Technical Debt and System Complexity
머신러닝 시스템의 복잡성과 기술 부채
DevOps의 토대가 자동화와 협업의 원칙을 제공하는 것은 사실이지만, 머신러닝 시스템은 이를 효과적으로 관리하기 위해 새로운 엔지니어링적 접근이 필요한 독특한 복잡성을 수반합니다.
코드가 망가지면 즉시 오류가 발생하는 전통적인 소프트웨어와 달리, ML 시스템은 데이터의 변화, 모델 간의 상호작용, 그리고 진화하는 요구사항 등으로 인해 '조용히(silently)' 성능이 저하될 수 있습니다.
연합 학습 시스템이 고유한 조정 문제에 직면하거나, 견고한 시스템 구축을 위해 세심한 모니터링이 필요한 것처럼, 모든 배포 환경은 운영 효율성과 보안 요구사항 사이의 균형을 잡아야 합니다.
'기술 부채(Technical Debt)'라고 통칭되는 이러한 운영상의 과제들을 이해하는 것은, 이후에 다룰 엔지니어링 솔루션과 관행들을 도입해야 하는 핵심적인 동기가 됩니다.
이러한 복잡성은 머신러닝 시스템이 성숙하고 확장됨에 따라 '기술 부채', 즉 개발 과정에서 내린 편의 중심의 설계 결정이 초래하는 장기적인 비용을 축적하며 나타납니다.
1990년대 소프트웨어 엔지니어링 분야에서 처음 제안된 이 비유는 구현 과정에서의 지름길(shortcuts)을 금융 부채에 비유한 것입니다. 단기적으로는 개발 속도를 높일 수 있지만, 결국 유지보수, 리팩토링, 시스템 리스크라는 형태로 지속적인 '이자'를 지불하게 만든다는 의미입니다.
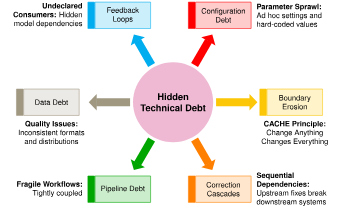
이러한 운영상의 과제들은 ML 시스템이 진화함에 따라 팀들이 마주하게 되는 몇 가지 뚜렷한 패턴으로 나타납니다. 모든 부채 패턴을 나열하기보다는, MLOps가 제공하는 엔지니어링 접근 방식을 잘 보여주는 대표적인 사례들에 집중하고자 합니다. 각각의 과제는 머신러닝 워크플로우만이 가진 고유한 특성에서 비롯됩니다.
-
데이터 의존성: 확정적(deterministic) 로직보다 데이터에 의존한다는 점.
-
통계적 동작: 정확한 이분법적 동작보다는 통계적인 동작을 보인다는 점.
-
암시적 종속성: 명시적인 인터페이스보다는 데이터 흐름(data flows)을 통해 암시적인 종속성을 만드는 경향이 있다는 점입니다.
다음에 이어지는 기술 부채 패턴들은 왜 전통적인 DevOps 관행이 ML 시스템을 위해 확장되어야 하는지를 보여주며, 이후 섹션에서 제시할 인프라 솔루션들의 필요성을 뒷받침합니다.
Boundary Erosion
경계 침식(Boundary Erosion): ML 시스템의 보이지 않는 위협
전통적인 소프트웨어 시스템에서는 모듈화와 추상화를 통해 구성 요소 간의 명확한 경계를 설정하며, 이를 통해 변경 사항을 격리하고 시스템의 동작을 예측 가능한 상태로 유지합니다. 반면, 머신러닝 시스템은 이러한 경계가 모호해지는 경향이 있습니다. 데이터 파이프라인, 특성 공학(feature engineering), 모델 훈련, 그리고 하위 소비(downstream consumption) 단계 사이의 상호작용은 흔히 인터페이스가 불분명하고 서로 단단히 결합된(tightly coupled) 구성 요소를 만들어냅니다.
이러한 경계의 침식은 ML 시스템을 아주 작은 변화에도 연쇄적인 효과(cascading effects)를 입기 쉬운 취약한 상태로 만듭니다. 전처리 단계나 특성 변환에서의 겉보기에 사소한 업데이트가 시스템 전체에 예상치 못한 방식으로 전파되어 파이프라인의 다른 곳에서 세워둔 가정들을 깨뜨릴 수 있습니다. 이러한 캡슐화의 부재는 '얽힘(entanglement)'의 위험을 증가시키며, 구성 요소 간의 종속성이 너무 밀접해져서 국부적인 수정조차 시스템 전체에 대한 이해와 조정을 요구하게 됩니다.
CACHE 원칙: 하나를 바꾸면 모든 것이 바뀐다
이 문제의 대표적인 현상 중 하나는 CACHE(Change Anything Changes Everything, 하나를 바꾸면 모든 것이 바뀐다)로 알려져 있습니다. 강한 경계 없이 구축된 시스템에서는 특성 인코딩, 모델 하이퍼파라미터 또는 데이터 선택 기준을 조정하는 것만으로도 하위 시스템의 동작에 예측 불가능한 영향을 미칠 수 있습니다. 이는 반복적인 실험을 저해하고 테스트와 검증을 더욱 복잡하게 만듭니다. 예를 들어, 수치형 특성의 구간화(binning) 전략을 변경하면 이전에 튜닝된 모델의 성능이 떨어질 수 있으며, 이는 결국 모델 재학습과 하위 평가 지표의 변화를 촉발합니다.
완화 전략: 모듈화와 캡슐화
경계 침식을 완화하기 위해 팀은 모듈화와 캡슐화를 지원하는 아키텍처 관행을 우선시해야 합니다. 명확하게 정의된 인터페이스로 구성 요소를 설계하면 결함을 격리하고, 변경 사항의 영향을 추론하며, 시스템 전반의 회귀(regression) 위험을 줄일 수 있습니다. 예를 들어, 데이터 수집(ingestion)을 특성 공학에서 분리하고, 특성 공학을 모델링 로직에서 명확히 분리하면 각 계층을 독립적으로 검증, 모니터링 및 유지 관리할 수 있는 구조가 마련됩니다.
경계 침식은 개발 초기에는 보이지 않지만, 시스템이 확장되거나 적응이 필요할 때 큰 부담으로 다가옵니다. 그러나 확립된 소프트웨어 엔지니어링 관행을 통해 이 문제를 효과적으로 예방하고 완화할 수 있습니다. 추상화를 보존하고 상호 의존성을 제한하는 선제적인 설계 결정과 체계적인 테스트, 인터페이스 문서화의 결합은 복잡성을 관리하고 장기적인 유지보수 비용을 피할 수 있는 실질적인 해결책을 제공합니다.
이러한 도전 과제가 발생하는 이유는 ML 시스템이 논리적 보증이 아닌 통계적 보증(statistical guarantees)으로 작동하기 때문이며, 이로 인해 전통적인 소프트웨어 엔지니어링의 경계를 강제하기가 더 어렵습니다. 경계 침식이 왜 그렇게 빈번하게 발생하는지 이해하려면 머신러닝 워크플로우가 기존의 소프트웨어 개발과 어떻게 다른지 살펴봐야 합니다.
-
데메테르의 법칙 위반: ML 시스템의 경계 침식은 '데메테르의 법칙(Law of Demeter)' 및 '최소 지식 원칙(principle of least knowledge)'과 같은 기존 소프트웨어 엔지니어링 원칙을 위반합니다.
-
암시적 결합: 전통적인 소프트웨어가 명시적 인터페이스와 정보 은닉을 통해 모듈화를 달성하는 반면, ML 시스템은 이러한 명시적 경계를 우회하는 데이터 흐름을 통해 암시적인 결합을 생성합니다.
-
리스코프 치환 원칙의 붕괴: CACE 현상은 리스코프 치환 원칙(Liskov Substitution Principle)의 붕괴를 의미하며, 구성 요소의 수정이 해당 구성 요소에 의존하는 다른 요소들이 기대하는 행동 계약을 위반하게 됩니다.
컴파일 타임에 보증이 이루어지는 전통적인 소프트웨어와 달리, ML 시스템은 통계적 동작을 기반으로 작동하므로 본질적으로 다른 결합 패턴을 만들어냅니다. 결국 핵심 과제는 통계적 종속성과 데이터 기반 동작이 만들어내는 이러한 복잡한 결합 패턴을, 전통적인 소프트웨어 엔지니어링 프레임워크가 다루지 못했던 영역까지 확장하여 전통적인 모듈화 개념과 조화시키는 데 있습니다.
Correction Cascades
수정 연쇄
머신러닝 시스템은 진화하면서 성능 문제를 해결하거나, 새로운 요구사항을 수용하고, 혹은 환경 변화에 적응하기 위해 종종 반복적인 개선(iterative refinement) 과정을 거칩니다. 엔지니어링이 잘 된 시스템에서는 이러한 업데이트가 모듈식 변경을 통해 국지적으로 격리되어 관리됩니다. 그러나 ML 시스템에서는 아주 작은 조정조차도 워크플로우의 전후방으로 전파되는 일련의 종속적 수정 사항인 '수정 연쇄(Correction Cascades)'를 유발할 수 있습니다.
그림 4는 이러한 연쇄 효과가 ML 시스템 개발 과정에서 어떻게 전파되는지 시각화하여 보여줍니다. 이러한 연쇄 반응의 구조를 이해하면 팀이 그 영향을 미리 예측하고 완화하는 데 큰 도움이 됩니다.
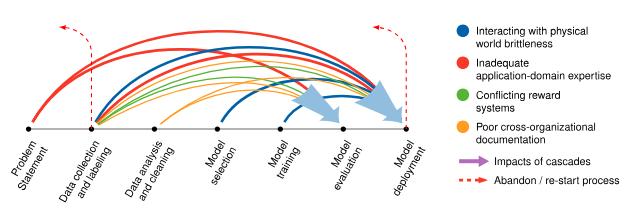
그림은 문제 정의와 데이터 수집부터 모델 개발 및 배포에 이르기까지 ML 수명 주기(lifecycle)의 각 단계에서 이러한 연쇄 반응이 어떻게 발생하는지 설명합니다.
-
교정 작업: 다이어그램의 각 아크(arc)는 수행된 교정 작업을 나타냅니다.
-
불안정성의 원인: 아크의 색상은 다음과 같은 다양한 불안정성 소스를 나타냅니다:
부족한 도메인 전문 지식 취약한 실세계 인터페이스 불일치된 인센티브 불충분한 문서화 -
연쇄적 수정: 빨간색 화살표는 연쇄적으로 발생하는 수정을 의미합니다.
-
시스템 전체 재시작: 하단의 점선 화살표는 비록 극단적이지만 때로는 불가피한 결과인 시스템 전체 재시작(full system restart)을 강조합니다.
수정 연쇄가 발생하는 흔한 원인 중 하나는 순차적 모델 개발(sequential model development)입니다. 이는 새로운 작업을 수행할 때 개발 속도를 높이기 위해 기존 모델을 재사용하거나 미세 조정(fine-tuning)하는 방식입니다. 이 전략은 효율적일 때가 많지만, 나중에 풀기 어려운 숨겨진 종속성을 유발할 수 있습니다. 초기 모델에 포함된 가정들이 후속 모델들에게는 암묵적인 제약 사항이 되어, 유연성을 제한하고 하류(downstream) 단계에서 발생하는 수정 비용을 높이게 됩니다.
예를 들어, 한 팀이 신규 제품을 위해 기존의 고객 이탈 예측 모델을 미세 조정한다고 가정해 봅시다. 원래 모델에는 새 환경에서는 유효하지 않은 특정 제품만의 행동 방식이나 특성 인코딩이 내포되어 있을 수 있습니다. 성능 문제가 발생하기 시작하면 팀은 모델을 패치(수정)하려고 시도하겠지만, 문제의 근본 원인이 훨씬 상류 단계인 초기 특성 선택이나 라벨링 기준에 있다는 것을 뒤늦게 발견하게 될 뿐입니다.
수정 연쇄의 영향을 피하거나 줄이려면, 팀은 재사용과 재설계 사이에서 신중한 트레이드오프(trade-off)를 결정해야 합니다. 몇 가지 요인이 이 결정에 영향을 미칩니다.
데이터 규모와 변화 속도: 정적인 소규모 데이터셋의 경우 미세 조정이 적합할 수 있습니다. 반면, 대규모이거나 빠르게 변화하는 데이터셋의 경우 처음부터 다시 학습(retraining from scratch)하는 것이 더 높은 통제권과 적응성을 제공합니다.
-
자원 제약: 미세 조정은 계산 자원을 적게 소모하므로 자원이 제한된 환경에서 매력적입니다.
-
장기적 비용: 하지만 이러한 연쇄 효과 때문에 나중에 기초가 되는 구성 요소를 수정하는 것은 매우 막대한 비용을 초래하게 됩니다.
따라서 자원이 많이 들더라도 나중에 발생할 수정 연쇄를 방지하기 위해 새로운 모델 아키텍처를 도입하는 것을 신중히 고려해야 합니다. 이러한 접근 방식은 하류에서 발생하는 문제의 증폭 효과를 완화하고 기술 부채를 줄이는 데 도움이 될 수 있습니다. 물론 순차적 모델 구축이 여전히 합리적인 시나리오도 존재하므로, ML 개발 프로세스에서 효율성, 유연성, 그리고 장기적 유지보수성 사이의 사려 깊은 균형이 필요합니다.
수정 연쇄 패턴은 소프트웨어 엔지니어링에서 확립된 시스템 모듈화 원칙을 위반하는 '숨겨진 피드백 루프'에서 발생합니다. 모델 A의 출력이 모델 B의 훈련 데이터에 영향을 미칠 때, 이는 모듈식 설계를 약화시키는 암묵적 종속성을 생성합니다. 이러한 종속성은 명시적인 코드 인터페이스가 아닌 데이터 흐름(data flows)을 통해 작동하기 때문에 전통적인 종속성 분석 도구로는 감지할 수 없어 특히나 더 위험합니다.
시스템 이론의 관점에서 볼 때, 수정 연쇄는 서로 독립적이어야 할 구성 요소들이 강하게 결합(tight coupling)되어 있는 사례를 나타냅니다.
-
멱법칙 분포(Power-law distributions): 연쇄의 전파는 멱법칙을 따르는데, 이는 초기 단계의 아주 작은 변화가 시스템 전체에 불균형적으로 큰 수정을 촉발할 수 있음을 의미합니다.
-
나비 효과: 이는 복잡계에서의 '나비 효과'와 유사하며, 미세한 섭동(perturbation)이 비선형적 상호작용을 통해 증폭되는 현상입니다.
이러한 이론적 토대를 이해하면, 수정 연쇄를 방지하기 위해 단순히 더 좋은 도구를 사용하는 것을 넘어 학습 구성 요소가 존재하더라도 시스템의 모듈성을 보존할 수 있는 아키텍처 결정이 필요함을 알 수 있습니다. 핵심 과제는 데이터 중심 워크플로우의 본질적인 상호 연결성에도 불구하고, 느슨한 결합(loose coupling)을 유지하는 ML 시스템을 설계하는 것입니다.
