안녕하세요 chaen 입니다!
새로운 학기를 맞아 저희 팀은 주에 한 번 씩 미팅을 가져 유용한 칼럼을 읽어보는 시간을 가져보기로 했습니다.
이번에 공부한 주제는 "메달리온 아키텍처"입니다.
이번 주 읽은 글
- https://medium.com/@parklaus1078/medallion-architecture-bfc755c9dada
- https://aws.plainenglish.io/making-sense-of-the-aws-lake-house-architecture-ef0d8bc47897
작성 시 참고한 자료
레이크 하우스
레이크 하우스의 등장 배경
빅 데이터는 그 규모(Volume), 속도(Velocity), 다양성(Variety), 정확성(Veracity)의 네 가지 특징을 가집니다. 기업은 점점 더 많은 데이터를 생성하고 있으며, 이 데이터는 다양한 형태와 빠른 속도로 축적됩니다. 이러한 데이터의 폭발적인 증가는 기존의 데이터 처리 방식으로는 관리와 분석이 어렵다는 문제에 직면했습니다.
데이터 웨어하우스는 잘 구조화된 데이터에 대한 빠른 쿼리와 분석을 위해 설계되었습니다. 그러나 빅 데이터의 다양성과 복잡성은 데이터 웨어하우스가 처리하기에는 너무 크고 복잡하다는 특징을 가지죠. 보다 유연한 데이터 저장 및 관리 방식이 필요해짐에 따라 데이터 레이크가 등장했습니다. 데이터 레이크는 모든 유형의 데이터를 원시 형태로 저장할 수 있는 대규모 저장소로, 필요에 따라 데이터를 가공하고 분석할 수 있는 구조입니다.
비록 데이터 레이크가 데이터 웨어하우스의 한계를 극복하고 빅 데이터를 수용할 수 있는 유연성을 제공했지만, 여전히 데이터 레이크도 빅데이터를 처리하기엔 단점이 존재했습니다. 데이터 레이크 내의 데이터는 '데이터 스왐프(data swamp)' 혹은 '데이터 그레이브야드(data graveyard)'로 전락할 위험이 있습니다. 데이터 레이크에서 원하는 결과를 얻어내려면 전문적인 지식과 기술이 필요했기 때문에, 대부분의 사람들은 데이터 레이크 내의 데이터가 가치없다고 생각하게 된다는 것입니다. 또한, 데이터 웨어 하우스의 데이터가 이미 잘 정리가 되어있었기에 여기에서 벗어나기 어렵다는 점도 존재합니다.(data gravity)
데이터 레이크 하우스란
이러한 문제를 해결하기 위해 등장한 것이 데이터 레이크 하우스 아키텍처입니다. 데이터 레이크 하우스는 데이터 웨어하우스의 구조화된 분석이 편리하다는 장점과 데이터 레이크의 유연성을 결합하여, 빅 데이터의 가치를 활용할 수 있는 접근 방식입니다. 이를 통해 복잡한 데이터 환경에서도 확장성, 유연성, 그리고 실시간 분석을 지원하면서도, 데이터 관리와 거버넌스를 강화할 수 있게 되었습니다.
메달리온 아키텍처란
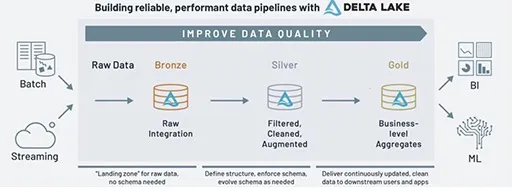
메달리온 아키텍처(Medallion Architecture)는 데이터 레이크하우스 환경에서 데이터를 체계적으로 관리하는 데 사용되는 데이터 디자인 패턴입니다. 이 아키텍처는 데이터의 구조와 품질에 따라 동(Bronze), 은(Silver), 금(Gold)의 세 가지 레이어로 분류하여 저장합니다.
Bronze Layer (Raw Data)
Bronze 레이어에는 외부 소스로부터 수집된 날 것의 데이터(raw data)가 저장되며, 이 데이터는 결측치나 분석 불가능한 값, 비정형 데이터를 포함할 수 있습니다. 데이터를 수집한 그대로(as-is) 저장합니다. 이 레이어는 빠른 변경 데이터 캡처(Change Data Capture, CDC)를 수행하고, 원본 데이터를 안전하게 보관하여 필요 시 언제든지 접근할 수 있도록 합니다.
Silver Layer (Cleansed & Conformed Data)
Silver 레이어는 정제되고 표준화된 데이터를 저장합니다. 결측치 보완, 중복값 제거, 데이터 타입의 일치화 등의 처리가 된 데이터가 저장됩니다. 분석가나 데이터 과학자가 사용하기에 적합한 형태로, Databricks에서는 이 상태의 데이터를 'just-enough' 처리된 상태라고도 합니다.
Gold Layer (Curated Business-Level Tables)
Gold 레이어는 비즈니스 분석에 사용이 가능한, 고도로 정제되고 구조화된 데이터를 저장합니다. 최종 사용자와 의사결정자가 쉽게 이해하고 사용할 수 있도록 데이터를 구조화하고, 데이터의 가치가 극대화된 형태입니다.
후기
이 주제는 제가 한 번 공부해보고 싶다고 제시하였는데요! 사실 학생의 입장에서 엄청나게 큰 데이터셋도, 혹은 장기적인 서비스 개선이나 분석을 위한 프로젝트 설계도 아직 경험해본 적이 없어 조금 생소했습니다. 팀원들과 함께 이 주제에 대해 이야기 해볼 수 있어서 훨씬 즐겁게 공부했던 것 같네요. 이 위클리 스크럼이 장기적으로 저희의 발전에 도움이 되길 바랍니다😍
