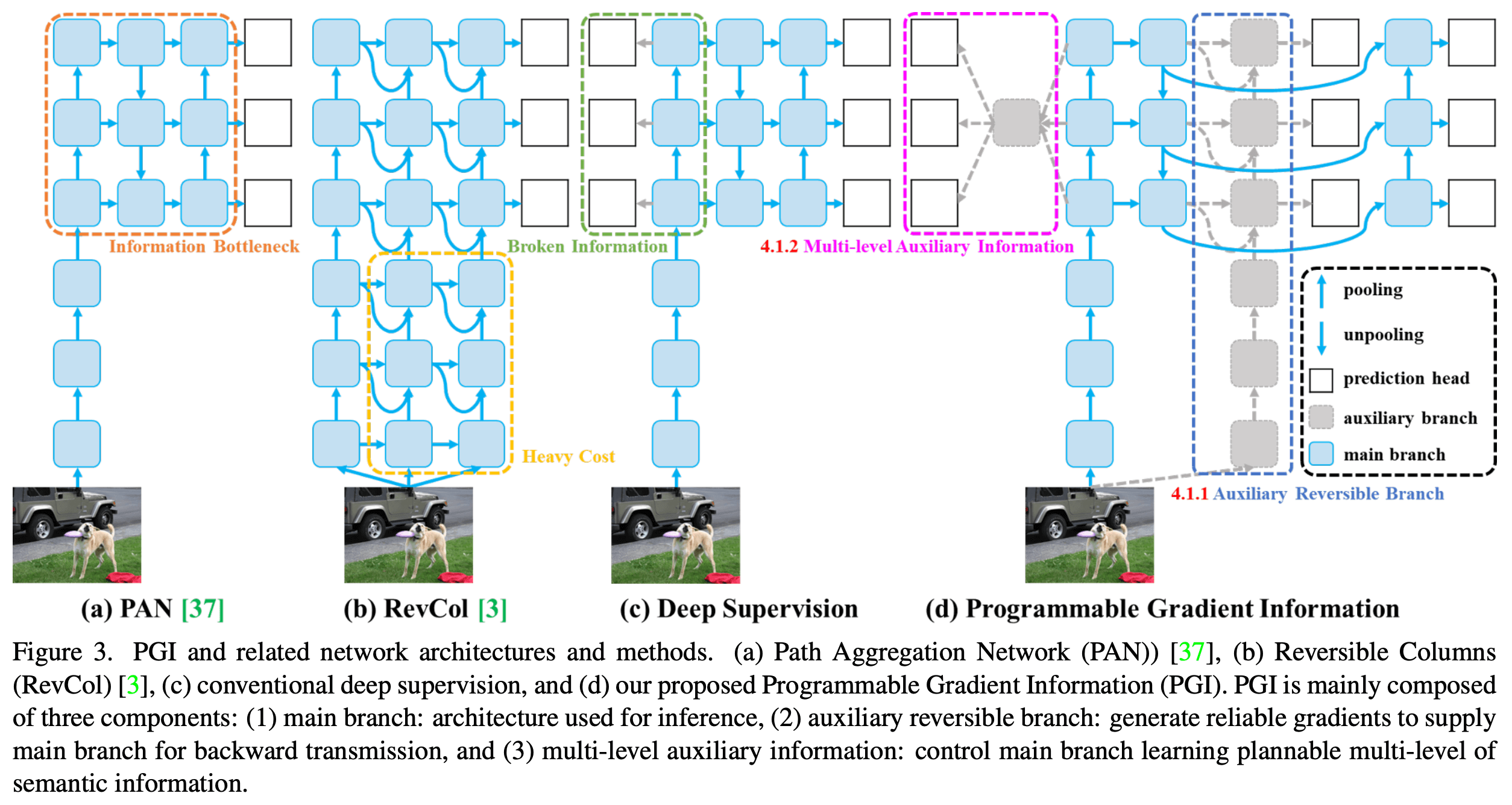
2024년 2월 YOLOv9가 공개되었다. 기존의 네트워크에서 정보 손실의 문제점을 해결하기 위해 PGI를 사용하여 설계한 GELAN 신경망을 사용하여 기존 모델을 개선하였으며 이전의 모델보다 MS COCO 데이터셋에서 가장 우수한 성능을 보인다고 한다.논문 : htt
25.YOLO v8 모델
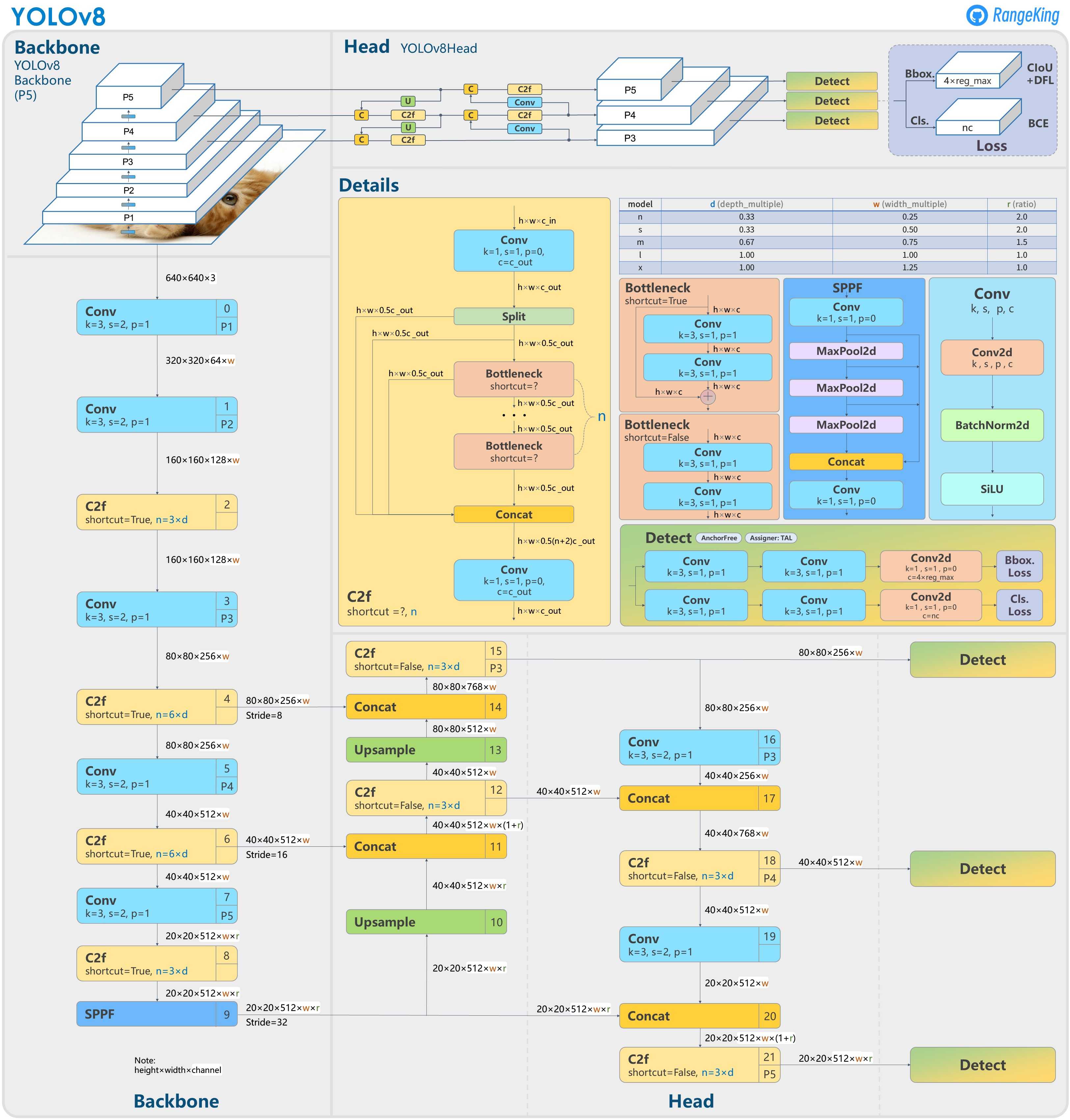
YOLOv8의 구조는 modified CSPDarknet32 backbone을 사용한다. YOLOv5에서 사용되었던 CSPLayer는 C2f module로 대체되었다. spatial pyramid pooling fast(SPPF) layer가 이미지 특징들을 고정된 크
26.TensorRT
TensorRT는 학습된 딥러닝 모델을 최적화하여 NVIDIA GPU 상에서 추론 속도를 향상시켜 딥러닝 서비스를 개선하는데 도움을 줄 수 있는 모델 최적화 엔진이다. 학습된 모델을 실행하고자 할 때 모델을 경량화 시켜 연산 속도를 향상시킨다. 딥러닝 프레임워크인 py
27.CLIP : Learning Transferable Visual Models From Natural Language Supervision
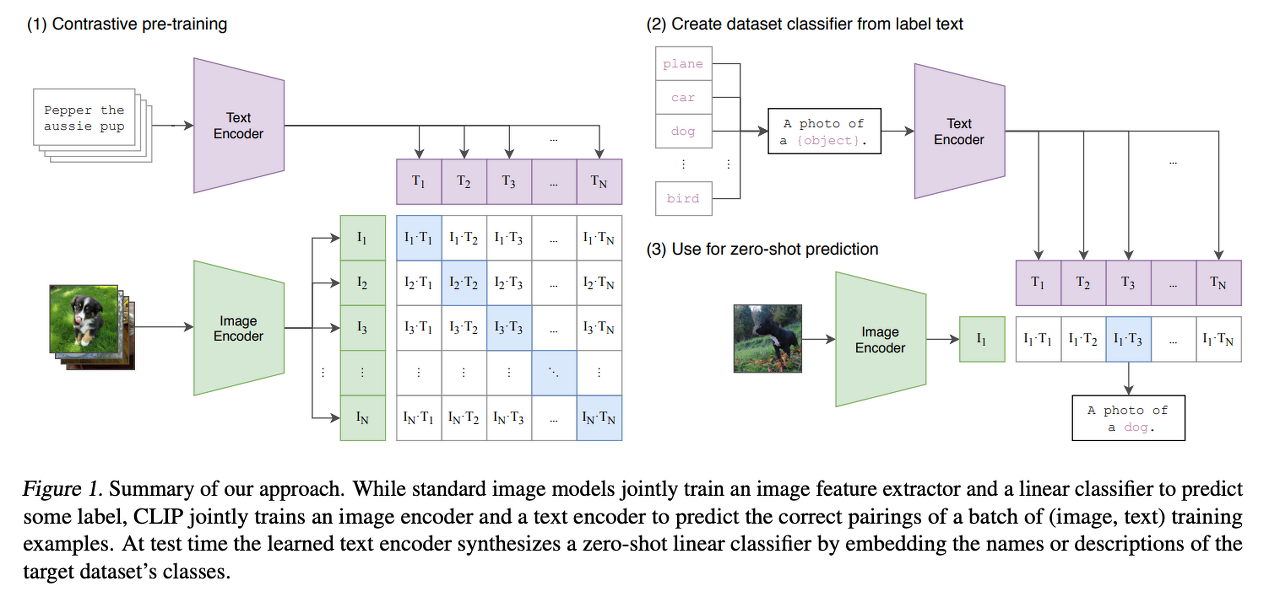
이제까지의 SOTA의 Computer vision 시스템들은 미리 정의된 카테고리의 데이터셋에 대해서 예측하도록 훈련되어 왔다.이런 supervision방식은 generality와 usability를 한정짓게 된다. 다른 visual concept을 특정화지으려면 추가
28.YOLOv9 - model Part1
모델을 구성하는 common.py에 대한 클래스 및 함수 구성요소에 대해 알아보자본 포스트는 추가 설명 없이 함수나 클래스에 대한 코드만 존재한다(주석으로 간단히 설명할 것이다)
29.[딥러닝] OFA - Once For All
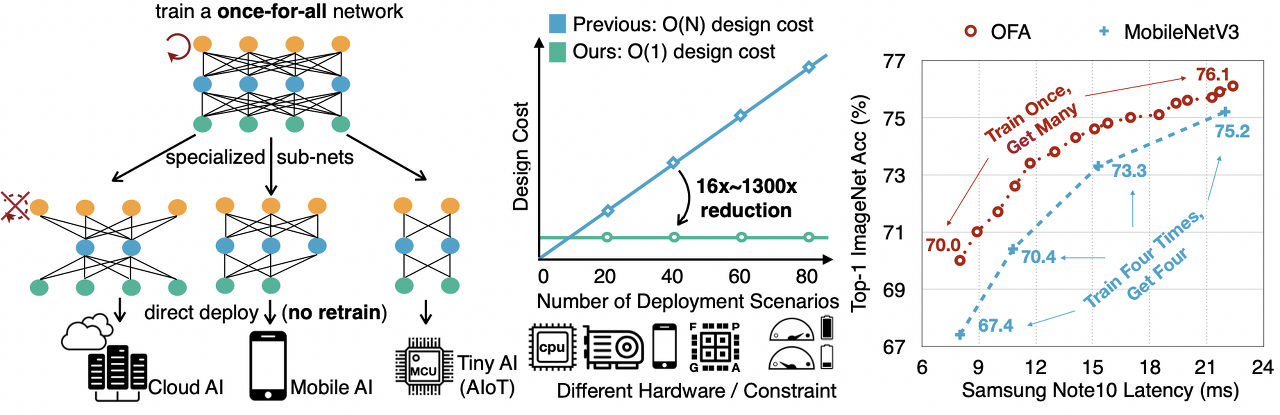
다양한 device의 제약조건 하에서 효율적으로 inference 하는 것은 쉽지 않은 문제이다. 전통적인 방법으로 네트워크를 디자인하는 것도 엄청난 연산량이 부담된다. 본 연구에서는 a once-for-all (OFA) 네트워크 학습법을 제안하며, OFA는 train
30.[딥러닝]Deeplake

Deep Lake는 원시 데이터에 이미지, 비디오, 오디오 및 기타 비정형 데이터가 포함된 딥러닝 사용 사례에 특화된 데이터 레이크(데이터베이스) 입니다. 원시 데이터는 딥 러닝 기본 저장 형식으로 구체화되고 네트워크를 통해 모델 학습으로 스트리밍됩니다.우리 삶을 더
31.[딥러닝] Vision Transformer에 대한 시각적 설명

Vision Transformer(ViT)는 CV(Computer Vision) 분야에 Transformer를 적용하여 객체 탐지 및 이미지 분류 등의 분야에서 뛰어난 성능을 보이는 모델입니다. 특히 이미지로부터 특징(feature)을 추출하는 Visual Encode
32.[딥러닝]ONE-PEACE: 무제한 멀티 모달리티를 위한 일반 표현 모델

비젼, 오디오, 언어 모달리티를 모두 아우르는 General Represenation Model사전학습된 모델 없이도 통합된 작업들에 훌륭한 결과를 냄강력한 Emergent Zero-shot Retrieval로 훈련 데이터에서 페어링 되지 않은 모달리티를 얼라인 가능A
33.[딥러닝] Attention 신경망 구현
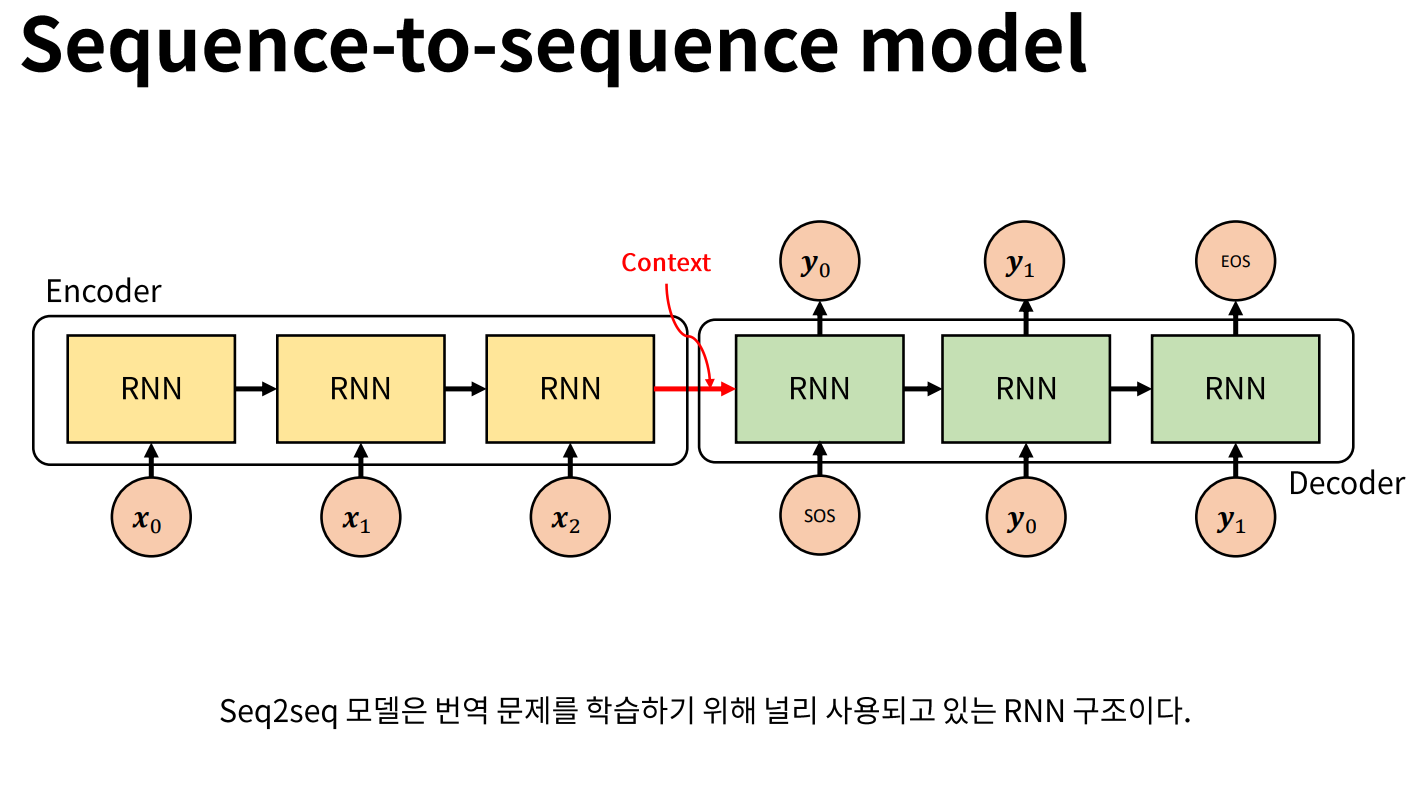
Attention 신경망 구현 하이퍼 파라메터 설정 Encoder Decoder Seq2seq Training & Test Loop 학습 환경 정의 및 학습 동작
34.[딥러닝]YOLOv10
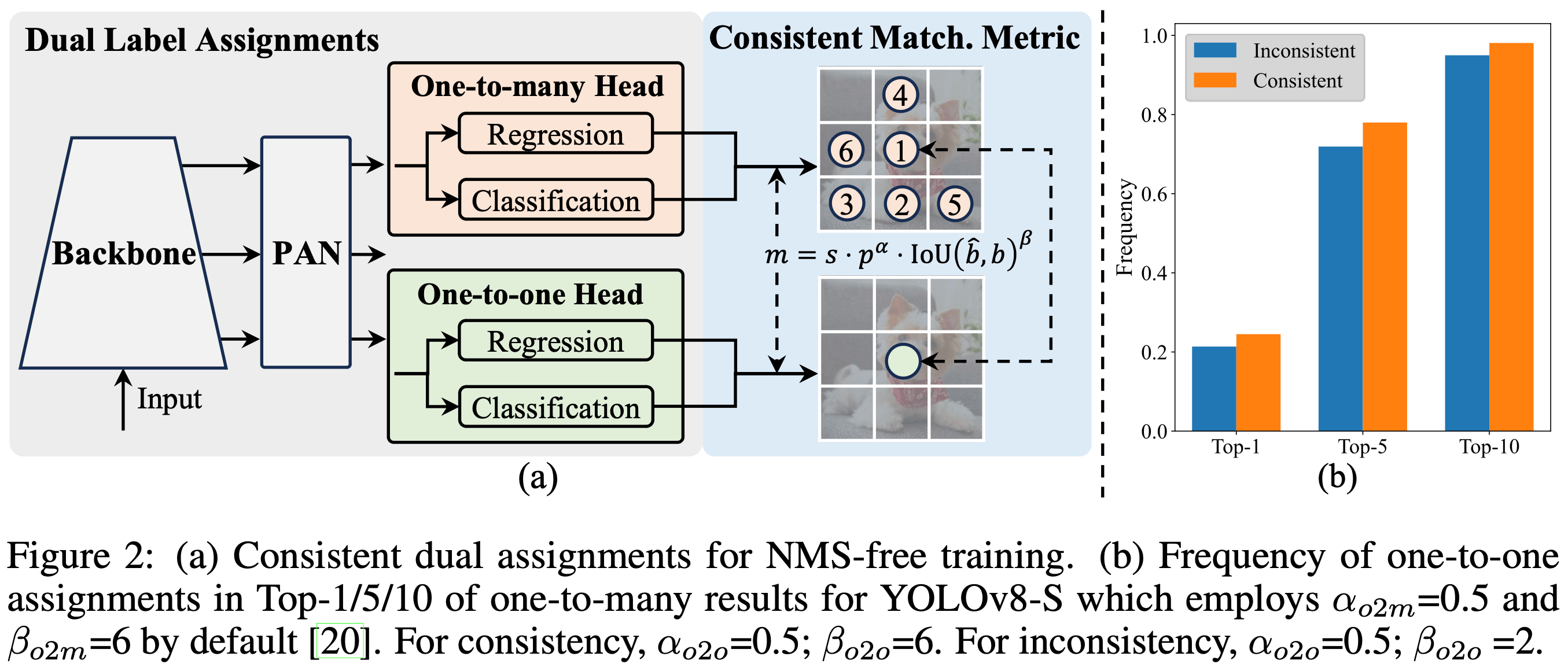
논문https://github.com/THU-MIG/yolov10• YOLOv10은 NMS가 없는 훈련을 위해 일관된 이중 할당을 도입하여 경쟁력 있는 성능과 낮은 추론 대기 시간을 동시에 달성한다.• YOLO에 대한 전체적인 효율성-정확성 기반 모델 설계 전
35.[딥러닝] Florence-2
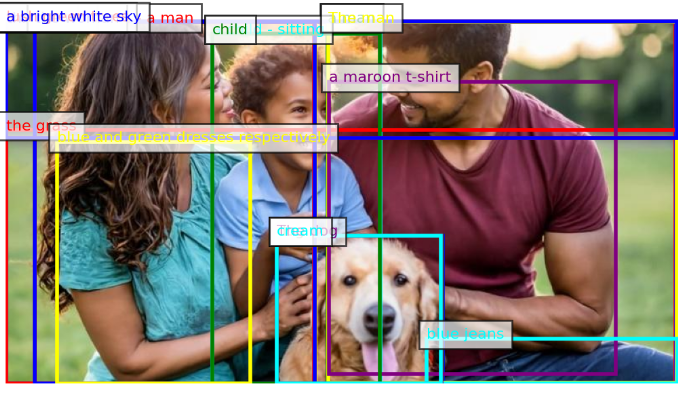
이번 포스트에서는 Florence-2에 대해 알아보겠습니다. 이 모델은 복잡한 공간적 계층 구조와 의미론적 세분화를 다루는 능력을 통해 객체 감지, 이미지 캡션 생성은 물론 각 픽셀을 객체 또는 장면 범주로 분류하는 Semantic Segmentation, 특정 구문과
36.[딥러닝] YOLO-World
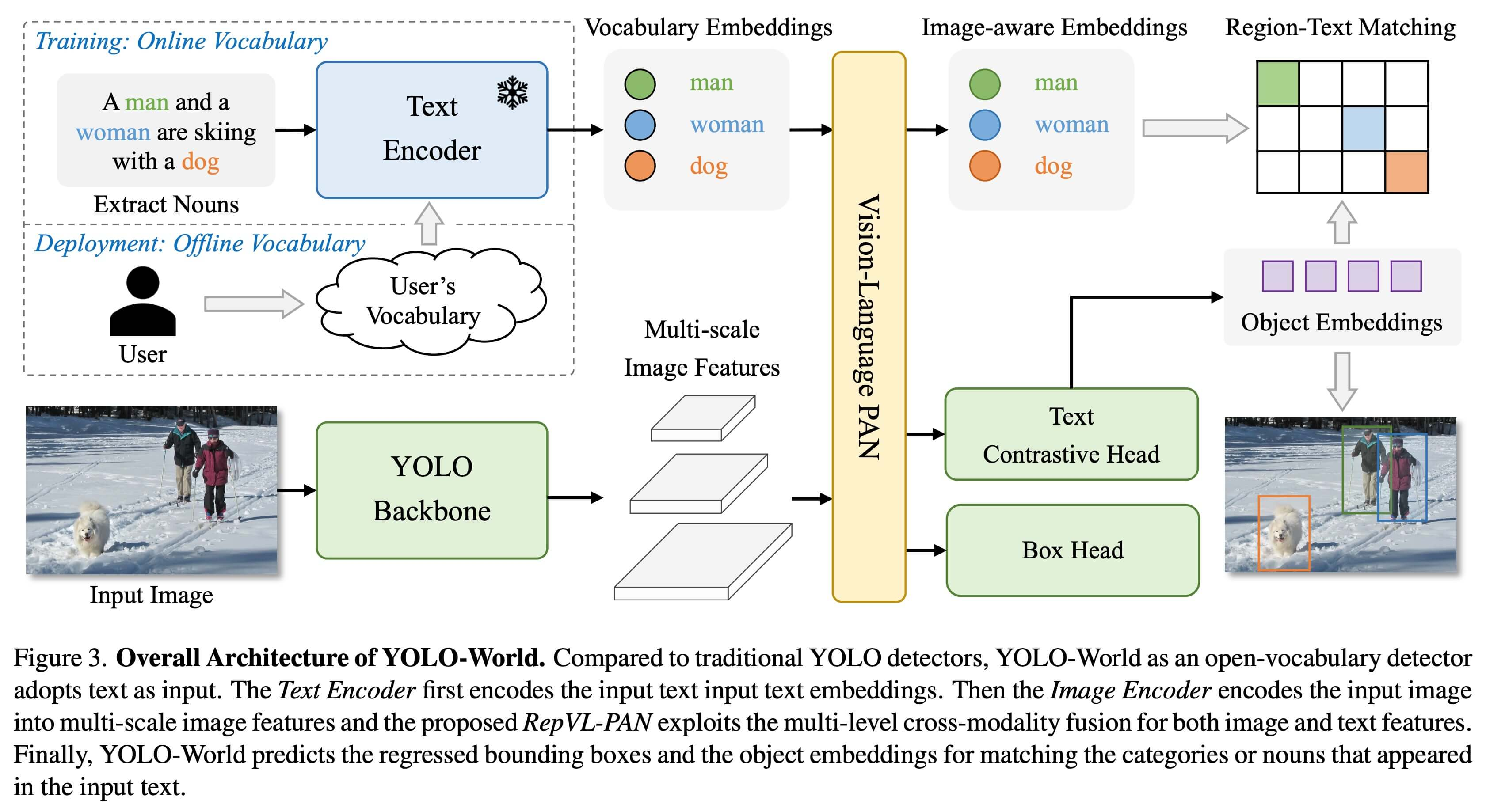
YOLO-World는 많은 리소스를 필요로 하는 트랜스포머 모델에 의존하는 기존의 Open-Vocabulary 감지 모델이 직면한 문제를 해결합니다. 이러한 모델은 사전 정의된 개체 범주에 의존하기 때문에 동적 시나리오에서 유용성이 제한되기도 합니다. YOLO-Worl
37.[딥러닝]Transformer Explainer: 복잡한 Transformer 모델을 시각적으로 이해하기
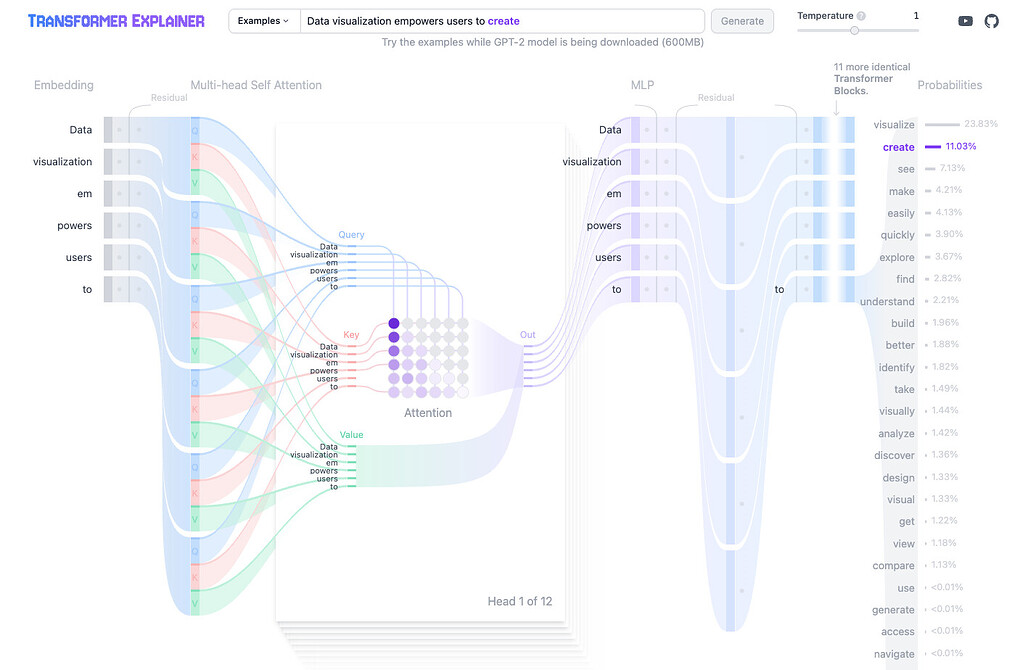
Transformer 모델은 자연어 처리(NLP) 분야에서 혁신적인 변화를 가져온 모델입니다. 하지만 그 복잡한 구조와 동작 원리는 많은 사람들에게 여전히 난해합니다. Polo Club의 Transformer Explainer는 이러한 복잡성을 시각적으로 풀어주는 도구
38.[딥러닝] Transfusion
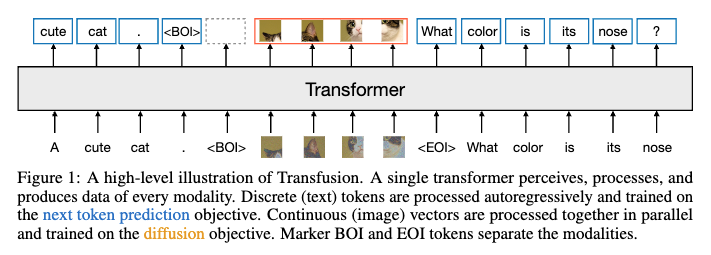
트랜스퓨전(Transfusion)은 이산 데이터(예: 텍스트)와 연속 데이터(예: 이미지)를 동시에 처리하고 생성할 수 있는 통합된 멀티모달 모델입니다. 기존의 모델들은 주로 이산 데이터와 연속 데이터를 별도의 모달리티별 모델로 처리했으며, 이를 통합하려는 시도는 주로
39.[딥러닝] Qwen-2VL
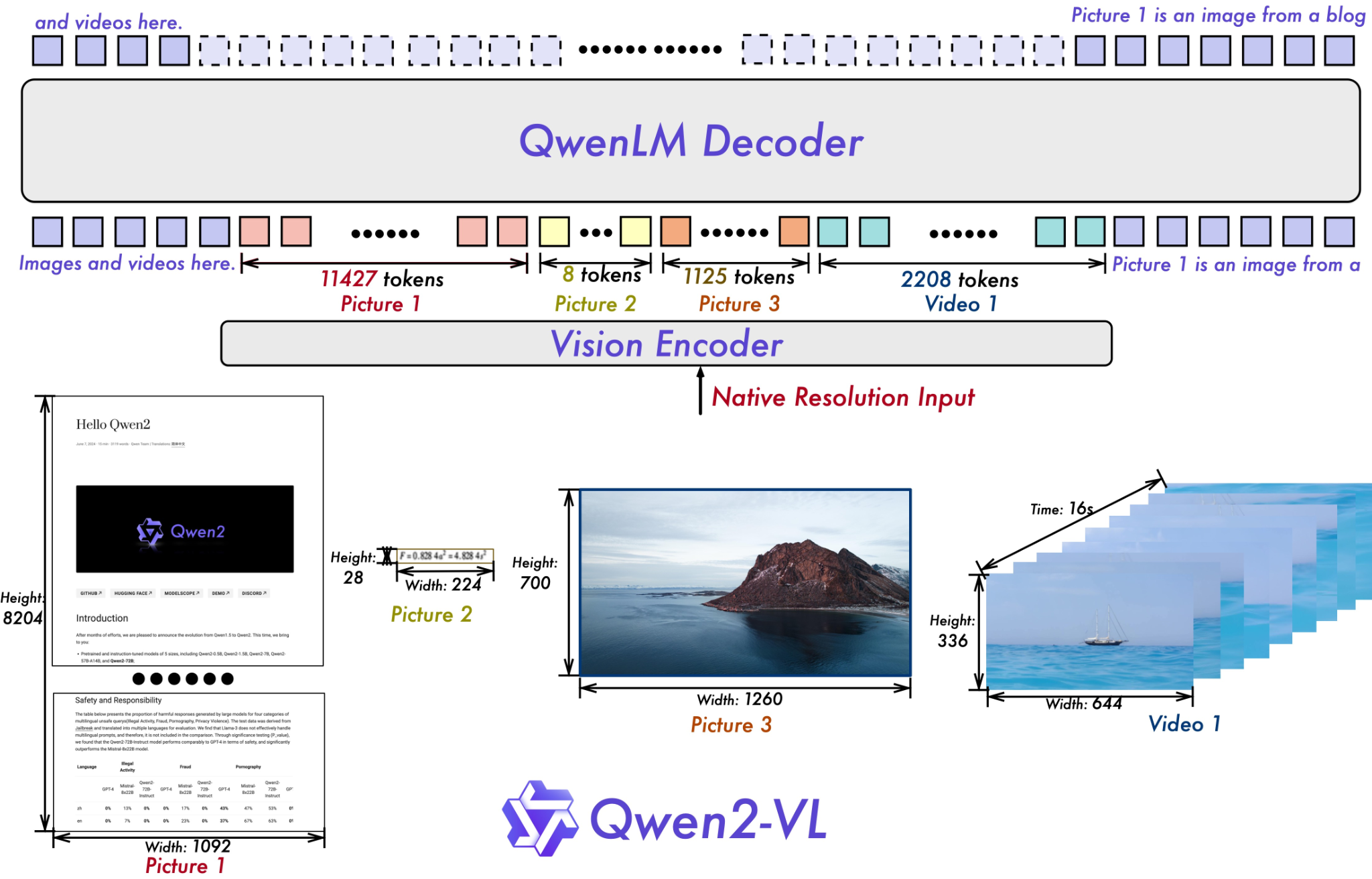
Qwen-2VL은 Qwen 시리즈의 두 번째 비전-언어(Vision-Language) 모델로, 다양한 멀티모달 작업에서 뛰어난 성능을 발휘하는 모델입니다. Qwen 시리즈는 Alibaba Group의 연구소에서 개발한 대형 언어 모델(Large Language Mode
40.[딥러닝] Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
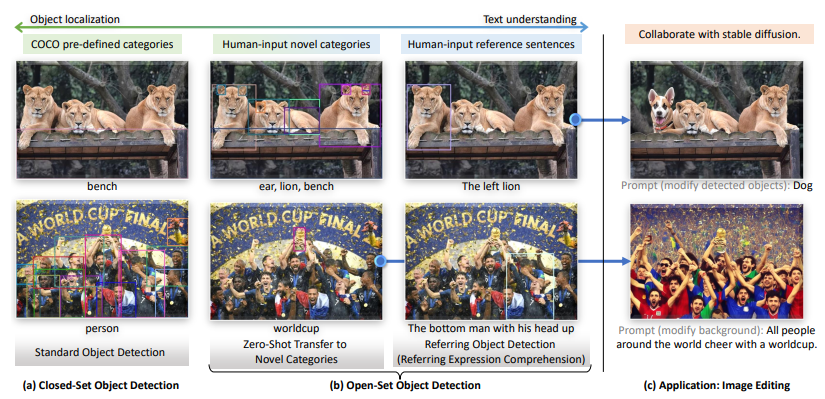
개방형 객체 검출에 관한 연구로, 인간 언어 입력(예: 카테고리 이름 또는 참조 표현)을 사용하여 임의의 객체를 검출할 수 있는 모델인 Grounding DINO를 제안합니다. 이 모델은 Transformer 기반 DINO 검출기를 기반으로 하여 언어와 시각 정보의 긴
41.[딥러닝] YOLOv11 리뷰
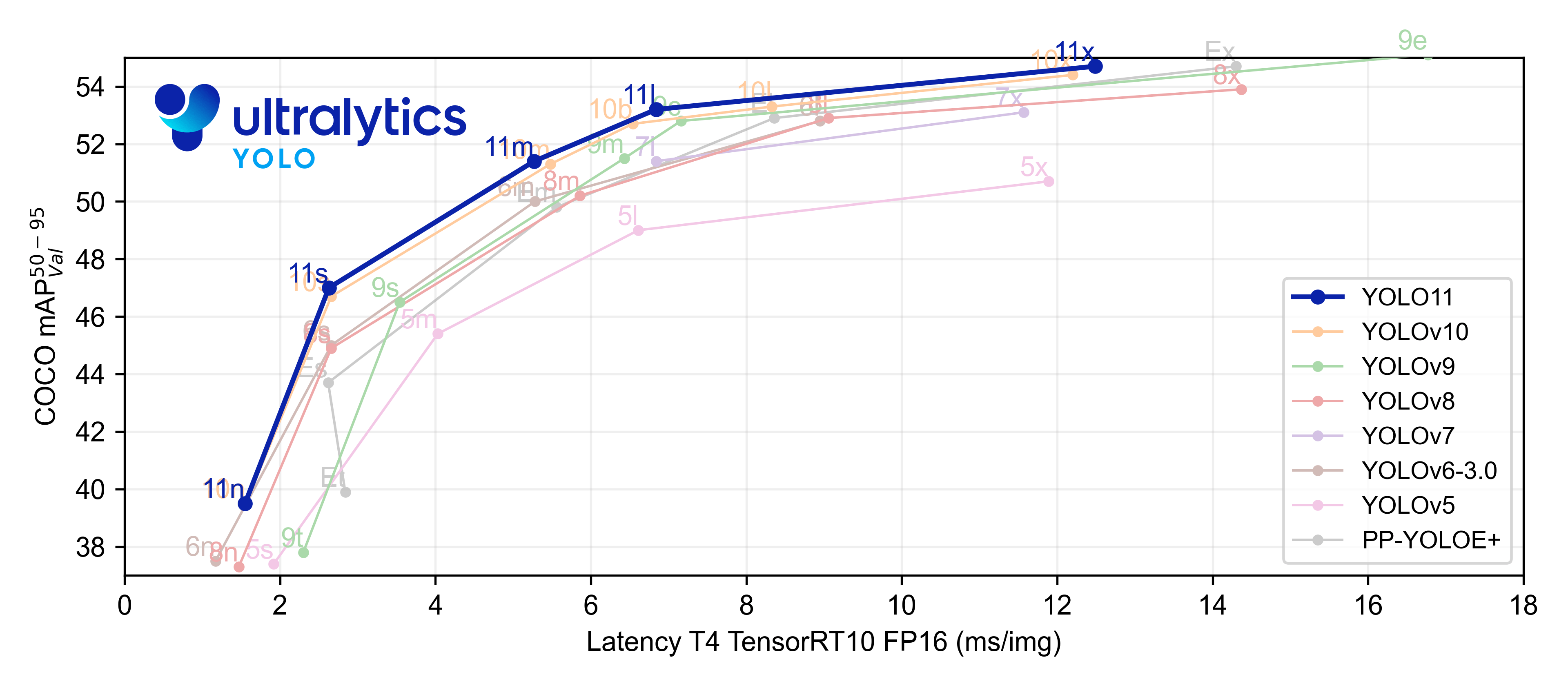
문서https://docs.ultralytics.com/models/yolo11/YOLO11은 Ultralytics YOLO 시리즈의 최신 버전으로, 실시간 객체 탐지 분야에서 정확도, 속도, 효율성 측면에서 혁신을 이루었다. 이전 YOLO 버전들의 발전을 바
42.[딥러닝] Differential Transformer
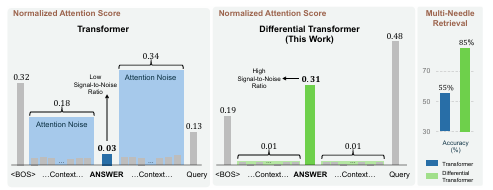
Differential Transformer 논문이 논문은 Differential Transformer(이하 DIFF Transformer)에 대해 설명하고 있습니다. DIFF Transformer는 주어진 문맥에서 중요한 정보에 대한 주의를 강조하고 불필요한 정보를
43.[딥러닝] SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities
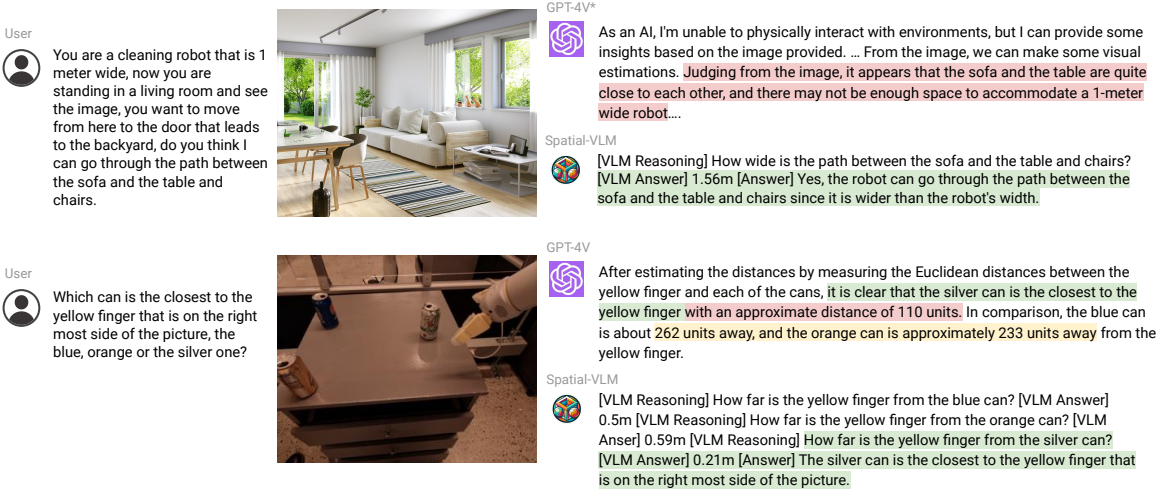
논문https://arxiv.org/pdf/2401.12168시각적 질문 답변(Visual Question Answering, VQA) 및 로봇 공학에서 공간적 관계(Spatial Reasoning) 를 이해하고 추론하는 능력은 매우 중요합니다. 기존의 비전-
44.CLIP 모델 분석
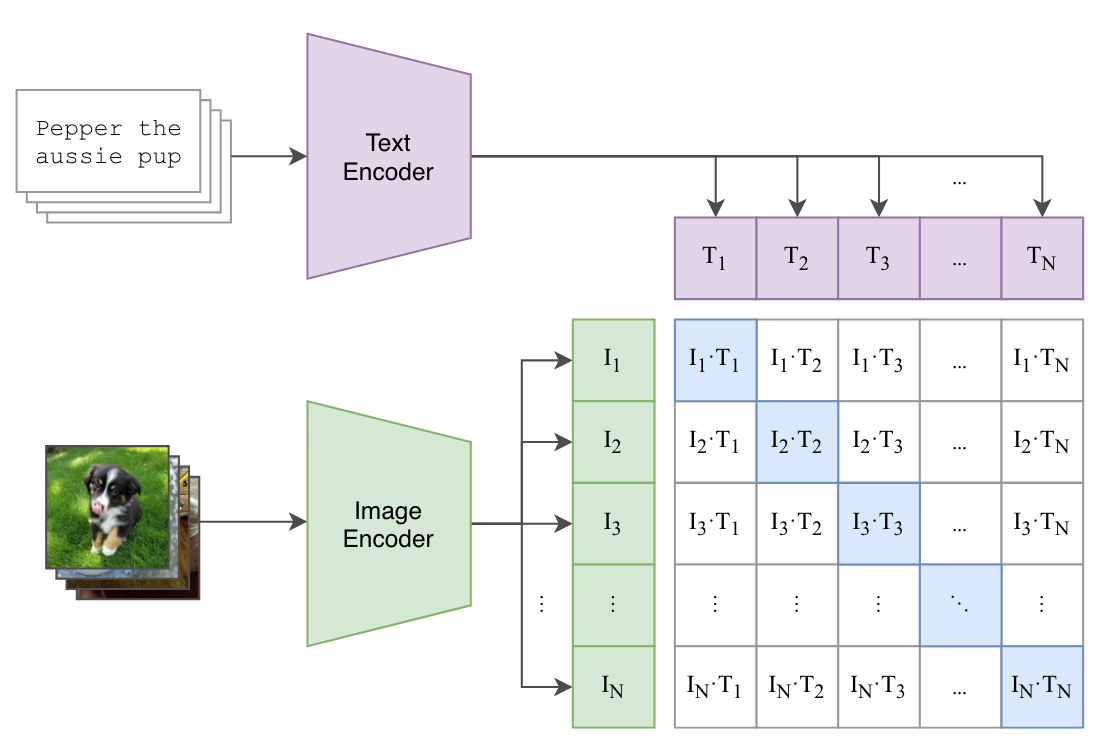
CLIP은 OpenAI에서 개발한 멀티모달 AI 모델로, 텍스트와 이미지를 함께 이해하는 모델이야. 기본적으로, 텍스트와 이미지가 연관된 정도를 학습하여 이미지 검색, 분류, 생성 등 다양한 작업을 수행할 수 있어.Contrastive Learning(대조 학습) 방식
45.[딥러닝] FastestDet

FastestDet은 초경량 앵커 프리(Anchor-Free) 객체 탐지 알고리즘으로, 모델 크기가 250K 파라미터에 불과하며, yolo-fastest 대비 시간 소모를 10% 절감하고 후처리 과정도 단순화되었습니다.Github향상된 성능: Yolo-fastest 대
46.Fine-Tuning YOLOv12: Comparison with YOLOv11 & Darknet-Based YOLOv7

https://learnopencv.com/fine-tuning-yolov12/이 글은 최신 객체 탐지 모델인 YOLOv12, YOLOv11, 그리고 Darknet 기반 YOLOv7을 HRSC2016-MS 데이터셋에 맞게 미세 조정(fine-tuning)하는
47.[딥러닝]Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP
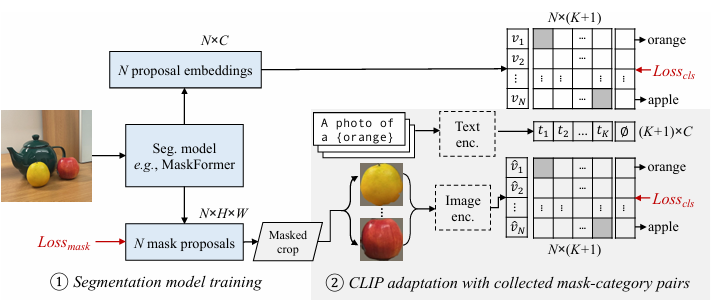
이 논문은 개방형 어휘 의미 분할(open-vocabulary semantic segmentation)을 위한 새로운 접근 방식을 제안합니다. 기존의 의미 분할 모델들은 사전에 정의된 카테고리 집합에 대해서만 훈련되어, 훈련 데이터에 없는 새로운 클래스를 인식하는 데
48.[딥러닝] YOLOE : Real-Time Seeing Anything

YOLOE는 기존 YOLO 계열(object detection) 모델들을 기반으로 성능과 효율성을 더욱 향상시킨 변형 모델 중 하나입니다. 일반적으로 “YOLO Enhanced” 혹은 “PP-YOLOE”라는 이름으로도 불리며, Baidu의 PaddleDetection
49.[딥러닝] nanoVLM
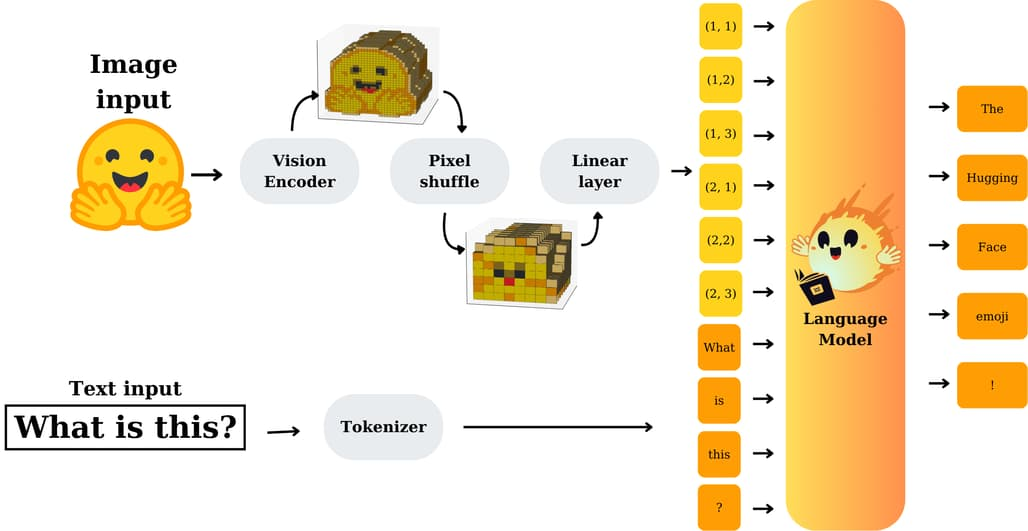
nanoVLM GithubHugging Face가 최근 공개한 nanoVLM은 단 750줄의 순수 PyTorch 코드로 구성된 초경량 비전-언어 모델입니다. 복잡한 종속성이나 무거운 프레임워크 없이, 단일 GPU에서도 학습 가능한 이 프로젝트는 비전-언어 모델 구조를
50.[딥러닝]Marigold: Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation

단안 깊이 추정(monocular depth estimation) 은 단일 2D 이미지로부터 3D 공간의 깊이 정보를 예측하는 기본적인 컴퓨터 비전 과제입니다.그러나 단일 이미지에서 깊이를 추정하는 것은 기하학적으로 잘 정의되지 않은 문제(ill-posed proble
51.[딥러닝] FastVLM

시각‑언어 모델(VLM)은 이미지와 텍스트를 동시에 이해하면서 질의응답, 이미지 캡션 생성, UI 내비게이션 보조 등 다양한 멀티모달 AI 응용에서 중심 기술로 부상했습니다. 특히 문서 이미지, 차트, 손글씨처럼 텍스트 정보가 풍부한 이미지를 처리할 때 높은 해상도의
52.[LLM] Claude Code on the web

Anthropic이 최근 발표한 Claude Code on the Web은 브라우저에서 직접 코딩 작업을 수행할 수 있도록 지원하는 새로운 기능입니다. 기존에는 터미널을 통해 수행하던 코딩 세션을 이제 웹 환경에서 바로 실행할 수 있으며, 버그 수정, 루틴한 작업 자동
53.[딥러닝] YOLO26: A Comprehensive Architecture Overview and Key Improvements
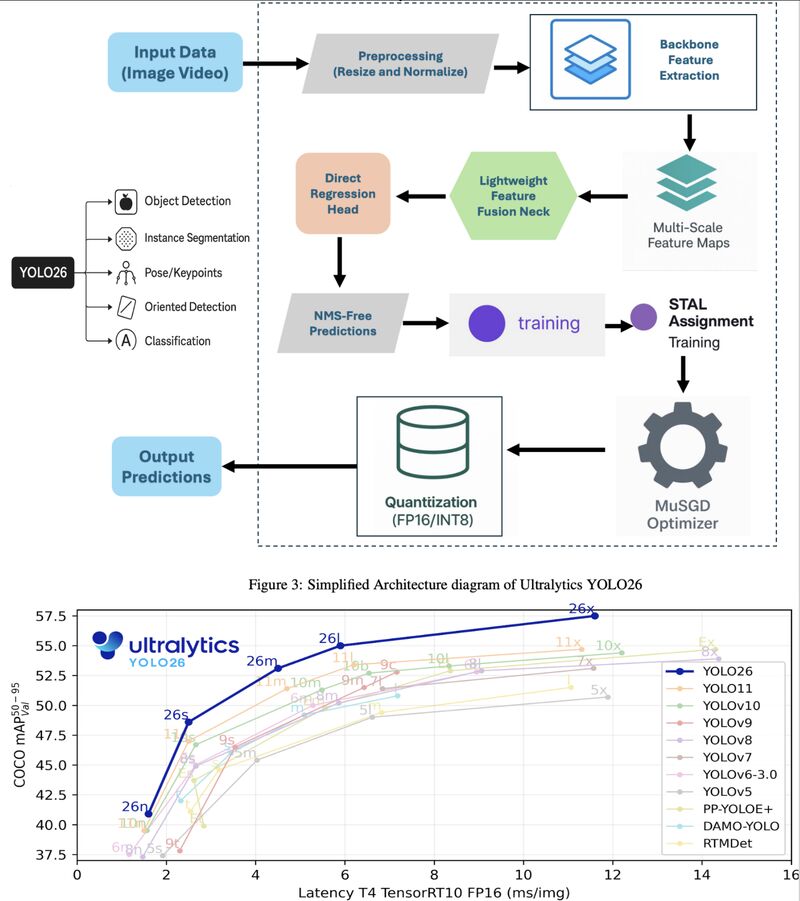
YOLO26YOLO(You Only Look Once)는 10년간 딥러닝 컴퓨터 비전의 대표 모델이었습니다. 이 논문은 YOLO 시리즈의 최신 버전인 YOLO26의 새로운 특징을 탐구합니다.핵심 개선사항은 4가지입니다: DFL 제거, NMS-Free 추론, ProgLo
54.[딥러닝] QWEN3.5 : 초기부터 멀티모달 데이터로 학습한, 에이전트 중심의 워크플로우에 최적화된 Native Multimodal Agent Model
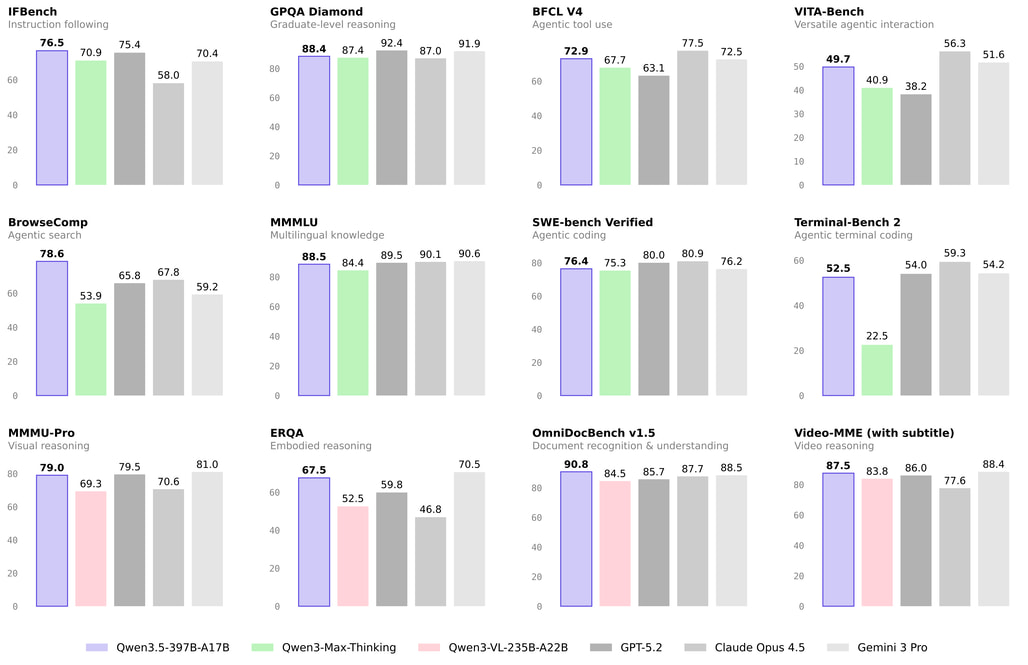
최근 대규모 언어 모델(LLM) 생태계는 텍스트를 넘어 이미지, 비디오 등 다양한 형태의 데이터를 동시에 이해하고, 실세계 환경에서 주도적으로 도구를 활용하는 네이티브 멀티모달 에이전트(Native Multimodal Agent) 시대로 진입하고 있습니다. 이러한 흐름
55.AITune: NVIDIA가 공개한 딥러닝 모델 추론 성능 자동 최적화 파이썬 라이브러리
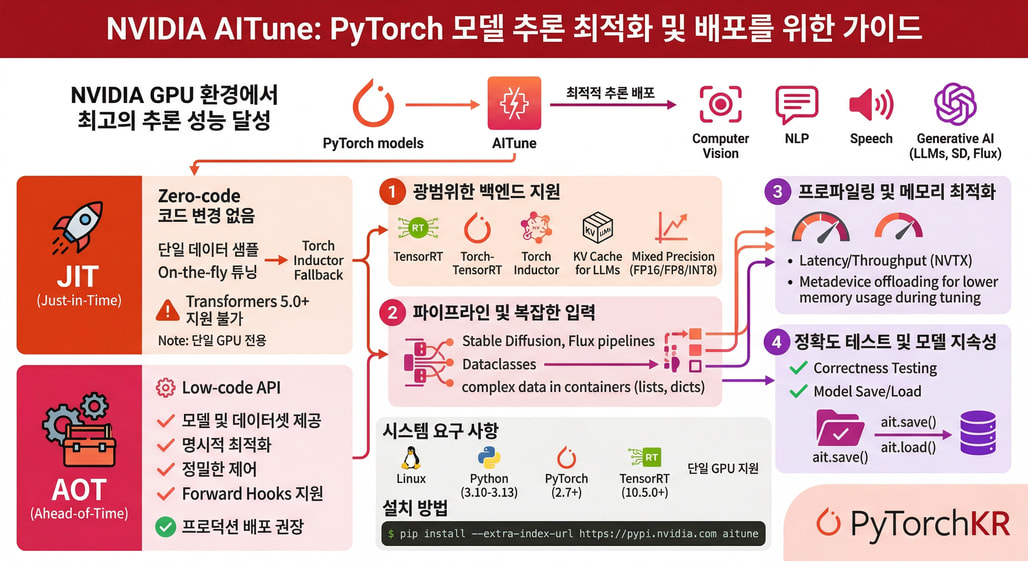
딥러닝 모델을 프로덕션 환경에 배포할 때 가장 큰 과제 중 하나는 추론 성능 최적화입니다. TensorRT(텐서알티), TorchAO, Torch Inductor 등 다양한 최적화 백엔드가 존재하지만, 각각 다른 API와 설정 방식을 요구하기 때문에 실무에서는 어떤 백
56.[딥러닝] Google DeepMind, 모바일 기기부터 클라우드까지 사용 가능한, 통합 멀티모달 모델 Gemma 4

구글 딥마인드(Google DeepMind)는 지난 밤, 자사의 가장 지능적이고 강력한 개방형 모델(Open Weights Models)인 Gemma 4 라인업을 공식 발표했습니다. 이 모델은 업계를 선도하는 Gemini 3을 기반으로 최신 연구 및 아키텍처를 동일하게
57.[딥러닝] QWEN 에서의 Attention 메커니즘 변화
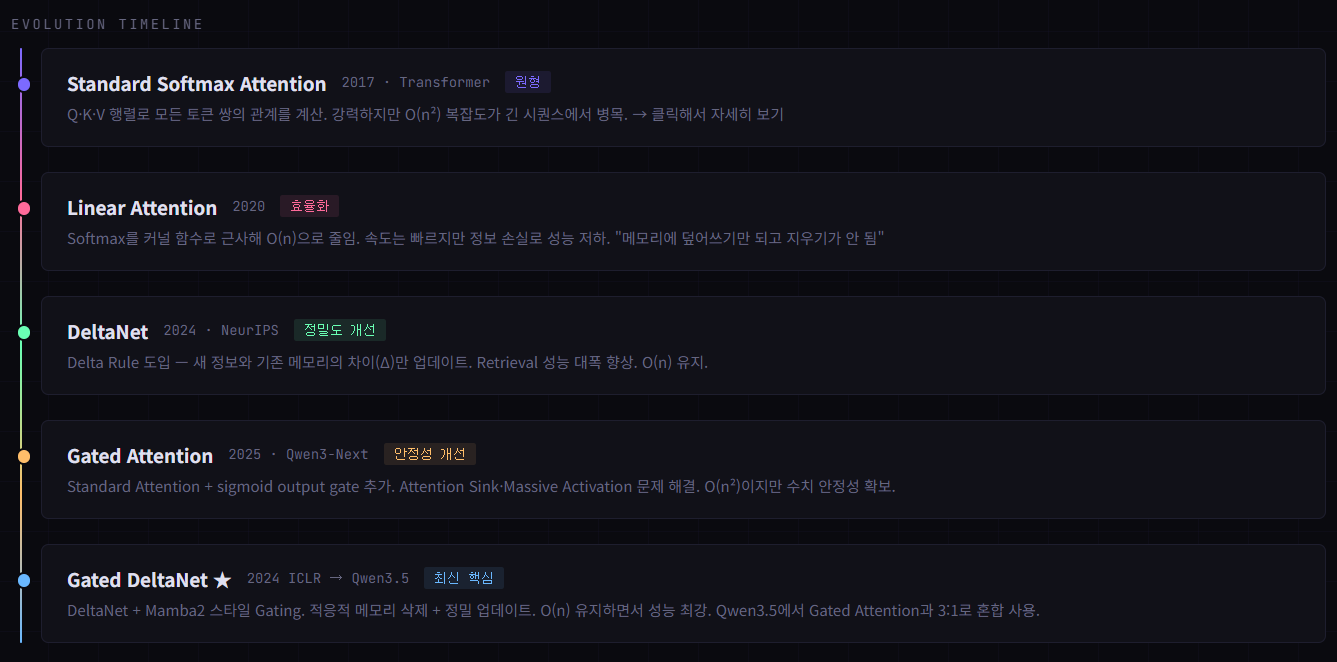
Standard Attention → Gated DeltaNet 까지 변화를 정리해 보았다Transformer의 원형. 모든 토큰이 서로를 "바라보는" 완전 연결 구조. 강력하지만 비쌈.강점모든 위치 간 직접 연결 → 장거리 의존성 완벽 포착. 표현력 최강.약점O(n²