
Scene Text Recognition 이란?
1) 전통적인 OCR 과의 차이
- 전통적인 OCR은 일반적으로 문서의 글자를 인식하는 Task를 의미한다.
- 이 경우 대부분 아래와 같이 제한된 환경인 경우가 많다.
- 한 가지 색의 배경과 글자(ex. 흰 종이, 검은 글자)
- 정면 각도
- 한 가지 글씨채
- 이 경우 대부분 아래와 같이 제한된 환경인 경우가 많다.
- 반면 길가의 간판 등 일상 속 텍스트를 인식하고 싶을 경우 훨씬 다양한 경우의 수와 복잡한 배경이 주어진다.
- 기우러지거나 굴곡된 이미지가 많은 STD의 특성 상, 직사각형 형태의 bbox로 충분하지 않은 경우가 많다.
- 어떤 형태를 선택할 지도 성능에 많은 영향을 줄 것으로 보인다.
- 이런 테스크를 따로 자정하여 "Scene Text"라고 부른다.
2) Scene Text 과정
- Scene Text Detection : 글자 영역 찾기
- Scene Text Recognition : 영역 속 글자 인식
- End-to-End Scene Text Detection & Recognition(= Text Spotting) : Detection과 Recognition 전 과정
대표적인 Datasets
- ICDAR2015/3013/2003(테스크나 모델에 따라 최적의 버전이 다르다.)
- Total-Text(for Scene Text Detection)
- SVT(for Scene Text Recognition)
- MSDA(for Scene Text Recognition)
대표적인 모델
1) Scene Text Detection
A. EAST
- 가장 기본이 되는 Scene Text Detection 모델
- 기존 모델들이 Convolution 블록을 3~5차례 거치는 것과 달리, 하나의 Convolution 블록을 사용하여 연산 시간을 대폭 단축
- Fully Convolutional Network(FCN) 활용 -> 단어 포함된 Rotated Rectangle 또는 Quadrilateral box 예측
- U자 구조 사용 -> 보다 정밀한 Localization
- F1 score : ICDAR2015 기준 0.8072
- 현재의 SOTA models(약 0.9) 보다는 성능이 떨어지지만, 이후 End-to-End 모델에도 사용되는 등 Scene Text Detection 분야의 중요한 방향성 제시
B. TextFuseNet
Scene Text Detection의 SOTA (paper with code 기준)
- paper with code
: https://paperswithcode.com/sota/scene-text-detection-on-icdar-2015 - paper
: https://www.ijcai.org/Proceedings/2020/0072.pdf
2) Scene Text Recognition
- RNN 계열 모델을 주로 사용한다.
- 영역을 정확히 글자 단위로 나누기 어려움
- 잘린 영역만 보고, 정확히 어떤 글자인지 알기 어려움
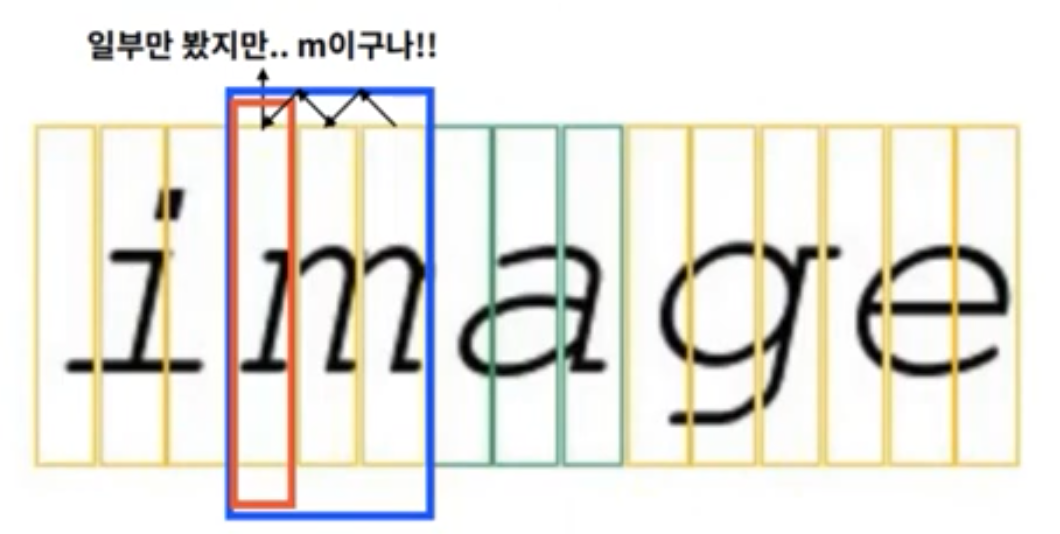
- Attention 모델들도 주목받고 있다.
A. CRNN
from "An End-to-End Trainable Neural Network for Image-based Sequencce Recognition and Its Application to Scene Text Recognition(Shi. et al., 2015)"
B. Yet Another Text Recognizer
- Scene Text Recognition의 Sota(paper with code 기준)
- paper with code
: https://paperswithcode.com/paper/why-you-should-try-the-real-data-for-the
3) Text Spotting(End-to-End Scene Text Recognition)
A. Fast Oriented Text Spotting with a Unifed Network(FOTS)
- East와 CRNN 모델을 하나로 합친 모델
- 연산 시간이 굉장히 줄어듦
- ROI Rotate
- Detection 부분과 Recognition 부분을 연결
- 추출된 글자 영역들의 높이를 일정하게 맞추고 수평을 맞춘다
- Shared Convolution
- 각 단계에서 쓰이는 정보를 교차로 사용할 수 있게 함 -> 따로 할 때보다 성능이 올라간다
출처

기억은 나 대신 컴퓨터가