Introduction to DL
1.Introduction to Deep Learning
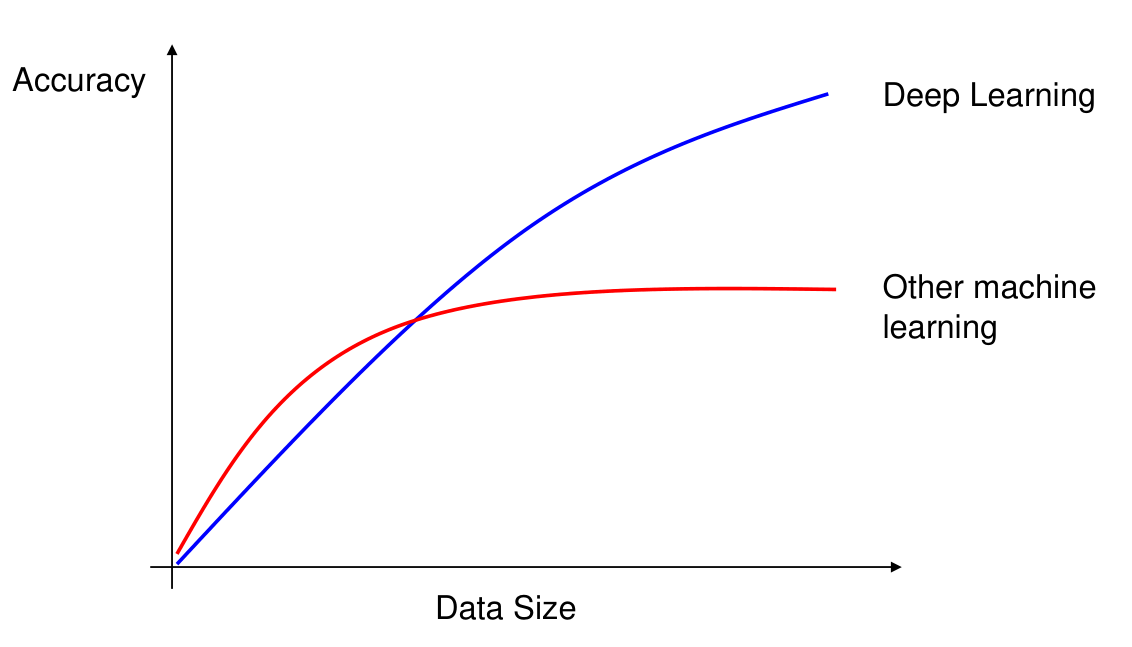
Machine Learning (ML)은 주어진 x (predictor)와 y (response)에 대해 function f (즉, y=f(x))를 data로부터 배우는 것을 말한다. 이는 전통적인 programming 방식인 주어진 x와 f()로부터 y를 계산하는 것
2.Mathematics for Deep Learning

$$\\sigma(x) = \\frac{1}{1+\\exp(-x)}$$$$\\zeta(x) = \\log(1+\\exp(x))$$softened version of $x^+ = \\max(0,x)$$\\sigma(x) = \\frac{1}{1 + \\exp(-x)} =
3.Architecture Design
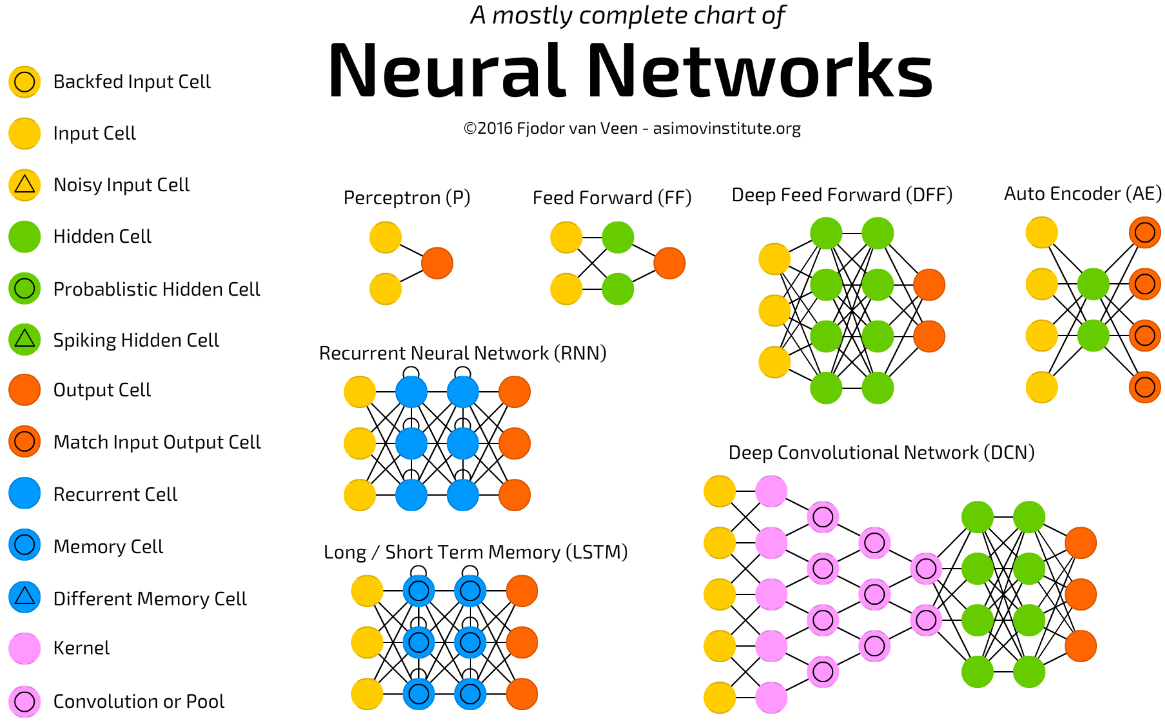
Architecture란 network의 전반적인 구조를 말한다. Neural networks에서의 architecture란 몇 개의 layer를 사용할 것인지, 각 layer 별로 몇 개의 unit을 어떤 식으로 사용할 것인지, 각 unit들을 어떻게 연결할 것인지와
4.FeedForward Neural Networks

Feedforward neural network (FNN)는 가장 핵심적이고 기본적인 deep learning model이다. Deep feedforward network 또는 multi-layer perceptrons (MLP)로도 불린다.FFN도 일종의 input
5.Backpropagation
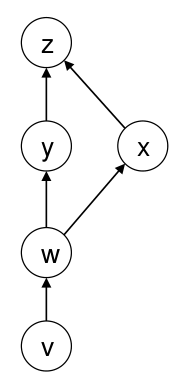
우리는 앞서 FFN을 통해 input layer부터 output layer까지 순서대로 값을 계산하고 저장하는 작업을 수행했다. 이를 forward propagation이라고 한다. 이후, 이렇게 forward propagation을 통해 계산된 output과 미리 정
6.Convolutional Neural Network
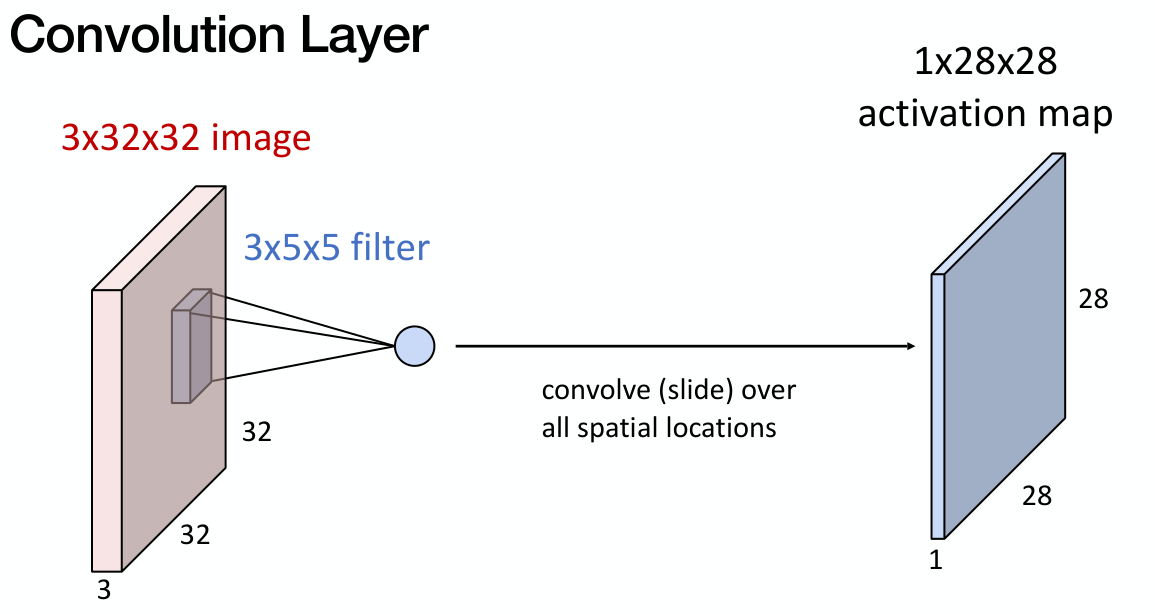
Image 분류 및 처리 등에 있어서 탁월한 성능을 보인 convolutional neural network (CNN)에 대해서 정리하고자 한다. CNN은 FNN에서 feedforward 과정에서 진행했던 matrix multiplication 연산을 convoluti
7.Recurrent Neural Network
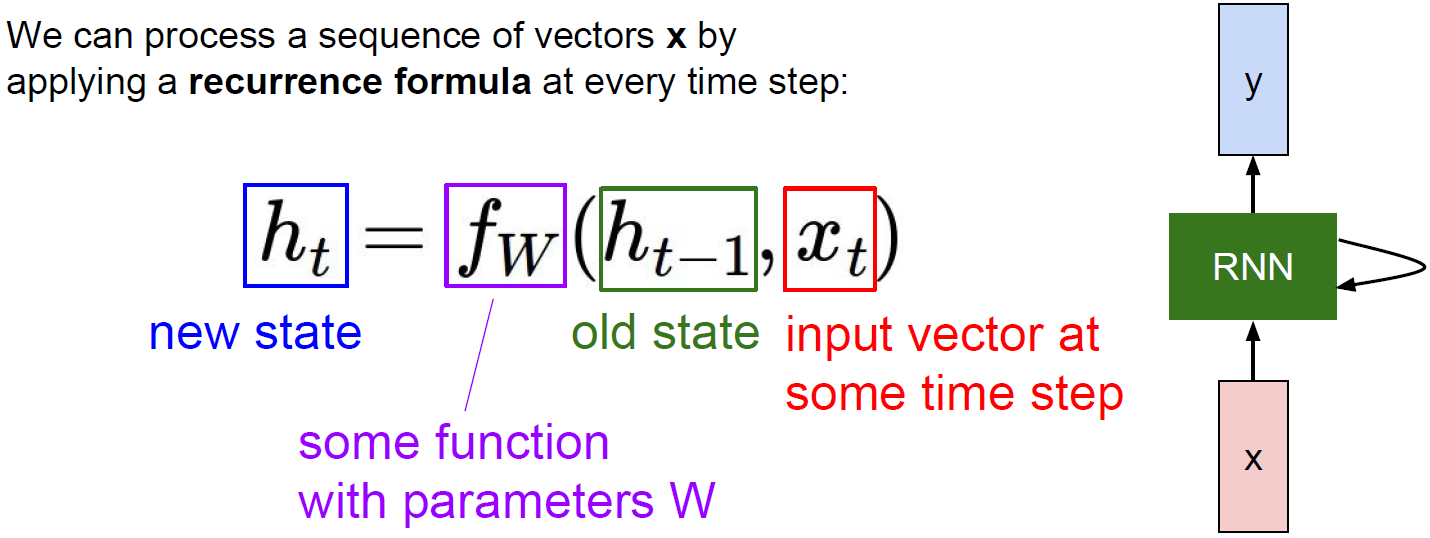
Recurrent neural network (RNN)은 sequential data를 처리하는 것에 특화된 neural network로, 자연어 처리(natural language processing, NLP), 기계 번역(machine translation) 등 다
8.LSTM and GRU

참고: RNNRNN은 sequential data를 학습하는 것에 있어서 좋은 framework였지만, 한 가지 큰 문제를 가지고 있었다. 바로 vanishing/exploding gradient라는 문제이다. 이는 backprop 과정에서 path를 거칠수록 gra
9.Autoencoder
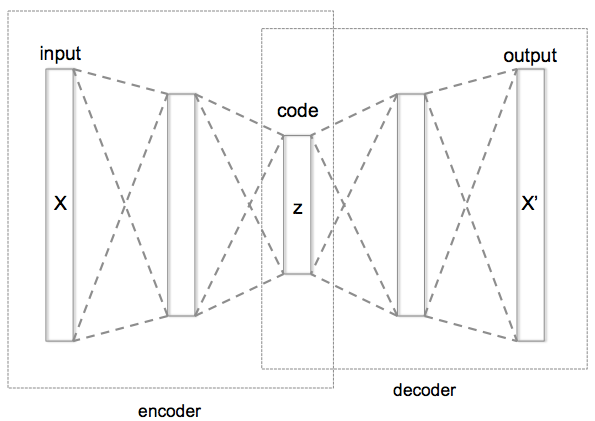
Autoencoder (AE)란 input과 output이 동일하도록 학습하는 neural network를 의미한다. 언뜻보면 아무런 의미가 없는 NN으로 보이지만, 주로 데이터의 dimension reduction 및 feature extraction을 위해 사용되는
10.Sequence-to-Sequence and Attention
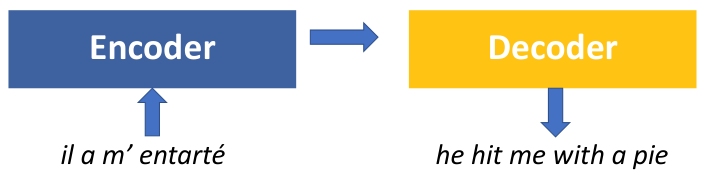
Sequence-to-Sequence (seq2seq)는 encoder-decoder structure라고도 불리우는 모델이자 일종의 framework이다. Seq2seq은 input (또는 source) sequence를 입력받는 encoder 부분과 output (
11.Transformer and Self-attention
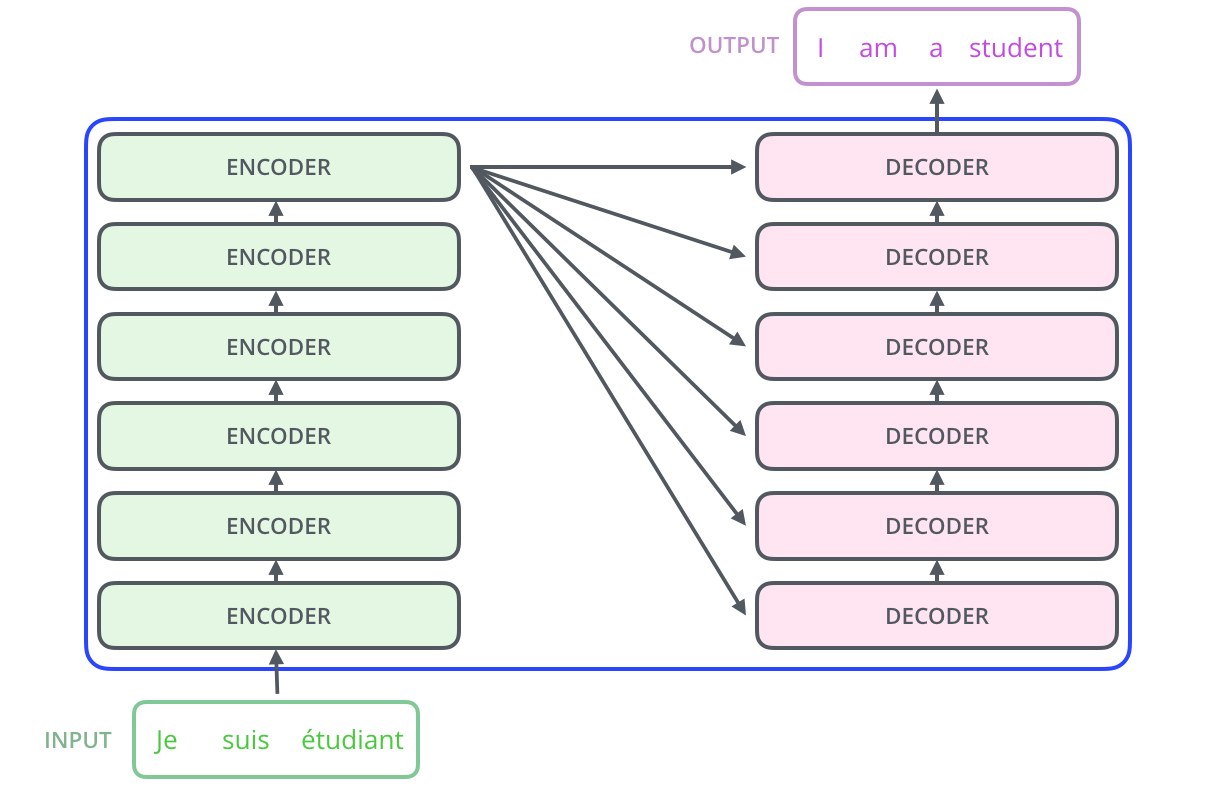
참고Sequence-to-Sequence and AttentionVaswani et al, “Attention is all you need” (2017)Deep learning, 특히 NLP의 발전은 self-attention 기법을 이용한 transformer 모델의
12.Variational Autoencoders
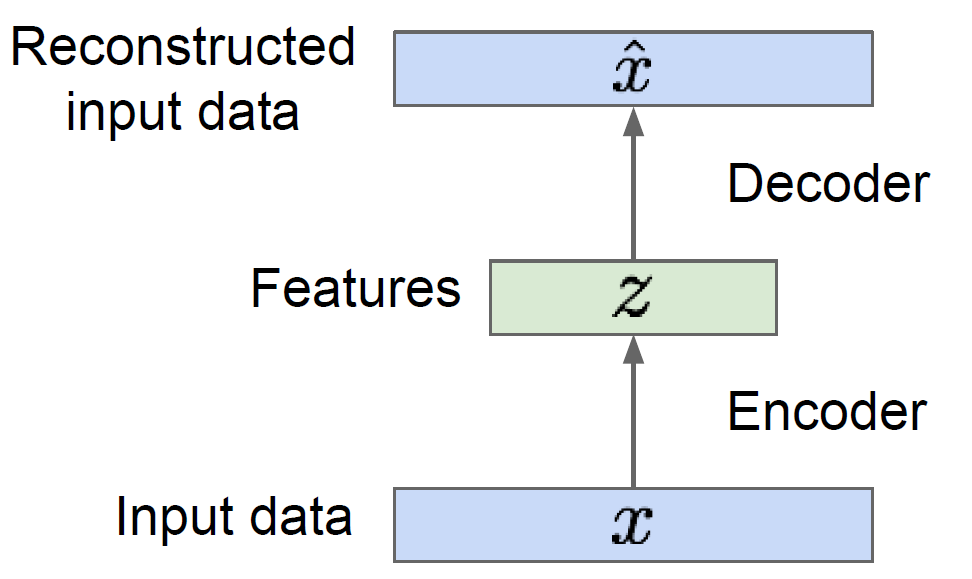
Generative model 이란 training data $p{data}(x)$으로부터 유사한 분포를 갖는 새로운 sample ($p{model}(x)$)을 생성하는 모델을 말한다. Explicit modeling은 그러한 $p{model}(x)$을 수리적으로 정의
13.Generative Adversarial Network
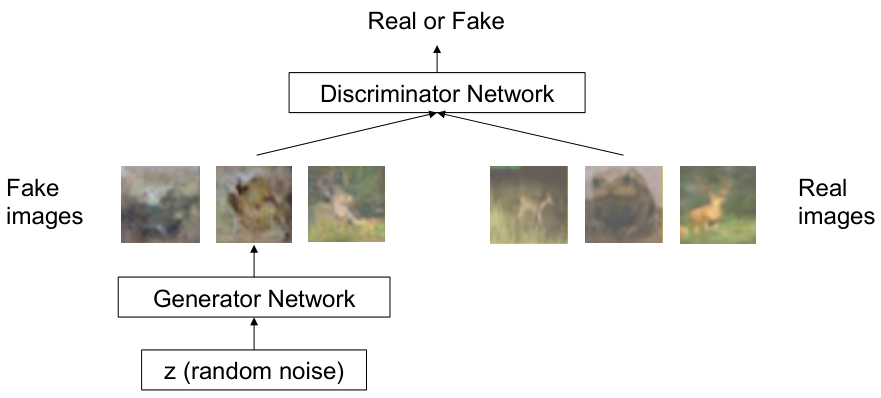
Variational autoencoder (VAE)이 sample의 분포를 미리 정해두고 이를 학습하는 explicit modeling이었다면, generative adversarial network (GAN)은 density function에 대한 가정이 필요없는
14.Hyperparameters in Deep Learning
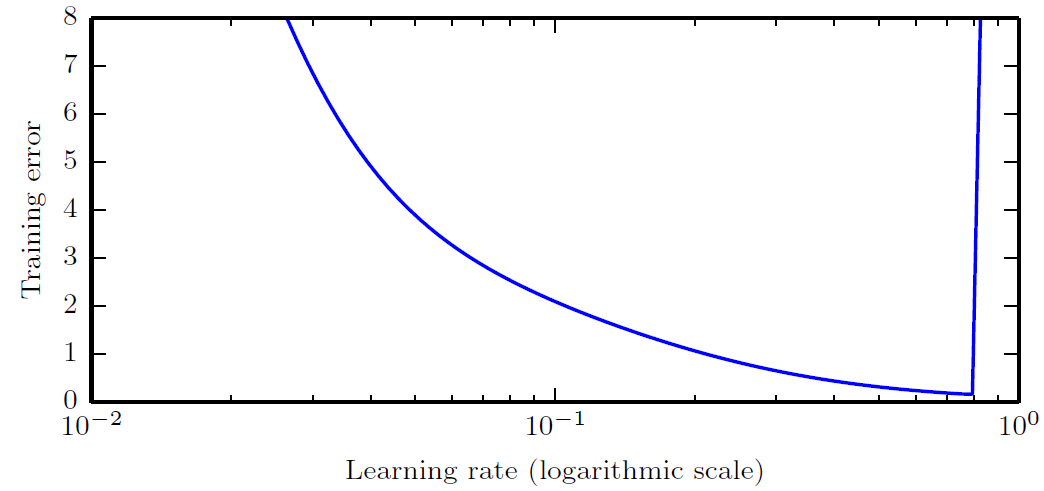
Hyperparameter에 관한 기초 내용은 아래 post를 참조하길 바란다.HyperparameterHyperparameter를 더 세부적으로 분류하면 모델의 구조에 관여하는 architectural hyperparameters와 모델의 학습 과정에 관여하는 tra
15.Advanced Regularization
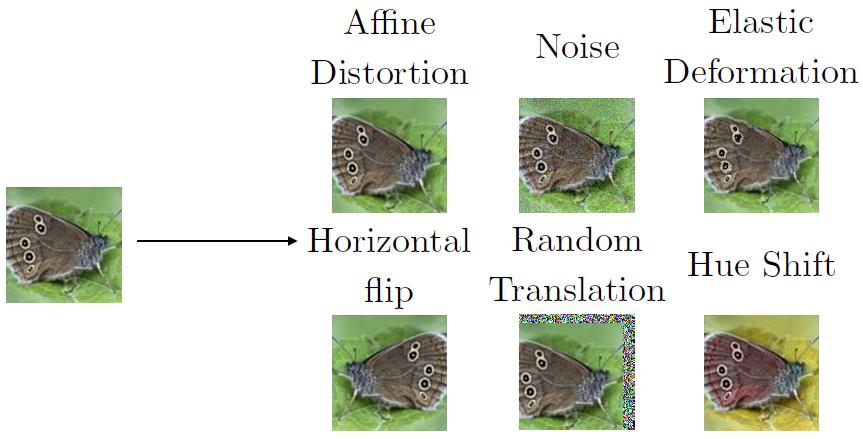
Regularization은 model의 flexibility를 조절하여 overfitting을 방지하고, model의 성능을 향상시키기 위해 사용되는 기법을 말한다.앞서 ML에 대한 posting 중에서 norm penalty (ridge, lasso)를 활용한 re
16.Batch and Layer Normalizations
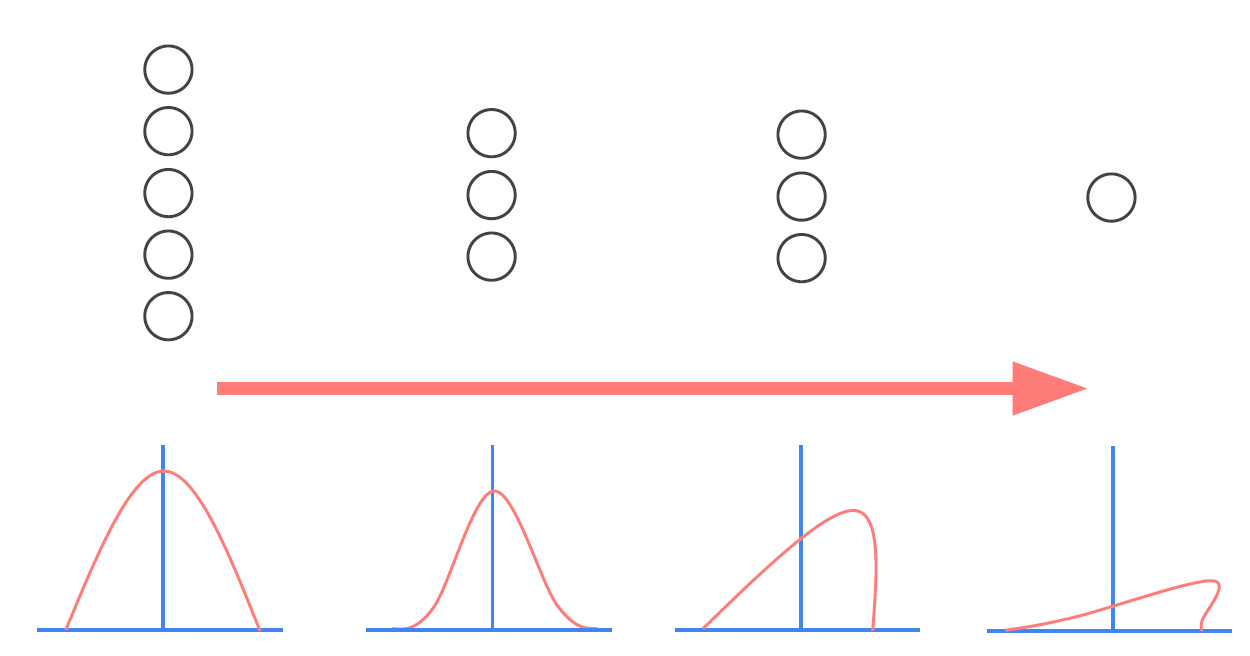
Normalization은 데이터의 분포를 특정 범위나 특정 평균과 표준 편차로 조정하여 특정 feature에 대해 과대/과소 평가를 하지 않도록 만드는 과정을 말한다. 일반적으로 machine learning 등에서 input data에 대해 standard 또는 m
17.Transfer Learning

Deep learning 분야가 크게 성장할 수 있었던 이유 중 하나는 바로 transfer learning (전이 학습)이다. 이는 우리가 풀고자하는 새로운 문제를 해결하고자 할 때, 새로운 모델을 만들고 이를 처음부터 학습하는 것이 아니라 기존에 학습된 모델을 활용