Attention 메커니즘 진화 비교
전체 계보
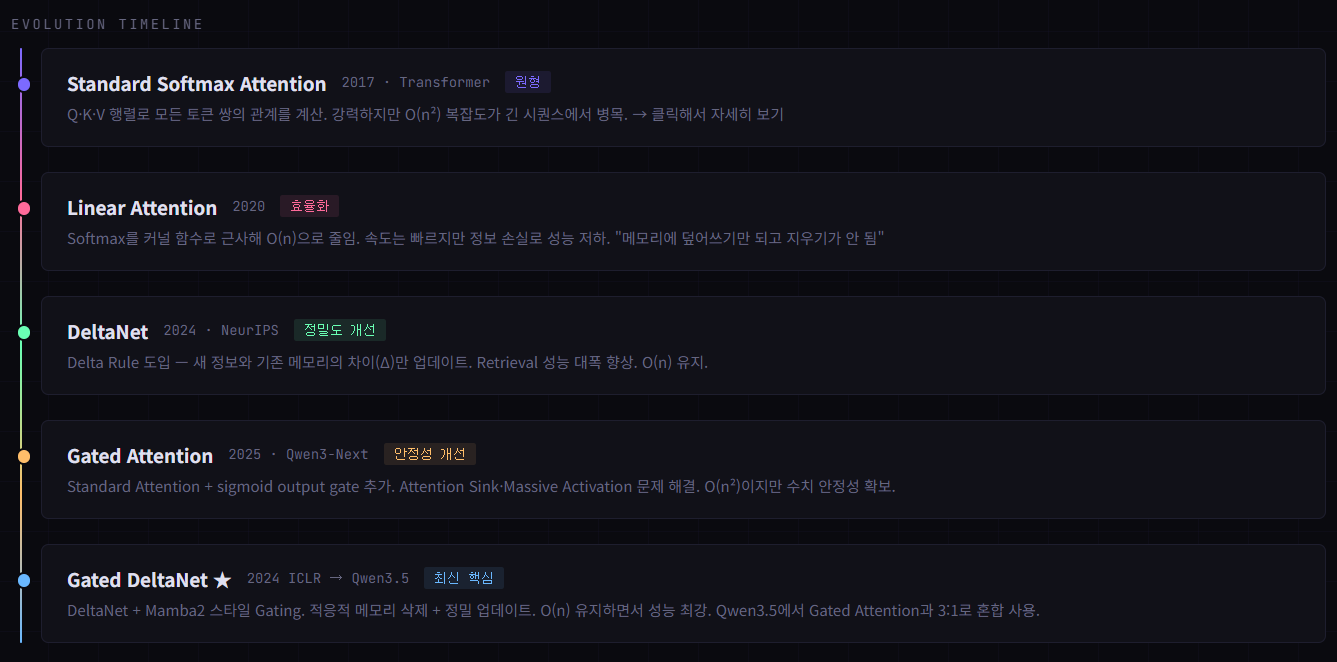
Standard Attention → Gated DeltaNet 까지 변화를 정리해 보았다
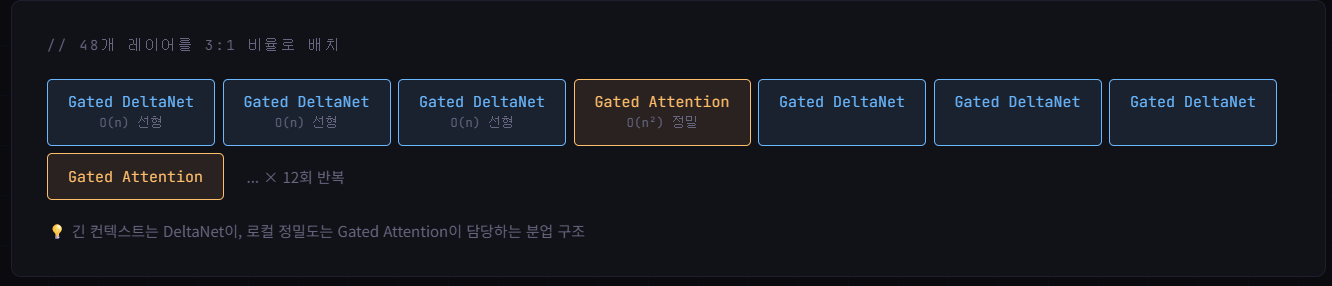
Qwen3.5 Hybrid 구조
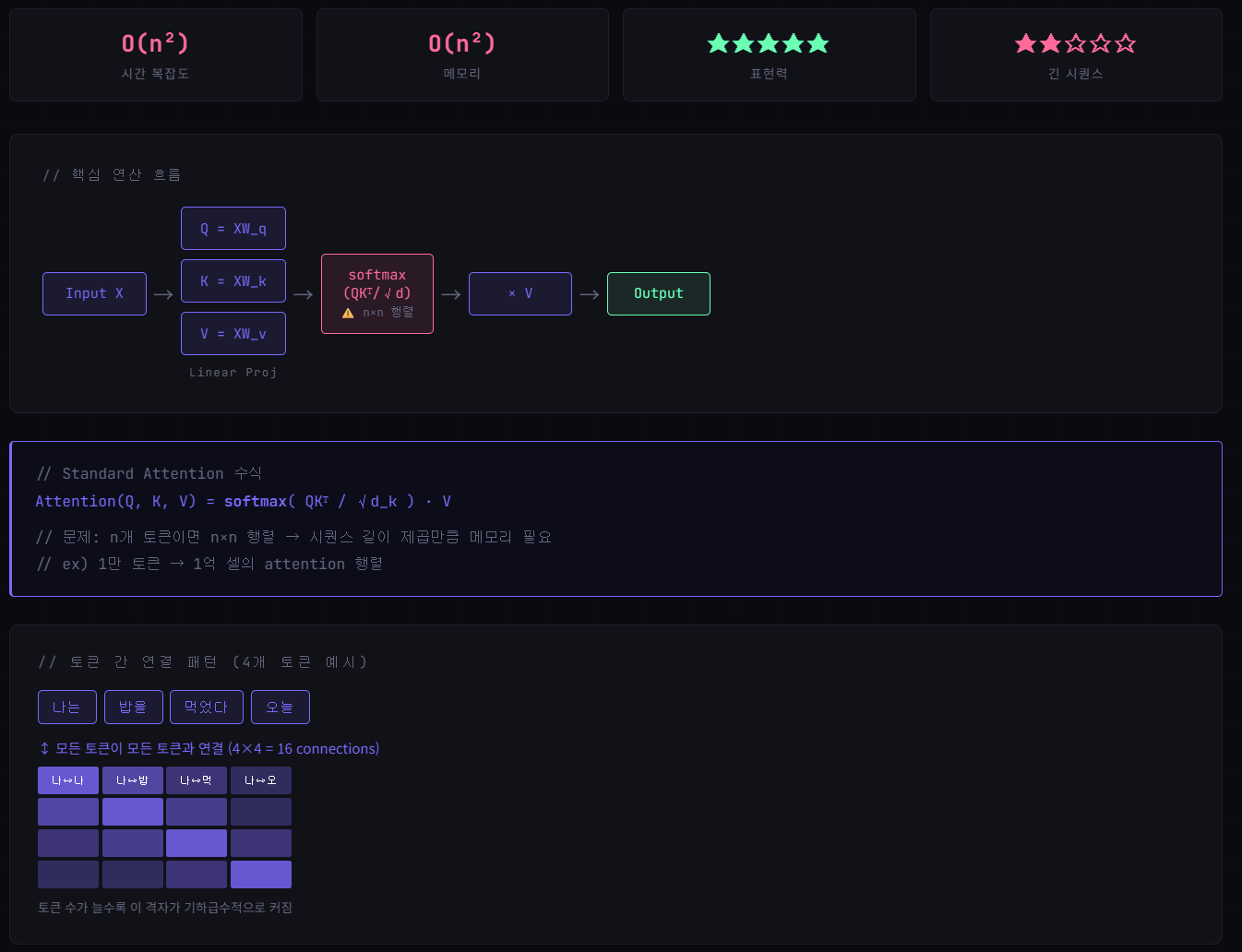
01 - Standard Softmax Attention
Transformer의 원형. 모든 토큰이 서로를 "바라보는" 완전 연결 구조. 강력하지만 비쌈.
-
강점
모든 위치 간 직접 연결 → 장거리 의존성 완벽 포착. 표현력 최강. -
약점
O(n²) 복잡도. 32k 토큰만 돼도 메모리 폭발. 긴 문서·코드에 한계.
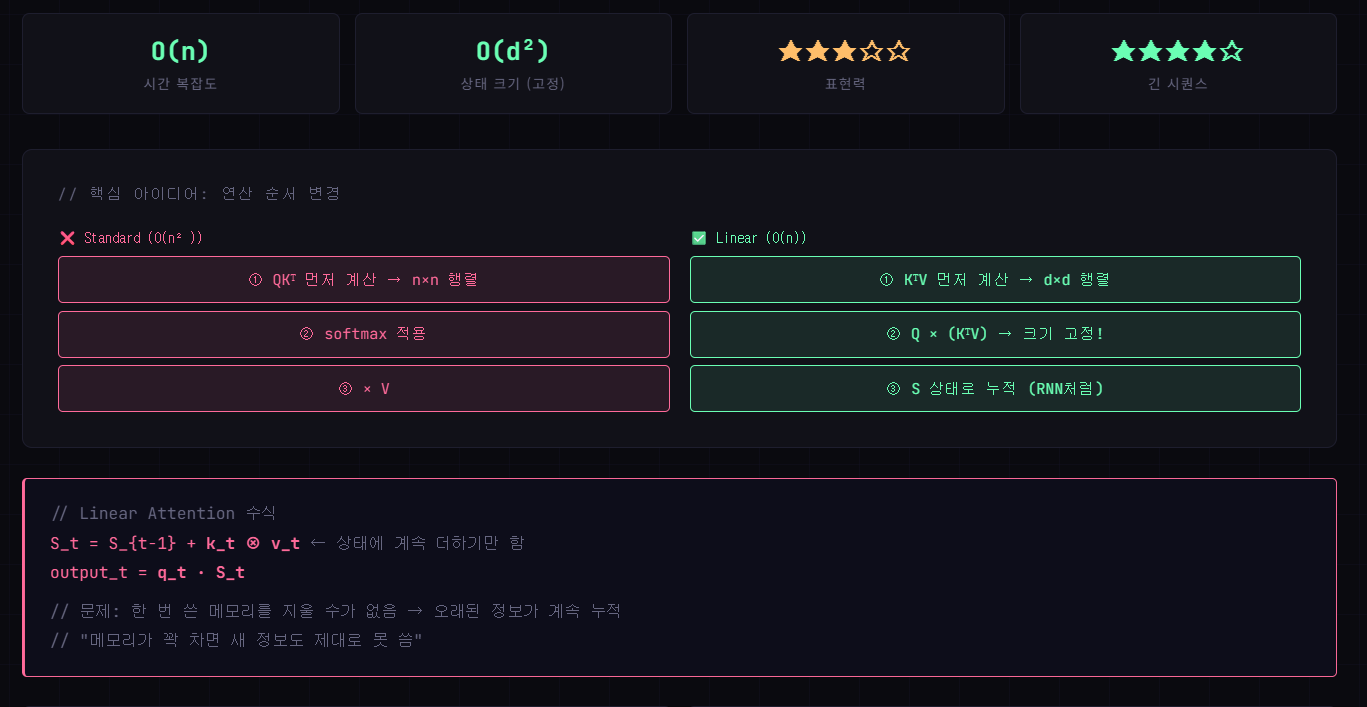
02 - Linear Attention
Softmax를 커널 함수 φ(·)로 근사해 연산 순서를 바꿈으로써 O(n²)을 O(n)으로 해결.
-
강점
O(n) 선형 복잡도. 어떤 길이의 시퀀스도 고정 크기 상태(S)로 처리 가능. -
약점
메모리 삭제 불가 → 정보 누적으로 "오래된 잡음"이 쌓임. Retrieval 성능 저하.
03 - DeltaNet
Linear Attention의 "지우기 불가" 문제를 Delta Rule로 해결. 차이(Δ)만큼 정밀하게 업데이트.
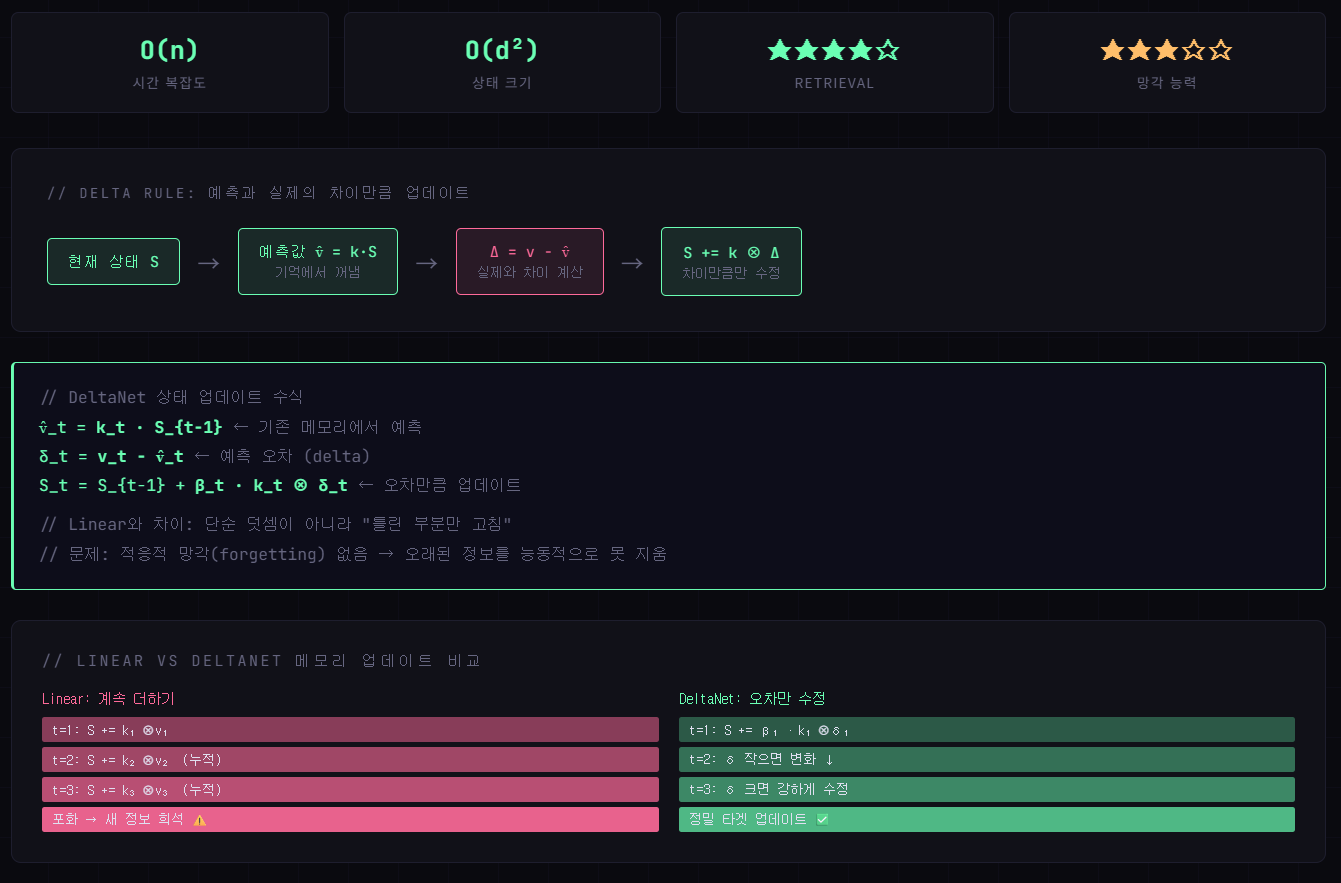
-
강점
예측 오차(Δ)만 업데이트 → 이미 잘 기억된 내용은 건드리지 않음. Retrieval 성능 대폭 향상. -
약점
능동적 망각(forgetting) 없음. 불필요한 오래된 정보를 스스로 지우지 못함.
04 - Gated Attention
Standard Attention에 sigmoid output gate를 추가. Qwen3-Next에서 채택. 수치 안정성 개선.
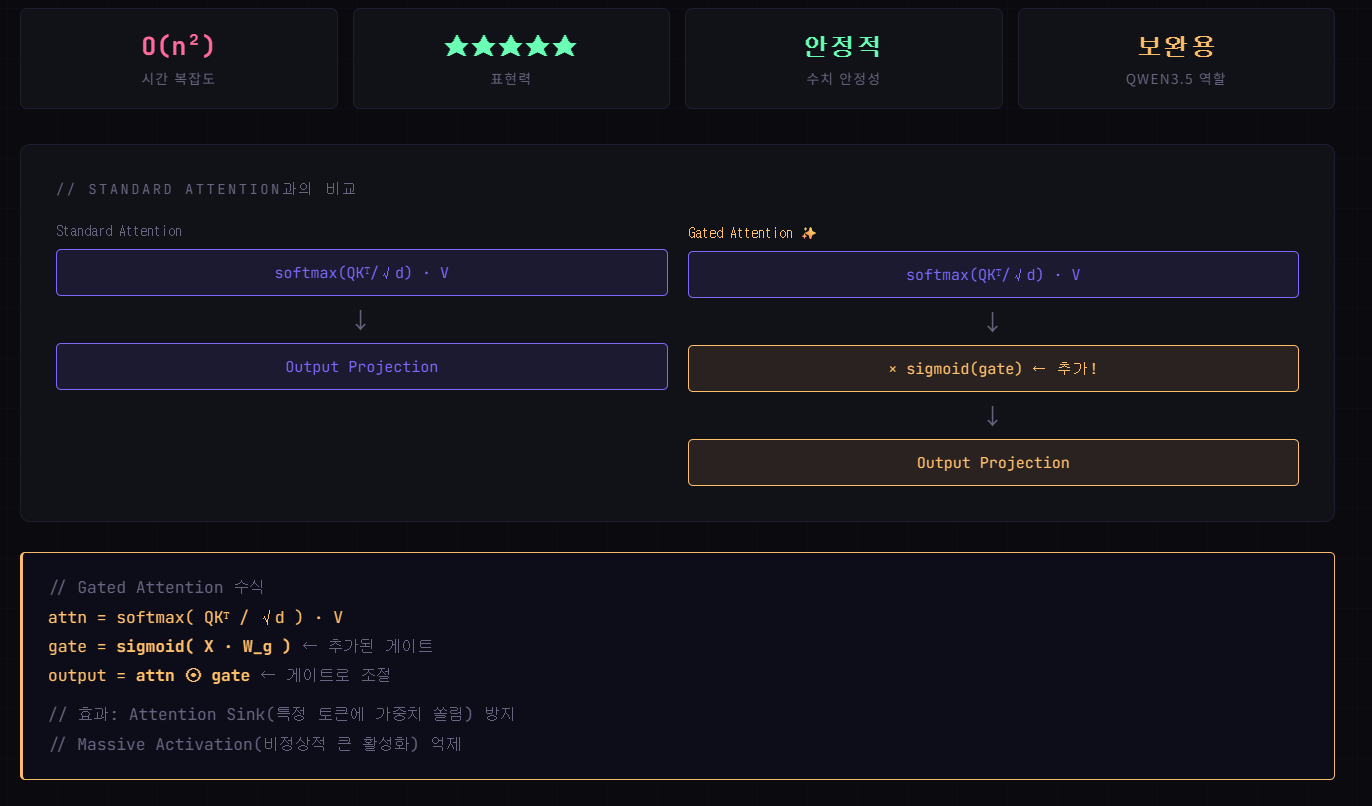
-
강점
수치 안정성 확보. 로컬 문맥 정밀 포착. Standard Attention의 표현력 그대로 유지. -
Qwen3.5에서 역할
전체 레이어의 25%(3:1 비율 중 1). DeltaNet이 못하는 로컬 정밀 어텐션 담당.
05 - Gated DeltaNet ★ (ICLR 2025)
DeltaNet + Mamba2 스타일 gating. O(n) 유지하면서 능동적 망각까지 가능. Qwen3.5의 핵심.
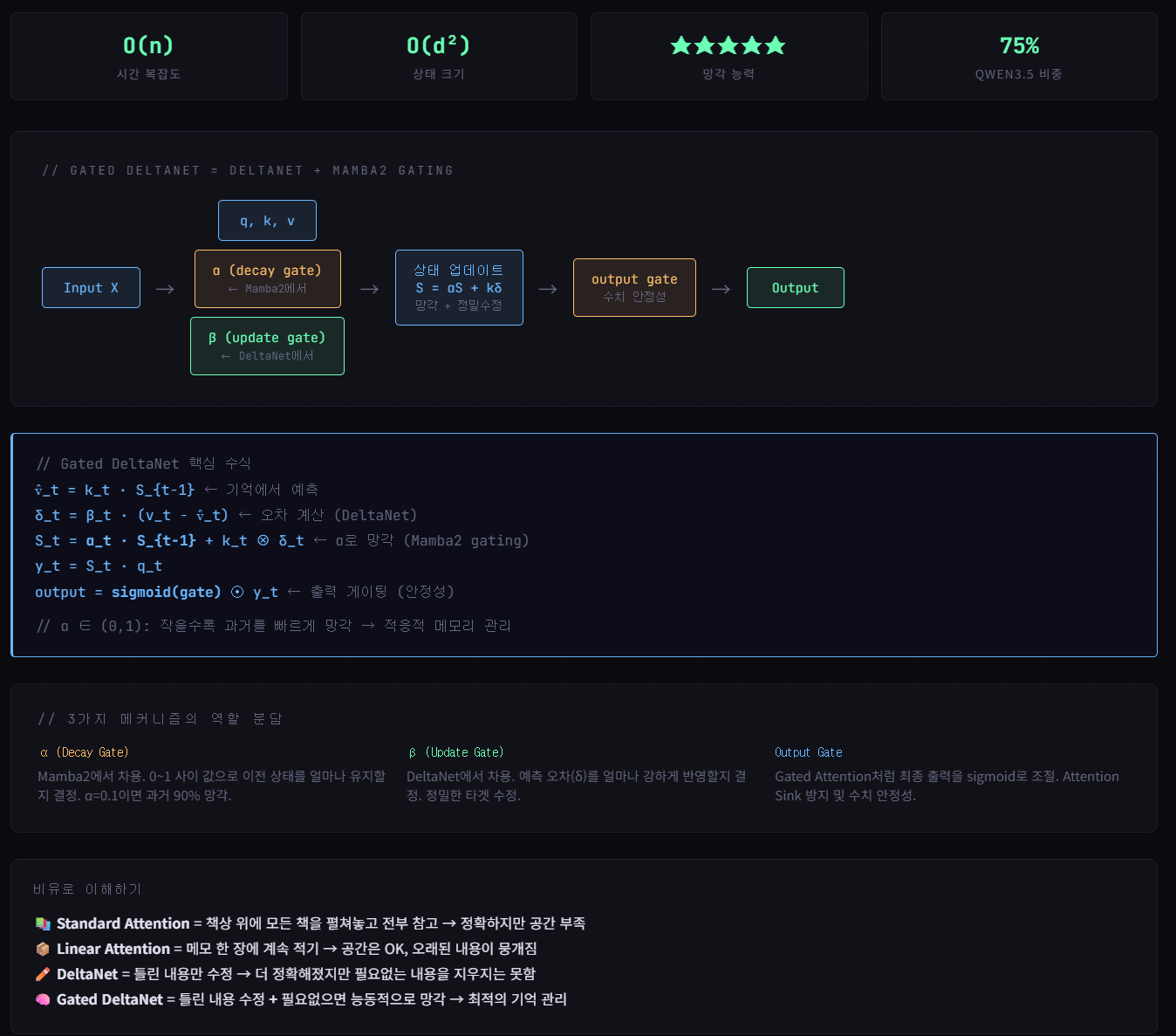
-
강점 종합
O(n) 선형 복잡도 + 능동적 망각 + 정밀 업데이트 + 수치 안정성. 모든 장점의 집합. -
남은 약점
로컬 토큰 간 세밀한 비교는 여전히 Full Attention보다 약함 → Gated Attention과 혼합 사용으로 보완.
