Feature Pyramid Network
Feature Pyramid
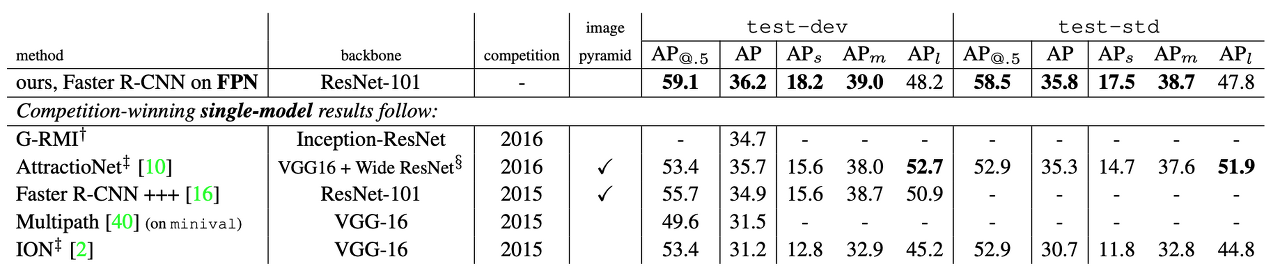
object detection 분야에서 풀리지 않았던 고질적인 난제는 작은 물체를 탐지해내기가 어렵다는 것입니다. 이를 위해서 이미지나 피쳐맵의 크기를 다양한 형태로 rescale하는 접근 방식이 있어왔습니다.
(a)는 입력 이미지 자체를 여러 크기로 resize 한 뒤, 각각의 이미지에서 물체를 탐지하는 기법입니다. 해당 기법은 입력 이미지 자체를 여러 크기로 복사하여 연산량이 큰 단점이 있습니다
(b)는 CNN 신경망을 통과하여 얻은 최종 단계의 피쳐맵으로 object detection을 수행하는 기법입니다. YOLO가 이러한 기법에 속하며 해당 기법은 신경망을 통과할 수록 이미지에 담겨져 있는 정보들이 추상화 되어 작은 물체들에 대한 정보가 사라진다는 문제가 있습니다.
(c)는 CNN 신경망을 통과하는 중간 과정에서 생성되는 피쳐맵들 각각에 object detection을 수행하는 기법입니다. SSD가 이러한 기법에 속하며 해당 기법은 작은 물체에 대한 정보를 살리면서 object detection을 수행할 수 있지만 상위 레이어에서 얻게되는 추상화 된 정보를 활용하지 못하는 단점이 있습니다.
(d)가 대망의 feature pyramid network에서 제안하는 방법입니다. 먼저 신경망을 통과하면서 단계별로 피쳐 맵들을 생성합니다. 그리고 가장 상위 레이어에서부터 거꾸로 내려오면서 피쳐를 합쳐준 뒤 object detection을 진행합니다. 이러한 방식을 통해서 상위 레이어의 추상화된 정보와 하위 레이어의 작은 물체들에 대한 정보를 동시에 살리면서 object detection을 수행할 수 있게 됩니다.
Feature Fusion
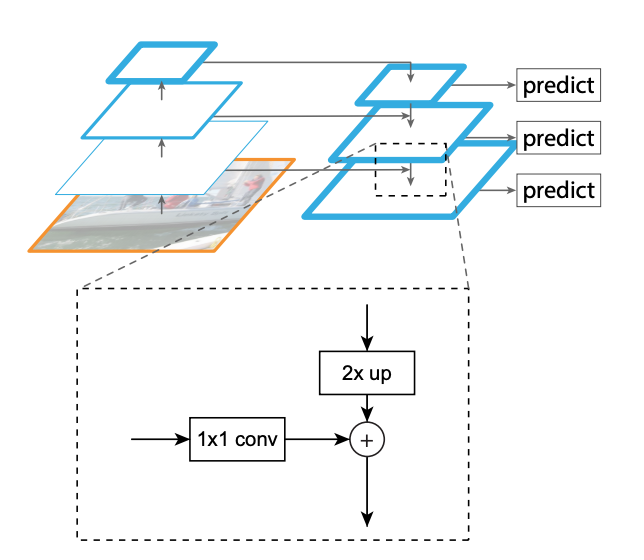
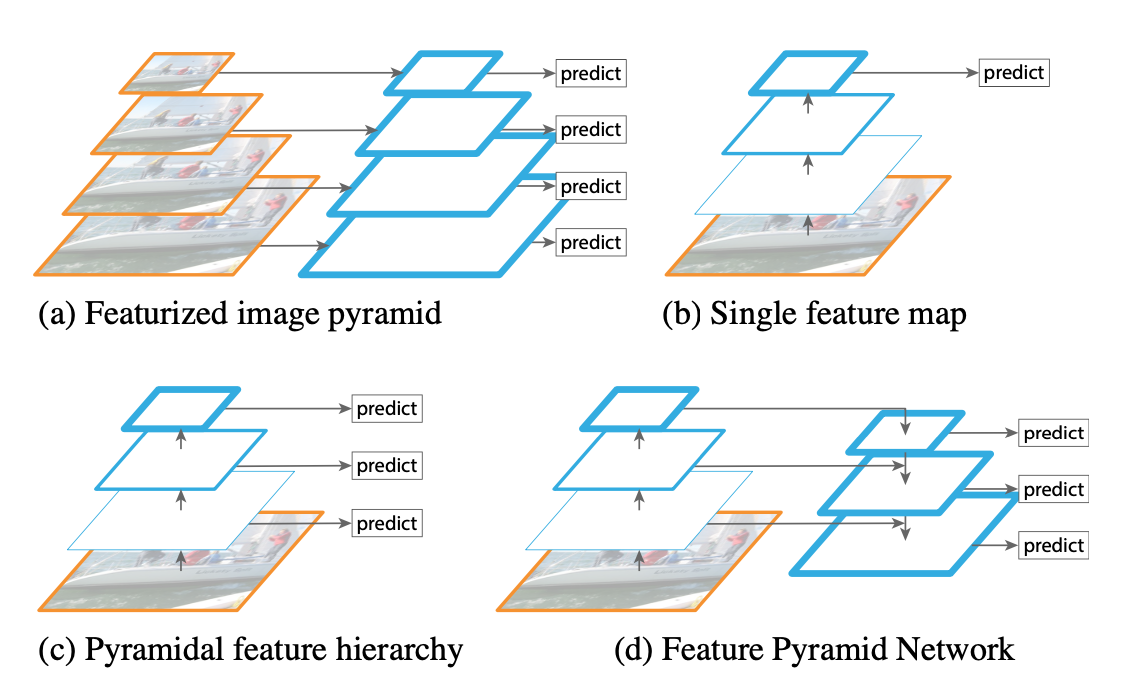
FPN이 어떻게 상위 피쳐맵과 하위 피쳐맵을 합쳐주는 지를 살펴보겠습니다. 기본적으로 FPN은 피쳐맵이 레이어를 통과하면서 해상도가 2배씩 작아진다고 가정하였습니다. (이는 EfficientNet 등 다양한 CNN 아키텍쳐들에서 보편적으로 나타나는 특징이기도 합니다.) 때문에 상위 피쳐맵과 하위 피쳐맵을 합쳐주기 위해서는 해상도를 맞춰주여야 했습니다. 저자들은 nearest neighbor upsampling 이라는 기법을 적용하여 상위 피쳐 맵의 해상도를 2배 키워주었는데, 그림으로 나타내면 아래와 같습니다.
upsampling에도 다양한 기법들이 있지만 저자들은 단순함을 위해 위 기법을 채택했다고 합니다. 다음으로 하위 피쳐맵에 1x1 컨볼루션을 수행하여 상위 피쳐맵과 동일한 체널수를 갖도록 합니다. 해상도와 체널 수를 모두 맞춰준 두 피쳐맵을 elementwise 덧셈을 수행하여 합쳐주며 그 결과로 나온 피쳐맵에 Object Detection 기법들을 적용하는 것입니다.
Feature Pyramid Network for RPN
저자들은 Feature Pyramid Network 기법을 기존 Object Detection 모델들에 적용하여 실제로 잘 작동하는 지를 확인해보고자 했습니다. 논문에서는 Faster R-CNN의 RPN과 Classifier에 적용하여 실험을 진행하였습니다. Faster RCNN의 RPN은 기존에는 아래와 같은 형태를 취했습니다.
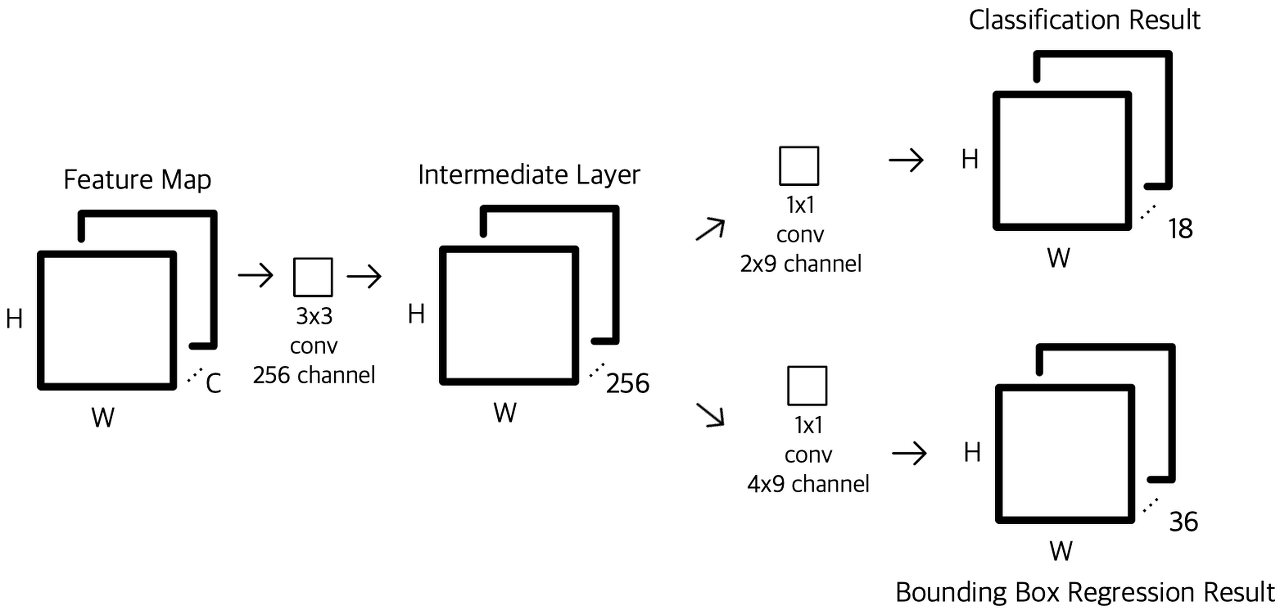
Faster RCNN에서의 RPN은 먼저 pretrained 된 VGG를 통과한 피쳐맵을 전달받습니다. 해당 피쳐맵에 3x3 컨볼루션을 적용하여 Intermediate Layer라는 피쳐맵을 생성합니다. 이를 각각 1x1 컨볼루션을 양갈래로 적용하여 각 엥커 박스가 object인지 여부와 bounding box regression을 수행해줍니다. RPN에 FPN 기법을 적용하면 아래와 같은 구조를 취합니다.
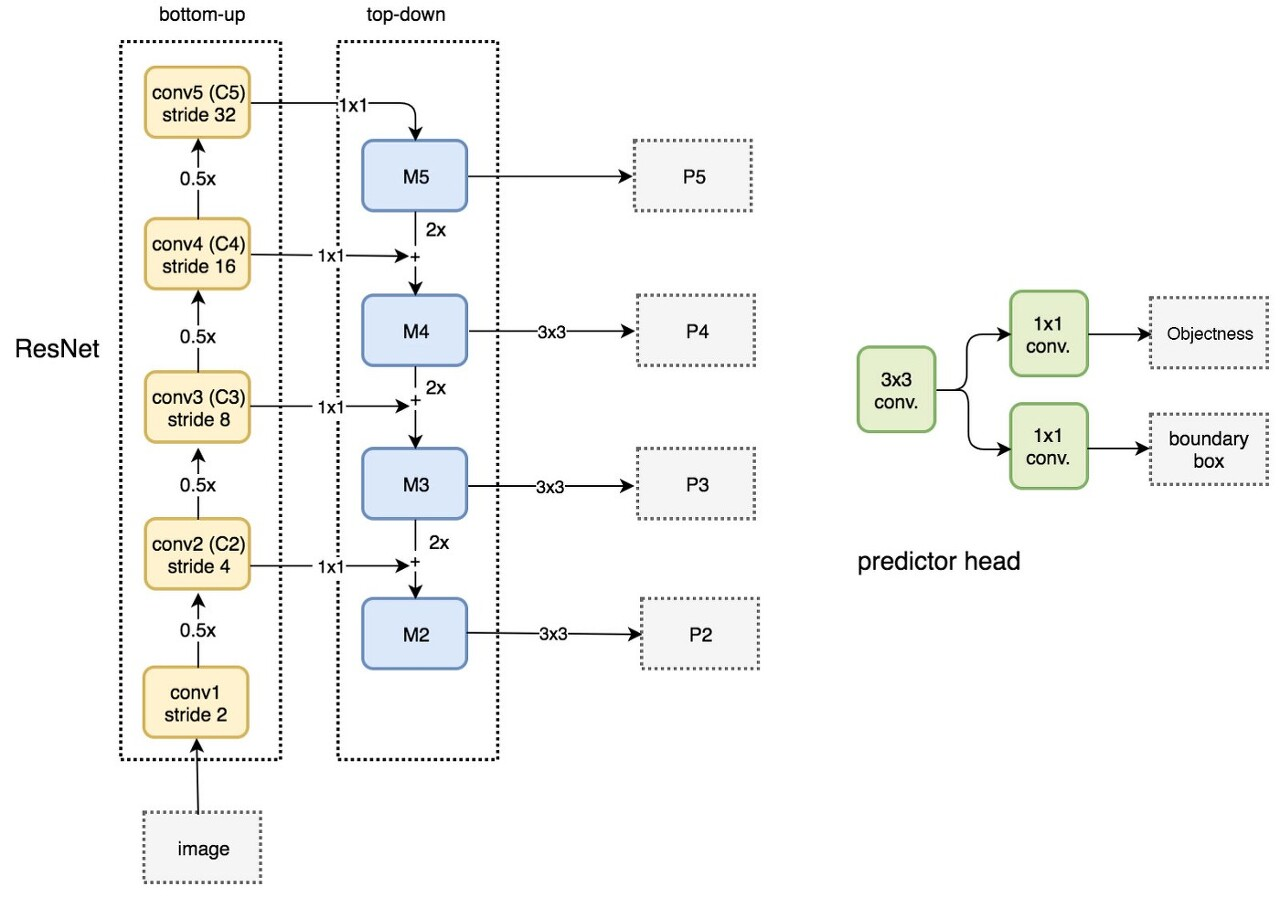
먼저 백 본 네트워크를 VGG에서 ResNet-50 혹은 ResNet-101로 변경합니다. (백 본 네트워크의 크기에 따라서 레이어의 개수가 살짝 달라질 수 있습니다.) 입력 이미지를 먼저 ResNet을 통과시키며 중간 피쳐맵들을 생성합니다. 그리고 상위 레이어부터 내려오면서 피쳐들을 합쳐주어 P5, P4, P3, P2를 생성합니다.
P5와 같이 상위 피쳐맵들의 합으로 생성된 피쳐맵은 크기가 큰 물체에 대한 정보를 담고 있을 것으로 예상 가능합니다. 그러므로 큰 앵커박스를 의미한다고 가정할 수 있습니다. 반면 P2는 작은 물체에 대한 정보를 담고 있을 것이므로 작은 앵커 박스를 나타낸다고 볼 수 있습니다. 논문에서는 하위 피쳐맵부터 순서대로 32x32, 64x64, 128x128, 256x256, 512x512 크기의 앵커 박스를 적용하였습니다.
기존의 RPN에서는 intermediate layer에 1x1 컨볼루션을 엥커 박스 수 만큼 채널 수를 취해서 계산하였습니다. 하지만 FPN을 적용한 RPN에서는 P5, .. P2가 각각 특정한 크기의 앵커 박스를 의미합니다. 이 피쳐맵에 predictor head로 표시된 네트워크를 적용해서 해당 엥커박스가 물체인지 여부에 대한 Classfication과 Bounding box regression을 구해주게 됩니다.
Feature Pyramid Networks for Fast R-CNN
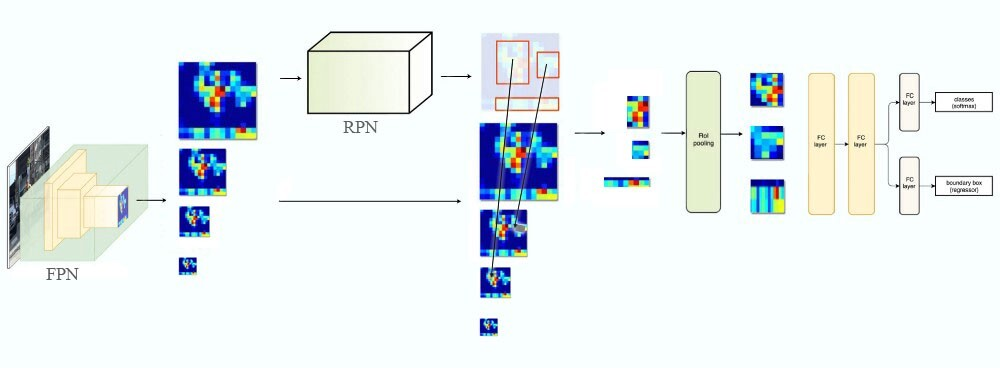
이제 Faster R-CNN에서 물체의 종류를 판별하는 부분입니다. 사실 이 부분은 Fast R-CNN의 구조를 그대로 계승하였는데요, 바로 앞서 구한 RoI를 Feature Map에 사상한 뒤, RoI Pooling을 거쳐서 Classfication을 진행합니다. 이 과정을 시각화 하면 아래와 같습니다.

기존의 구조에서는 입력 이미지를 pretrained model을 통과시켜서 얻은 피쳐맵에 RoI를 사상시켰습니다. 하지만 앞서서 FPN을 통해서 우리는 P2, ..., P5에 이르는 다양한 크기의 피쳐맵을 생성하였습니다. FPN을 적용한 RPN을 통해서 RoI를 얻어낼 수는 있었지만, 이 RoI를 어디에 사상시켜야 할 지가 애매해졌습니다.
이러한 문제를 해결하기 위해서 저자들은 RoI의 크기에 따라서 사상시킬 피쳐맵을 결정하는 수식을 제안했으며, 이는 아래와 같습니다.

여기서 k는 피쳐 맵의 번호입니다. 224란 크기는 pretrained model이 224x224 크기의 이미지를 학습한 것에서 따왔습니다. k0는 224x224 크기의 RoI가 들어왔을 때 몇 번째 피쳐맵에 사상시킬 것인지를 결정하는 수이며, 논문에서는 4로 설정되었습니다. 만약 512x512 크기의 RoI가 입력으로 들어왔다면 4+log2(2.28) = 5.11로 P5에 사상됩니다. 이를 시각화하면 아래와 같습니다.
Experiment
이와 같은 FPN을 적용한 Faster RCNN은 기존 모델들보다 높은 성능을 보여주게 됩니다.