Bellman Equation for MRP
MRP ⟨S,P,R,γ⟩에서 value function V(st)에 대한 Bellman equation은 다음과 같이 정의된다.
V(s)=E[Gt∣st=s]=E[Rt+1+γRt+2+γ2Rt+3+⋯∣st=s]=E[Rt+1+γk=0∑∞γkRt+k+2∣st=s]=E[Rt+1+γV(St+1)∣st=s]=st+1∑p(st+1∣st)[R(st,st+1)+γV(st+1)]
즉, 현재 state st에서의 value function은 미래 state st+1의 value function으로 표현할 수 있다 (one-step look ahead).
V(s)=Rs+γs′∈S∑Pss′V(s′)
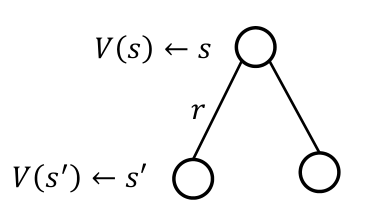
V=R+γPV
⎣⎢⎢⎡V(s1)⋮V(sn)⎦⎥⎥⎤=⎣⎢⎢⎡R1⋮Rn⎦⎥⎥⎤+γ⎣⎢⎢⎡P11⋮Pn1⋯⋱⋯P1n⋮Pnn⎦⎥⎥⎤⎣⎢⎢⎡V(s1)⋮V(sn)⎦⎥⎥⎤
위 식은 linear equation이므로, 다음과 같이 solution을 구할 수 있다.
V=(I−γP)−1R
일반적으로 inverse matrix를 explicit하게 계산하는 경우, computation cost (O(n3) for n states)가 너무 높으므로 DP와 같은 다른 방법을 사용한다.
Bellman Expectation Equation for MDP
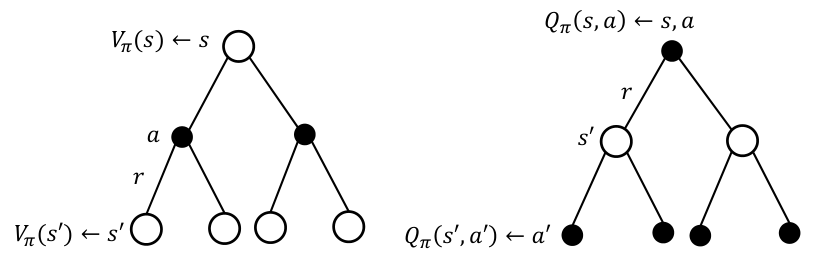
위 방법과 유사하게, MDP에서 state-value function Vπ(s)와 action-value function Qπ(s,a)에 대한 Bellman expectation equation을 다음과 같이 얻을 수 있다.
Vπ(s)=Eπ[Rt+1+γVπ(St+1)∣St=s]
Qπ(s,a)=Eπ[Rt+1+γQπ(St+1,At+1)∣St=s,At=a]
Bellman Equation for Vπ and Qπ
Bellman expectation equation을 Vπ와 Qπ의 관계로써 나타낼 수 있다.
Vπ(s)=a∈A∑π(a∣s)Qπ(s,a)
Qπ(s,a)=Rsa+γs′∈S∑Pss′aVπ(s′)
위 식을 이용하면, 아래와 같은 식을 얻는다.
Vπ(s)=a∈A∑π(a∣s)(Rsa+γs′∈S∑Pss′aVπ(s′))
Qπ(s,a)=Rsa+γs′∈S∑Pss′a(a′∈A∑π(a′∣s′)Qπ(s′,a′))
Vπ=Rπ+γPπVπ
⎣⎢⎢⎡Vπ(s1)⋮Vπ(sn)⎦⎥⎥⎤=⎣⎢⎢⎡R1π⋮Rnπ⎦⎥⎥⎤+γ⎣⎢⎢⎡P11π⋮Pn1π⋯⋱⋯P1nπ⋮Pnnπ⎦⎥⎥⎤⎣⎢⎢⎡Vπ(s1)⋮Vπ(sn)⎦⎥⎥⎤
위 식 역시 다음과 같이 solution을 얻을 수 있다.
Vπ=(I−γPπ)−1Rπ
Bellman Optimality Equation
Optimal Value Function
Optimal state-value function V∗(s)는 모든 policy들을 고려했을 때, 가장 높은 state-value를 말한다.
V∗(s)=πmaxVπ(s)
Optimal action-value function Q∗(s,a) 역시 동일하게 정의된다.
Q∗(s,a)=πmaxQπ(s,a)
만약 모든 state s∈S에 대해, Vπ1(s)≥Vπ2(s)인 경우, π1≥π2라고 표현하며, π1이 π2보다 더 나은 (better) policy라고 말한다.
만약 모든 policy에 대해 더 나은 policy π∗가 있다면, 이를 optimal policy라고 한다.
Theorem
- Optimal policy π∗는 항상 존재한다.
- Optimal policy π∗를 통해 계산된 state-value Vπ∗(s)와 Qπ∗(s,a)는 각각 optimal state-value 및 action-value 이다.
즉, Vπ∗(s)=V∗(s), Qπ∗(s,a)=Q∗(s,a).
Finding an Optimal Policy
만약 optimal action-value function Q∗(s,a)를 안다면, optimal policy를 다음과 같이 바로 얻을 수 있다.
π∗(a∣s)={10if a=arga∈AmaxQ∗(s,a)otherwise
즉, Q∗(s,a)가 가장 큰 action을 고르는 것이 optimal policy가 된다.
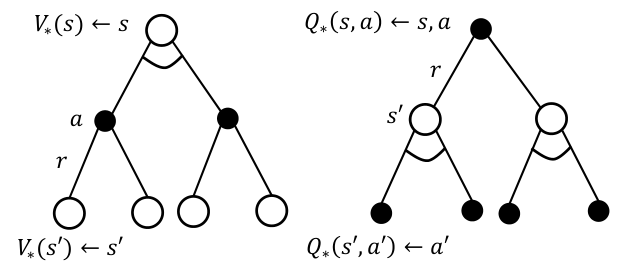
Bellman Optimality Equation for V∗(s) and Q∗(s,a)
Bellman optimality equation은 V∗(s)와 Q∗(s,a)에 대한 iterative equation을 제시하며, 이를 풀어냄으로써 optimal value function 및 optimal policy를 얻을 수 있다.
앞서 Bellman expectation equation과 마찬가지로 V∗(s)와 Q∗(s,a) 관계를 다음과 같이 표현할 수 있다.
V∗(s)=a∈AmaxQ∗(s,a)
Q∗(s,a)=Rsa+γs′∈S∑Pss′aV∗(s′)
위 식을 이용하면, 다음 Bellman optimality equation을 얻을 수 있다.
Vπ(s)=a∈Amax(Rsa+γs′∈S∑Pss′aV∗(s′))
Qπ(s,a)=Rsa+γs′∈S∑Pss′aa′∈AmaxQ∗(s′,a′)
Bellman optimality equation은 non-linear 하므로 단순한 matrix 연산으로 solution을 구할 수는 없다. 따라서, iterative alogirthm을 통해 solution을 구하게 된다. 자세한 방법에 대해서는 다음 post에서 다룰 예정이다.
