Monte Carlo Method
몬테카를로 방법 (Monte Carlo Method)이란, 어떤 값 (또는 함수값)을 근사적(approximation)으로 계산하는데 있어 확률분포로부터 생성한 무작위 샘플(표본)들을 이용하는 방법이다.
이를 위해 큰 수의 법칙 (Law of large number, LLN)를 이용한다.
- LLN: X1,⋯,Xn∼i.i.d.f에 대하여
Xˉn=n1i=1∑nXi→pE(X1)
우리가 구하고자 하는 값을 θ라고 할 때, θ를 어떤 확률변수의 기대값으로 표현할 수 있다고 하자. 즉, θ=E(h(X)),X∼f.
만약 X1,⋯,Xn가 f로부터 생성한 무작위 샘플(표본)이라면, LLN에 의해 다음이 성립한다.
n1i=1∑nh(Xi)→pE(h(X))=θ
따라서, 몬테카를로 방법을 쓰기 위해서는 주어진 확률분포로부터 무작위 샘플을 생성하는 (난수생성) 알고리즘이 필요하다.
대부분의 알려진 확률분포들은 무작위 샘플을 생성하는 알고리즘들이 연구되어, R, Python 등에서 쉽게 사용할 수 있다.
Sampling Methods
Inverse CDF
Inverse CDF 샘플링 방법은 Probability Integral Transform (PIT)를 이용한 방법이다.
- PIT: 연속 확률 변수 X의 CDF를 FX라고 할 때, FX(X)는 Unif(0,1)을 따른다.
만약 FX(X)∼U,U는 (0,1)에서의 균일분포 (Unif(0,1))이면 다음이 성립한다.
X∼FX−1(U)=inf{x:F(x)≥U}
즉, U1,⋯,Uk를 (Unif(0,1))에서 생성하면, X1=F−1(U1), ⋯, Xk=F−1(Uk)는 F(x) (또는 f(x))를 따르는 랜덤 샘플이 된다.
만약 F−1(u)를 구하기가 어려운 경우에는 다음과 같은 방법을 따른다.
-
f(x)의 support 내의 숫자열 x1,⋯,xm을 적당히 찾아 ui=F(xi)를 구한다.
- f의 support = {x∣f(x)>0}
-
U∼Unif(0,1)인 U를 생성하여 ui≤U≤uj를 만족하는 가장 가까운 ui,uj에 대하여 다음의 X를 구한다.
X=uj−uiuj−Uxi+uj−uiU−uixj
- 위의 X는 (xi,F(xi)),(xj,F(xj))를 linear interpolation 한 값이다.
Example of Inverse CDF
f(x)=21x, 0<x<2 인 확률밀도함수를 갖는 확률변수를 무작위 생성한다고 하자.
F(x)=∫0xf(y)dy=41x2, 0<x<2 이므로 F−1(u)=4u=2u, 0<u<1 이 된다.
따라서 U1,⋯,Uk∼Unif(0,1) 분포로부터 생성한 샘플이라면, X1=2U1,⋯,Xk=2Uk는 주어진 f(x)에서 생성된 샘플이 된다.
Rejection Sampling
확률분포 f를 따르는 X를 생성하고자 한다: X∼f.
Rejection Sampling은 다음과 같은 순서로 진행된다.
-
f보다 난수생성이 쉽고 다음을 만족하는 확률분포 g를 찾는다.
βf(x)≤g(x),0<β<1
- g(x)/β=e(x)를 f(x)의 upper envelop이라고 한다.
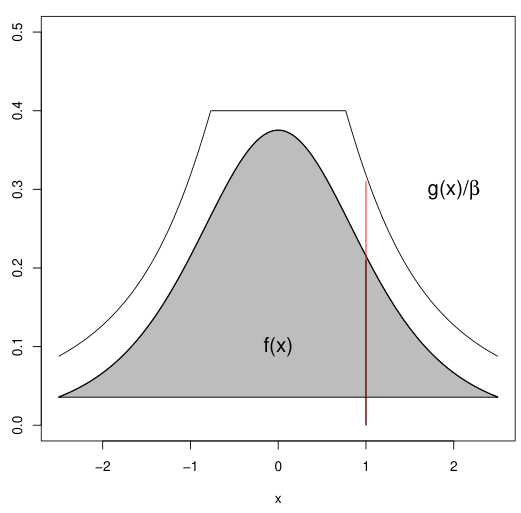
-
g로부터 X를 생성한다.
-
Unif(0,1)으로부터 U를 생성한다.
-
만약 Ug(X)≤βf(X) (또는 U≤f(X)/e(X))를 만족하면 X를 f로부터 생성된 난수로 받아들인다 (accept). 아니라면 (reject), 1번으로 돌아간다.
-
위 과정을 원하는 크기의 샘플을 얻을때까지 반복한다.
Example of Rejection Sampling
Inverse CDF방법에서의 예시와 같은 함수 f(x)=21x,0<x<2인 확률밀도함수로 갖는 확률변수를 Rejection sampling을 이용해 생성해보자.
g(x)=21,0<x<2는 Unif(0,2)의 확률밀도함수이면서 f(x)≤g(x)/β,β=1/2를 만족한다. 또한 Unif(0,2)로부터 데이터를 생성하는것은 쉽다.
이때 envelop 함수는 e(x)=2g(x)=1가 된다.
이 경우, rejection sampling 알고리즘은 다음과 같다.
-
X∼Unif(0,2)인 X 생성하기
-
U∼Unif(0,1)인 U 생성하기
-
U≤f(X)/e(X)=21X를 만족하면 X를 f(x)로 부터 생성된 샘플로 받아들이고 아니면 버린다.
Importance Sampling
θ=E(h(X))인 θ를 구하는 문제로 다시 돌아가보자. 여기서 X∼f로 가정한다.
f보다 난수생성이 쉽고 support가 f의 support를 포함하는 확률분포 g가 있다고 하자.
θ를 g를 이용하여 다음과 같이 표현할 수 있다.
θ=Ef(h(X))=∫h(x)f(x)dx=∫h(x)g(x)f(x)g(x)dx=Eg(h(X)g(X)f(X))
X1,…,Xn이 g로부터 생성된 난수라고 하자. w∗(x)=g(x)f(x)라고 하면, 다음은 θ를 근사(approximate)하는 값이 된다.
θ^=n1i∑h(Xi)w∗(Xi),
이 때의 g를 importance sampling 함수라고 부른다.
Example of Importance Sampling
Inverse CDF 방법에서의 예시와 같은 함수 f(x)=21x,0<x<2 인 확률밀도함수를 갖는 확률변수를 X 라고 하자.
이 때, θ=E(X2)인 θ를 추정하는 문제를 생각해보자.
f(x)=21x,0<x<2이므로 E(X2)=∫02(21)x3dx=2로 쉽게 계산할 수 있지만, Importance sampling방법으로 근사적으로 θ를 구해볼수도 있다.
θ=Ef(X2)=∫x2f(x)dx=∫x2(g(x)f(x))g(x)dx=∫x2⋅x⋅(21)dx
g(x)=21로 보면, θ=Eg(X3)이 된다.
따라서 Unif(0,2)에서 데이터 X1,⋯,Xn을 생성하여 θ^=n1∑h(Xi)w∗(Xi)=n1∑Xi2⋅Xi를 이용하여 구할 수 있다.
