
네트워크는 노드와 연결선들로 이루어진 그래프가 현실 세계에서 주로 복잡계의 형태로 나타나는 것이다. 인공 신경망은 네트워크 형태로 나타낼 수 있다. 본 포스트에서는 인공 신경망 구조 중 하나인 RNN을 네트워크 이론을 통해 분석한 논문인 Structural Properties of Recurrent Neural Networks (Dobnikar & Šter, 2009)를 리뷰한다.
Complex Systems
현실 세계의 많은 계는 복잡계이다. 복잡계(Complex System)란 시간이 지남에 따라 변화할 수 있는 잠재력이 있는 거시적 집합의 행동에 대한 연구이다. 복잡계 연구는 큰 데이터베이스와 높은 컴퓨터 성능, 학문 분야 간의 활발한 교류 덕분에 크게 발전하고 있다.
복잡계 네트워크를 표현하기 위해서는 주로 그래프가 사용된다. 그래프(Graph)는 와 같이 표현되는데, 이때 는 개의 노드(Node)의 집합이고, 는 개의 연결선(Edge)의 집합이다. 그래프의 특성을 나타내는 데에는 의 세 가지 값을 주로 이용한다.
Characteristic Path Length
은 모든 연결선의 길이가 1이라고 가정할 때, 그래프 상의 모든 두 노드 간의 최소 거리의 평균을 의미한다. 이때 두 노드 간의 거리 는 두 노드 사이에 있는 연결선의 개수를 의미한다. Characteristic Path Length는 다음과 같은 수식으로 표현된다.
Clustering Coefficient
는 연결선으로 연결된 가장 가까운 노드의 개수의 평균이다. 노드 의 도수(degree)를 라고 할 때, 이 노드의 Clustering Coeffieient는 다음과 같이 표현된다.
그래프의 Clustering Coefficient는 모든 노드의 의 평균이다.
Degree Distribution
는 무작위로 노드를 선택했을 때 그 노드가 개의 연결선을 가지고 있을 확률이다. 이때 평균 도수는 다음과 같이 계산된다.
Structures of Networks
네트워크는 구조적인 면에서 Random Network, Small-World Network, Scale-Free Network로 나눌 수 있다.
Random Network (RN)
Watts와 Strogatz의 논문에서 제시된 모델을 이용하여 그래프를 만든다고 가정하자. 개의 노드와 각각의 노드에 대해 개의 연결선이 있다. 각각의 연결선을 의 확률로 무작위로 바꾼다고 가정하자. 이러한 과정을 통해 Random Network (RN)을 얻을 수 있다. 만약 네트워크의 임의의 두 노드가 의 확률로 연결되어 있다면, 네트워크는 개의 연결선을 가지게 된다. 는 이항 분포를 따르므로 평균 도수는 이 되고, 이는 매우 큰 에 대해 으로 근사된다. 임을 이용하여 다음과 같은 식을 도출할 수 있다.
한편, 연결선이 무작위적으로 분포하기 때문에 이다.일반적으로 이는 실제 세상에서 같은 노드와 연결선 수를 가진 그래프에 비해 작은 값을 가진다.
Small-World Networks (SWN)
Small-World Network는 정렬된 그래프에서 가 0.1~0.3의 값을 갖도록 무작위로 연결선을 바꾸거나 무작위의 연결선을 추가하여 생성할 수 있다. SWN의 도수 분포 그래프는 RN과 비슷하지만, 에서 최댓값을 가지고 크거나 작은 에서 지수함수적으로 값이 작아진다는 특징을 가진다.
Scale-Free Network (SFN)
Scale-Free Network는 다음과 같은 도수 분포를 가진다.
이러한 분포는 개의 연결선을 가진 노드가 시간의 흐름에 따라 더해져 존재하는 노드 와 의 확률로 연결될 때 나타난다.
Recurrent Neural Network
이 부분에 대한 설명은 이후 포스트에서 자세히 다루어질 내용이므로 생략한다.
Structural Properties of RNN
RNN을 네트워크 이론으로 해석하기 위해 먼저 RNN을 그래프로 변환해 보자. 노드 와 는 임계값 에 대해
일 경우 연결된 것으로 간주된다. 이때 대신 를 사용할 수도 있다. 초기 가중치는 일반적으로 매우 작기 때문에 두 임의의 노드가 연결될 확률을
로 정의하였다. 적합 과정에서 도수의 분포는 척도 없는 네트워크와 유사하게 나타났지만, 최종 분포가 power-law distribution을 가지지 않으므로 일반적인 분포로 볼 수 없다. 따라서 Shannon entropy를 고려하여 이것이 어떻게 증가하는지를 확인할 것이다.
개의 노드를 가지는 네트워크에서, 다음의 식을 만족한다.
Shannon의 식에 의해, 엔트로피는 다음과 같이 정의된다.
를 대입하여 적절히 정리하고 식을 간단히 하기 위해 를 대입하면
이 된다. 임의의 연결선을 큰 도수 을 가지는 허브와 연결한다면, 허브의 도수는 이 되고, 도수 과 의 빈도 는
이 되며, 동시에 도수 을 가지는 어떤 노드는 연결을 잃어
이 된다.
이므로,
이다. 이때 의 기댓값은 이며, 도수가 가 로 변하는 변화에 대한 엔트로피 변화의 기댓값은
이고, 허브의 연결에 의한 엔트로피 변화는
이다. 두 엔트로피 변화량 모두가 양의 값을 가지므로, 전체 엔트로피 변화량의 기댓값도 항상 양의 값이다.
결과
두 input에 대한 delayed XOR을 실행했을 때, 와 뉴런의 개수를 변경해 가며 학습을 진행한 결과는 다음과 같았다.
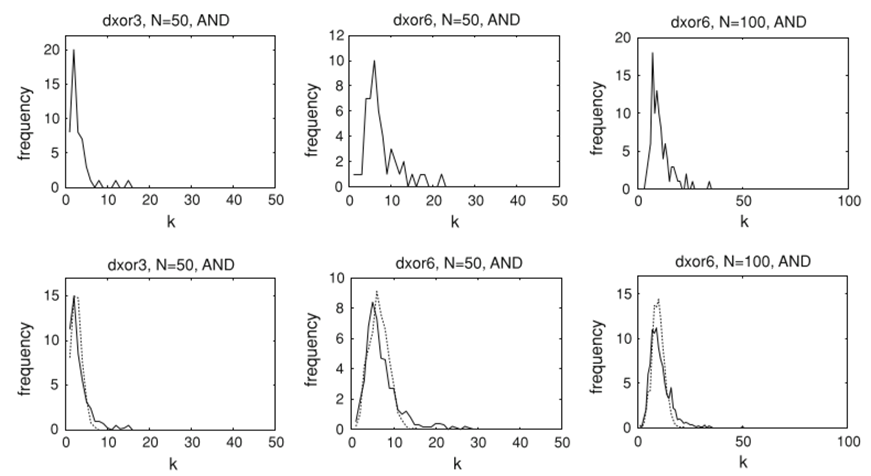
빈도가 최대가 되는 지점이 가 낮은 곳에 존재하며, 빈도가 매우 높게 나타나는 허브의 존재가 일관적으로 나타낸다. 일 경우의 과 는 다음과 같이 변화하였다.
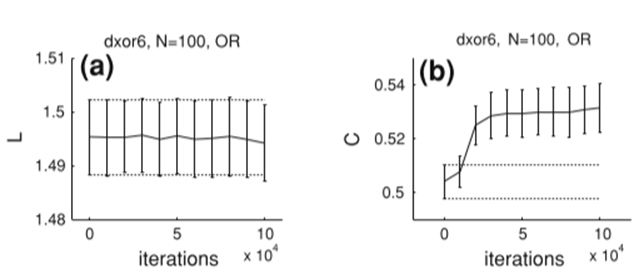
은 낮은 값으로 유지되고, 는 점점 증가하는 양상을 보인다.
결론
실험 결과, 적합 과정은 RNN을 무작위 네트워크에서 특정한 형태의 네트워크로 변경하는 것으로 나타났다. 적합 과정이 진행되며 은 낮게 유지되고 는 증가하는데, 이는 좁은 세상 네트워크에서 일반적이다. 또 는 척도 없는 네트워크의 전형적인 특징인 허브의 일관된 존재를 나타낸다. 이로써 RTRL 훈련된 RNN은 좁은 세상 네트워크와 척도 없는 네트워크의 성질을 모두 가지고, 지속적으로 증가하는 엔트로피 값을 가짐을 확인할 수 있었다.
