강화학습
1.Multi-armed bandit problem - (1) (feat. 호구 형님)

대분의 알고리즘들이 그렇듯강화학습의 궁극적 목적도 보상의 최대화이다. Multi-armed bandit 문제는 이 궁극을 잘 표현할 수 있는 사례이다.여기서 bandit이란 영화에서라도 한 번쯤 봤을 라스베이거스에서 흔히 레버를 당겨 도박할 때 사용하는 그 기계다
2023년 3월 22일
2.Multi-armed bandit problem - (2) coding
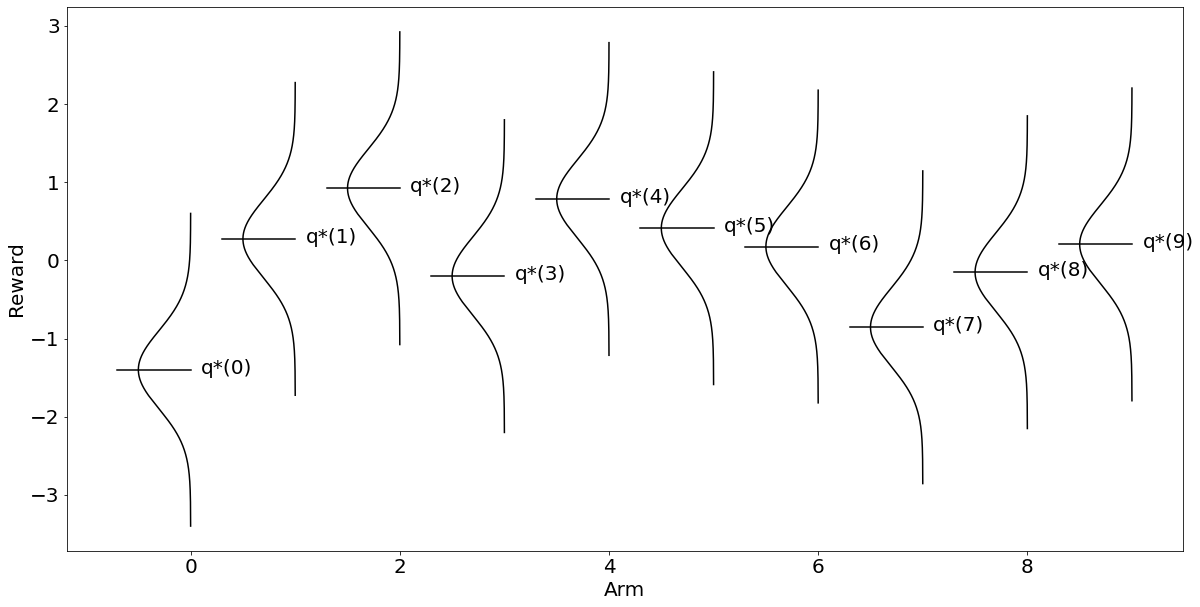
전편에 이어 multi-armed bandit을 Python으로 구현해보자.알고리즘은 greedy, $\\epsilon$-greedy, optimistic initial value 세 가지가 있었는데, greedy가 기본형이고 나머지 둘은 greedy의 단점을 보완하는
2023년 3월 23일
3.Finite Markov Decision Process - (1) (feat. kurly)
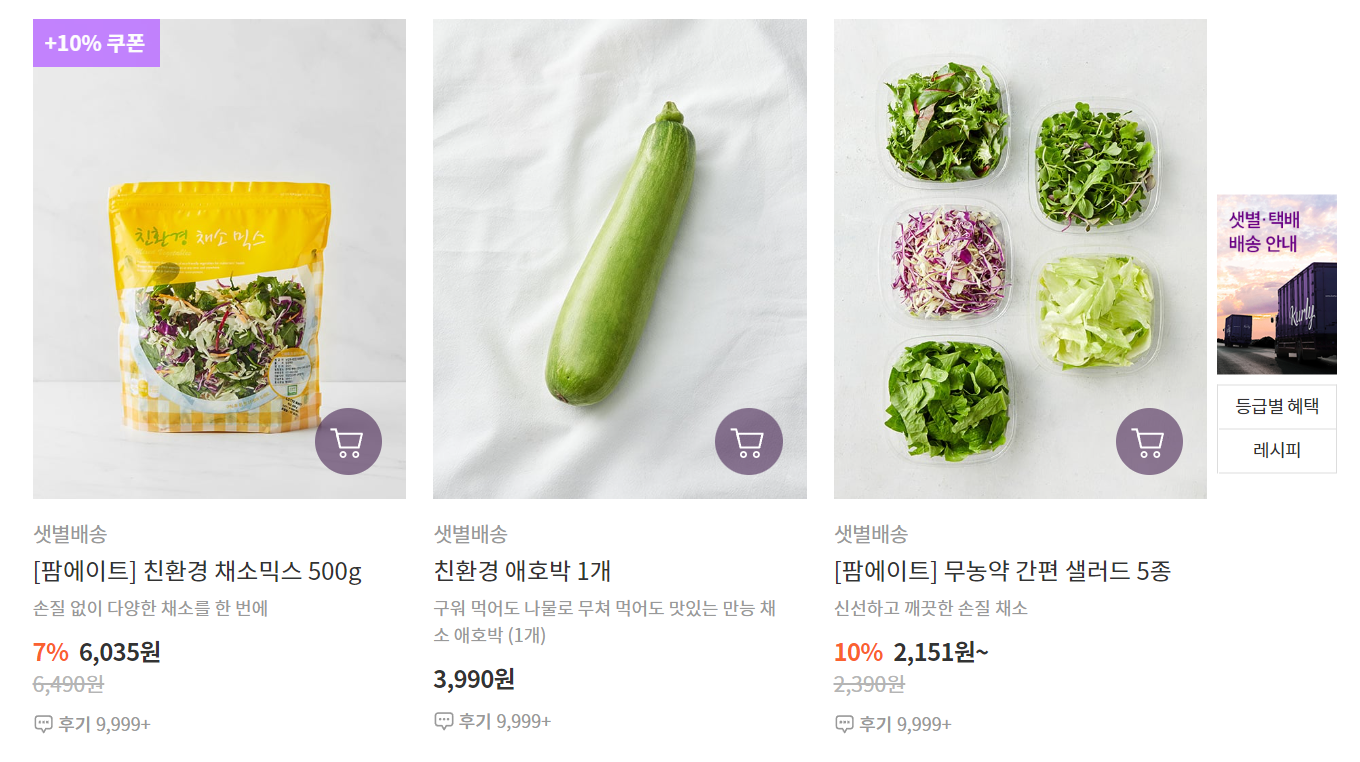
강화학습은 MDP를 푸는 알고리즘 중 하나이다. MDP는 Sequential Decision Process로도 불린다. 의사결정이 한 시점에서만 이뤄지는 것이 아니기 때문이다.($t= 0, 1, 2, 3,\\cdots$)$A{t} \\in A: Action \\;\\
2023년 3월 23일
4.Finite Markov Decision Process - (2) notation

앞서 Markov propery 개념을 이해했고, 이번 글은 본격 이론이라 notation들을 정의해둘 필요가 있다. 1. MDP dynamics 아래 함수는 현재 state가 $s$로 주어져 있고 $a$라는 action을 취했을 때 결과로 얻는 다음 시점 sta
2023년 3월 24일