머신러닝 기본을 위한 시리즈입니다 아래 링크에서 원본을 보실 수 있습니다
https://mlsysbook.ai/contents/core/introduction/introduction.html
1 Introduction

1.1 Why Machine Learning Systems Matter
머신러닝 시스템(Machine Learning Systems, MLSys)은 현대 인공지능(AI)의 근간을 이루며, 일상생활과 산업에 걸쳐 큰 영향을 미치고 있습니다. 머신러닝 시스템이 중요한 이유를 다음과 같이 정리할 수 있습니다:
- 일상에서의 AI 적용
머신러닝 시스템은 우리의 일상에 깊이 스며들어 있습니다. 아래는 일상생활에서 흔히 볼 수 있는 AI의 적용 사례입니다.
- 아침: AI 기반 스마트 알람은 사용자의 수면 패턴을 학습하여 깨우는 시간을 최적화합니다.
- 출근: 스마트폰은 교통 데이터를 학습하여 최적의 경로를 제안합니다.
- 업무: 이메일 클라이언트는 스팸을 필터링하고 중요한 메시지를 우선순위로 정렬합니다.
- 여가: 음악 앱은 사용자의 음악 취향을 학습하여 맞춤형 재생목록을 생성합니다.
- 건강 관리: 스마트워치는 활동 데이터를 분석해 운동 알림을 제공합니다.
- 가정: 스마트홈 장치는 학습된 사용자의 습관에 따라 조명과 온도를 자동 조절합니다.
이러한 사례들은 단순한 시작에 불과하며, 실제로 머신러닝 시스템은 의료, 환경, 과학, 그리고 예술 등 다양한 분야에서 혁신을 주도하고 있습니다.
- 머신러닝 시스템의 실제 응용
- 의료: AI는 초기 암을 정확히 진단하며, 질병의 진행을 추적합니다.
약물 개발에 있어 분자 상호작용을 시뮬레이션하여 신약 개발 속도를 높입니다. - 환경:AI는 극단적인 날씨를 예측하고 추적하여 생명을 구하는 데 기여합니다.
- 과학 및 기술:
AI는 단백질 구조를 예측하여 새로운 치료법 개발에 도움을 줍니다.
차세대 태양광 전지 및 배터리 소재를 찾는 데 활용됩니다. - 자동차:자율주행차는 센서를 통해 실시간 데이터를 분석하고 도시 환경을 탐색합니다.
- 언어 처리:언어 모델은 복잡한 대화를 수행하고, 수백 개의 언어를 번역하며, 방대한 연구 데이터베이스를 분석합니다.
- 창작 활동:AI는 예술가 및 음악가와 협력하여 창작 과정을 혁신하고, 인간의 창의성을 확장합니다.
- 머신러닝 시스템의 사회적 중요성
유비쿼터스 컴퓨팅(Ubiquitous Computing)의 실현: 1990년대, 컴퓨터 과학자 마크 와이저(Mark Weiser)는 컴퓨터가 환경에 자연스럽게 통합되고 인간의 주의를 요구하지 않는 '유비쿼터스 컴퓨팅' 개념을 제시했습니다. 오늘날, 머신러닝 시스템은 이 비전을 실현하며, 지능형 환경을 조성하여 인간의 요구를 예측하고 자동으로 반응합니다.
기술 인프라의 복잡성: 우리의 일상에서 발생하는 단순한 상호작용들 뒤에는 대규모의 데이터, 정교한 알고리즘, 복잡한 컴퓨팅 인프라가 있습니다. 이러한 기술적 요소들을 이해하고 최적화하는 것은 매우 중요합니다.
- 현대 머신러닝 시스템의 배경
현대 머신러닝 시스템은 단순한 기술 발전 이상의 의미를 가지며, 기술적 진화와 함께 인간의 사고방식 변화를 반영합니다. 초기 AI에서 시작된 기술들은 점차 사용자의 필요에 맞게 정교하게 발전했습니다. 이는 실생활에서 사용 가능하고 신뢰할 수 있는 AI를 만드는 데 있어 중요한 전환점이 되었습니다.
1.2 The Evolution of AI
AI는 다음과 같은 주요 단계를 통해 발전해왔습니다.
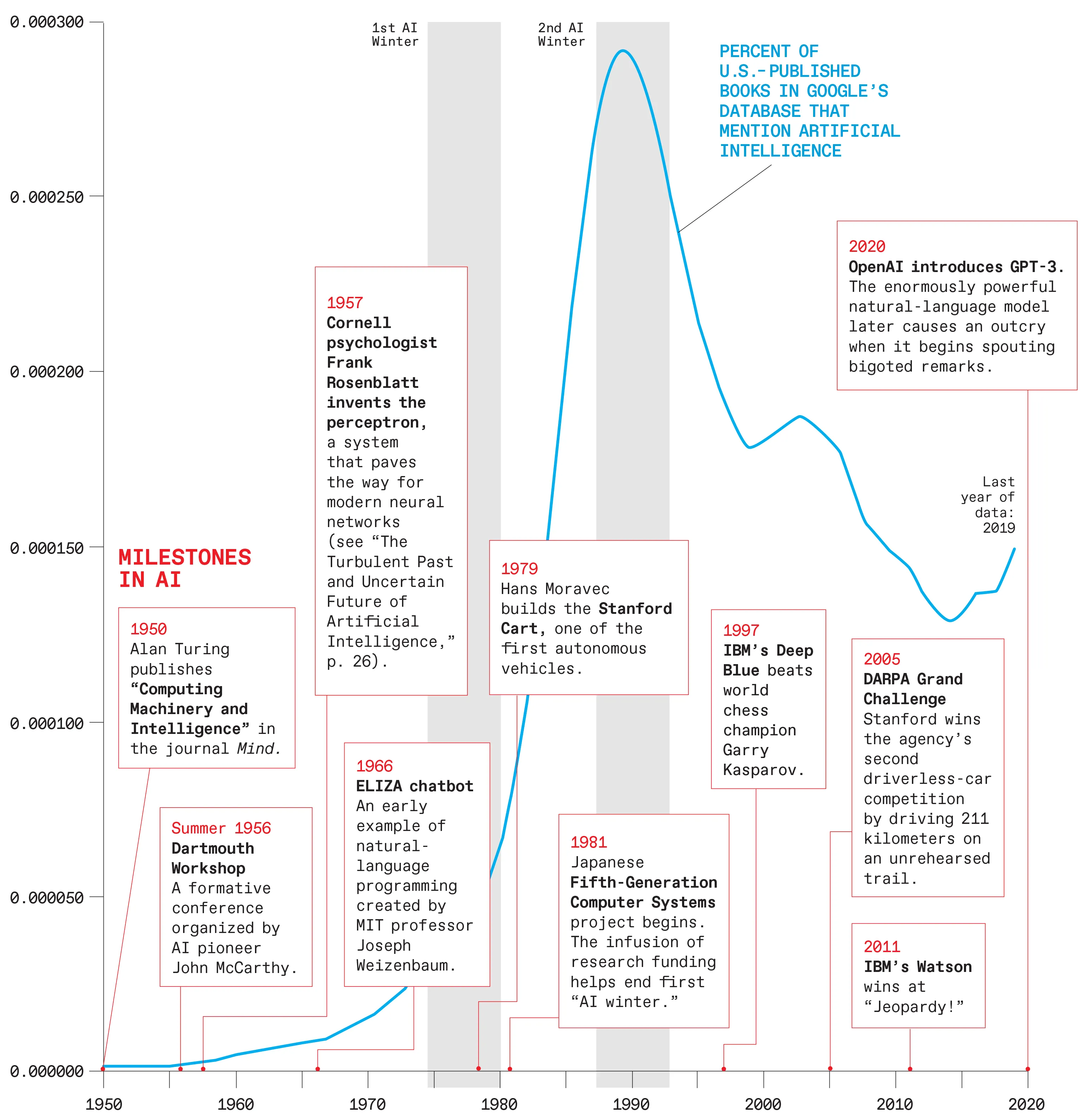
심볼릭 AI (1956-1974):초기 AI는 수학적 정리 증명 및 특정 문제 해결에 초점을 맞췄습니다. 그러나 규칙 기반 시스템의 한계(유연성 부족 등)가 발견되었습니다.
전문가 시스템 (1970-1980년대): 특정 도메인의 전문 지식을 활용하여 문제를 해결하는 방식이 개발되었습니다. 예: 의료 AI 시스템 MYCIN.
통계적 학습 (1990년대): 대량 데이터와 컴퓨팅 파워의 발전으로 AI는 규칙 기반에서 학습 기반으로 전환되었습니다. 이 시기에 서포트 벡터 머신(SVM)과 같은 알고리즘이 개발되었습니다.
얕은 학습(2000년대): SVM, 의사결정 나무 등 비교적 단순한 알고리즘이 데이터 처리에 사용되었으며, 사람의 피처 엔지니어링이 강조되었습니다.
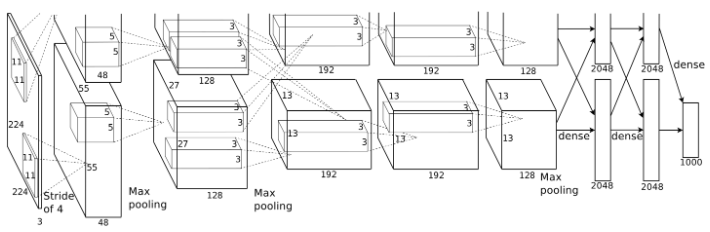
딥러닝 (2012년 이후): AlexNet이 이미지넷 대회에서 돌파구를 열며, 다층 신경망의 강력한 학습 능력을 증명했습니다. 이를 통해 현대 AI 기술의 초석이 마련되었습니다.
1.3 The Rise of ML Systems Engineering
AI의 발전은 이제 알고리즘 개발뿐만 아니라, 이를 실제 시스템에 적용하기 위한 엔지니어링으로 확장되었습니다. 이는 ML 시스템 엔지니어링이라는 새로운 학문 분야를 탄생시켰습니다.
정의: ML 시스템 엔지니어링은 알고리즘, 데이터, 컴퓨팅 인프라를 통합하여 AI 시스템을 설계, 구현, 운영하는 학문입니다.
특징:
데이터 수집 및 관리, 모델 훈련 및 배포 등 전 과정을 포함.
신뢰성과 효율성을 강조.
1.4 Definition of a ML System
머신러닝 시스템은 데이터, 알고리즘, 컴퓨팅 인프라로 구성된 통합 시스템입니다. 각 요소는 상호의존적이며, 이를 통해 예측, 생성, 행동 수행이 가능합니다.
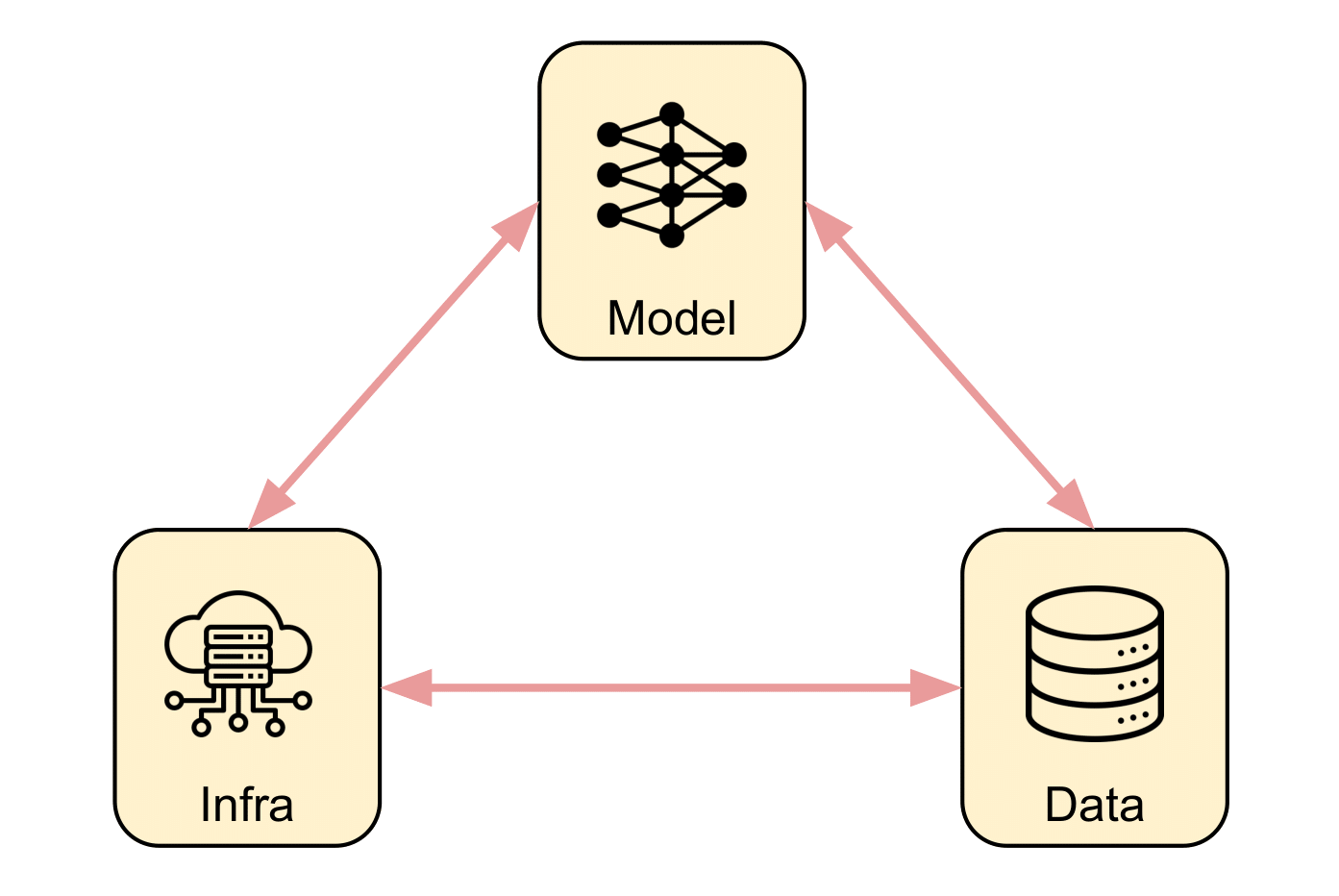
- 알고리즘: 데이터에서 패턴을 학습하는 수학적 모델.
- 데이터: 학습 및 추론을 지원하는 인프라.
- 컴퓨팅: 효율적 훈련 및 운영을 가능하게 하는 하드웨어 및 소프트웨어.
1.5 The ML Systems Lifecycle
머신러닝 시스템은 전통적인 소프트웨어 시스템과는 본질적으로 다른 특성을 가지고 있으며, 이러한 특성은 머신러닝 시스템의 생애 주기에서 명확히 드러납니다.

머신러닝 시스템의 생애 주기는 코드가 아닌 데이터가 시스템 동작의 핵심 원동력이라는 점에서 기존 소프트웨어 개발과는 큰 차이가 있습니다. 이에 따라 머신러닝 시스템은 새로운 형태의 복잡성을 도입합니다.
ML 시스템과 전통적인 소프트웨어 시스템의 차이점
-
전통적인 소프트웨어 시스템
명시적으로 작성된 코드를 실행합니다.
수십 년 동안 확립된 소프트웨어 공학 원칙에 따라 개발됩니다.
예: 버전 관리 시스템, CI/CD(Continuous Integration/Continuous Deployment) 파이프라인, 정적 분석 도구 등.
명확한 요구사항과 규칙 기반으로 작동합니다. -
머신러닝 시스템
데이터에서 패턴을 학습하여 행동을 결정합니다.
알고리즘, 데이터, 컴퓨팅 인프라가 상호작용하며 동작합니다.
데이터의 품질과 다양성이 시스템의 성능에 중요한 영향을 미칩니다.
명시적 규칙보다는 데이터에 의존하기 때문에 시스템이 더욱 불확실하고 예측하기 어렵습니다.
ML 시스템 생애 주기의 주요 단계
머신러닝 시스템은 다음의 주요 단계를 거쳐 설계, 구현, 배포, 운영됩니다.
- 문제 정의 및 요구사항 수집
- 목표 정의: 시스템이 해결하려는 문제를 명확히 설정.
- 예: 고객 이탈 예측, 자율주행차 경로 최적화 등. - 성공 기준 설정: 정확도, 신뢰성, 효율성 등 목표를 달성하기 위한 평가 메트릭 설정.
- 요구사항 수집: 데이터를 포함하여 시스템이 작동하는 데 필요한 모든 리소스를 정의.
- 데이터 수집 및 준비
-
데이터 수집:
- 시스템 성능을 결정하는 핵심 단계. 모델은 수집된 데이터로부터 학습합니다.
- 데이터의 양과 다양성은 시스템의 성능에 직접적인 영향을 미칩니다. -
데이터 전처리:
- 누락 값 처리, 이상치 제거, 데이터 정규화 등.
- 데이터 품질 보장을 위해 클린징 작업 수행. -
라벨링 및 주석 작업:
- 지도학습을 위해 데이터에 정확한 라벨을 부여.
- 예: 이미지 분류에서 각 이미지에 해당 클래스 라벨 추가.
- 모델 개발
-
알고리즘 선택:
- 문제 유형에 적합한 ML 알고리즘 선택 (예: 회귀, 분류, 딥러닝 등). -
모델 설계 및 훈련:
- 하이퍼파라미터 튜닝.
- 데이터의 학습을 통해 모델 성능 최적화. -
검증 및 테스트:
- 테스트 데이터셋에서 모델 성능 평가.
- 과적합 방지를 위한 교차 검증 수행.
- 시스템 통합
-
모델 배포:
- ML 모델을 실제 운영 환경에 통합.
- REST API 또는 온디바이스(On-device) 시스템으로 제공. -
엔드 투 엔드 통합:
- 데이터 수집 파이프라인, 모델, 사용자 인터페이스 간의 통합 작업.
- 예: 고객 이탈 예측 모델을 CRM 시스템에 연결.
- 배포 및 운영
-
모델 배포:
- 시스템이 실시간으로 작동하도록 클라우드 또는 온프레미스 인프라에 배포.
- CI/CD를 사용해 지속적으로 모델 업데이트. -
모니터링 및 유지보수:
- 모델이 예상대로 작동하는지 확인하기 위해 실시간 데이터 모니터링.
- 성능 저하, 데이터 드리프트(Data Drift), 개념 드리프트(Concept Drift)를 탐지. -
운영 환경에서의 안정성 보장:
- 모델 성능을 유지하고, 필요시 재훈련 수행.
- 지속적인 개선
-
성능 평가 및 피드백 루프:
- 모델 성능을 지속적으로 평가하고, 필요시 데이터와 모델을 업데이트.
- 사용자 피드백을 통해 시스템을 개선. -
데이터 재수집 및 재훈련:
- 새로운 데이터를 수집하여 모델이 최신 정보를 반영하도록 재훈련.
ML 시스템 생애 주기의 주요 도전 과제
-
데이터 중심 접근 방식의 복잡성:
- 데이터 품질 문제 해결.
- 데이터 라벨링 비용 및 시간.
-
운영 환경의 불확실성:
- 실시간 데이터에서 발생할 수 있는 문제 예측.
- 데이터 및 개념 드리프트 탐지 및 해결.
-
대규모 시스템 구현:
- 수천 개의 GPU를 활용한 모델 훈련.
- 대규모 데이터 파이프라인 설계 및 최적화.
-
모니터링 및 유지보수:
- 배포된 모델의 성능 저하를 실시간으로 감지하고 대응.
- 시스템 장애 복구 및 롤백 관리.
