Statistics
1.Probability Distribution

확률(Probability)이란, 어떤 사건(event)이 일어날 가능성을 나타내는 개념으로 사건 A가 일어날 확률을 $P(A)$로 나타낸다.$P(A)$ = 사건 A에 속하는 원소의 개수 / 표본공간 전체의 원소의 개수이 때, 사건 A는 어떤 시행(Experiment,
2.Joint Probability Distribution
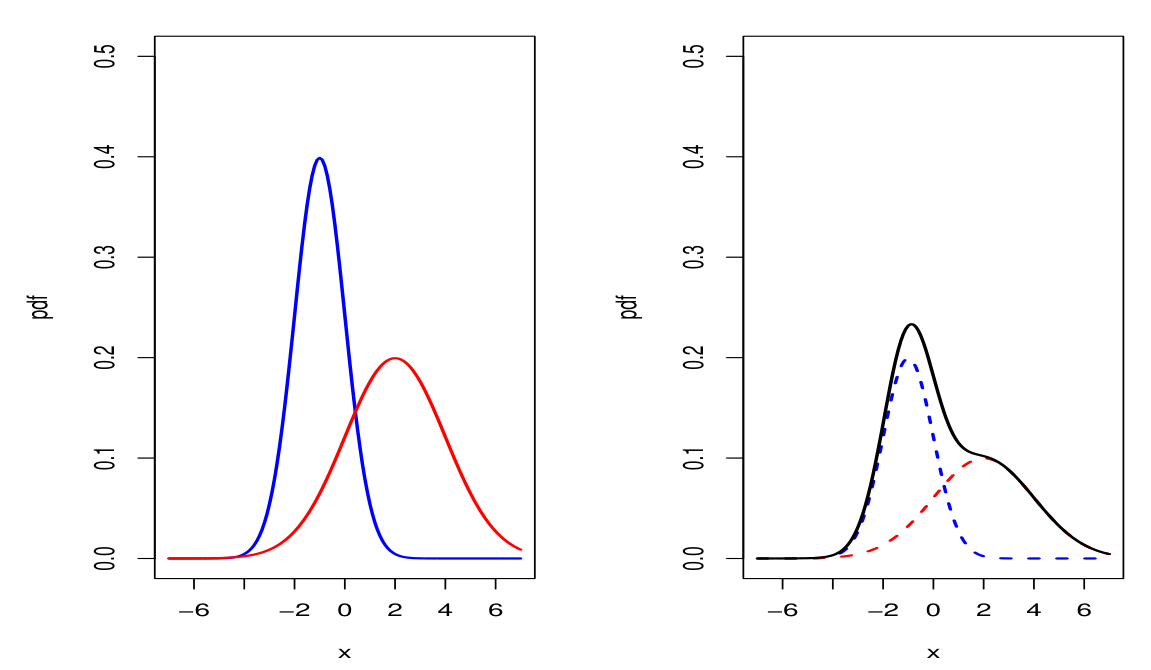
결합분포(Joint Probability Distribution)는 두 개의 확률변수가 취할 수 있는 값들의 모든 쌍의 확률을 나타낸 것이다.이산형 결합확률질량함수$$p(x,y) = P(X=x, Y=y)$$$0 \\leq p(x,y) \\leq 1$$\\sum_x\\s
3.Parameter Estimation and Hypothesis Test
표본으로부터의 정보를 이용하여 모집단에 관한 추측이나 결론을 이끌어내는 과정을 통계적 추론 (Statistical Inference)라고 한다. 이러한 통계적 추론의 종류로는 추정 (Estimation)과 가설 검정 (Hypothesis test)이 있다.Estimat
4.Nonparametric Statistics
Parameter estimation의 경우 기본적으로 모집단의 분포를 가정(정규분포 등)한 후, 해당 분포의 parameter를 추정하고 검정하였다 (참고). 하지만, 모집단에 대해 정규분포 같은 구체적인 분포함수를 가정하는 것이 무리일 때에는 모집단 분포에 대한 가
5.Bayesian Statistics
베이지안 추론 (Bayesian Inference)은 통계적 추론의 한 방법으로, 추론해야 하는 대상의 사전 확률에서 데이터 관측을 통해 해당 대상의 사후 확률을 업데이트하여 추론하는 방법이다. 이는 베이즈 확률론을 기반으로 하며, 이는 추론하는 대상을 확률변수로 보아
6.Monte-Carlo Method
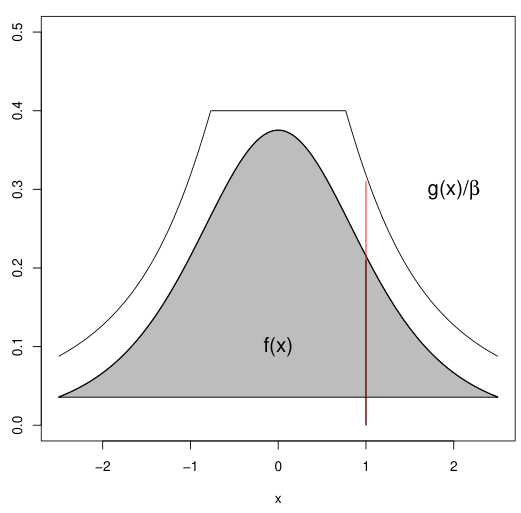
몬테카를로 방법 (Monte Carlo Method)이란, 어떤 값 (또는 함수값)을 근사적(approximation)으로 계산하는데 있어 확률분포로부터 생성한 무작위 샘플(표본)들을 이용하는 방법이다.이를 위해 큰 수의 법칙 (Law of large number, L
7.Markov Chain Monte-Carlo
Bayesian inference를 요약하면 다음과 같다.데이터의 분포에 관한 모형 (likelihood, $L(\\theta\\mid X)$)와모델을 정하는 모수 (parameter)의 사전분포 (prior distribution, $\\pi(\\theta)$)를 이
8.Variational Inference
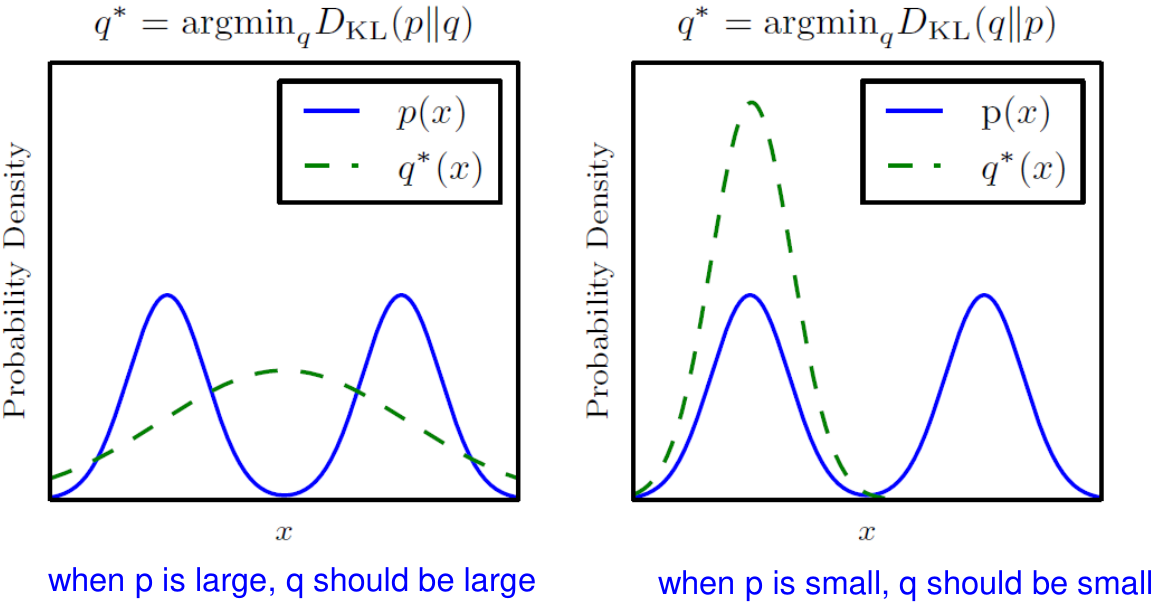
Bayesian inference를 요약하면 다음과 같다.데이터의 분포에 관한 모형 (likelihood, $L(\\theta\\mid X)$)와모델을 정하는 모수 (parameter)의 사전분포 (prior distribution, $\\pi(\\theta)$)를 이