
Deploy
Planet Scale
Planet Scale에 처음 만든 branch는 main의 이름을 가지고 있으며 단 하나만 존재한다. 개발 환경에서는 상관 없지만, 개발 시에 쓰던 데이터베이스를 실제 서비스와 혼용해 사용하고 싶지는 않을 것이다. 때문에 배포용 DB와 개발용 DB branch를 나눠야 한다.
배포용 branch 생성

해당 DB의 overview에서 promote a branch to production을 클릭한다. production으로 설정한 branch는 직접적인 스키마 변경으로부터 보호되고, 효율성이 높아지며, 자동 백업된다.
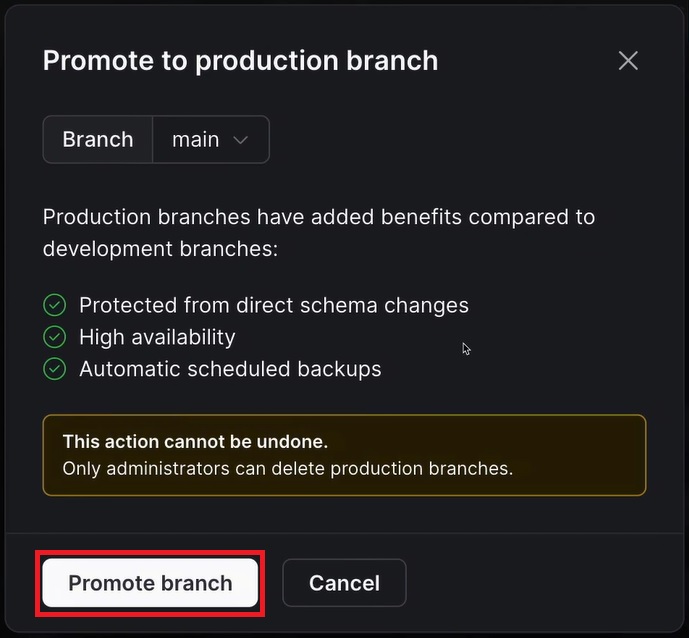
Promote branch를 클릭한다. 이렇게 설정된 production branch는 개발 환경에서의 npx prisma db push를 사용할 수 없게 된다.
개발용 branch 생성
branch탭에서 New branch를 클릭해 새 branch를 만든다.
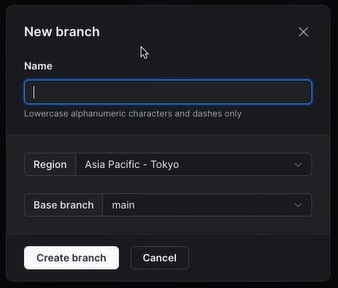
생성한 branch 명이 test라고 하면, pscale connect main-database test로 연결할 수 있다.
이렇게 생성한 DB는 데이터가 존재하지 않는다. 당연하게도 Planet Scale에서 데이터까지 복사해주지는 않기 때문이다. 데이터가 필요하다면 데이터베이스 시딩(Database seeding)으로 더미 데이터를 생성하자.
Index
데이터베이스는 기본적으로 선형 검색을 한다. 데이터 요청을 받으면 처음부터 훑으며 해당 데이터를 가져온다. 데이터의 양이 많아질수록 시간 역시 선형으로 증가하기 때문에 효율적이지 않다. 그러한 부분을 방지하기 위해 데이터베이스에 Index를 정의하여 관리한다. 새로운 데이터가 추가되면 인덱스 역시 추가되고, 요청 시 인덱스부터 검색해 요청한 데이터를 찾는다.
prisma에서는 스키마 모델에 @@index([foreignKey])로 정의한다.
model Post {
id Int @id @default(autoincrement())
user User @relation(fields: [userId], references: [id], onDelete: Cascade)
userId Int
question String @db.MediumText
created DateTime @default(now())
updated DateTime @updatedAt
@@index([userId])
}배포용 DB와 개발용 DB를 연결하기 위해서 필요한 작업으로, 모든 SQL에 해당하는 기본이라고 한다.
이렇게 수정한 모델을 푸시하고, deploy request를 통해 main branch와 통합한다.
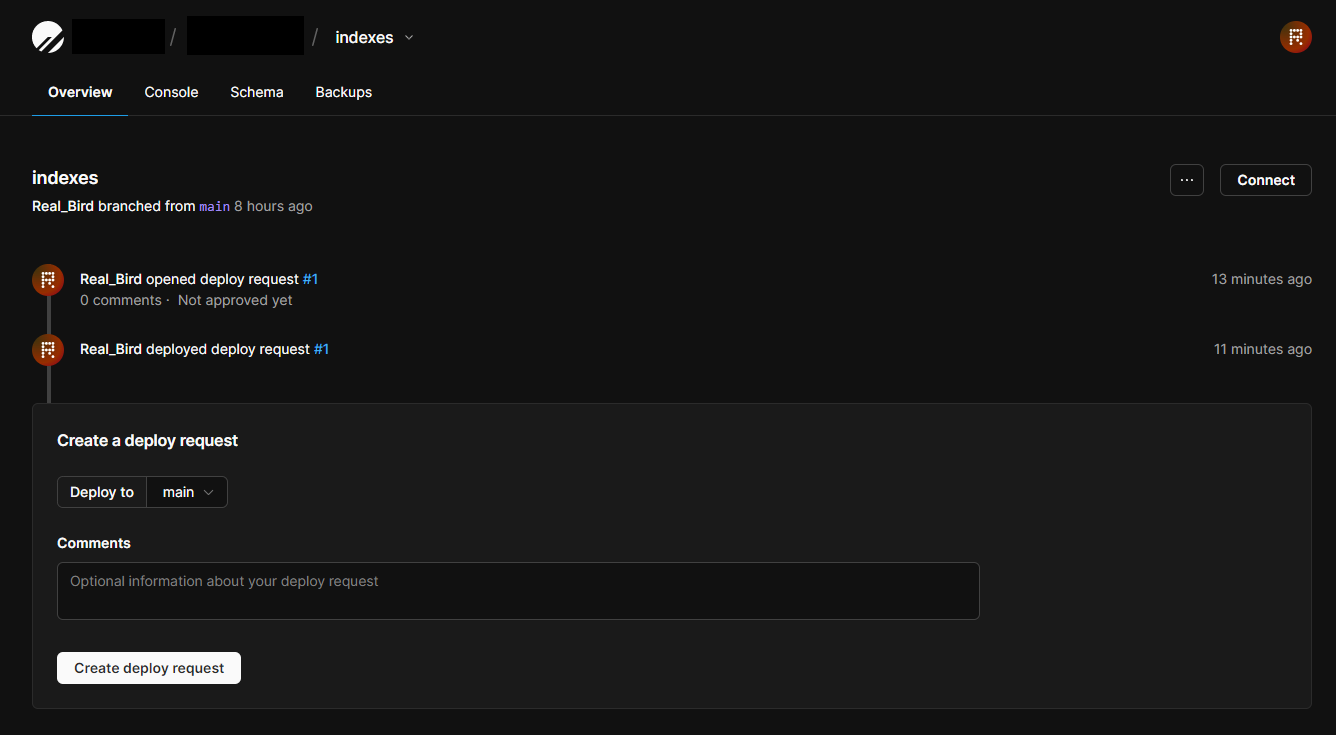
깃허브의 커밋처럼 배포할 branch 설정 후 코멘트를 달아 배포 요청을 클릭한다.
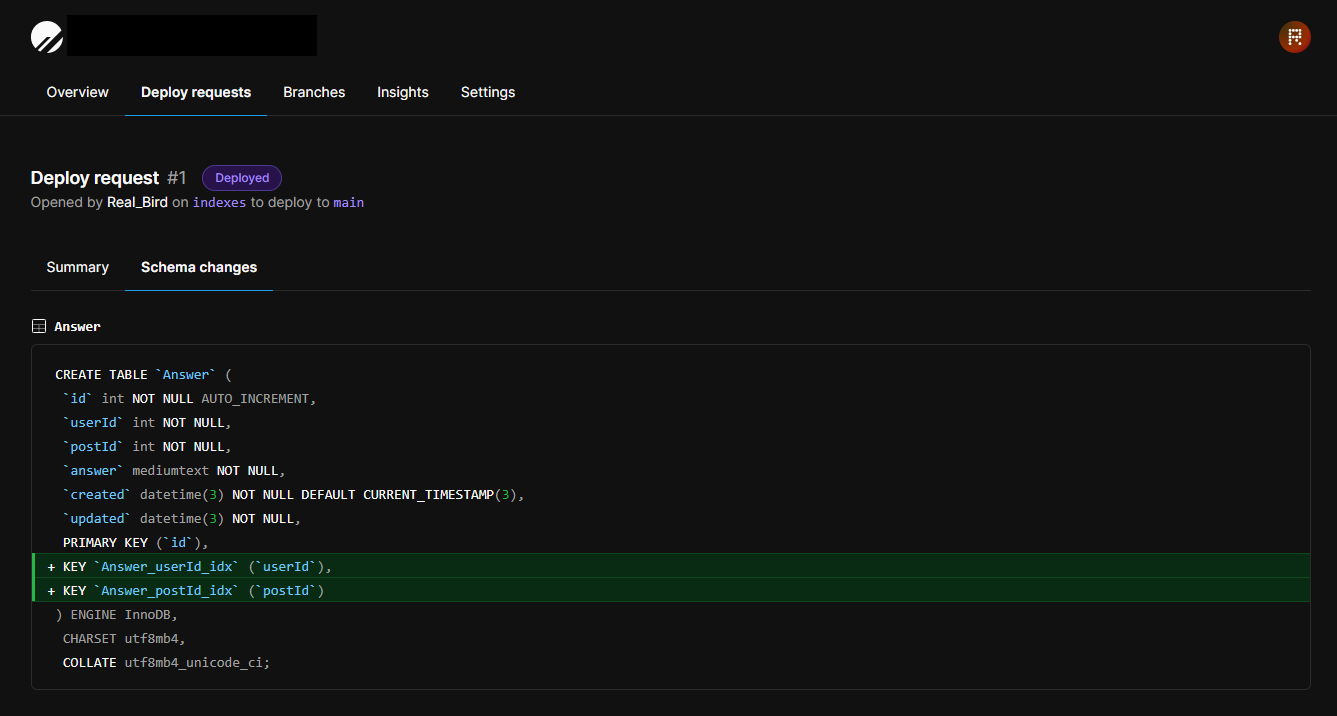
바뀐 부분 역시 깃허브처럼 확인할 수 있다. 배포 요청 또한 함께 작업하는 모든 개발자가 같은 버전의 branch여야 정상적으로 요청 가능하다.
