Garbage-in garbage-out의 관점에서, 좋은 모델이 되기 위해서는 결국 좋은 data가 필요하다. 하지만 좋은 data를 모으기는 정말 어렵고, 또 모은 data는 항상 생각한 것만큼 좋지는 않다. 따라서, data를 깊게 살펴보는 작업을 통해 data를 이해하고, 적절한 형태의 data로 transform하는 것은 좋은 model을 만드는 것에 있어서 필수적이고 가장 중요한 과정이며, 더 나아가 결과를 올바르게 이해하는 것에도 도움을 준다.
Extract, Transform, and Load (ETL)
Extract, transform, 그리고 load 작업, 줄여서 ETL은 일반적으로 여러 시스템에 퍼져있는 data를 하나의 database 또는 data warehouse 등에 적절한 형태로 저장하는 작업 process를 의미한다.
-
Extract: 다양한 source (database, file, API 등)에서 data를 추출하는 단계로, 필요한 raw data를 수집하는 단계이다.
-
Transform (변환): 추출된 data를 분석 및 학습에 적합한 형태로 변환하는 단계이다.
- 일반적인 data preprocessing 과정이 이 단계에 해당한다.
-
Load (적재): 변환된 data를 최종 대상 시스템(data warehouse, data lake 등)에 적재하는 단계이다.
이러한 ETL은 일반적으로 pipeline을 구축하여 운영된다.
최근 많은 기업 등에서는 data source와 load 대상 system이 모두 cloud 형태이다. 즉, ETL pipeline이 back-fill 형태를 갖는다.
Questions about Data
Data는 기본적으로 data object (sample, instance, data point 등 으로 불림)와 attribute (field, feature, column 등으로 불림)로 구성된다.
Data의 attribute들은 다음 type들로 구분한다. 이는 data preprocessing 뿐만 아니라 model 생성에서도 기초가 된다.
Extraction을 통해 data를 얻게된 이후에는 아래와 같은 질문에 대해 답할 수 있을 정도로 자세히 살펴보는 것이 중요하다.
-
Data가 어떤 type의 attribute 또는 field로 구성되어 있는가?
- Nominal attribute: 명목 속성
- Numeric attribute: 수치 속성
- Ordinal attribute: 서열 속성
- Binary attribute: 이진 속성
-
각 attribute는 어떤 종류의 값을 갖는가?
-
어떤 attribute들이 discrete하고, 또 continuous한가?
-
Data가 어떻게 생겼는가?
-
각 attribute들이 어떤 분포를 가지고 있는가?
-
Data에 대한 정보를 더 얻기 위해 어떤 visualization이 가능한가?
-
Outlier를 구분해낼 수 있는가?
-
각 data object들의 similiarity를 측정할 수 있는가?
위 질문들에 대한 답을 위해서는 data의 기본적인 특성에 대해서 이해할 필요가 있다.
Characteristics of Data
Data의 주요 특성은 다음과 같은 것들이 있다.
-
Dimensionality: data의 차원이 어떤 형태인지 알아야한다.
-
Sparsity: data가 sparse한지, 즉 값이 없거나 0인 data가 어떤 비율로 있는지 알아야 한다.
- Sparse data에서는 특정 값이 존재하는 것 자체가 중요할 수 있다.
-
Resolution: data가 어떤 level까지의 정보를 담고 있는지 알아야 한다.
- 높은 resolution 또는 scale에서는 세부적인 pattern을 발견할 수 있지만, 낮은 resolution에서는 전체적인 trend를 더 잘 파악할 수 있다.
-
Distribution: 각 data가 대략적으로 어떤 분포를 갖는지, 눈에 띄는 outlier는 없는지 파악해야 한다.
- Machine learning에서는 training data이 실제 data와 유사한 분포를 갖도록 만드는 것이 중요하다.
Basic Statistical Descriptions of Data
Data의 statistics를 파악하는 것은 data 자체의 이해도를 높이는 것에도 목적이 있지만, missing/noisy data 처리 및 outliers 처리 등의 preprocessing에도 도움이 된다.
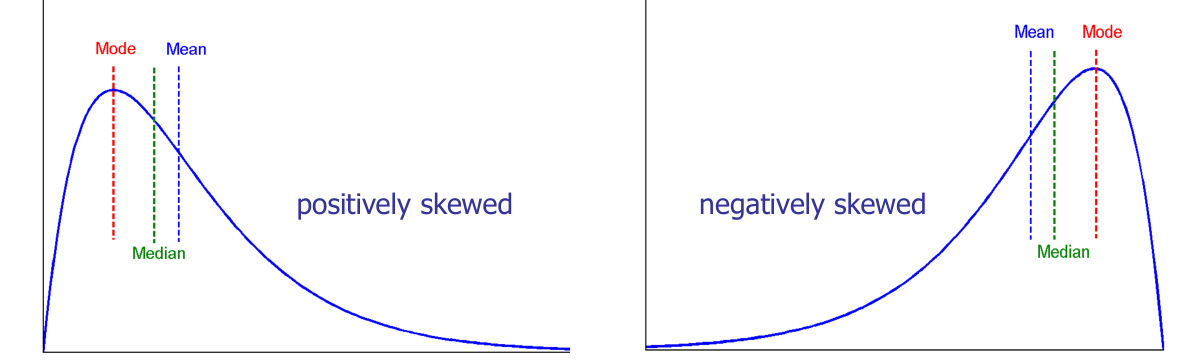
Central tendency에 관한 statistics으로는 mean (평균), median (중앙값), mode (최빈값)이 있다.
- Symmetric data: mean = median = mode
- Skewed data의 경우,
- positively skewed: mode < median < mean
- negatively skewed: mode > median > mean
Dispersion에 관한 statistics으로는 variance, standard deviation, quantiles, IQR 등이 있다.
-
Quantiles
- The k-th q-quantile: q등분 시, k번째 지점
- The 4-quantiles: quartiles
- The 100-quantiles: percentiles
-
Interquartile Range (IQR)
- The distance between the first and the third quartiles: .
Data Visualization
Data를 visualize하는 것은 data의 relations, trends, hidden structures 등을 가장 잘 이해할 수 있는 방법이다. Statistics는 결국 data를 요약한 하나의 숫자이기에, statistic만으로 data를 설명한다면 큰 오류에 빠질 수 있다. (참고: WHAT DINOSAURS ARE HIDING IN YOUR DATA?)
Data를 visualize하는 방법들은 무척 다양하게 있지만, 대표적인 것들은 다음과 같은 것들이 있다.
- Box Plot
- Histogram
- Quantile plot
- 오름차순으로 정렬된 data를 y, 각 data에 해당하는 quantile 값을 x
- Quantile-Quantile plot (QQ plot)
- 각 data의 quantile 값이 같은 것끼리 매칭
- Scatter plot, Surface plot, Scatter plot matrix
- Tree-Maps
- Tag Cloud
Similarity/Dissimilarity between Objects
Data object 간의 similarity 또는 dissimilarity는 outlier detection, 여러 classification 및 clustering 알고리즘 등의 결과를 좌우할 수 있는 주요한 지표이다.
Distances/Norms
를 data object 의 번째 attribute라고 하자. 특히 data point 간의 similarity를 나타내는 norm은 다음과 같다.
-
Manhattan:
-
Euclidean:
-
Minkowski with :
-
Chebyshev:
이 외에도,
-
주로 vector 간의 similarity를 표현하는 cosine similarity,
-
set 간의 similarity를 표현하는 jaccard similarity,
-
time series 간의 similarity를 표현하는 time warping distance,
-
string 간의 similarity를 표현하는 edit distance
등이 있다.
Data Preprocessing
Data preprocessing이란, data 분석 및 학습을 수행하기 전에 data를 정리하고 준비하는 과정을 말한다.
ETL에서의 transform 단계에 해당한다.
일반적으로 현실의 데이터는 noisy data와 missing data, 그리고 inconsistent data가 부지기수이고, 이러한 저품질 데이터는 데이터 분석과 이를 이용한 학습의 결과의 품질을 저하시키는 결과를 낳는다. 즉, 이러한 저품질 데이터를 가공하여 데이터의 품질을 높여주고 이를 통해 데이터를 이용한 분석과 학습 결과를 개선하는 것이 데이터 전처리의 목적이다.
Data Quality
Data preprocessing의 목적은 data의 품질을 향상시키는 것이다. 아래 항목들은 data의 품질을 나타내는 여러가지 요소로, preprocessing을 적용했을 때 아래 항목들이 개선되지 않는다면 제대로 된 preprocessing 방법이 적용되었는지 점검할 필요가 있다.
-
Accuracy: 데이터가 실제 값을 정확하게 반영하는지 확인
-
Completeness: 데이터가 누락된 부분이 없는지 확인
-
Consistency: 데이터가 모순되지 않는지 확인
-
Timeliness: 데이터가 최신 정보를 반영하는지 확인
-
Believability: 데이터가 올바른지에 대한 신뢰 수준 확인
-
Interpretability: 데이터가 얼마나 쉽게 이해되고 해석될 수 있는지 확인
Data Preprocessing Process
Data preprocessing은 일반적으로 다음과 같은 과정들을 거친다.
-
Data Cleaning
- Missing data 처리: missing data를 식별하고 보완하거나 삭제하는 작업
- Noisy data 처리: 분석 결과를 왜곡할 수 있는 noisy data 및 outlier를 감지하고 처리하는 작업
- 오류 처리: 데이터 내의 오류를 식별하고 수정하는 작업
-
Data Integration
- 여러 data source에서 data를 가져와 통합하고, 형식과 속성 등을 일치시켜 하나의 dataset으로 통합
-
Data Transformation
- Data normalization or standardization: 특정한 attribute 또는 value의 단위가 data의 분포를 dominate하는 것을 방지하기 위해 data의 값이 가질 수 있는 범위를 특정 분포로 조정
- Categorical data encoding: nominal 또는 ordinal attribute를 분석이나 모델에 적합한 numeric data로 변환
- Feature construction: 기존 attribute에서 새로운 attribute를 생성
- Discretization: numerical attribute를 categorical attribute로 변환
-
Data Reduction
- Feature engineering: 목표 변수 또는 모델링 작업에 가장 영향을 주는 중요한 특성을 식별하고 선택
- Numerosity reduction: 데이터 그 자체가 아닌, 데이터를 표현할 수 있는 요소들만 저장하여 처리할 데이터의 양을 줄임
- Dimensionality reduction: PCA 또는 feature engineering 등을 통해 모델에 가장 영향을 주는 중요한 attribute를 선별
- Sampling: 본래 dataset으로부터 일부 데이터를 골라내어 보다 작은 dataset을 만듬
- Data compression: data 손실이 없거나 최소한으로 만드는 data 압축 알고리즘을 적용하여 data를 보다 적은 용량으로 가공
