Introduction to RL
1.Introduction to Reinforcement Learning
Reinforcement learning (RL, 강화학습) 이란, agent가 환경과의 상호작용을 통해 목표를 달성하는 방법을 배우는 학습 방법을 말한다. 일반적으로 사람이 무언가를 배울 때, 여러번 시행착오를 통해 목표를 달성하게 되는데 이를 모방한 학습 방법으로
2.Markov Decision Process
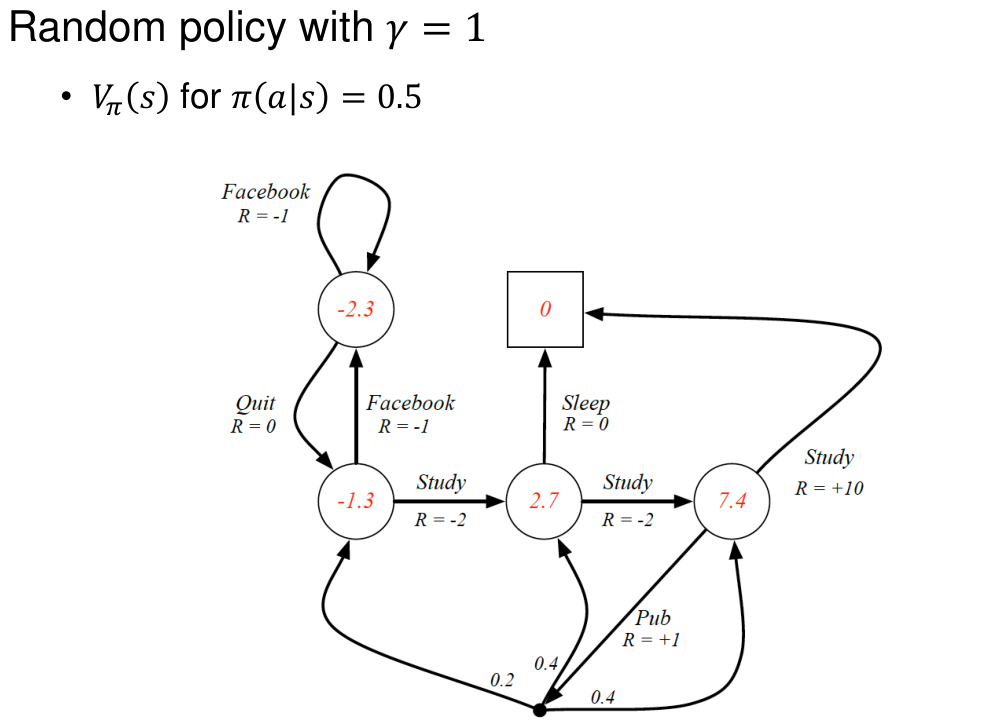
Markov process란, Markov property를 만족하는 random variable의 sequence로, $\\langle S,P \\rangle$로 나타낸다.State의 집합: $S$Transition probability matrix (model):
3.Bellman Equation and Optimality
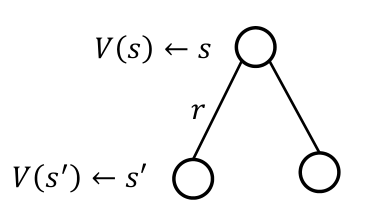
참고: Markov Decision Process (MDP)MRP $\\langle S,P,R,\\gamma \\rangle$에서 value function $V(s_t)$에 대한 Bellman equation은 다음과 같이 정의된다. $$\\begin{aligned}
4.Solving MDP
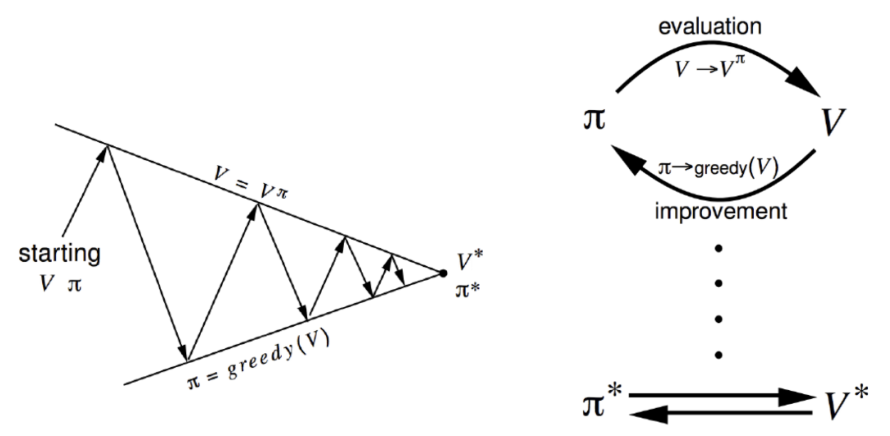
참고MDPBellman Equation and OptimalityMDP를 푼다는 것은 optimal policy $\\pi\_\\ast$를 구한다는 것과 동일하며, 이는 결국 Bellman optimality equation를 푸는 것과 동일하다. 여기서는 non-li
5.Model-free Prediction
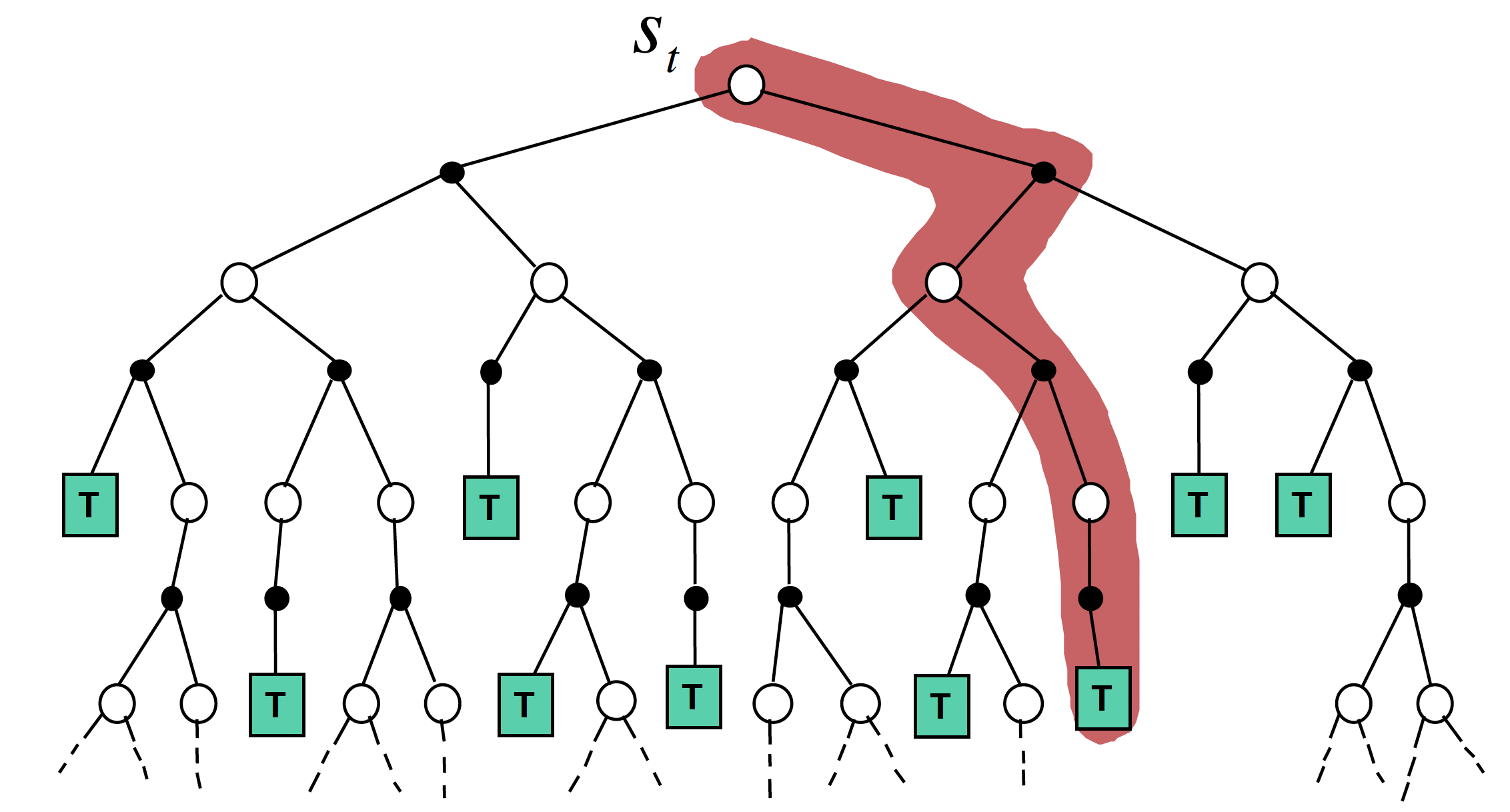
참고: Monte Carlo Method이전 post 'Solving MDP'를 통해 우리가 MDP를 알고 있는 경우, DP를 이용한 prediction 및 control이 가능하다는 것을 확인했다. 하지만, 우리가 실제 마주하는 문제들의 경우 MDP에 대해서 알 수
6.Model-free Control
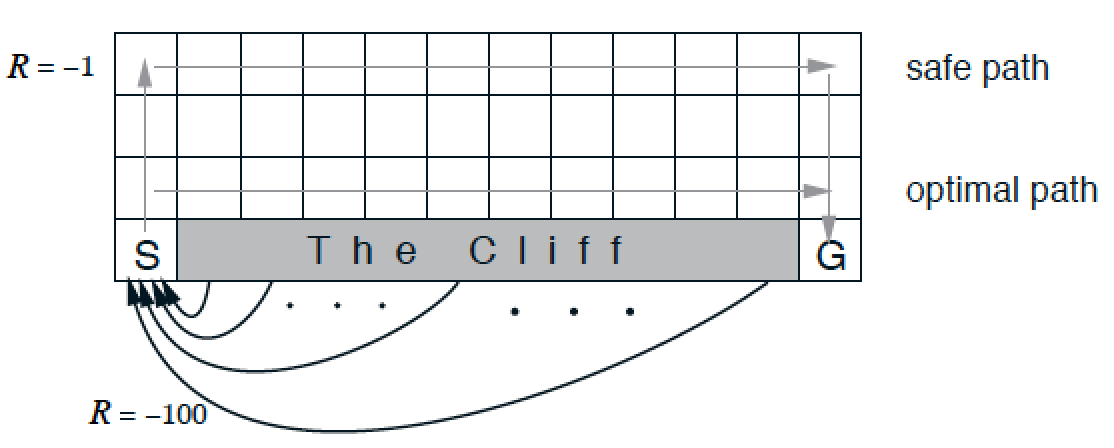
참고: Model-free PredictionModel-free control이란 환경이 주어져 있지 않거나, 또는 환경을 알 수 있으나 다루기에 너무 큰 상황(예. Robot walking 등)에서 optimal policy를 찾기 위한 방법을 말한다.Model-fr
7.Deep Q-Learning
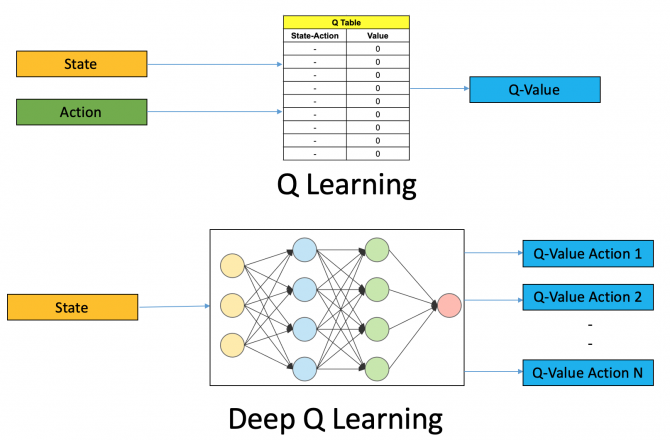
참고: Model-free ControlSARSA와 Q-learning과 같은 model-free prediction 기법은 model의 size가 작은 경우에는 비교적 잘 동작한다. 하지만, 만약 바둑과 같이 state-action pair가 셀수없이 많은 문제에는
8.Monte-Carlo Policy Gradient

참고: Deep Q-learningDeep Q-learning을 생각해보자. 여기서는 value와 action-value 값을 어떤 parameter $\\theta$를 갖는 함수로 모델링하였다.$$v\\theta(s) \\approx v^\\pi(s), \\quad
9.Actor-Critic Policy Gradient
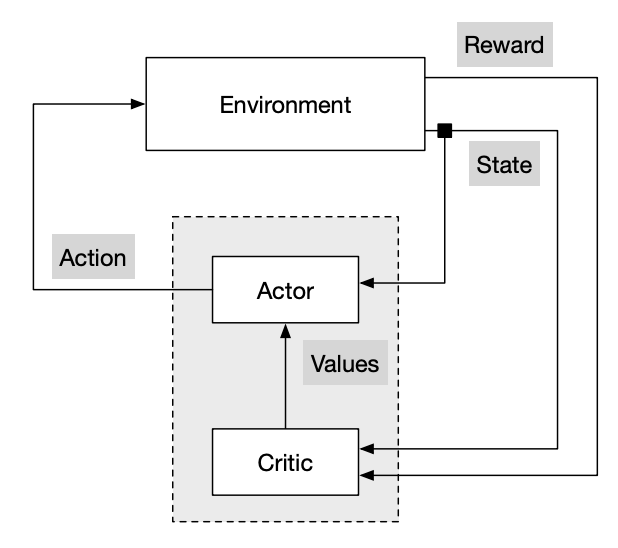
참고: Monte-Carlo Policy GradientMonte-Carlo policy gradient, 또는 REINFORCEMENT 알고리즘의 경우 variance가 무척 크다는 단점이 있다. 즉, 정밀한 estimation을 위해서는 아주 많은 computing
10.Proximal Policy Optimization

최근 가장 많이 사용되는 policy-based RL 알고리즘으로는 proximal policy optimization (PPO)이 있다. PPO는 trust region policy optimization (TRPO) 알고리즘으로부터 유도되었기에 PPO를 설명하기 전