Introduction to ML
1.Bias-Variance Trade-off
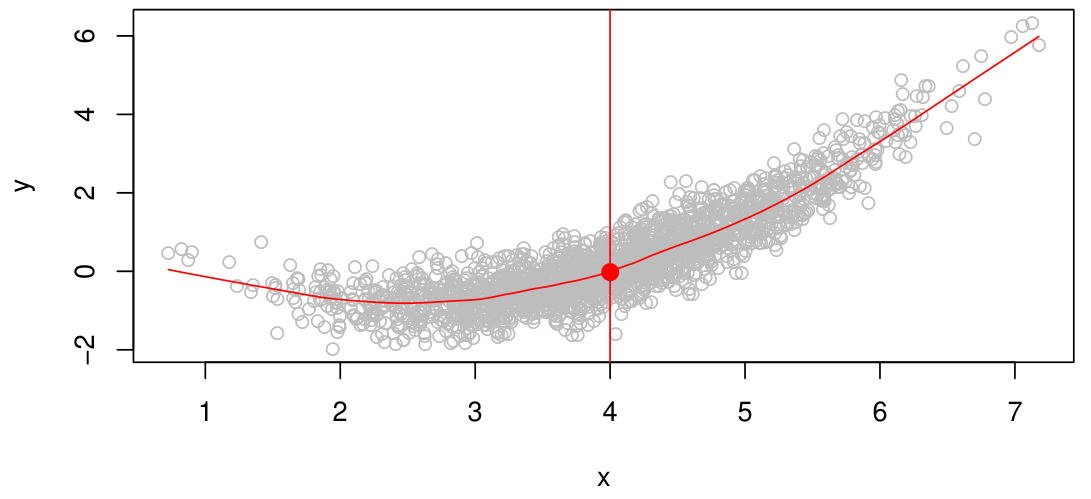
두 variable Y, X가 있을 때, X를 사용해서 Y를 예측하는 model은 다음과 같이 쓸 수 있다.$$Y=f(X)+\\epsilon$$Y: response, targetX: feature, input, predictor$\\epsilon$: errors$f$:
2.Linear Regression
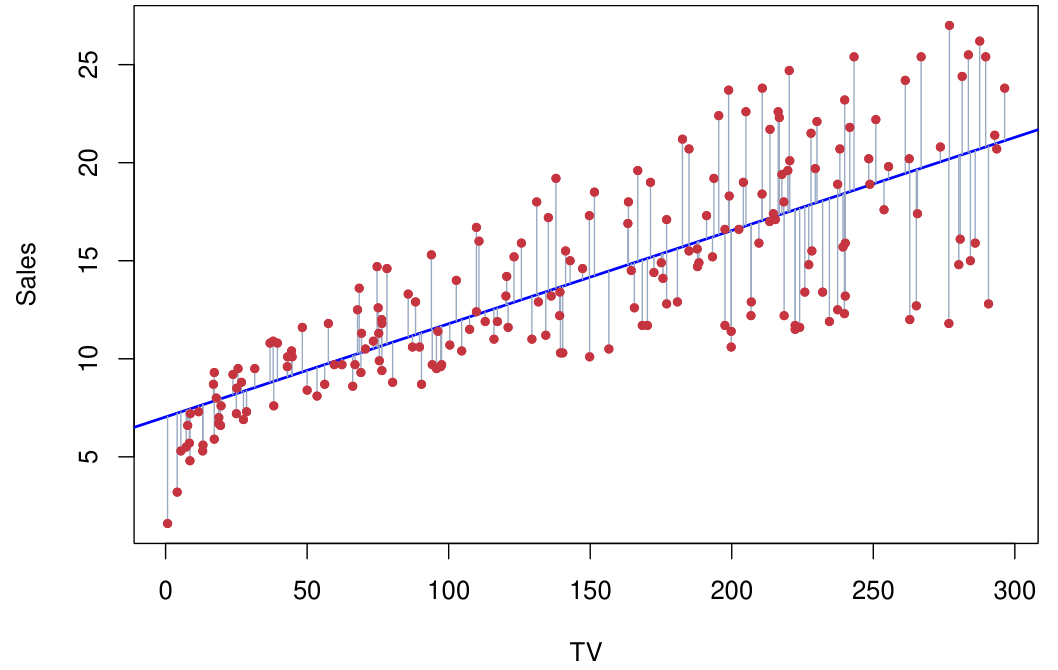
Linear regression은 가장 간단한 버전의 supervised learning으로, 이는 $Y$가 $X_1, X_2, \\dots, X_p$와 linear dependency를 가진다고 가정한다.현실의 data는 결코 linear가 아니지만, linear m
3.Logistic Regression
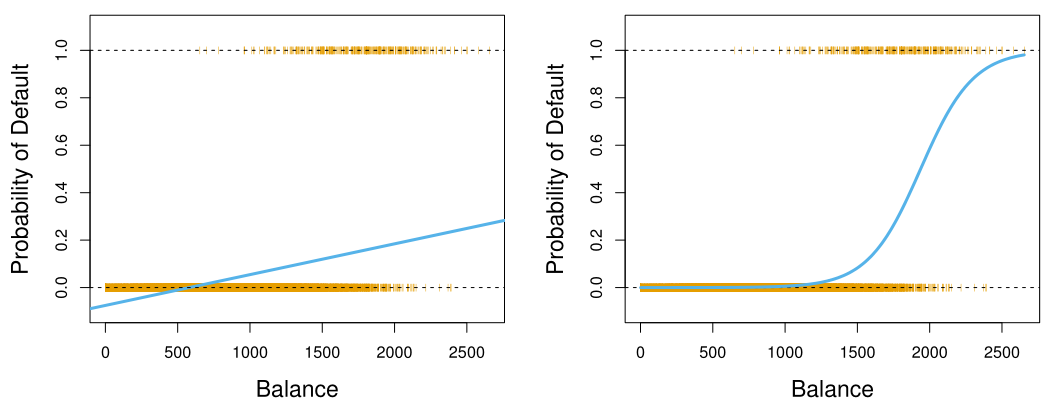
주어진 data, 또는 feature vector X,에 대해, 해당 data가 어떤 category에 포함될 지를 결정하는 것을 classification이라고 한다. 이는 X가 각 category C에 포함될 확률을 통해 결정된다.예를 들어, 'No'이면 Y=0,
4.Discriminant Analysis
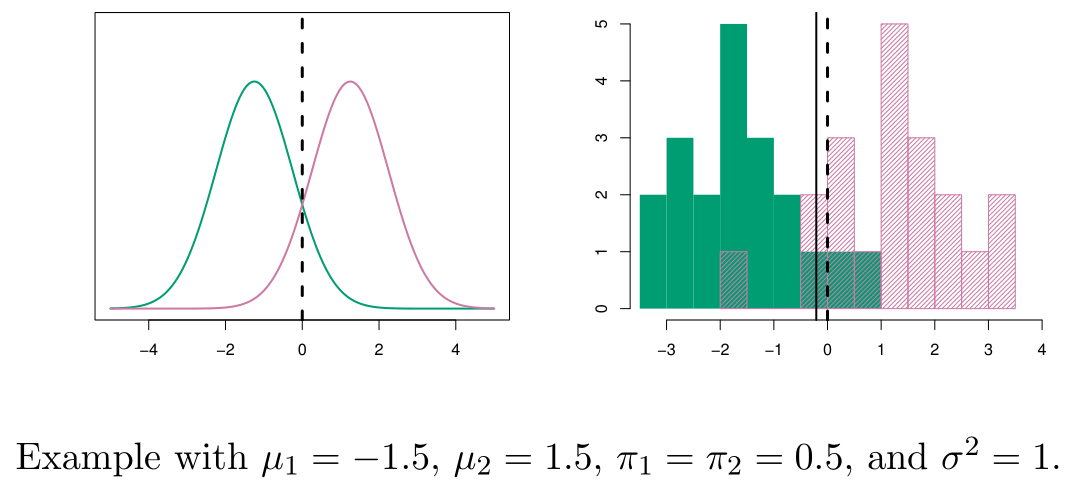
Logistic regression과 다른 방법으로도 classification을 진행할 수 있다.각 class 별 X의 distribution을 modeling하고, Bayes theorem을 적용해 $Pr(Y\\mid X)$를 얻는다. 이를 discriminant
5.Model Evaluation Metric
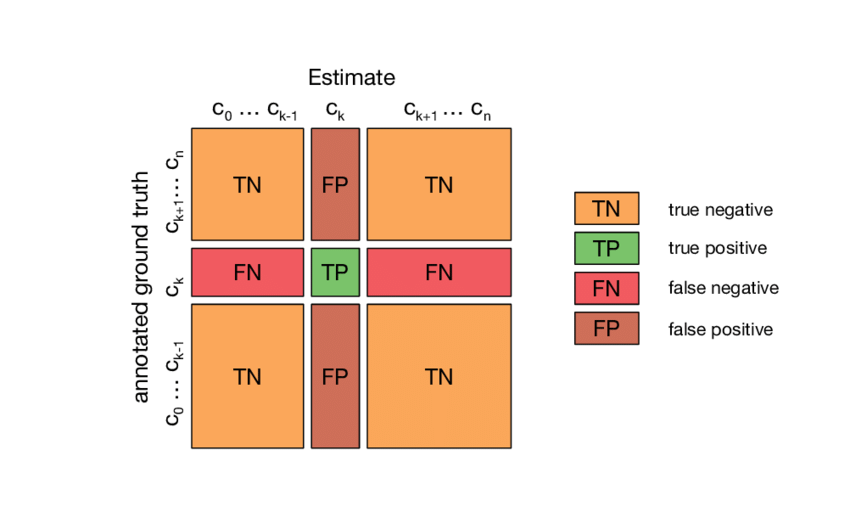
Model evaluation은 당연하게도 무척 중요하다. 특정 application에 적용할 model이라면, 해당 application에서 요구하는 수준의 performance를 낼 수 있는지 미리 확인 할 수 있어야 한다. 또한, model 자체를 optimizi
6.Hyperparameter
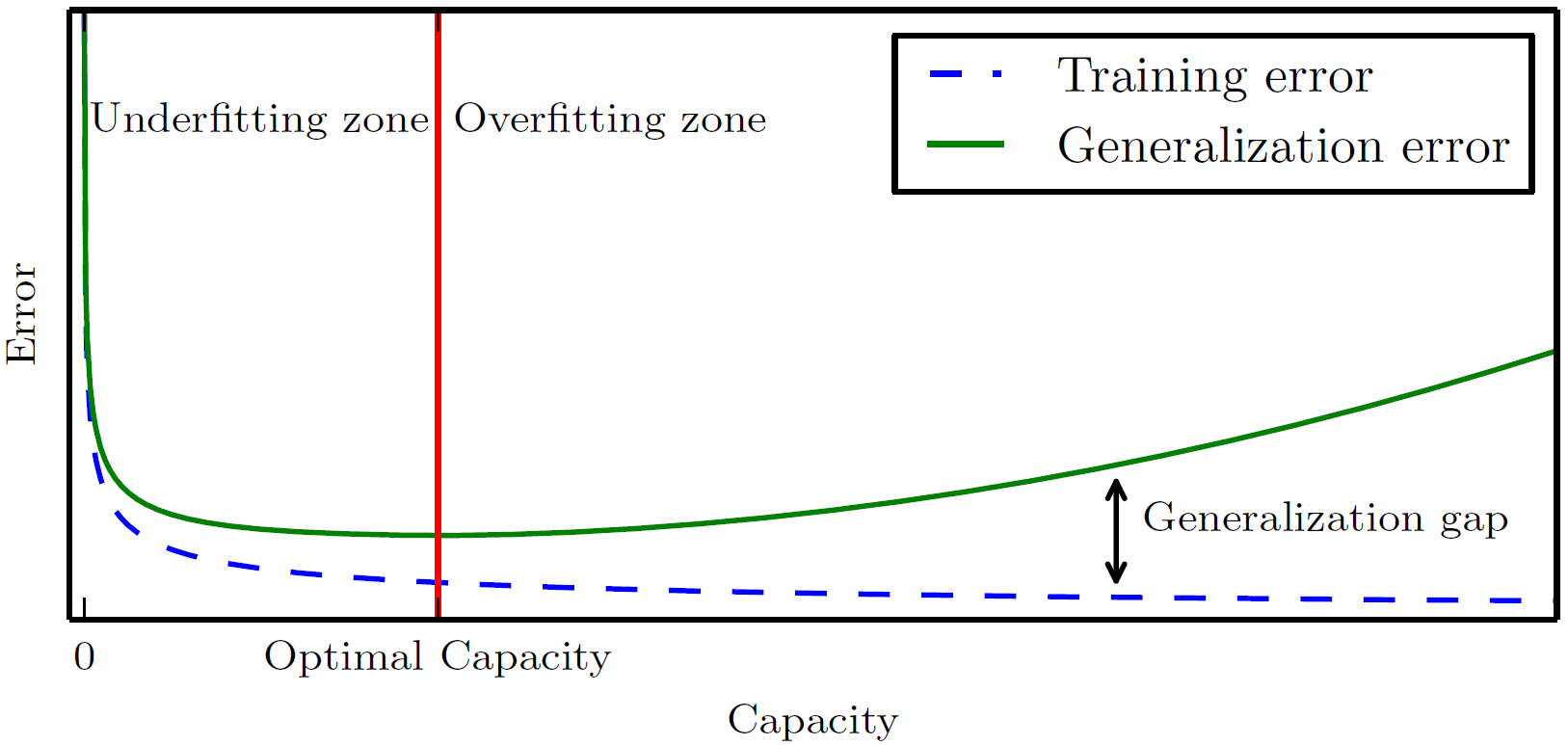
Hyperparameter는 일반적인 model의 parameter와 다르게, 학습 과정으로부터 배우는 parameter가 아니라 학습 과정을 control하기 위해 사용자가 직접 설정하는 parameter를 말한다. 일반적인 model의 parameter는 learn
7.Cross-validation

기본적으로 model의 성능은 test error를 기반으로 평가된다. 그러나 test set은 기본적으로 training 과정에서 알 수 없기 때문에, training 시에는 test error를 예측하는 방법이 필요하다. Validation-set Approach Validation-set approach 또는 hold-out approach는 우리가...
8.Bootstrap
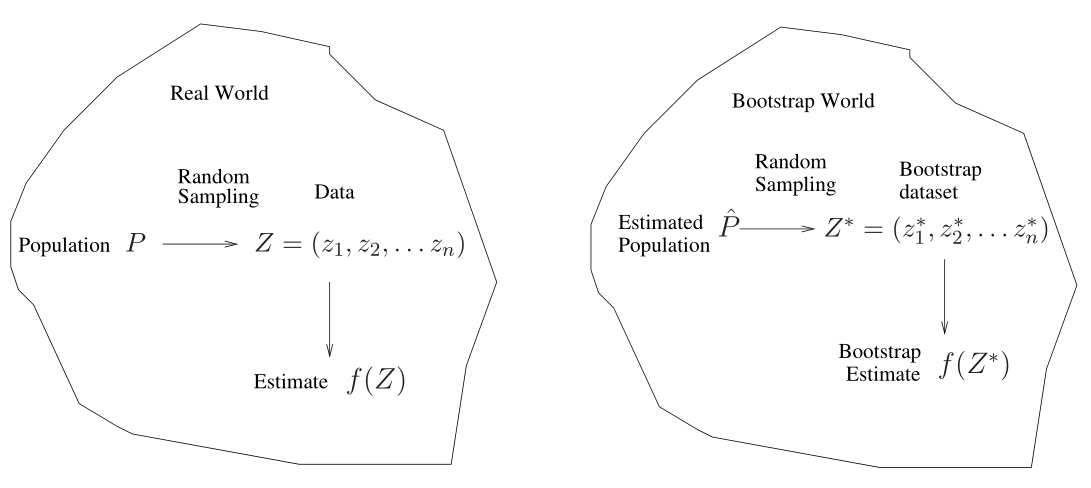
Bootstrap은 estimator 또는 learning method의 불확실성을 측정함에 있어서 상당히 유용한 통계적 기법이다. 사전에 bootstrap을 검색하면 '자기 스스로 하는, 독력(獨力)의'라는 뜻이라고 나온다. 본래 bootstrap이란 부츠 신발에 달
9.Feature Subset Selection
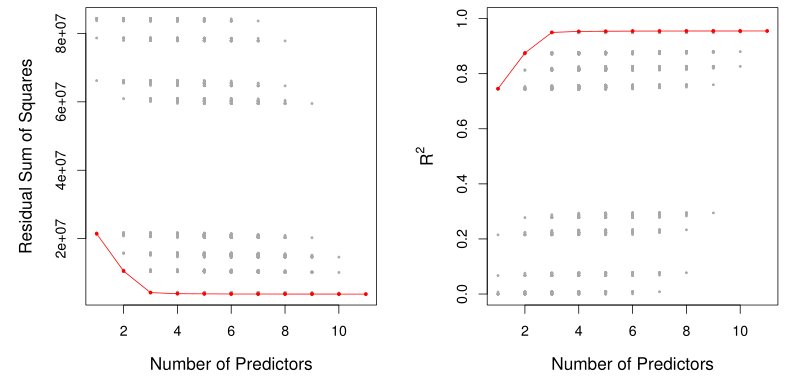
Machine learning에서 가장 중요한 것 중 하나는 올바른 feature들을 찾는 것이다. 이는 결과와 무관한 feature들을 제거하여 prediction accuracy와 model interpretability를 향상시키는 것을 말한다.여기서는 그 방법
10.Regularization
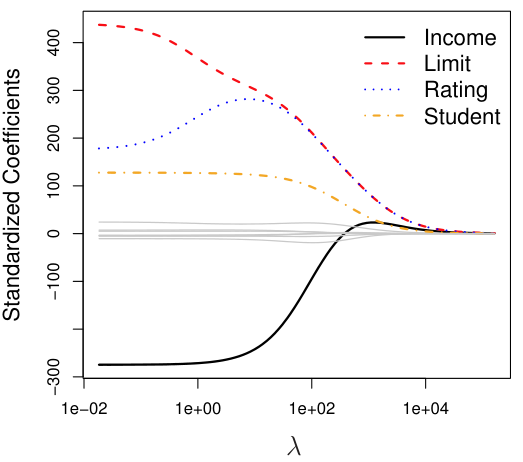
Regularization은 model의 flexibility를 조절하여 overfitting을 방지하고, model의 성능을 향상시키기 위해 사용되는 기법을 말한다. 주로 regression analysis와 machine learning에서 사용된다.Regulari
11.Dimension Reduction
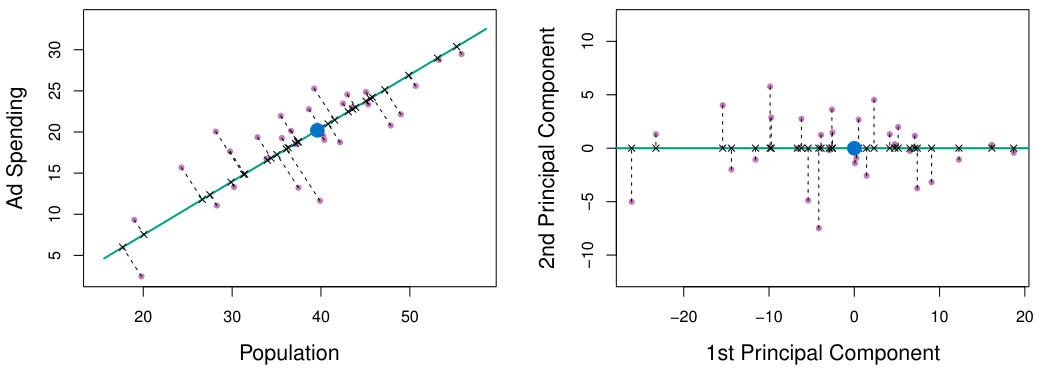
Dimension reduction이란 high dimensional data에서 중요한 정보를 유지하면서 data의 dimension을 줄이는 기법을 말한다. 기본적으로 data를 2-dim 또는 3-dim으로 표현하게 되면 data visulalization, in
12.Non-Linear Regression Model
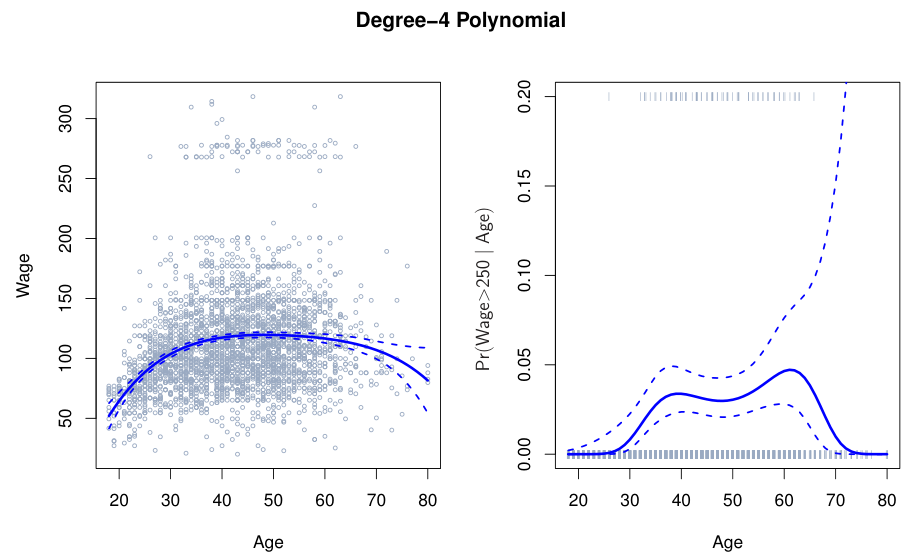
현실의 data는 결코 linear하지 않지만, linear model은 interpretability에서 큰 장점을 가지고 있기에 자주 사용된다. 여기서는 기존 linear model에 non-linearity를 더해 accuracy와 interpretability를
13.Decision Trees
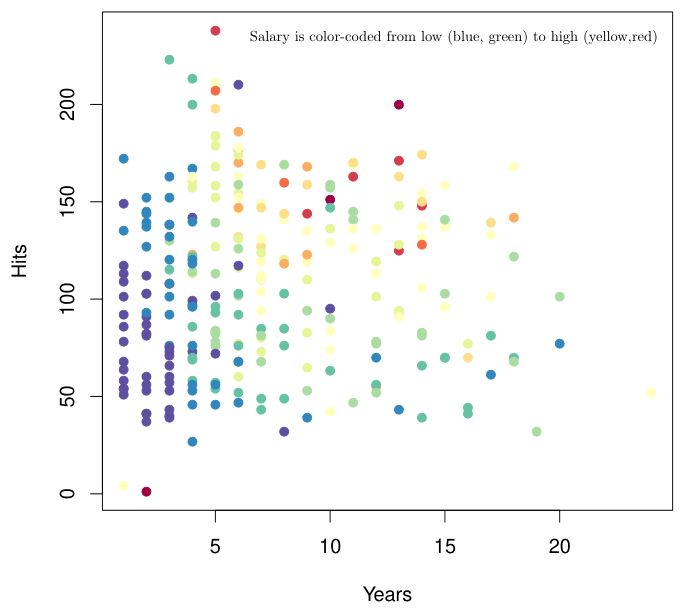
아래 예시는 야구 선수의 연차(Years)와 연간 안타 수(Hits)에 따른 연봉(Salary)를 표시한 그림이다. Salary는 낮으면 blue, 높으면 red로 표시된다.Data를 대략 살펴보았을 때, Years가 4.5를 넘는지와 Hits가 117.5를 넘는지에
14.Bagging and Random Forest
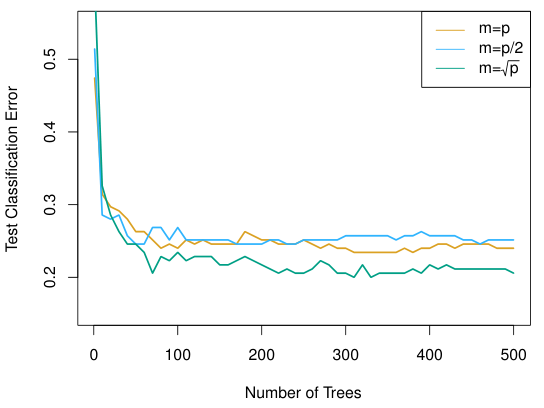
Ensemble 방법이란 하나의 target에 대해 여러개의 prediction model을 만든 후, 이를 결합하여 최종적인 prediction model을 만드는 방법을 통칭한다.예: Bagging, Boosting, Random ForestEnsemble 방법이
15.Boosting
Boosting은 weak learner 또는 baseline model 여러 개를 결합하여 보다 높은 성능의 prediction model을 만드는 방법으로, Bagging 및 Random Forest와 함께 널리 사용되는 ensemble 방법 중 하나이다 (Bagg
16.Support Vector Machines
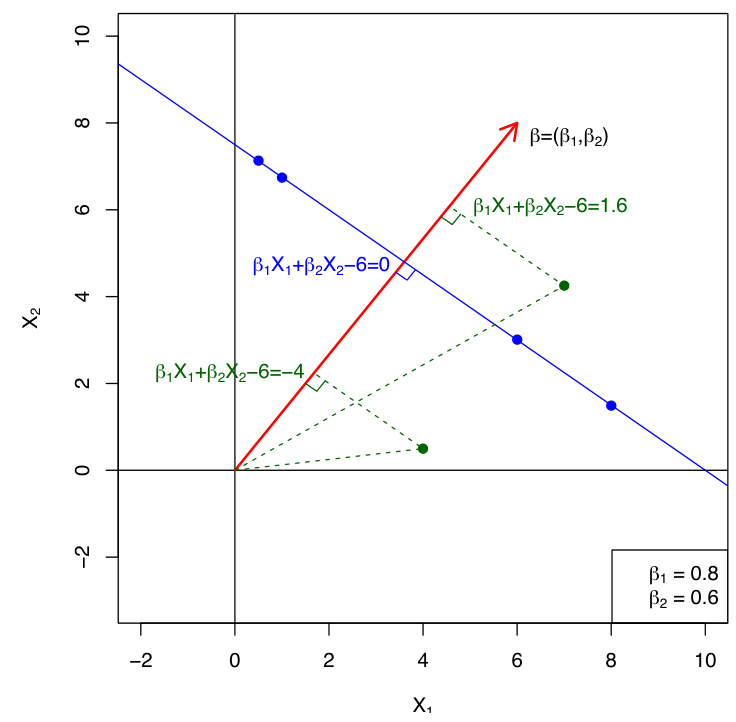
Support Vector Machines(SVMs)는 deep learning model의 큰 발전이 있기 전에는 boosting과 함께 가장 널리 사용되던 machine learning model이다.Classification 문제에 대해서, SVM은 기본적으로 c
17.Clustering
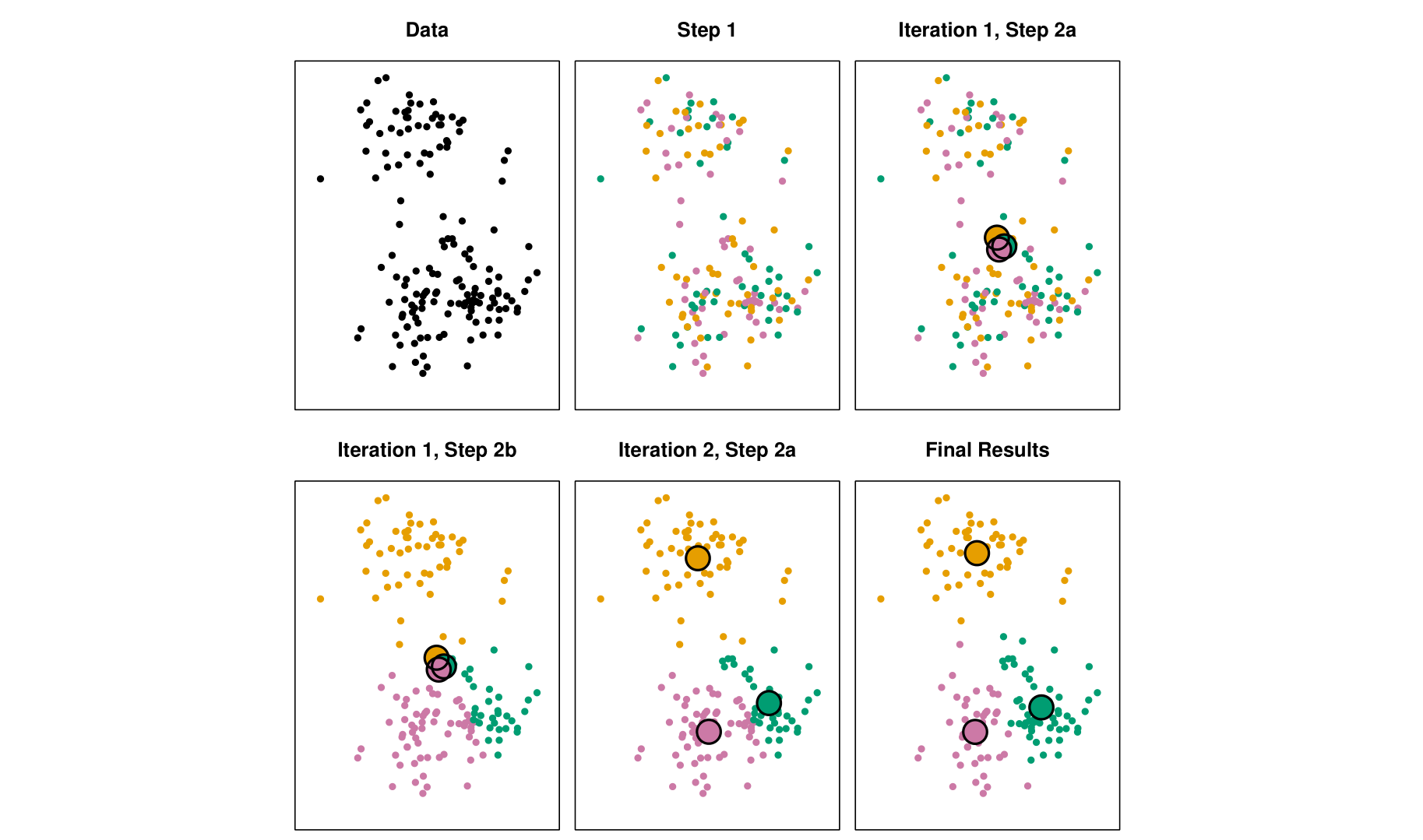
Clustering이란 대표적인 unsupervised learning 방법 중 하나로, data set에 대해서 homogeneous subgroup 또는 cluster를 찾는 기법을 말한다.Clustering이란 기본적으로 어떤 algorithm과 measure를
18.Overview of Data Preprocessing
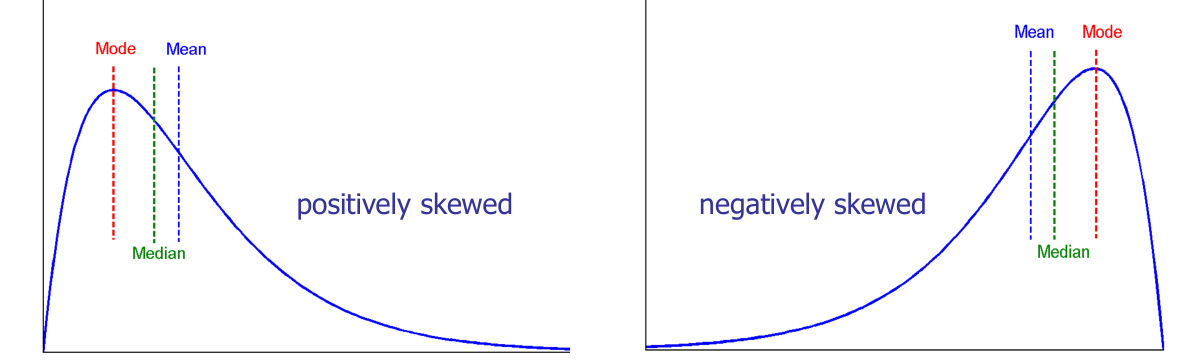
Garbage-in garbage-out의 관점에서, 좋은 모델이 되기 위해서는 결국 좋은 data가 필요하다. 하지만 좋은 data를 모으기는 정말 어렵고, 또 모은 data는 항상 생각한 것만큼 좋지는 않다. 따라서, data를 깊게 살펴보는 작업을 통해 data를
19.Data Preprocessing Process
Data cleaning이란 데이터의 품질을 높이기 위해 다양한 규칙을 검사하여 데이터의 일관성을 유지하고 오류를 방지하는 작업이다. Data preprocessing에서 필수적이고 중요한 단계이다.일반적으로 data cleaning을 위한 방법으로는 data disc