머신러닝 프로토타입이 프로덕션에서 실패하는 이유 및 MLOps의 목표
이번 포스팅에서는 머신러닝(ML) 프로토타입이 개발 환경에서는 완벽하게 작동해도 실제 운영(프로덕션) 환경에 배포될 때 치명적으로 실패하는 이유 및 이러한 문제를 해결하기 위해 MLOps(Machine Learning Operations)라는 별도의 엔지니어링 분야가 새롭게 등장하는 것에 대해 알아봅니다.
ML 시스템은 기존의 확정적인(deterministic) 소프트웨어와 달리 확률적(probabilistic) 특성을 가지며, 실제 환경의 변화에 따라 성능이 조용히(silent) 저하될 수 있기 때문에 특별한 운영 관리가 필요합니다.
실패의 주요 원인: 개발 환경과 프로덕션 환경의 차이
- 데이터 분포 변화 (Data Drift/Shift): 연구 모델은 클린한(clean) 데이터셋으로 학습되지만, 프로덕션 환경에서는 변화하는 데이터 분포, 진화하는 사용자 행동 등 훈련 시점과 다른 실제 조건에 직면합니다.
- 예측의 불확실성 (Prediction Uncertainty): ML 시스템은 확률적 동작을 보이며, 실제 조건이 훈련 가정에서 멀어지면 성능 저하가 사용자에게 영향을 미치기 전에 감지하기 어렵습니다.
- 엔지니어링 요구 사항: 이러한 불안정성은 성능 저하를 감지하고, 데이터 변화에 따라 모델을 자동으로 재학습하며, 예측 불확실성에도 불구하고 시스템의 신뢰성을 유지할 수 있는 운영 관행을 요구합니다.
MLOps의 등장 및 주요 학습 목표
MLOps는 실험적 검증과 프로덕션 신뢰성 사이의 간극을 메워, 모델이 운영 수명 기간 내내 효과를 유지할 수 있도록 지원하는 엔지니어링 규율입니다.
-
MLOps의 필요성 이해
전통적인 소프트웨어 실패 vs. ML 시스템의 조용한 실패: ML 시스템의 예측이 틀려도 시스템 자체는 작동하는 '조용한 실패'의 특성을 이해하고, 왜 MLOps가 별개의 엔지니어링 분야로 부상했는지 설명합니다. -
ML 시스템의 기술 부채 및 해결책 분석
기술 부채 패턴 분석: 경계 침식(boundary erosion), 수정 연쇄(correction cascades), 데이터 종속성(data dependencies)과 같은 ML 시스템 특유의 기술 부채 패턴을 분석하고 체계적인 엔지니어링 솔루션을 제안합니다. -
ML 특화 CI/CD 파이프라인 설계
CI/CD (Continuous Integration/Continuous Delivery) 설계: 모델 검증, 데이터 버전 관리, 자동 재학습 워크플로우 등 ML 고유의 과제를 해결하는 CI/CD 파이프라인을 설계합니다. -
모니터링 전략 평가
생산 ML 시스템 모니터링: 전통적인 시스템 지표뿐만 아니라, 데이터 드리프트(data drift) 및 예측 신뢰도(prediction confidence)와 같은 ML 특유의 지표를 감지하는 모니터링 전략을 평가합니다. -
배포 패턴 구현
다양한 환경 배포: 클라우드 서비스, 엣지 디바이스, 연합 학습 시스템 등 다양한 환경에 대한 배포 패턴을 구현합니다. -
조직 성숙도 평가
MLOps 구현: 효과적인 MLOps 구현을 위한 조직의 성숙도 수준을 평가합니다. -
도메인별 MLOps 적응 비교
특수 요구 사항 분석: 헬스케어, 임베디드 시스템 등 특화된 요구 사항이 운영 프레임워크를 어떻게 재구성하는지 분석하여 도메인별 MLOps 적용 방식을 비교합니다. -
거버넌스 프레임워크 구축
규제 환경 대응: 규제 환경에서 모델의 재현성, 감사 가능성, 규정 준수를 보장하는 거버넌스 프레임워크를 만듭니다.
MLOps: 기계 학습 운영의 핵심 원리와 역할
경고 없는 실패와 MLOps의 등장 배경
-
전통 소프트웨어의 실패: 기존 소프트웨어는 오류 메시지나 스택 추적(stack traces)을 통해 시끄럽게(loudly) 실패합니다.
-
ML 시스템의 조용한 실패: ML 시스템은 데이터 분포가 바뀌거나 사용자 행동이 진화하는 등의 변화로 인해 성능이 점진적으로 저하되지만, 시스템 자체는 계속 작동하여 경고 없이(without raising any alarms) 조용히 실패합니다.
-
MLOps의 역할: MLOps는 이러한 조용한 실패를 가시화하고 관리하기 위해 고안된 엔지니어링 규율입니다. 변화하는 환경 속에서도 데이터 기반 시스템이 생산 환경에서 신뢰성을 유지하도록 필요한 모니터링, 자동화, 거버넌스를 제공합니다.
MLOps의 핵심 구성 요소 및 기능
MLOps는 머신러닝 방법론, 데이터 과학 관행, 소프트웨어 엔지니어링 원칙을 체계적으로 통합하여 자동화된 종단 간(end-to-end) 수명 주기 관리를 가능하게 합니다.
- 운영 복잡성 해결
-
실제 환경 문제: 예를 들어, 라이드셰어링 수요 예측 시스템의 경우, 실험 단계의 높은 정확도/낮은 지연 시간 외에도, 생산 환경에서는 데이터 스트림 품질의 변화, 계절적 패턴, 엄격한 가용성 및 실시간 응답 요구사항 등의 운영 복잡성이 추가됩니다.
-
MLOps의 해결책: MLOps는 이러한 운영상의 복잡성을 해결하는 프레임워크를 제공합니다.
- 표준화 및 협업 촉진
-
표준화된 프로토콜: 실험 환경에서 검증된 모델이 생산 시스템으로 전환되는 것을 용이하게 하기 위해 표준화된 프로토콜, 도구, 워크플로우를 구축합니다.
-
협업: 데이터 과학, 머신러닝 엔지니어링, 시스템 운영 등 전통적으로 분리되었던 도메인 간의 인터페이스와 책임을 정의하여 협업을 공식화합니다.
- 자동화 및 지속적 관리
-
CI/CD 확장: 머신러닝 환경에 맞춰 조정된 지속적 통합 및 배포(CI/CD) 관행을 지원합니다.
-
지속적인 모델 유지 관리: 새로운 데이터가 들어올 때마다 지속적인 모델 재학습을 가능하게 하며, 점진적 출시(graduated rollout) 전략을 통해 실험적 수정사항을 제어된 방식으로 배포합니다.
-
실시간 성능 평가: 운영 연속성을 저해하지 않으면서 실시간으로 성능을 평가하여 모델의 지속적인 관련성을 보장합니다.
- 거버넌스 및 책임
-
재현성 및 감사 가능성: 모델 버전 추적, 데이터 계보(data lineage) 문서화, 구성 매개변수 관리를 표준화하여 재현 가능하고 감사 가능한 아티팩트 경로를 구축합니다.
-
규정 준수: 모델 해석 가능성 및 운영 출처가 규정 준수 요건인 규제 환경에서 중요합니다.
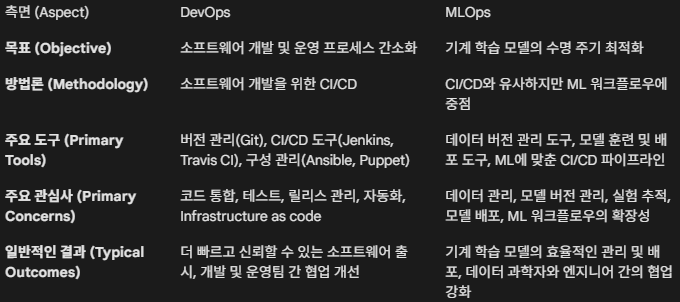
DevOps에서 MLOps로: 역사적 배경과 핵심 차이점
MLOps는 소프트웨어 개발 및 운영(DevOps)의 성공적인 원칙을 기반으로 하지만, 머신러닝(ML) 시스템의 고유한 문제를 해결하기 위해 진화한 별개의 엔지니어링 분야입니다. 이러한 진화를 이해하는 것은 현대 ML 시스템의 구조와 동기를 파악하는 데 중요합니다.
DevOps (소프트웨어 개발 및 운영)
DevOps는 소프트웨어 개발(Dev)과 IT 운영(Ops)을 결합한 일련의 관행입니다.
-
목표: 개발 수명 주기를 단축하고 고품질 소프트웨어의 지속적인 제공을 지원합니다.
-
배경: 2009년 Patrick Debois에 의해 창시되었으며, 개발팀과 운영팀이 사일로(silos)에서 일하는 전통적인 방식의 비효율성을 해결하기 위해 등장했습니다.
-
원칙: 공유 소유권, Infrastructure as Code, 자동화를 강조하여 배포 파이프라인을 간소화합니다.
-
주요 방법론: CI/CD(Continuous Integration and Continuous Delivery)를 구현하기 위해 Jenkins, Docker, Kubernetes와 같은 도구를 활용합니다.
-
결과: 더 빠르고 신뢰할 수 있는 소프트웨어 출시와 개발팀 및 운영팀 간의 개선된 협업을 이끌어냈습니다.
MLOps (기계 학습 운영)
MLOps는 DevOps의 문화적 및 기술적 토대 위에 구축되었지만, ML 워크플로우의 특정 요구 사항을 해결합니다.
-
목표: 머신러닝 모델의 수명 주기 최적화.
-
정의: 생산 환경에서 ML 시스템의 종단 간(end-to-end) 수명 주기를 관리하는 엔지니어링 규율로, 데이터 버전 관리, 모델 진화, 지속적인 재학습과 같은 고유한 과제를 해결합니다.
-
차이점: DevOps가 확정적(deterministic) 소프트웨어의 통합 및 제공에 중점을 둔다면, MLOps는 비확정적(non-deterministic)이며 데이터에 의존하는 워크플로우(데이터 수집, 전처리, 모델 훈련, 평가, 배포, 지속적 모니터링)를 관리해야 합니다. * 필요성 (조용한 실패): 모니터링이 시스템 가동 시간에만 초점을 맞추고 모델 성능 지표에는 집중하지 않아 조용한 데이터 드리프트(silent data drift)와 같은 문제로 인해 모델 정확도가 점진적으로 저하되고 비즈니스에 큰 손실을 입히는 실제 실패 사례가 발생합니다. MLOps는 지속적인 모델 모니터링 및 자동화된 재학습을 통해 이를 해결합니다.
MLOps의 주요 도전 과제
-
재현성 (Reproducibility): 코드, 데이터셋, 구성, 환경을 추적하는 표준화된 메커니즘이 부족하여 과거 실험을 재현하기 어렵습니다.
-
설명 가능성 (Explainability): 복잡한 모델에 대한 설명 가능성이 부족하여 투명성과 해석 가능성 도구에 대한 수요가 증가하고 있습니다.
-
운영 복잡성: 모델 성능 모니터링, 특히 조용한 실패 감지가 어려우며, 모델 재학습 및 재배포의 수동 오버헤드가 크고, ML 인프라 구성 및 유지 관리가 복잡하고 오류가 발생하기 쉽습니다.