유뷰브엔 연간 23억 명에 달하는 이용자들이 수많은 컨탠츠들을 생성하고 있다.
그런만큼 이런 데이터를 수집하고 분석하는 것이 필요한 경우가 많이 있다.
이때 유뷰브의 데이터를 대량으로 수집할 수 있는 방법은 대표적으로 2가지가 있다.
- 웹 크롤링
- API 활용
이 중 크롤링은 유뷰브 웹 사이트에서 보이는 정보를 모두 가져올 수 있다는 장점이 있지만, 시간이 많이 걸려 대량의 데이터를 수집할 때 문제가 될 수 있다. 또한 공식적으로 허락된 권한이 아니므로, 수익을 창출하는 등 활동을 할 경우 문제가 될 수 있다.
따라서
필요한 정보를 유뷰브에서 제공하는
공식 API를 활용해 수집할 수 있다면 베스트이다.
빠른 시간에 많은 정보를 얻을 수 있으며, 공식적으로 유뷰브에서 제공하는 정보이므로 문제가 될 가능성이 거의 없다.
1. 제공하는 정보 종류
API를 사용하기에 앞서서, 원하는 정보가 API로 제공되는지 확인하여야 한다.
API로 가져올 수 있는 대표적인 것들은 아래와 같다.
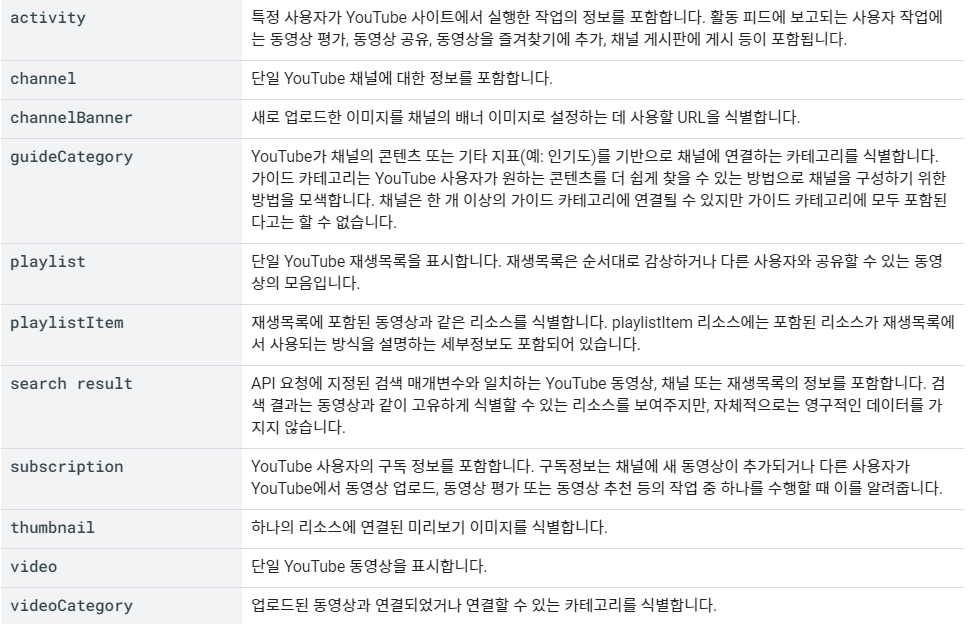
즉 위와 같은
검색결과, 재생목록, 채널, 영상, 카테고리, 썸네일 등
을 기준으로 영상별로
채널명, 재생목록, 작성날짜, 제목, 영상 설명문, 썸네일(url, 크기) 등
정보를 불러올 수 있다.
그 이외의 어떤 정보를 불러올 수 있는지 알고 싶으면 아래 링크를 참조하면 된다.
참조 : https://developers.google.com/youtube/v3/docs?hl=ko
2. API 사용을 위한 설정 - API 키 발급
1) 구글 계정 생성
- 대부분의 경우 이미 가지고 있는 구글 계정을 사용하면 된다.
2) Google 클라우드 플랫폼 접속
https://console.developers.google.com
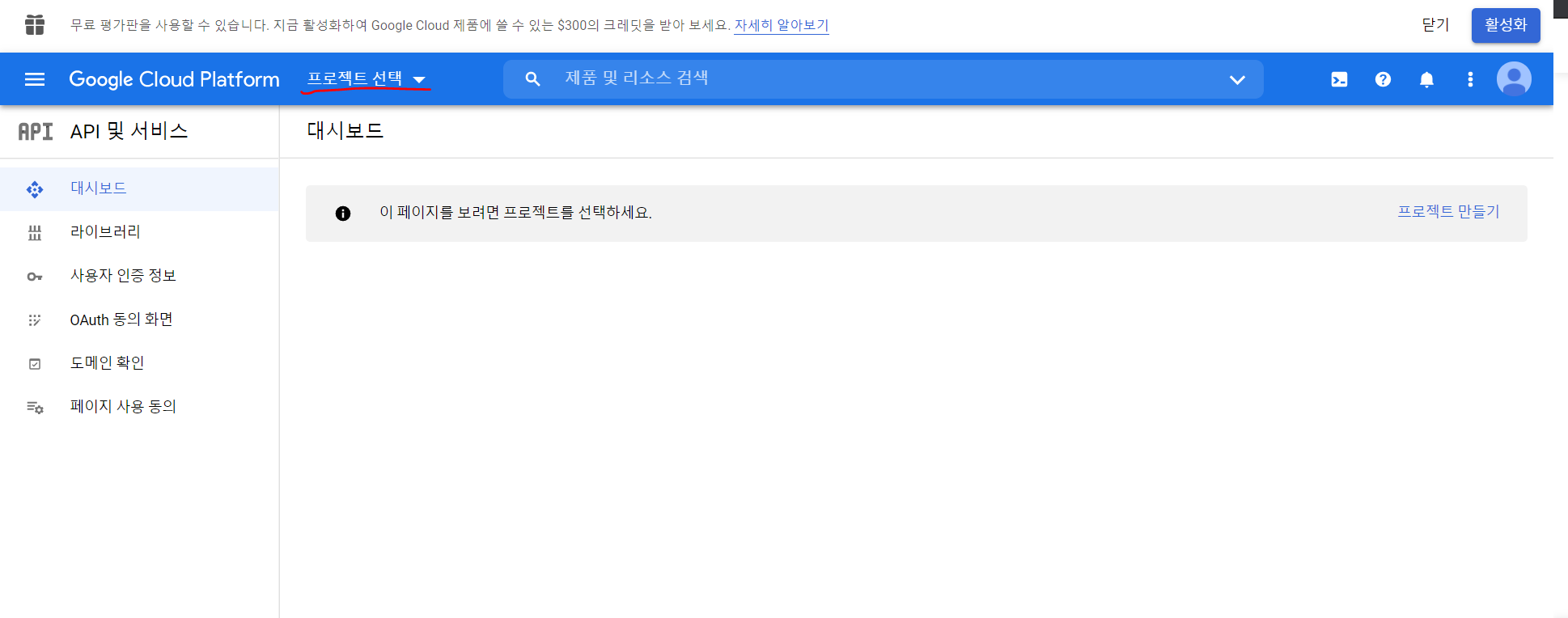
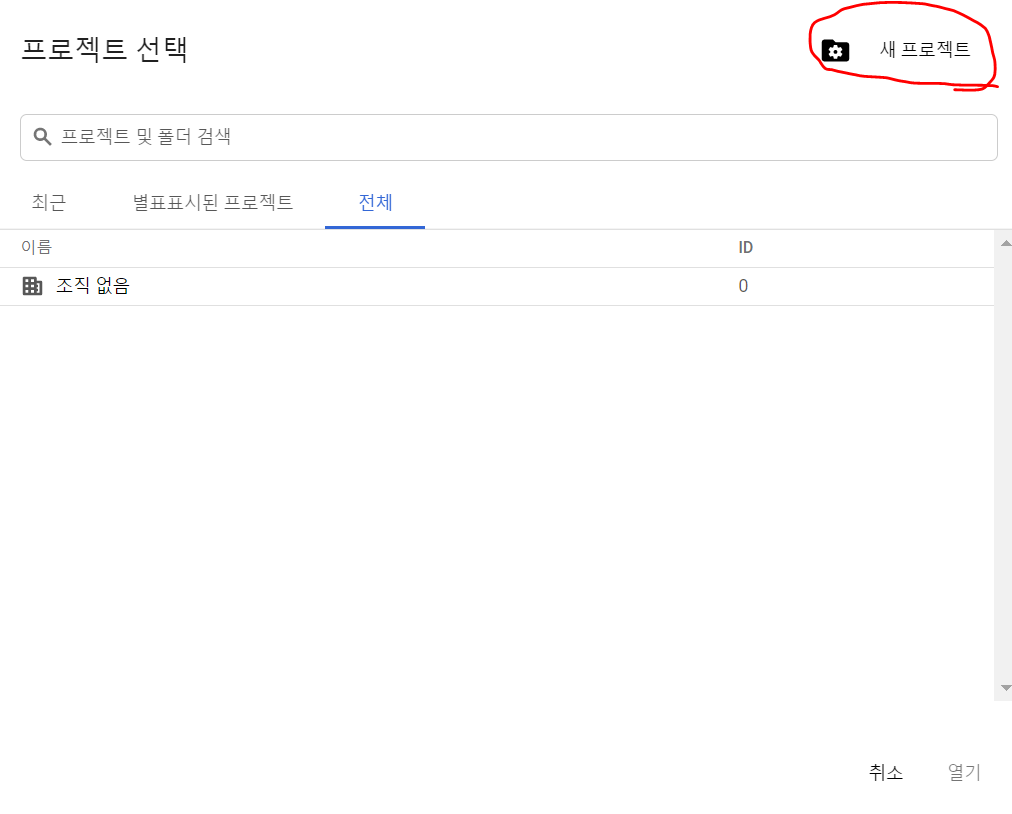
3) 프로젝트 만들기
프로젝트 선택을 눌러서
새 프로젝트 생성
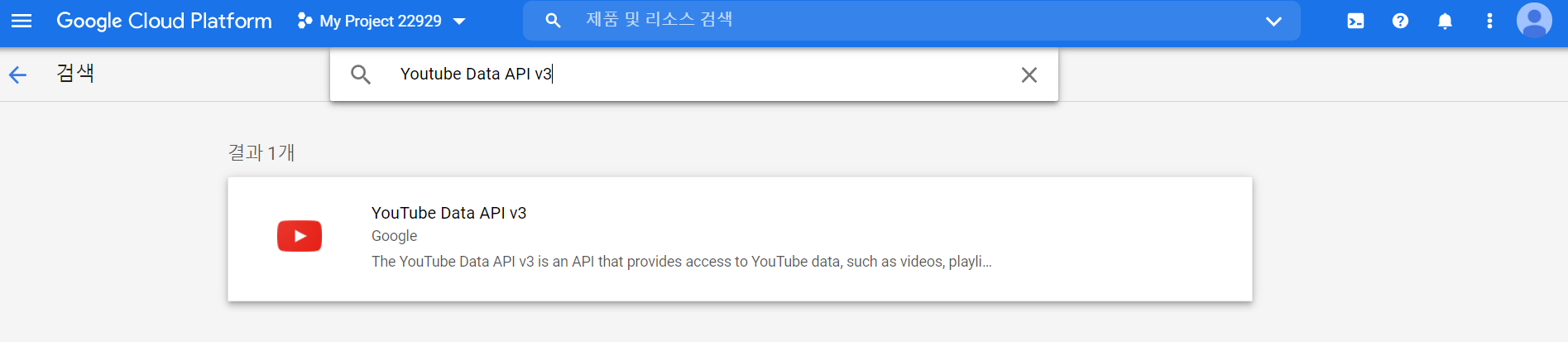
4) 프로젝트 사용 설정
API 및 서브시 사용 설정을 누르고

'Youtube Data API v3'를 검색해 선택한다.
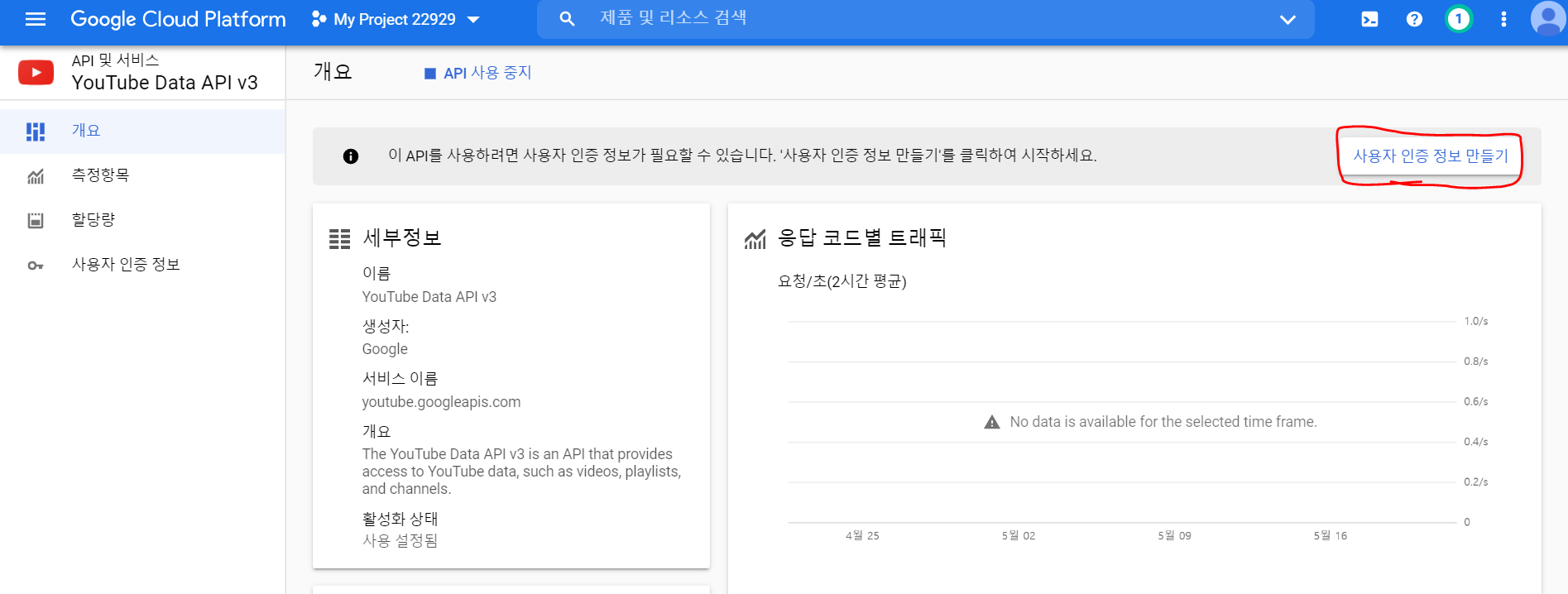
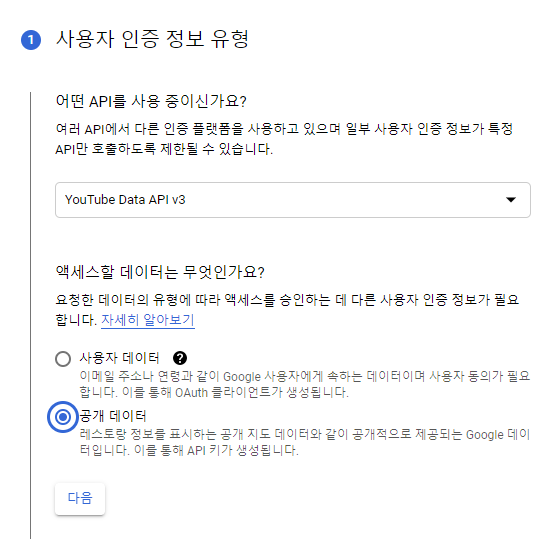
5) 사용자 인증
사용자 인증 정보 만들기를 눌러
정보를 설정한다.
이 과정을 완료하면

API키가 생성되었음을 확인할 수 있다.
3. API로 정보 불러오기
이제 코드를 사용하면 API로 Youtube에서 제공하는 정보를 불러올 수 있다.
https://github.com/youtube/api-samples
에서 샘플 코드를 제공하니 참조할 수 있다.
API를 불러오는 코드의 가장 기본적인 구조만 살펴보자.
Python으로 keyword를 검색한 결과를 가져오는 예로 들면 아래와 같다.
from googleapiclient.discovery import build youtube = build('youtube', 'v3', developerKey = '앞에서 발급받은 API_KEY')를 통해 유뷰브 API와 연결한다.
search_response = youtube.search().list( q = keyword, part = 'snippet', maxResults = 50 ).execute()이를 통해 api를 호출해 정보를 가져오고
for item in search_response['items']: channel_list.append(item['snippet']['channelId'])로 원하는 정보를 추출한다.
반복적으로 수행해서 더 많은 정보를 가져오고 싶다면
lsit()에서 변수로 page token을 활용할 수 있다.
예를 정리하자면
from googleapiclient.discovery import build youtube = build('youtube', 'v3', developerKey = '앞에서 발급받은 API_KEY') def get_youtube_channel_search_list(keyword): page_token = '' while (True): search_response = youtube.search().list( q = keyword, part = 'snippet', maxResults = 50, pageToken = page_token ).execute() for item in search_response['items']: channel_list.append(item['snippet']['channelId']) if ('nextPageToken' in search_response): page_token = search_response['nextPageToken'] else: break

기억은 내 대신 컴퓨터가...그렇죠 감사합니다 ㅎㅎㅎ