
안녕하세요! cathy입니다. 저희 팀은 매주 위클리 스크럼을 진행하면서 읽어보면 좋을만한 아티클을 공유하고 읽으면서 의견을 나누고 있습니다. 이번 주는 제가 발견한 "AI 연구자를 위한 클린코드란"에 대한 아티클을 읽고 의견을 나누어보았는데요, AI를 담당하신 chaen님 뿐만 아니라 팀원 모두가 이야기할 만한 내용이 많은 글이었습니다. 파이썬 클린코드에 관심 있으시다면 한번 쯤 읽어보시길 꼭 추천드립니다!
참고로 이번 주의 글을 팀원들이 대화하는 형식으로 작성해보았습니다. 의식의 흐름대로 따라가면서 글을 읽는 것을 추천드립니다😉
이번 주 읽은 글
슬라이드를 읽으며 나눈 팀원들의 의견

❤️🔥cathy: 평소에 일단 클린하지 않더라도 개발하기 급급한 사람으로서 깨진 유리창 이론, 매우 굉장히 찔리는데요.
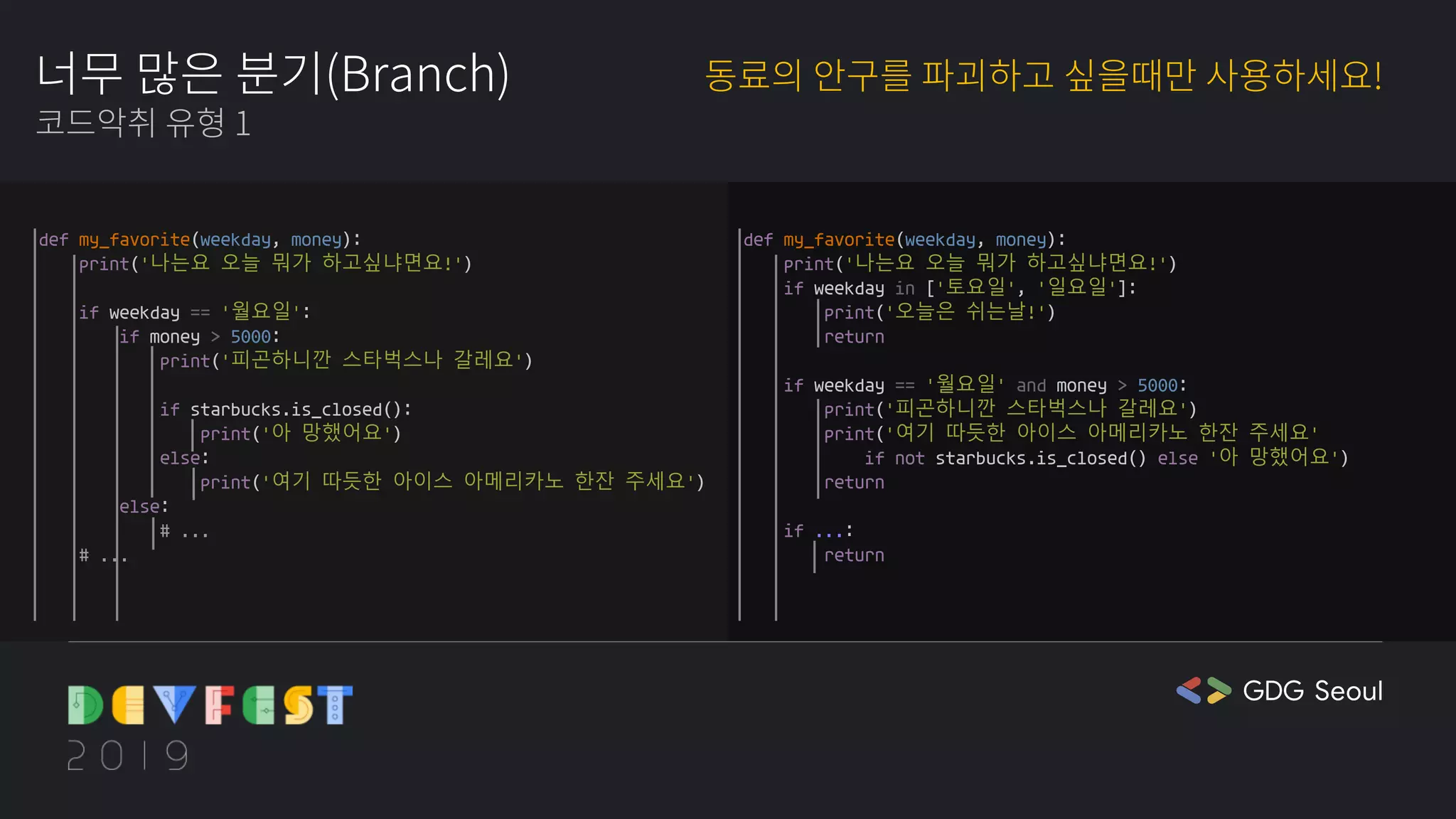
❤️🔥cathy: 맞아요. 이렇게 분기가 너무 많아지면 파이썬은 depth를 괄호로 묶지 않기 때문에 정말 힘들었어요. 이 부분을 깔끔하게 처리하는 게 매우 중요할 것 같아요(실제로 depth 깊은 분기 때문에 치명적 실수를 했던 사람의 당사자성 발언).
🍒chaen: 파이썬은 타입 선언도 하지 않아도 될 만큼 대충 코드를 작성해도 어떻게든 돌아가기 때문에 코드악취가 일어나기 쉬운 것 같아요.
❤️🔥cathy: 이런 식으로 if문을 쓰는 것을 코드 악취라고 하시네요. 굉장히 찔립니다. 제가 구현한 OAuth 로그인이 바로 딱 이런 방식이라서요!🤣 꼭 고쳐야겠어요.
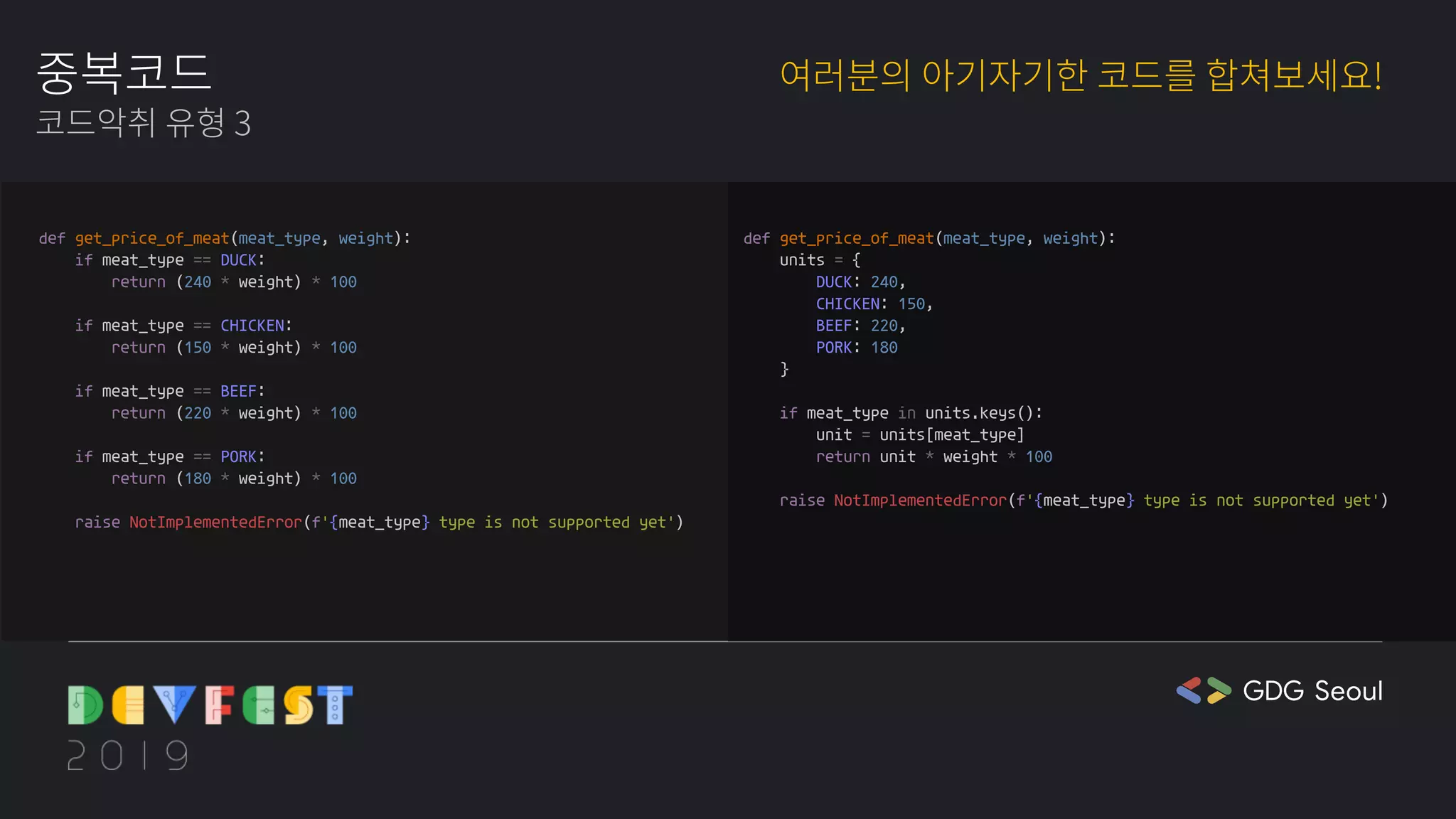
❤️🔥cathy: 제 눈에는 이 코드에서 하이퍼파라미터 선언하는 부분이 너무 더러워보여요. 이렇게 바꿔줘야 하는 변수는 따로 설정으로 묶어서 보여줘야 할 것 같아요.
🍒chaen: 그런가요? 저는 하도 AI 개발하면서 이상한 코드를 많이 봐서 그런지 하이퍼파라미터는 괜찮아 보여요.
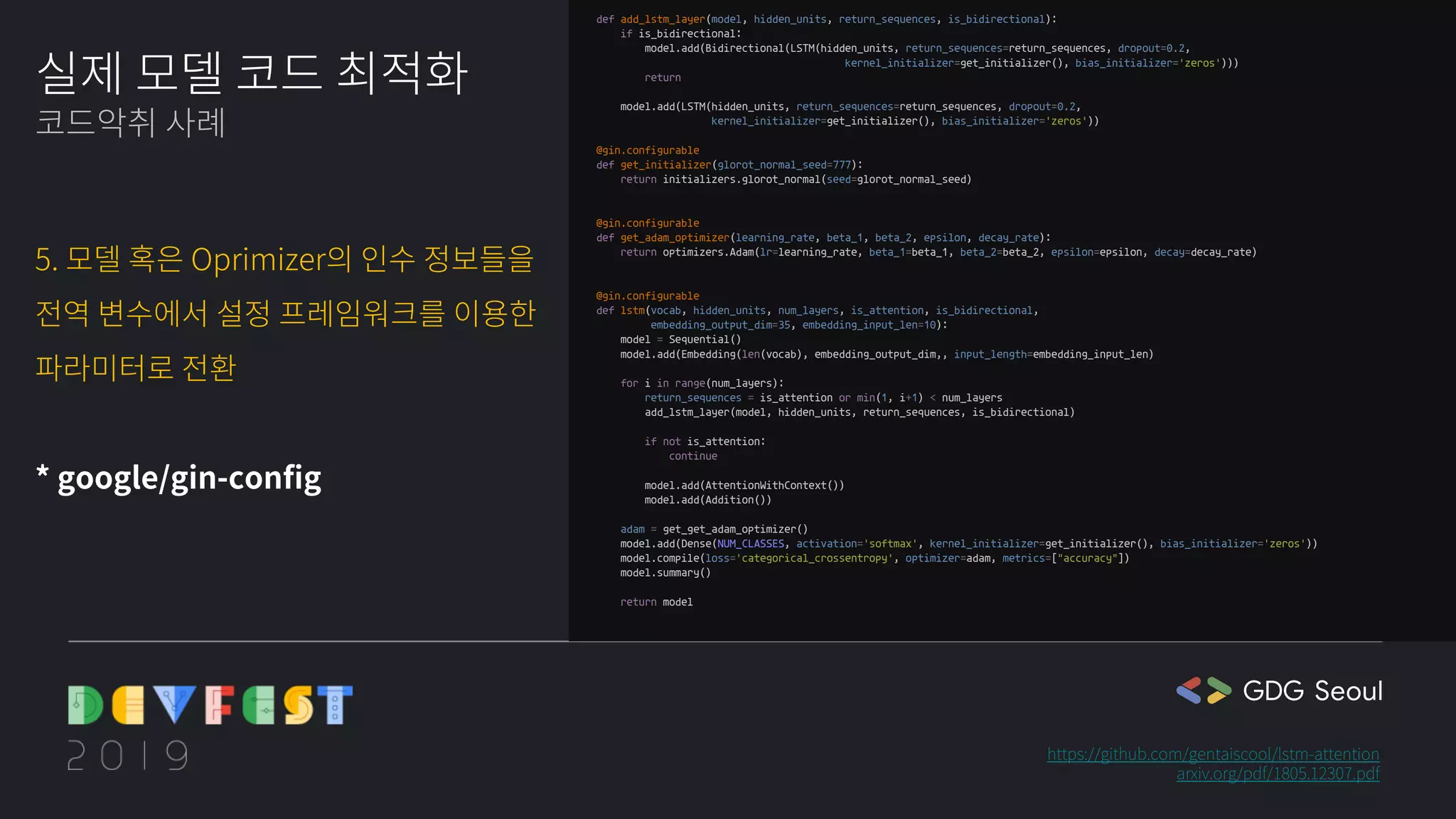
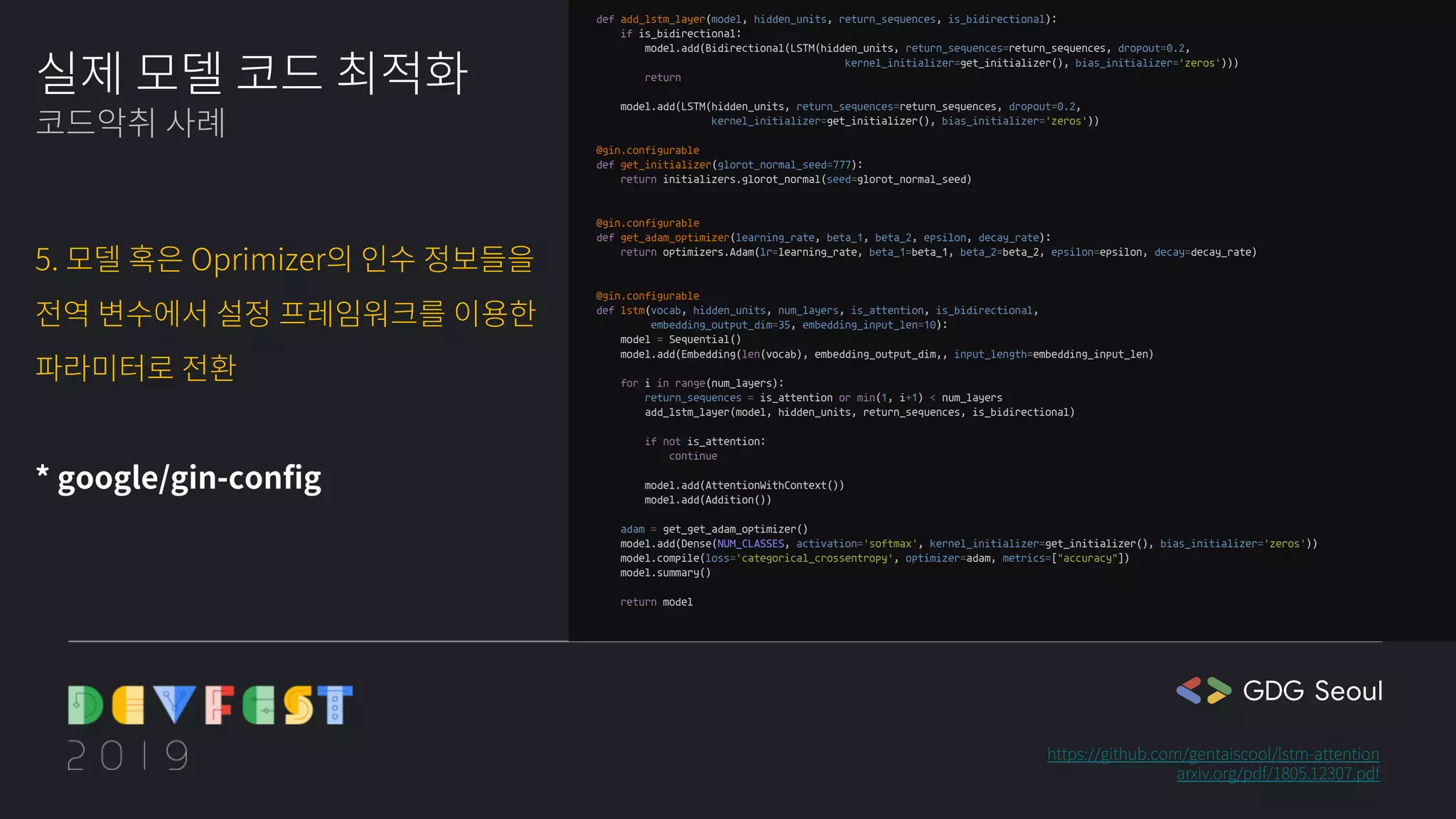
❤️🔥cathy: 코드가...더 길어졌어...!
🍒chaen: gin-config가 뭘까요? 처음 보는 거네요. (찾아 본 후) 구성 파일에서 매개변수를 제공해주는 거라고 하네요. 신기하다! 다음에 써보고 싶어요.
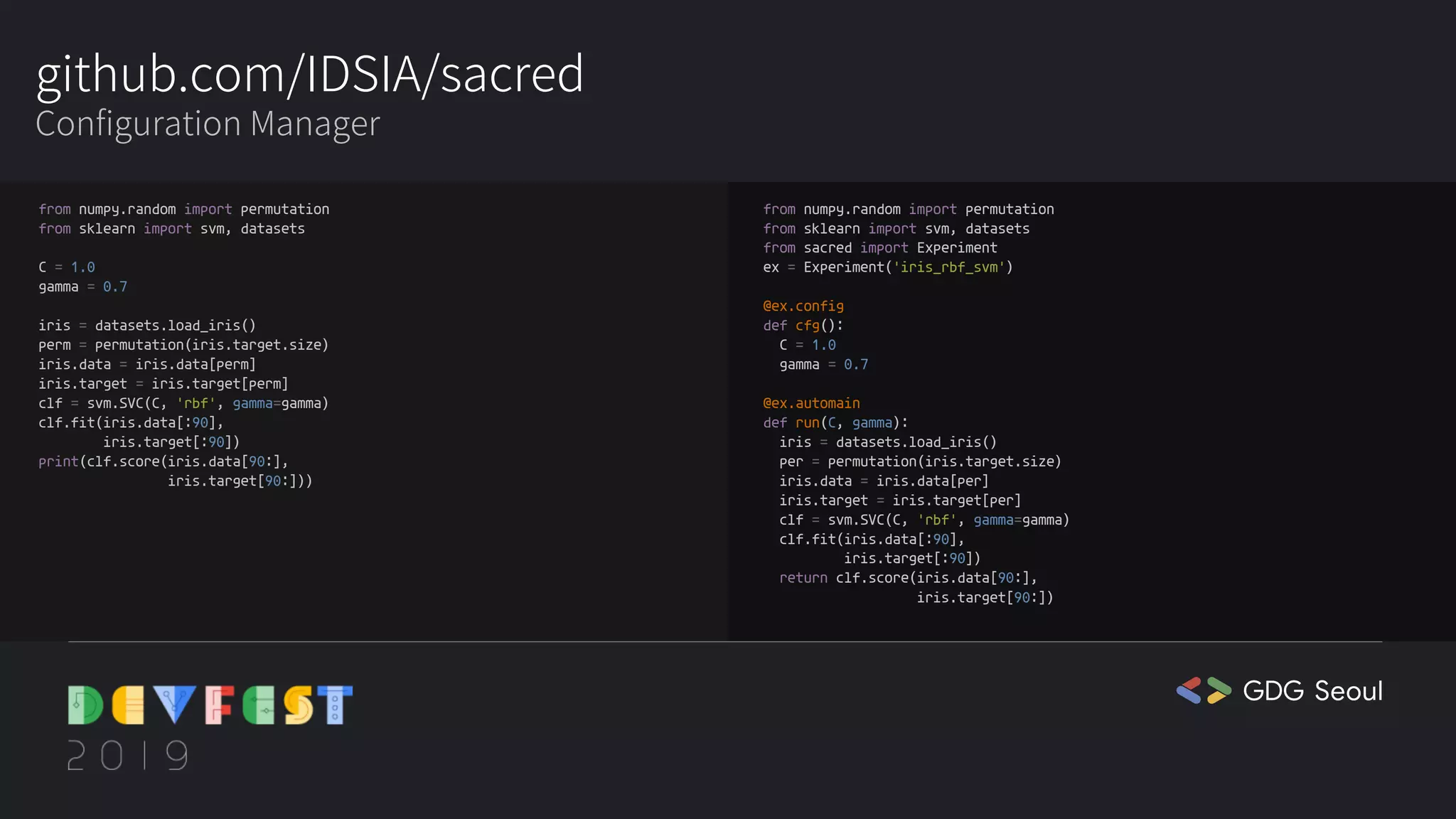
❤️🔥cathy: 처음 보는 게 또 나왔어요. IDSIA가 뭘까요?
🍒chaen: 실험을 구성, 구성, 기록 및 재현하는 데 도움이 되는 도구라고 깃허브에 나와있네요.
☕cora: 비슷한 역할인지는 모르겠지만, 프론트에도 커밋 날리기 전에 문법 등을 확인해주는 도구가 있어요.
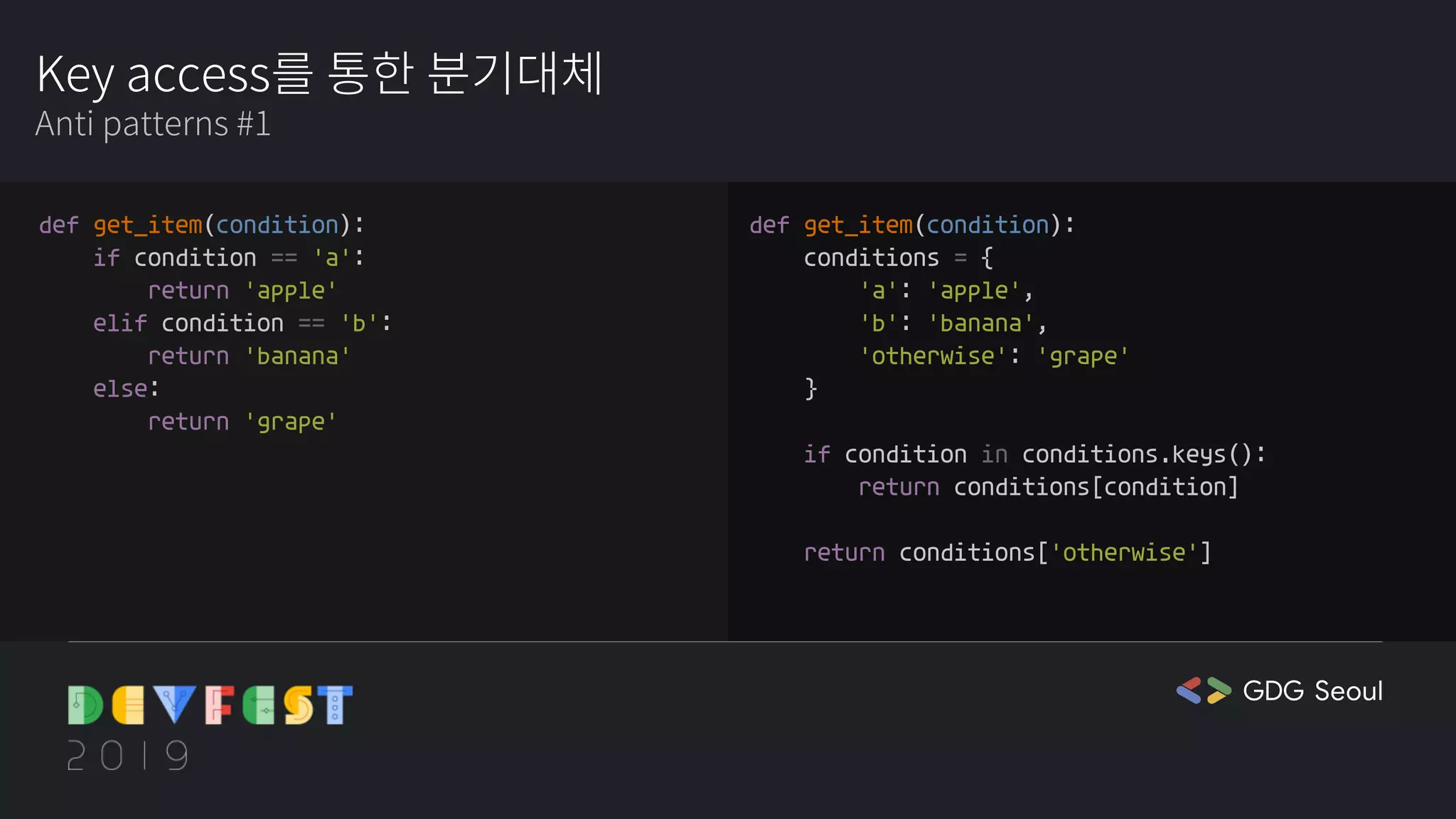
☕cora: 이거 정말 공감하는 부분이에요. 중복 코드 관련해서 최근에는 객체 처리하는 게 매우 중요하다는 생각을 해요. 프론트에서 하나의 객체를 만들어두면 굉장히 편리하게 재활용할 수 있는 경우가 많아서요.
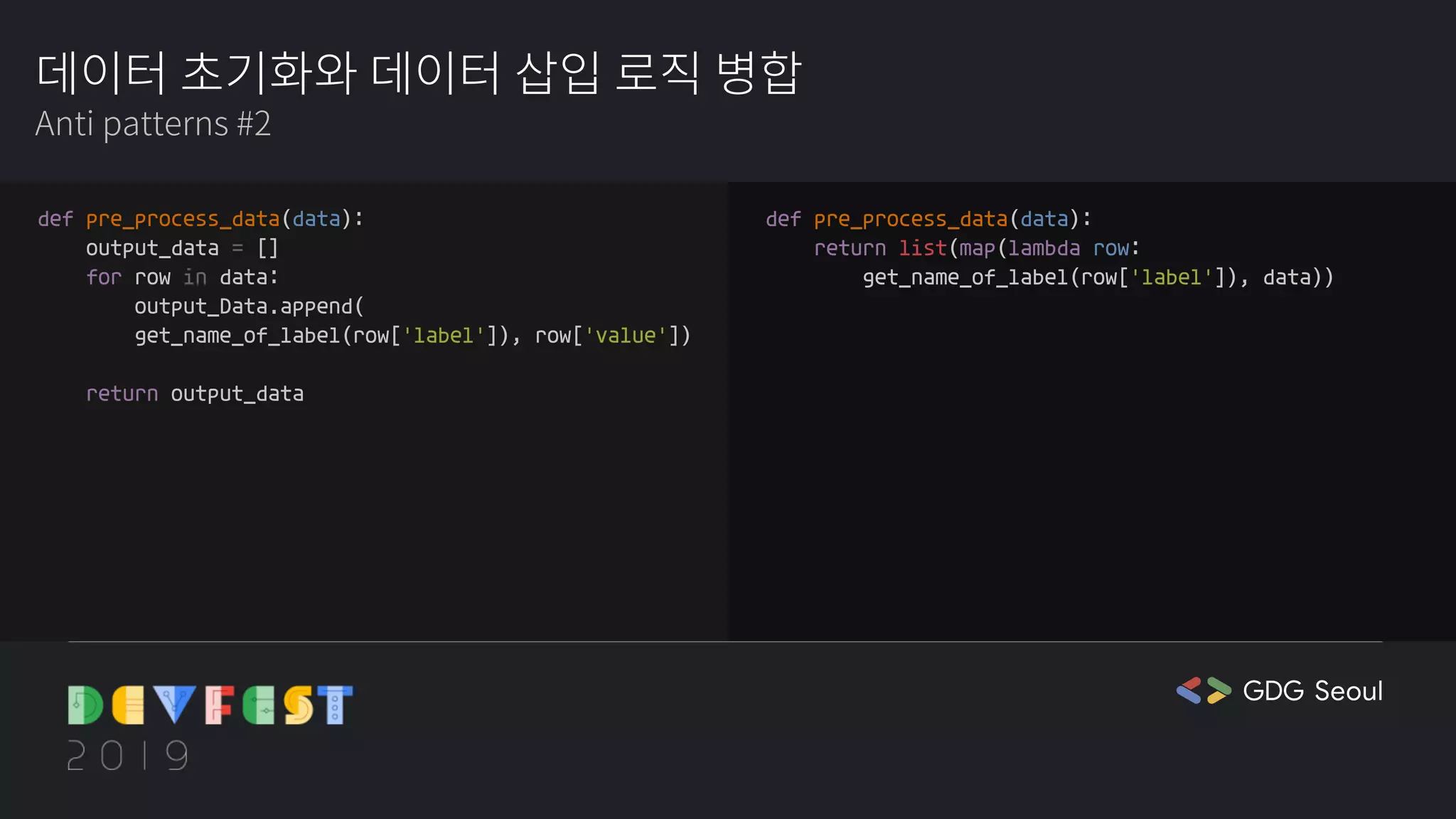
☕cora: 근데 저만 이렇게 생각하나요? 오히려 이렇게 lambda를 쓰는 게 무슨 뜻인지 한눈에 알기 힘들어서 별로인 것 같아요(웃음)
🍒chaen: 저도요. 개인적으로는 이렇게 map안에 lambda가 있고, 그 람다는 item을 리스트로 만들어주고, 이렇게 구구절절해 보이는 게 조금 별로에요. print문을 찍어가면서 디버깅하기도 힘들 것 같고요.
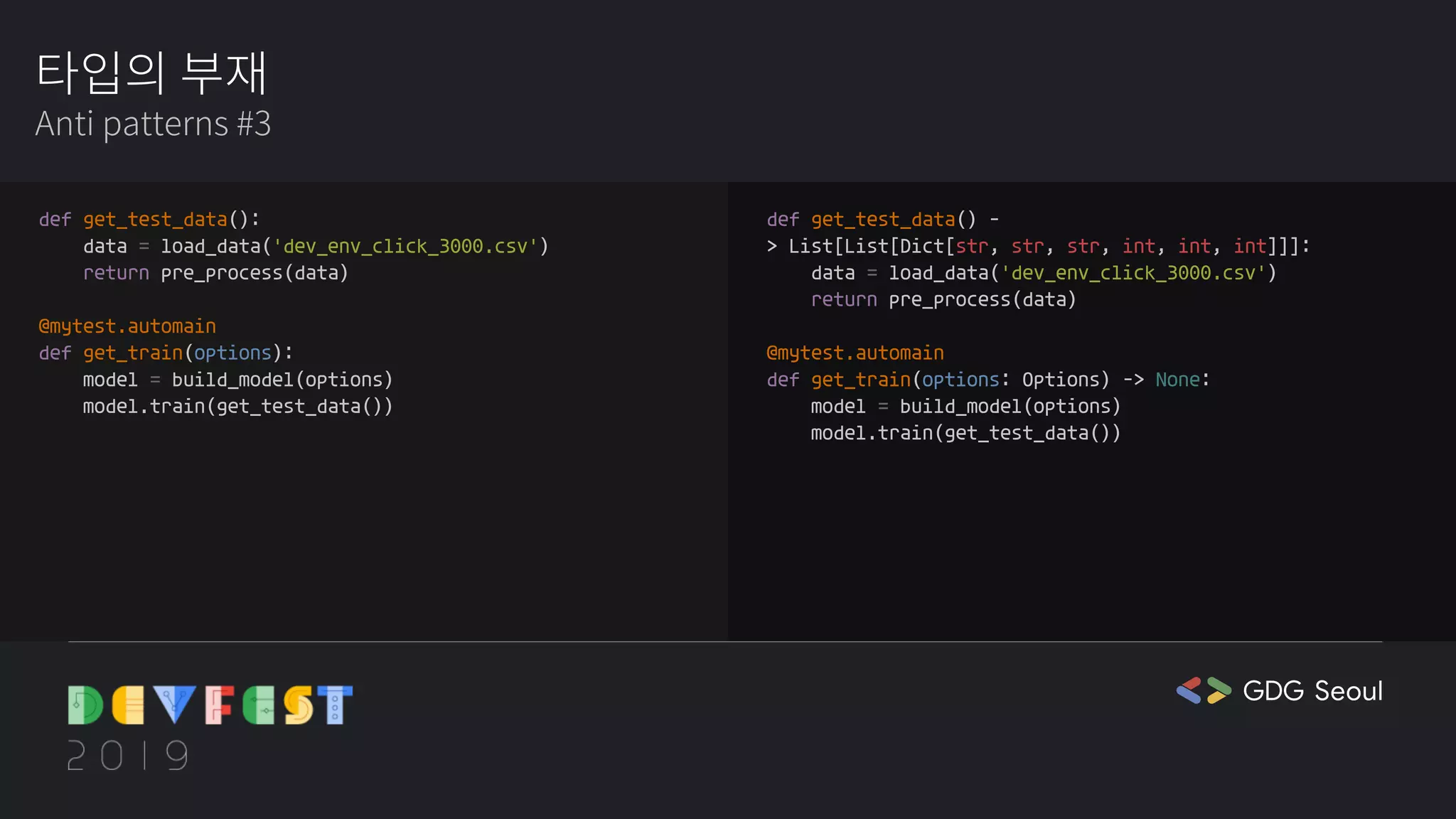
🍒chaen: csv 파일을 타입을 정해놓은 건 처음보는 것 같아요. 이렇게 타입을 명확하게 결정해야 할 이유가 있을까요? 오히려 에러가 나지 않을까요?
❤️🔥cathy: 저는 좋은 것 같아요. 빅데이터를 다루는 csv 파일은 엄청 무거워서 GUI로 안 열리는 경우가 아주 많고, 데이터를 열어보기도 힘든데, 이렇게 타입을 결정해놓으면 코드단에서 데이터의 형식을 확인할 수 있다는 장점도 있을 것 같아요.
☕cora: 이 부분은 고민되긴 하네요. 저도 프론트를 다룰 때 데이터 타입을 any로 할지, 아니면 백이랑 데이터 타입 다 결정해서 맞춰놔야 할지 항상 고민이라서요. 데이터 타입 관련해서는 고민되는 게 많은 것 같아요.
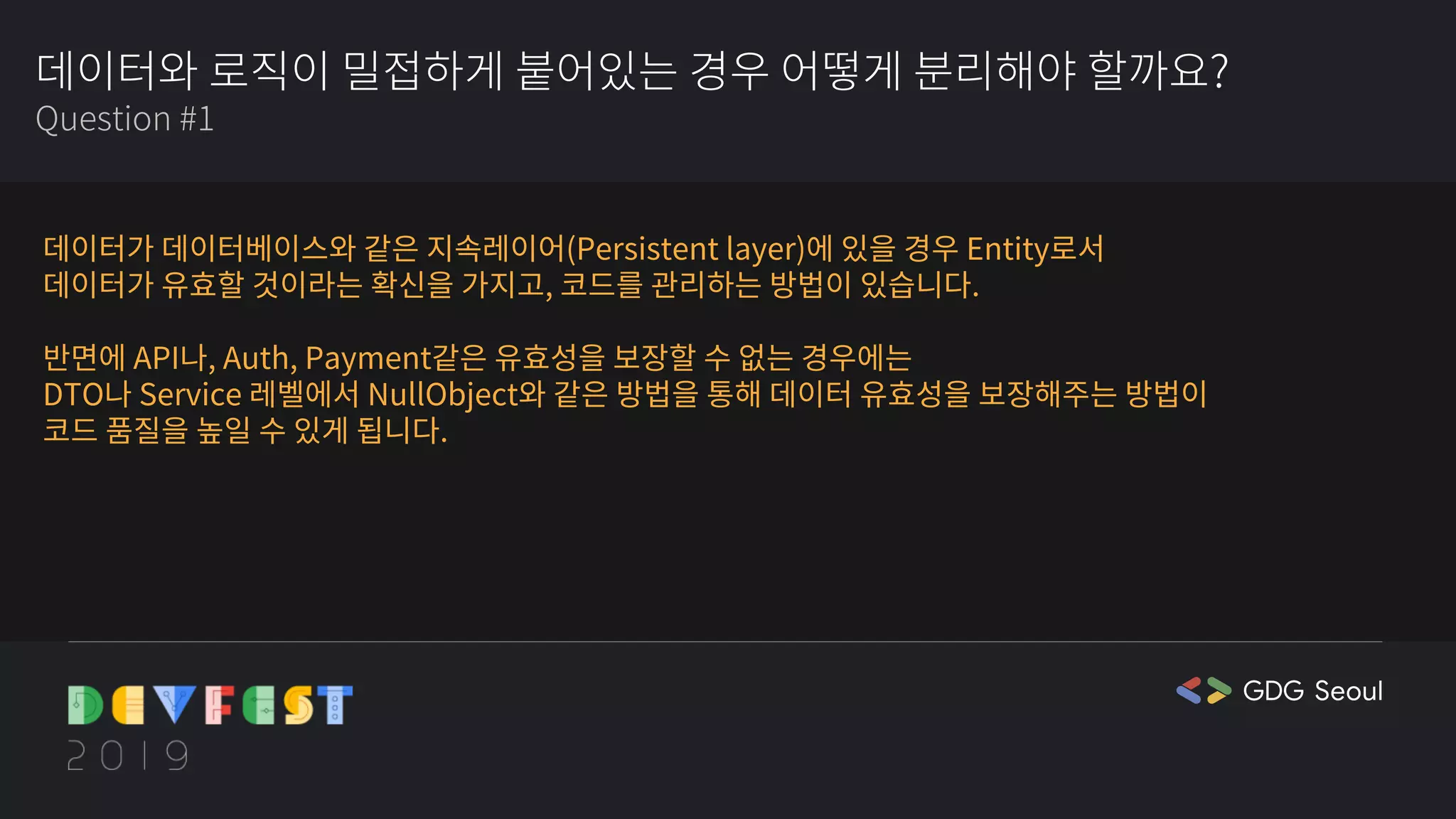
❤️🔥cathy: 이거 매우 좋은 질문에 좋은 답변이네요. csv일 경우에는 그냥 데이터가 유효할 것이라고 가정하는게 좋다는 게 실용적인 접근인 것 같아요. 실제로 AI 모델 개발할 때 만들어지는 csv는 깔끔하게 전처리한 데이터인 경우가 많고요.
