이번 포스트에서는 Florence-2에 대해 알아보겠습니다. 이 모델은 복잡한 공간적 계층 구조와 의미론적 세분화를 다루는 능력을 통해 객체 감지, 이미지 캡션 생성은 물론 각 픽셀을 객체 또는 장면 범주로 분류하는 Semantic Segmentation, 특정 구문과 관련된 영역을 식별하는 instance segmentation, 객체가 있을 가능성이 높은 이미지 영역을 제안하는 region proposal과 같은 다양한 시각 작업을 수행할 수 있습니다.
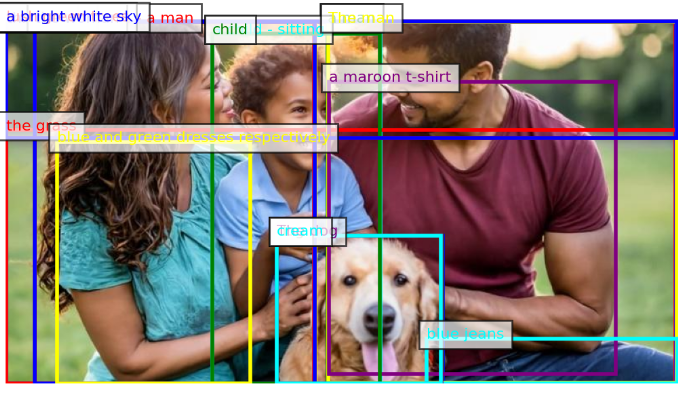
Florence-2 개요 및 특징
Florence-2의 핵심 아이디어는 텍스트 프롬프트를 태스크 지시로 받아 캡셔닝, 객체 탐지, 그라운딩(이미지 내 특정 영역을 텍스트 설명과 매핑), segmentation(이미지 내 모든 픽셀을 클래스 또는 객체로 분류하여 경계와 형태를 파악) 등 다양한 비전 태스크의 결과를 텍스트 형태로 생성하는 것 입니다. 이 모델은 1억 2천 6백만 개의 이미지와 54억 개의 주석으로 구성된 방대한 데이터셋인 FLD-5B를 사용하여 사전 학습되어, 이미지를 픽셀 수준에서부터 전체 이미지에 대한 설명에 이르기까지 다양한 작업을 0.23B/0.77B 단일 모델로 통합합니다.
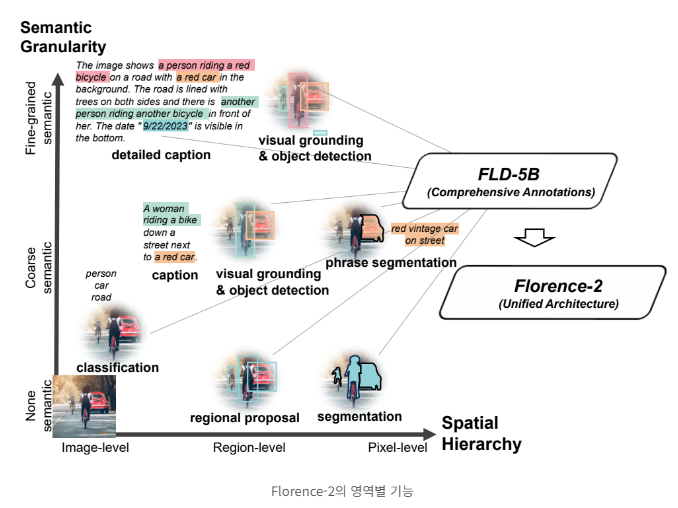
Florence는 다양한 컴퓨터 비전 작업을 수행할 수 있는 강력하고 다재다능한 모델로서, 대규모 데이터셋과 통합 아키텍처를 통해 이미지를 포괄적으로 이해할 수 있습니다.
주요 특징은 다음과 같습니다
- 통합된 프롬프트 기반 표현 : Florence-2는 다양한 비전 태스크를 위한 단일 통합 모델을 제공합니다. 텍스트 프롬프트를 통해 여러 태스크를 수행할 수 있어, 태스크별 특화 모델 없이도 다양한 비전 문제를 해결할 수 있습니다.
- 공간적 계층 구조와 의미론적 세분화 처리 : 이 모델은 이미지 수준의 개념부터 픽셀 수준의 세부 사항까지 다양한 스케일의 공간적 세부 정보를 인식할 수 있습니다. 또한 고수준 캡션부터 세부적인 설명까지 다양한 의미론적 세분화를 다룰 수 있습니다.
- 대규모 고품질 데이터셋 활용 : FLD-5B 라는 54억 개의 주석을 포함한 대규모 데이터셋을 사용하여 훈련되었습니다. 이 데이터셋은 자동화된 주석 생성과 모델 개선의 반복적 과정을 통해 구축되었습니다.
- 제로샷 및 파인튜닝 성능 : Florence-2는 다양한 태스크에서 뛰어난 제로샷 성능을 보여주며, 파인튜닝 후에는 더 큰 전문 모델들과 경쟁할 수 있는 성능을 보여줍니다.
구성요소 및 동작원리
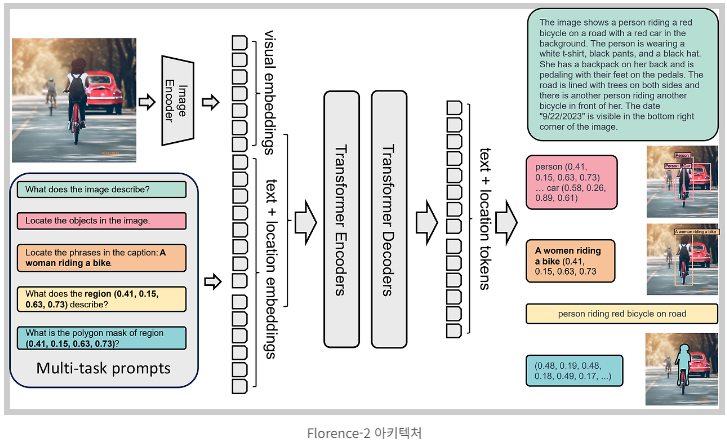
Florence-2 모델 아키텍처는 이미지 인코더와 표준 멀티모달리티 인코더-디코더로 구성되어 있습니다.
-
이미지 인코더 : 이미지를 입력받아 시각적 특징을 추출합니다.
-
텍스트 + 위치 임베딩 : 텍스트 입력을 받아 각 단어에 해당하는 임베딩을 생성하고, 이미지 내 위치 정보와 결합합니다.
-
트랜스포머 인코더 : 텍스트 + 위치 임베딩을 받아 더 풍부한 의미 정보를 추출합니다.
-
트랜스포머 디코더 : 이미지 인코더에서 추출된 시각적 특징과 트랜스포머 인코더에서 생성된 텍스트 정보를 결합하여 최종 출력을 생성합니다.
Florence-2는 이미지 캡션 생성, 객체 위치 파악, 영역 설명, 폴리곤 마스크 생성과 같은 다양한 작업을 수행할 수 있도록 다중 작업 프롬프트(Multi-task prompts)를 입력받을 수 있습니다.
-
"What does the image describe?" : 이미지 전체에 대한 설명을 요구합니다.
-
"Locate the objects in the image" : 이미지에서 특정 객체를 찾아 위치를 파악하도록 지시합니다.
-
"What does the region (0.41, 0.15, 0.63, 0.73) describe?" : 이미지 내 특정 영역에 대한 설명을 요구합니다.
-
"What is the polygon mask of region (0.41, 0.15, 0.63, 0.73)?" : 특정 영역을 나타내는 폴리곤 마스크 생성을 요청합니다.
성능 평가 결과
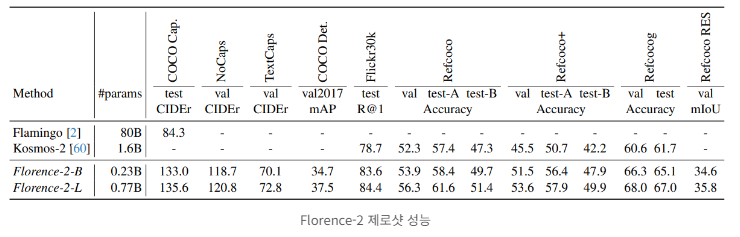
Florence-2 모델의 성능은 다양한 비전 태스크에서 평가되었으며, 제로샷 성능과 파인튜닝 후 성능 모두 뛰어난 결과를 보여주었습니다.
1. 제로샷 성능 : 모델이 학습하지 않은 상태에서 새로운 데이터난 작업에서 성능을 평가
- 캡셔닝 : COCO 데이터셋에서 뛰어난 제로샷 성능 달성
- 시각적 그라운딩 : Flickr30k 데이터셋에서 최고 성능 기록
- 참조 표현 이해 : RefCOCO, RefCOCO+, RefCOCOg 데이터셋에서 최고 성능 달성
이러한 제로샷 결과는 Florence-2가 사전 학습 과정에선 획득한 강력한 일반화 능력을 보여줍니다. 특별한 파인튜닝 없이도 다양한 비전 태스크에서 우수한 성능을 발휘할 수 있음을 의미합니다.
2. 파인튜닝 후 성능: 사전 훈련된 모델을 바탕으로 특정 작업에 맞춰 추가적으로 훈련한 후 해당 작업에서 모델이 보이는 성능
- 참조 표현 이해 : RefCOCO, RefCOCO+, RefCOCOg 데이터셋에서 새로운 최고 성능 기록
- 객체 탐지 및 인스턴스 segmentation : COCO 데이터셋에서 기존 모델들을 크게 상회하는 성능 달성
- Semantic segmentation : ADE20K 데이터셋에서 성능 향상 기록
Florence-2는 파인튜닝 후에도 더 큰 모델들과 경쟁할 수 있다는 성능을 보여주었습니다. 특히 컴팩트한 크기임에도 불구하고 우수한 성능을 달성했다는 점이 주목할 만합니다.
3. 계산 효율성
Florence-2는 파라미터 수가 0.23B/0.77B로 기존의 거대 규모 비전 모델들에 비해 상대적으로 작은 모델임에도 불구하고 우수한 성능을 보여주었습니다. 모델의 효율적인 설계를 통해 학습 효율성이 4배 향상되었다는 점은 실제 응용에 있어 큰 장점이 될 수 있습니다.
4. 다양한 일반화 능력
Florence-2는 이미지 분류, 객체 탐지, 세그멘테이션, 캡셔닝, 시각적 질문 응답 등 다양한 비전 태스크에서 고르게 우수한 성능을 보여주었습니다. 이는 모델이 획득한 시각 표현이 매우 범용적이고 일반화 능력이 뛰어남을 의미합니다.
