 인공지능 학습 시, 다량의 양질의 데이터셋 확보는 가장 중요한 작업 중 하나이다.
인공지능 학습 시, 다량의 양질의 데이터셋 확보는 가장 중요한 작업 중 하나이다.
이번엔 OCR 중 하나인 Scene Text 테스크를 위한 데이터를 정리해보자.
0. 빠르게 따라하기(전체 요약)
- 무료 데이터 다운로드
🔗 ICDAR 2015 다운로드
🔗 ICDAR 2017 다운로드 - 데이터 전처리 : Annotation 형식 통일, 인식 가능한 문자만 남기기
🔗 ICDAR 2015용 변환 코드
🔗 ICDAR 2017용 변환 코드 - 데이터 합치기
🔗 파일 통합 코드
1. 필요한 데이터셋 정의
목적에 따라, 필요한 정보를 정의해야 한다.
나는 영상 배경의 영어 문자를 인식해서, API로 한글로 번역하고, 번역 결과를 이미지에 합성하는 작업을 하고자 하였다.
따라서 알파벳 문자를 포함하는 일상 이미지가 필요하다.
또한 Scene Text 테스크의 경우, 글자의 위치를 찾는 Detection과 그 속 문자가 무엇인지 인식하는 Recognition 2단계로 진행된다. 따라서 이미지 별로 아래 2가지 정보가 필요하다.
- Detection을 위한 Bounding Box 좌표
- Recognition을 위한 알파벳 문자 annotation
2. 데이터 셋 찾기 - ICDAR 2015
양질의 데이터를 다량으로 확보하는 가장 좋고 쉬운 방법은 공개된 데이터셋을 사용하는 것이다.
이 경우 아래와 같은 장점이 있다.
- 대량의 데이터셋을 단기간에 확보 가능
- 직접 Labeling을 하지 않아도 됨(엄청난 시간 단축)
- 목적에 따라 정제된 데이터 확보 가능
먼저 Scene Text의 대표적인 공개 데이터셋을 살펴보자.
논문들을 비교해 볼 수 있는 사이트인 paper with code에서 Scene Text 의 상위 논문들을 검색해보면 아래와 같다.
이를 살펴보면, ICDAR 데이터셋이 가장 많이 사용됨을 볼 수 있다.
따라서 우선 해당 데이터셋을 살펴보기로 한다.
Recognition 테스크의 SOTA 논문에서 활용된 ICDAR 2015 의 Annotation Format을 살펴보면, 아래와 같다.
x1,y1,x2,y2,x3,y3,x4,y4,Text예를 들면, 이미지 별로 아래와 같은 Annotation 파일을 가지고 있다.
789,415,816,417,817,472,790,471,BEAST
737,330,762,329,762,355,737,355,CITY
737,315,762,315,761,329,737,328,###
303,507,399,514,415,573,319,566,$20
765,338,791,338,792,354,765,354,###
764,308,791,309,792,335,764,334,LOST
406,650,455,652,452,663,403,662,FOOD이를 보면, Bounding Box 좌표와 Text 내용을 모두 가지고 있다.
또한 Text는 모두 영어 데이터이다.
이미지도 살펴보면 아래와 같이 영어 문자를 포함한 일상 이미지이다.

적합한 정보를 모두 포함하였으므로, 해당 데이터셋을 활용하기로 한다.
이 데이터셋은 아래 링크에서 무료로 다운로드 할 수 있다.
🔗 ICDAR 2015 다운로드
3. 데이터 늘리기 - ICDAR 2017 추가
ICDAR 2015로 학습을 하다보면, 한 가지 문제를 발견하였다.
바로... 오버피팅(Overfitting)이다.
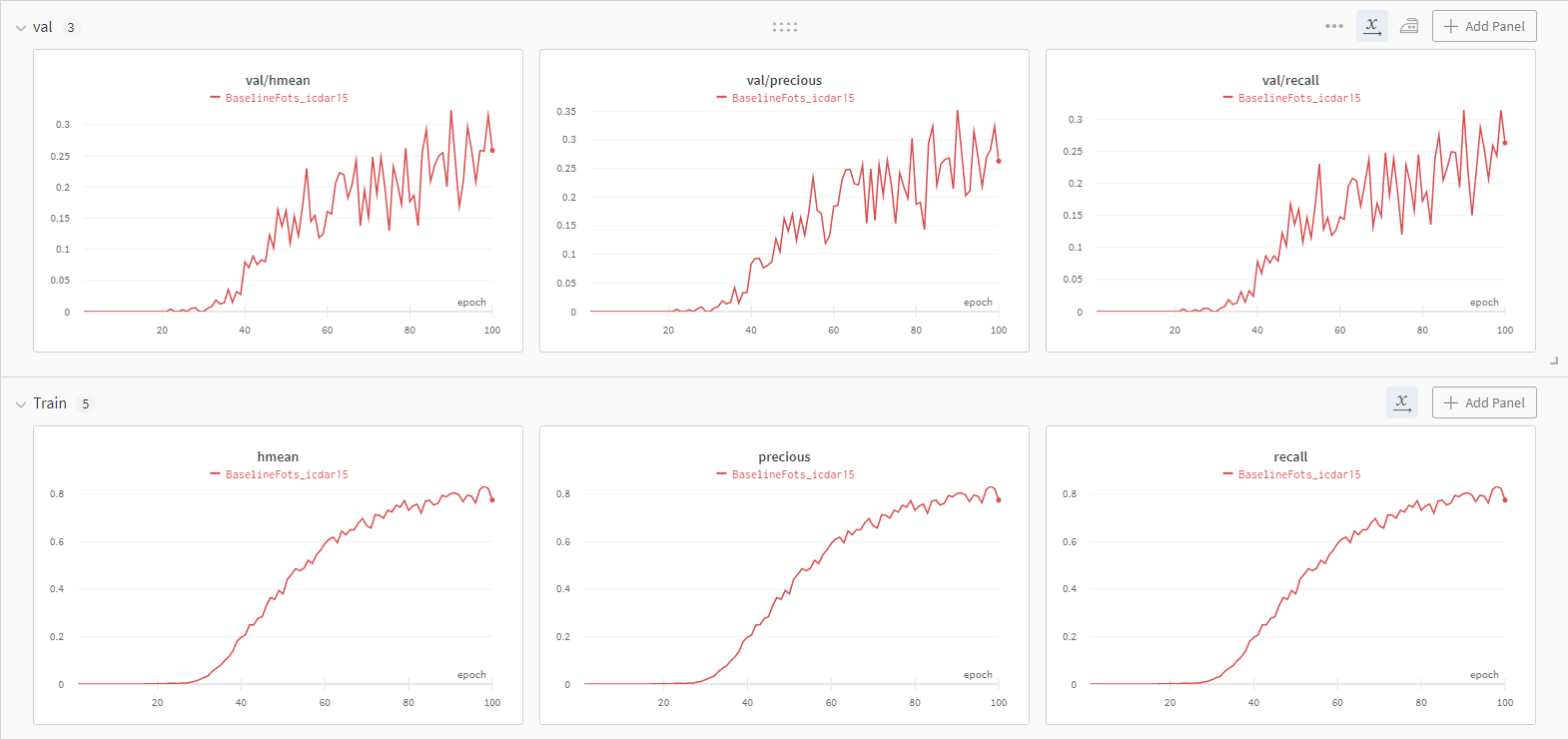
Train 데이터의 precision, recall, f1-score(hmean)이 0.8가량에 달할 때 까지, Valid는 0.3 가량에 머무르는 것이다.
ICDAR 2015의 Train Data 이미지가 1000개로 일반적인 딥러닝 학습에 사용하는 양보다 현저히 적음을 고려하면, 이미지 부족으로 인한 오버피팅 상황을 예측해 볼 수 있다.
따라서 데이터를 추가해보기로 하였다.
ICDAR 2017의 경우, Train Image 7200개, Valid Image 1,800개로 데이터 수가 훨씬 많다.
또한 Annotation 형식은 아래와 같이, ICDAR2015에서 언어 정보만 추가된 형식이다.
x1,y1,x2,y2,x3,y3,x4,y4,Language,Text따라서 해당 데이터셋을 추가하기로 하였다.
ICDAR 2017은 (2015와 마찬가지로) 아래 링크에서 무료로 다운로드 할 수 있다.
🔗ICDAR 2017 다운로드
데이터를 추가한 결과, Valid 성능이 향상되고, Train과 Valid의 격차가 감소하였다.
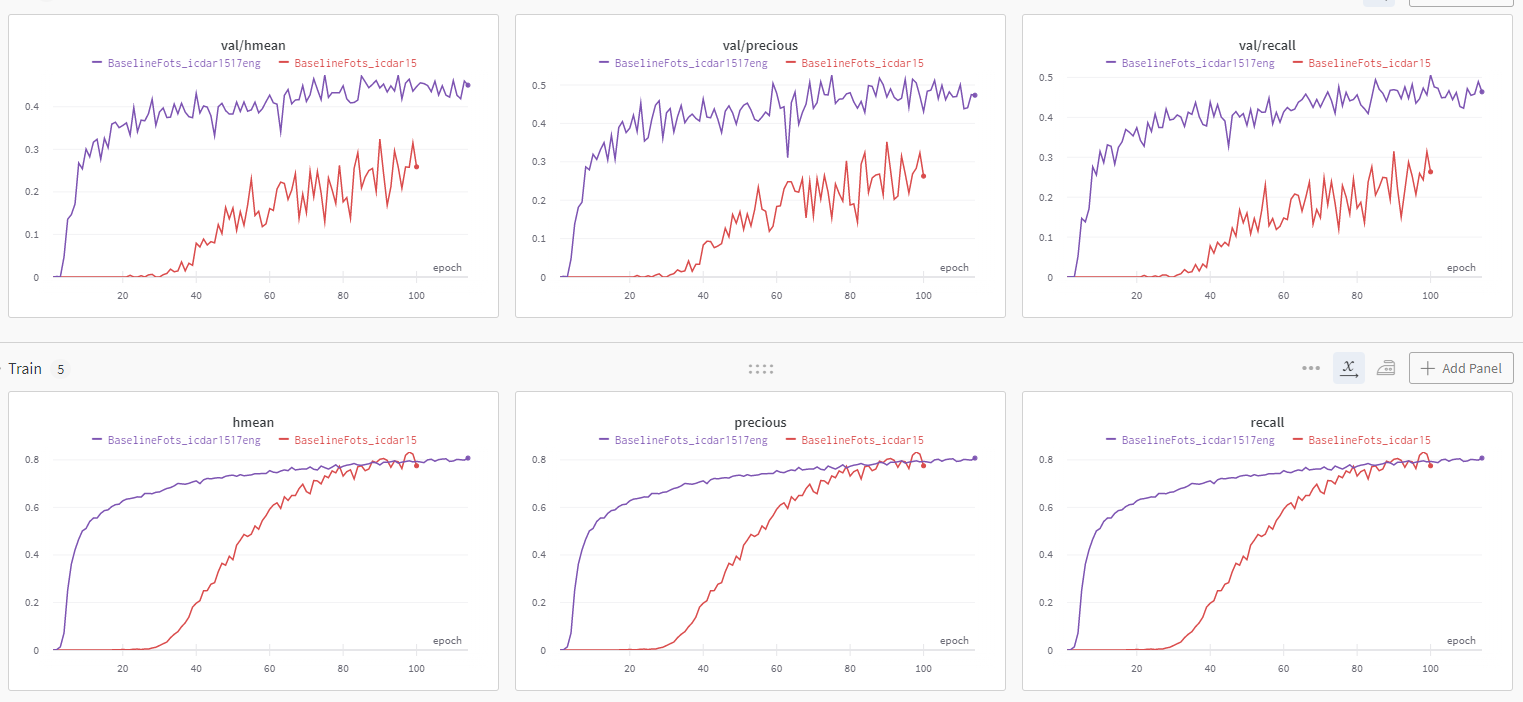
4. 영어 데이터만 남기기
- 이 글은 ICDAR 2017 기준으로 작성하였다.
- ICDAR 2015는 동일한 방식으로 진행하되, Language를 'Latin'으로 가정한다.
1) 모델이 인식할 문자(regular_char) 종류를 정의한다.
- 숫자(0-9)
- 영문알파벳(a-Z)
- 키보드로 입력 가능한 특수문자(`=;,./~!@#$%^&*()_+|:<>?°·£¥₩€-[]'"{})
regular_char = re.compile(r"[ 0-9a-zA-Z`=;,./~!@#$%^&*()_+|:<>?°·£¥₩€\-\[\]\'\"\{\}\\]")2) 특정 단어가 인식 가능한지 확인하는 함수를 만든다.
위에서 정의한 regular_char 이외의 문자가 있으면, False를 return 한다.
def check_possible_word(word) -> bool:
for char in word:
if not regular_char.match(char):
return False
return True3) 유사한 문자 합치기
인식 가능한 문자(regular_char)와 유사한 모양인 다른 문자들을 찾아서 매칭한다.
trans_char_dict = {
'À':'A', 'Á': 'A', 'Â': 'A', 'Ã': 'A', 'Ä': 'A',
'Ç':'C', 'È':'E', 'É':'E', 'Ê':'E', 'Ë':'E',
'Ì':'I', 'Î':'I', 'Ñ':'N', 'Ò':'O', 'Ô':'O', 'Ö':'O', 'Ù':'U', 'Ü':'U',
'à':'a', 'á':'a', 'â':'a', 'ä':'a', 'ç':'c', 'è':'e', 'é':'e', 'ê':'e', 'ì':'i', 'î':'i', 'ò':'o', 'ó':'o', 'ô':'o', 'ö':'o',
'ù':'u', 'ú':'u', 'û':'u', 'ü':'u',
'Ā':'A', 'ō':'o', 'Œ':'OE', 'œ':'oe', 'Š':'S','Ṡ':'S', 'Ÿ':'Y',
'、':',', '‘':'\'', '《':'<', '》':'>','–':'-', '—':'-', '’':'\'', '“':'\"', '”':'\"',
'²':'2', '×':'x', '™':'TM', '▪':'·', '●':'·', '・':'·', 'ـ':'_'
}아래 함수를 이용하면, word(string) 속에 key가 있으면 모두 value로 바꿀 수 있다.
transTable = word.maketrans(trans_char_dict)
word = word.translate(transTable)4) 인식 가능한 단어만 남기기
- 모든 이미지를 돌며, 모든 단어를 살핀다.
- trans_char_dict로 유사한 문자는 regular_char로 바꾼다.
- 인식 불가능한 단어는 illegibility 처리한다.(###으로 바꾸기)
- language가 'Latin'이 아닌 단어
- regular_char 이외의 문자가 있는 단어
- 인식 가능한 단어는 language를 'POSSIBLE'로 바꾼다.
- 인식 가능한 단어가 있는 이미지만 저장한다.
count_pos_img, count_neg_img = 0, 0
count_pos_word, count_total_word = 0, 0
remain_latin_set = set([])
for file_name in file_names[1:]:
src = os.path.join(file_path, file_name)
try:
with open(src, 'r', encoding='utf-8') as f:
new_texts = ''
lines = f.readlines()
possible_exist = False
for line in lines:
texts = line[:-1].split(',')
bbox = ','.join(texts[:8])
script = texts[8]
word = ','.join(texts[9:])
count_total_word += 1
if word == '': # 빈 문자열 지우기
# count_neg_word += 1
continue
elif word == '###':
script = 'null'
else:
if script != 'Latin':
word = '###'
else:
transTable = word.maketrans(trans_char_dict)
word = word.translate(transTable)
if check_possible_word(word):
script = 'POSSIBLE'
possible_exist = True
count_pos_word+=1
else:
for char in word:
if not check_possible_word(char):
remain_latin_set.add(char)
word = '###'
new_texts += bbox+','+script+','+word+'\n'
except:
print(file_name)
continue
if POSSIBLE_exist:
count_pos_img += 1
new_src = os.path.join(new_file_path, file_name)
with open(new_src,'w') as f:
f.write(new_texts)
image_name = 'img_' + file_name.split('_')[2].split('.')[0]+'.*'
image_name = glob.glob(image_path+'/'+image_name)[0].split('/')[-1]
image_src = os.path.join(image_path, image_name)
new_image_src = os.path.join(new_image_path, image_name)
shutil.copyfile(image_src, new_image_src)
# # print(image_src, new_image_src)
else:
count_neg_img += 1
print('pos img: '+str(count_pos_img)+', neg img : '+str(count_neg_img))
print('total word: '+str(count_total_word)+', pog word : '+str(count_pos_word))
print(sorted(list(remain_latin_set)))전체 코드 보기
🔗 ICDAR 2015용 변환 코드
🔗 ICDAR 2017용 변환 코드
5. 데이터 셋 합치기
두 데이터셋은 서로 유사하지만 다른 형식을 가지고 있다.
또한 둘 모두 파일이름이 1부터 시작하는 index로 나타난다.
따라서 두 데이터셋의 Annotation 형식을 통합하고, index가 겹치지 않도록 정리해보자.
이때 ICDAR 2017의 데이터가 훨씬 많다. 따라서 2015를 2017 format으로 바꾼는 것이 비용이 적다.
1. ICDAR 2017 복사하기
우선 새로운 폴더를 하나 만들고, 둘 중 데이터가 더 많은 ICDAR 2017의 데이터를 모두 복사한다.
import shutil
shutil.copytree(train_gts1, new_train_gts)
shutil.copytree(train_images1 , new_train_images)2. ICDAR 2015 복사하기
- icdar 2017과 동일한 형식의 파일명으로, index만 다르게 설정한다.
- 새 index는 기존 index에 10000을 더한 값으로 설정한다.
- 파일을 하나씩 새로운 이름으로 복사한다.
import os- ground truth(gt) 파일 수정 & 이름 변경 & 복사
old_file_path = train_gts2
old_file_names = os.listdir(old_file_path)
new_file_path = new_train_gts
if not os.path.isdir(new_file_path):
os.makedirs(new_file_path)
for old_name in old_file_names:
try:
new_idx = int(old_name.split('_')[-1].split('.')[0]) + 10000
except:
print(old_name)
continue
new_name = 'gt_img_'+str(new_idx)+'.txt'
old_src = os.path.join(old_file_path, old_name)
new_src = os.path.join(new_file_path, new_name)
shutil.copyfile(old_src, new_src)
# print(old_src, new_src)- image 파일 이름 변경 & 복사
old_file_path = train_images2
old_file_names = os.listdir(old_file_path)
new_file_path = new_train_images
if not os.path.isdir(new_file_path):
os.makedirs(new_file_path)
for old_name in old_file_names:
try:
new_idx = int(old_name.split('_')[-1].split('.')[0]) + 10000
new_name = 'img_'+str(new_idx)+'.jpg'
old_src = os.path.join(old_file_path, old_name)
new_src = os.path.join(new_file_path, new_name)
shutil.copyfile(old_src, new_src)
except:
print(old_name)
continue
# print(old_src, new_src)전체 코드 보기
🔗 파일 통합 코드
