머신러닝 시스템에 이어서 Data Engineering에 관한 포스팅 입니다
https://mlsysbook.ai/contents/core/data_engineering/data_engineering.html

데이터는 AI 시스템의 핵심입니다. 양질의 데이터 없이는 가장 발전된 머신러닝 알고리즘조차 성공할 수 없습니다. 그러나 TinyML 모델은 처리 능력과 메모리가 제한된 장치에서 작동합니다. 이 섹션에서는 AI 모델을 구동하기 위해 고품질 데이터셋을 구축하는 과정의 복잡성을 탐구합니다. 데이터 엔지니어링은 머신러닝 모델을 학습시키기 위해 데이터를 수집하고, 저장하며, 처리하고, 관리하는 과정을 포함합니다.
1 Overview
데이터 엔지니어링은 고성능 AI 시스템을 개발하기 위한 기초입니다. 이는 원시 데이터를 고품질 데이터셋으로 변환하여 AI 모델의 윤리적이고 강력한 개발을 위해 중요한 프라이버시, 대표성 격차, 데이터 유용성 문제를 해결하는 과정입니다.
- 데이터 엔지니어링의 중요성:
데이터가 풍부한 시대에도 단순히 데이터에 접근하는 것만으로는 부족합니다. 데이터를 적절히 처리하고 준비하며, 윤리적으로 관리하는 것이 신뢰할 수 있는 AI 모델을 구축하는 데 필수적입니다.
데이터 엔지니어링은 원시 데이터를 분석 가능하고 가치 있는 데이터로 변환하는 작업입니다.
- 프라이버시와 윤리적 도전 과제:
사용자 프라이버시 보호는 특히 의료와 같은 민감한 분야에서 매우 중요합니다.
차등 프라이버시(Differential Privacy), 데이터 집계, 익명화와 같은 기술을 사용하여 사용자 신뢰를 유지하면서도 데이터 유용성을 보장해야 합니다.
과도한 익명화는 프라이버시를 강화하지만 데이터의 유효성을 감소시킬 수 있습니다.
- 대표성 격차:
단순히 성별, 인종과 같은 개별 다양성 변수만이 아니라 고차원 격차(higher-order gaps)를 해결하는 것이 중요합니다.
예를 들어, 데이터셋이 성별과 나이에서는 균형이 맞더라도 특정 조건을 가진 고령 여성과 같은 하위 그룹이 부족할 수 있습니다. 이러한 격차는 모델 성능에 부정적인 영향을 미칠 수 있습니다.
- 윤리적이고 유용한 학습 데이터 구축:
데이터 익명화, 합성 데이터 생성, 과소대표 그룹의 균형 조정 등 다양한 접근 방식을 통해 윤리와 데이터 유용성 간의 균형을 맞추어야 합니다.
이해관계자 협업 및 외부 감사는 데이터셋 품질과 윤리성을 강화할 수 있습니다.
- 데이터셋 구축의 도전 과제:
프라이버시 위험, 대표성 격차, 법적 제한 등이 학습 데이터셋 생성 과정에서 복잡성을 초래합니다.
이러한 문제는 데이터 유용성, 윤리적 기준, 법적 준수 간의 신중한 조정을 통해 해결해야 합니다.
- 데이터 엔지니어링의 진화:
데이터 증강(data augmentation)으로 합성 샘플을 생성하여 데이터셋을 보강하거나, 버전 관리로 데이터 변경 사항을 추적하며, 메타데이터 문서화로 투명성과 재현성을 확보하는 등의 방식이 포함됩니다.
- 크로스펑셔널 협력:
기술적, 윤리적 팀 간의 협업을 통해 데이터셋이 성능과 사회적 책임 목표를 모두 충족할 수 있도록 보장합니다.
2 Problem Definition
머신러닝 프로젝트의 성공은 데이터의 품질에 크게 좌우됩니다. 그러나 고도화된 알고리즘에만 초점이 맞춰지다 보니 데이터의 근본적인 중요성이 종종 간과됩니다. 이로 인해 “데이터 캐스케이드(Data Cascades)”라고 불리는 문제가 발생할 수 있습니다. 데이터 품질의 미흡으로 인해 오류가 누적되어 잘못된 예측, 프로젝트 중단, 또는 더 나아가 커뮤니티에 피해를 주는 결과를 초래할 수 있습니다.
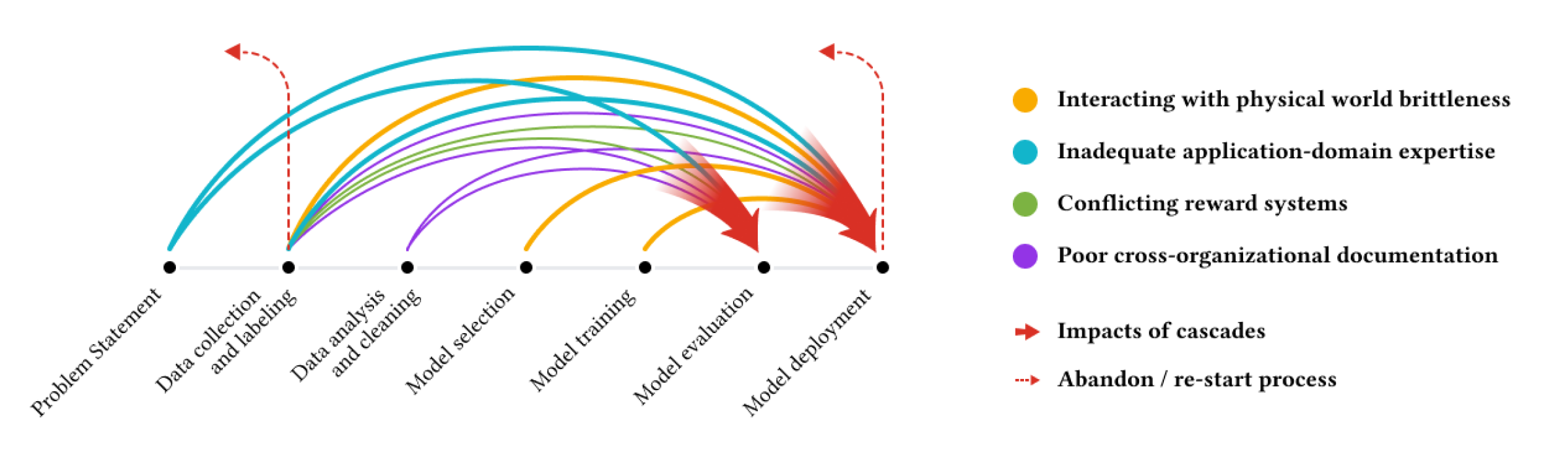
- 문제 식별 (Identifying the Problem):
프로젝트의 핵심 과제를 명확히 정의합니다.
예: 키워드 스포팅(KWS)에서는 소음과 다른 음성 속에서도 특정 키워드를 정확히 감지하는 시스템을 설계하는 것이 핵심입니다.
- 명확한 목표 설정 (Setting Clear Objectives):
프로젝트 목표를 구체적으로 정의합니다.
예: KWS의 경우, 키워드 감지 정확도 98% 달성, 200ms 이내 응답 시간, 전력 소모 최소화, 모델 크기를 제한된 메모리에 맞추기 등이 포함될 수 있습니다.
- 성공 기준 수립 (Establishing Success Benchmarks):
프로젝트 성공 여부를 평가할 수 있는 명확한 지표를 설정합니다.
예: 참 긍정률(True Positive Rate), 거짓 긍정률(False Positive Rate), 응답 시간(Response Time), 전력 소비(Power Consumption) 등이 지표로 사용될 수 있습니다.
- 이해관계자와의 협력 (Stakeholder Engagement):
장치 제조업체, 소프트웨어 개발자, 최종 사용자 등 다양한 이해관계자의 요구와 제약을 이해합니다.
예: 제조업체는 낮은 전력 소모를 우선시하고, 사용자는 정확도와 반응성을 중요하게 여길 수 있습니다.
- 제약과 한계 이해 (Understanding Constraints and Limitations):
임베디드 시스템과 같은 환경적 제약을 고려합니다.
예: KWS의 경우 제한된 메모리(16KB 이하), 낮은 처리 성능(수백 MHz), 다양한 소음 환경에서의 성능 유지 등의 제약이 포함됩니다.
- 데이터 수집 및 분석 (Data Collection and Analysis):
데이터의 다양성과 품질이 중요합니다.
예: 다양한 억양, 배경 소음, 키워드 발음 변이를 포함한 데이터 샘플을 수집해야 합니다.
3 Data Sourcing
AI 시스템 개발에서 데이터의 품질과 다양성은 정확성과 견고성을 보장하는 핵심 요소입니다. 데이터 소싱은 프로젝트 목표, 가용 리소스, 윤리적 고려사항을 바탕으로 데이터를 수집하는 과정입니다. 프로젝트의 요구에 따라 다양한 데이터 소싱 방법이 사용될 수 있습니다.
주요 데이터 소싱 방법
- 기존 데이터셋 활용 (Pre-existing Datasets)
플랫폼 예시:
Kaggle, UCI Machine Learning Repository, ImageNet
[장점]
비용 효율성: 새 데이터셋을 구축하는 데 필요한 시간과 비용을 절약.
표준 벤치마크 제공: 특정 연구 및 개발에서 기존 데이터셋은 성능 비교를 위한 기준점이 될 수 있음.
품질 보증: 널리 사용되는 데이터셋은 커뮤니티가 오류를 식별하고 수정하는 데 도움.
문서화: 데이터셋의 수집 과정, 변수 정의 및 베이스라인 성능 등을 제공.
[단점]
편향 및 현실과의 불일치: 기존 데이터셋은 종종 실제 세계 데이터를 충분히 반영하지 못할 수 있음.
재현성 문제: 다수의 모델이 동일 데이터셋으로 학습하면서 과대 적합(overfitting) 문제가 발생할 수 있음.
- 웹 스크래핑 (Web Scraping)
[개념]
자동화된 기술을 사용해 웹사이트에서 데이터를 추출.
주로 HTML 콘텐츠를 파싱하여 관련 정보를 수집.
도구 예시:
Beautiful Soup, Scrapy, Selenium.
[장점]
대규모 데이터 수집 가능: 컴퓨터 비전 연구(예: ImageNet)나 자연어 처리(NLP)에서 유용.
비용 효율성: 기존 데이터를 수집할 때 경제적인 옵션.
[단점]
윤리적, 법적 문제: 일부 웹사이트는 스크래핑을 금지하며, 위반 시 법적 문제가 발생할 수 있음.
데이터 품질: 스크래핑된 데이터는 종종 구조화되지 않고 노이즈가 많아 추가 정제 작업이 필요.
프라이버시 문제: 개인 데이터를 수집할 경우 익명화를 철저히 해야 함.
- 크라우드소싱 (Crowdsourcing)
[개념]
다수의 사람들에게 작업을 분배하여 데이터를 수집하거나 라벨링 작업 수행.
플랫폼 예시: Amazon Mechanical Turk.
[장점]
규모 확장성: 방대한 데이터를 빠르게 처리 가능.
다양성 확보: 다양한 문화적 배경과 언어 능력을 가진 사람들이 참여.
비용 효율성: 전통적인 데이터 수집 방식보다 경제적.
[단점]
품질 변동: 참여자 간 데이터 라벨링 품질이 일관되지 않을 수 있음.
윤리적 문제: 참여자의 프라이버시 보호와 데이터 사용 투명성 필요.
TinyML 한계: TinyML에 필요한 특화된 데이터(예: 특정 센서 데이터)를 얻기 어렵거나 비용이 많이 들 수 있음.
- 합성 데이터 (Synthetic Data)
[개념]
실제 관측 데이터 대신 알고리즘, 시뮬레이션, 또는 기타 기술을 사용해 생성한 데이터.
예: GAN(Generative Adversarial Networks)을 사용한 데이터 생성.
[장점]
현실 세계에서 데이터를 얻기 어려운 경우, 부족한 데이터를 보충.
민감한 데이터(예: 의료 데이터)를 대체하여 윤리적 문제를 완화.
[단점]
현실성 부족: 합성 데이터는 실제 데이터를 완벽히 대체할 수 없으며, 모델 성능에 부정적 영향을 미칠 수 있음.
생성 비용: 고품질 합성 데이터를 생성하려면 고도의 기술과 자원이 필요.
4 Data Storage
데이터 저장은 머신러닝 프로젝트에서 중요한 단계로, 수집된 데이터를 체계적으로 관리하고 효율적으로 활용할 수 있도록 돕습니다. 데이터 저장 방식은 프로젝트의 규모, 성격, 목표에 따라 적절히 선택되어야 하며, 올바른 저장 전략은 데이터 접근성, 확장성, 보안을 강화합니다.
5 Data Processing
데이터 처리는 원시 데이터를 정제하고 분석 가능한 형식으로 변환하는 과정으로, 머신러닝 프로젝트의 핵심 단계 중 하나입니다. 이 단계는 데이터의 품질을 높이고, 모델 학습의 정확성을 보장하며, 데이터 분석 및 결과 해석의 기반을 제공합니다.
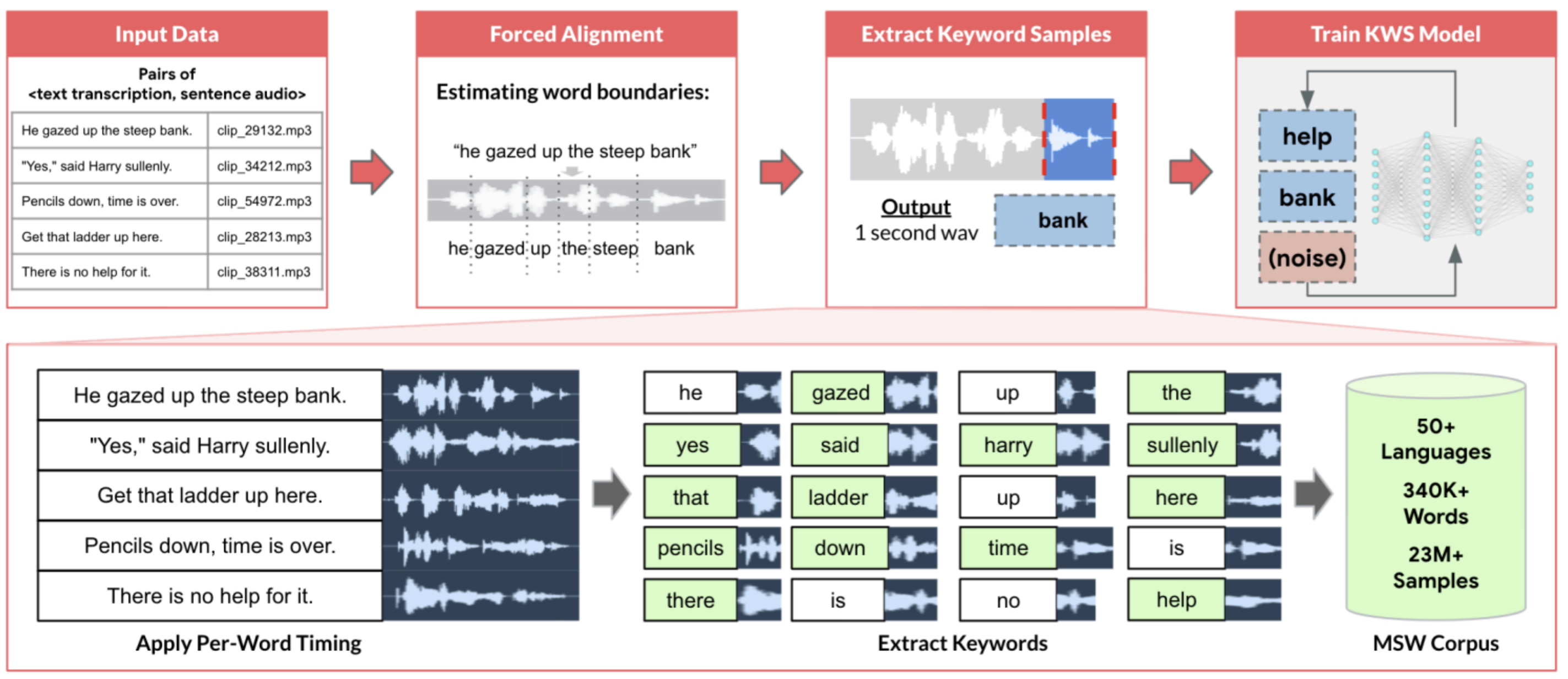
데이터 처리의 주요 단계
- 데이터 정제 (Data Cleaning)
-
개념:
- 데이터셋에서 오류, 중복, 누락 값을 제거하거나 수정하여 데이터의 품질을 높이는 작업. -
주요 활동:
- 결측값 처리: 평균값, 중앙값 대체 또는 삭제.
- 중복 제거: 중복된 데이터 레코드를 삭제.
- 이상치(outlier) 처리: 극단적인 값 식별 및 수정.
- 오류 수정: 잘못된 값 수정 (예: 잘못된 형식 또는 오타). -
중요성:
- 데이터 정제가 이루어지지 않으면 모델 학습에 부정적인 영향을 미칠 수 있음.
- 데이터 변환 (Data Transformation)
-
개념:
- 데이터를 모델 학습에 적합한 형식으로 변환하는 작업. -
주요 활동:
- 스케일링(scaling): 모든 데이터 값을 동일한 스케일로 조정 (예: Min-Max 스케일링, 표준화).
- 인코딩(encoding): 범주형 데이터를 수치형 데이터로 변환 (예: 원-핫 인코딩, 레이블 인코딩).
- 데이터 병합: 여러 데이터셋을 통합.
- 특성 생성(feature engineering): 새롭고 유용한 특성을 생성. -
중요성:
- 데이터 변환은 모델의 성능을 극대화하는 데 필수적.
- 데이터 샘플링 및 리샘플링 (Sampling and Resampling)
-
개념:
- 데이터의 일부를 선택하거나, 데이터를 균형 있게 다시 구성. -
주요 활동:
- 언더샘플링: 과다대표 클래스의 데이터 수를 줄임.
- 오버샘플링: 과소대표 클래스의 데이터 수를 늘림 (예: SMOTE).
- 데이터 분리: 학습(train), 검증(validation), 테스트(test) 데이터셋으로 분리. -
중요성:
- 모델이 데이터 편향 없이 학습하고, 테스트 단계에서 정확한 평가를 보장.
- 데이터 증강 (Data Augmentation)
-
개념:
- 데이터셋을 확장하기 위해 기존 데이터를 변형하여 새로운 샘플을 생성. -
예:
- 이미지 데이터: 회전, 반전, 크기 조정, 밝기 조정.
- 텍스트 데이터: 동의어 교체, 문장 재구성.
- 오디오 데이터: 잡음 추가, 시간 조정. -
중요성:
- 데이터셋 크기를 늘려 모델의 일반화 성능을 향상.
- 데이터 전처리 자동화 (Automated Data Preprocessing)
-
개념:
- 대규모 데이터셋에서 자동화 도구를 사용해 정제와 변환 작업을 수행. -
도구 예시:
- Python 라이브러리: Pandas, NumPy, Scikit-learn.
- 클라우드 서비스: AWS Glue, Google DataPrep. -
중요성:
- 대규모 데이터 작업 시 시간과 비용 절감.
6 Data Labeling
데이터 라벨링은 머신러닝 모델 학습을 위해 데이터에 의미 있는 태그를 부여하는 과정입니다. 라벨링된 데이터는 지도 학습(Supervised Learning)의 핵심으로, 모델이 패턴을 학습하고 정확한 예측을 생성할 수 있도록 도와줍니다.

데이터 라벨링의 주요 단계
- 라벨링 데이터의 정의
-
라벨의 의미 결정:
- 데이터를 분류하거나 예측하기 위한 기준과 범주를 정의.
- 예: 이미지 데이터에서 "고양이", "개" 등으로 분류하거나, 텍스트 데이터에서 "긍정", "부정" 감정 라벨 지정. -
목표 기반 라벨링:
- 프로젝트 목표에 따라 라벨의 종류와 세분화 수준 결정.
- 라벨링 방법
-
수동 라벨링 (Manual Labeling):
- 사람의 판단으로 데이터를 하나씩 라벨링.
- 장점: 높은 정확도, 복잡한 태스크에도 적용 가능.
- 단점: 시간과 비용이 많이 소요됨. -
반자동 라벨링 (Semi-Automated Labeling):
- 모델이나 알고리즘이 초안 라벨을 생성하고, 사람이 이를 검토 및 수정.
- 장점: 라벨링 속도 향상.
- 단점: 모델 초안의 품질에 따라 정확도 편차 발생. -
자동 라벨링 (Automated Labeling):
- 완전히 자동화된 도구와 알고리즘으로 라벨링.
- 장점: 대규모 데이터셋 처리 가능, 비용 효율적.
- 단점: 복잡하거나 정교한 라벨링 작업에는 부적합.
