[논문리뷰] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (S. Ioffe and C. Szegedy, 2015)
논문리뷰

배치 정규화(Batch Normalization)은 Gradient Vanishing과 Exploding을 방지하고 전체적인 학습 효율을 높이기 위한 방식 중 하나이다. 본 포스트에서는 배치 정규화를 최초로 제안한 논문인 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (S. Ioffe and C. Szegedy, 2015)을 리뷰한다.
Stochastic Gradient Descent (SGD)
Gradient Descent를 진행할 때에는 학습 데이터 전체를 사용하여 학습을 진행한다. 하지만, 학습 데이터의 크기가 클 경우 한 번에 너무 많은 양의 데이터를 처리하는 데에 어려움이 생긴다. 따라서 데이터를 batch단위로 나누어 학습을 진행시키는 것이 일반적인데, 이러한 방식을 Stochastic Gradient Descent (SGD)라고 한다.
SGD에 대해 좀 더 자세히 살펴보자. 모든 Optimizer는 다음 식을 만족시키는 파라미터 를 찾는 것을 목표로 한다.
SGD에서는 위 식을 만족시키는 를 찾기 위해 각각의 단계에서 mini batch(또는 batch)만을 계산한다. 즉, 입력 데이터를 크기가 인 batch 으로 만들어 다음 계산을 반복적으로 진행한다.
Saturation and Vanishing Gradients
다음과 같은 레이어를 가정해 보자.
여기서 는 layer의 입력값이고, 는 가중치 행렬(weight matrix)이며 는 편향 벡터(bias vertor)이다. 이다.
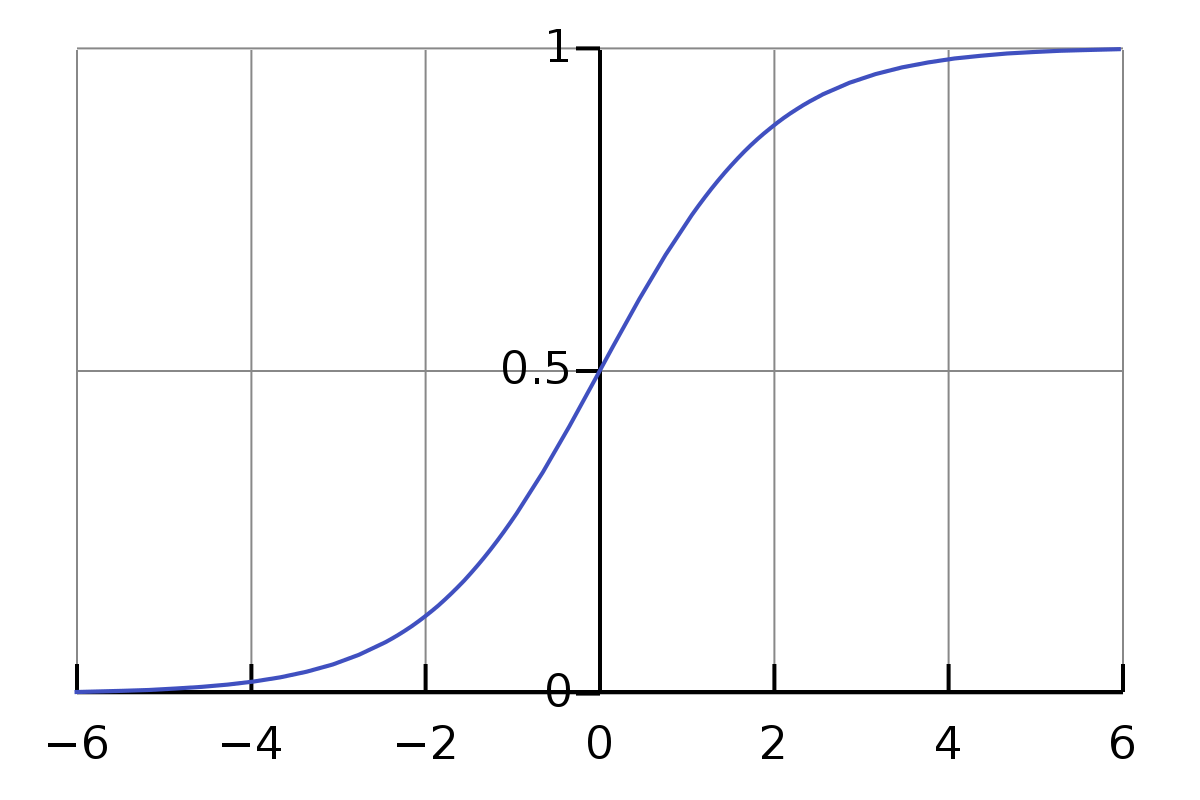
sigmoid 함수의 그래프 개형에서 확인할 수 있듯, 가 커질수록 는 0에 수렴한다. 즉, 가 아주 작은 경우를 제외하고는 가 0이 되어 더 이상 가 업데이트되지 않는 Saturation(포화) 현상이 일어난다. 뒤쪽의 layer가 saturated되면 앞의 layer도 saturated되어 가 업데이트되지 못하는데, 이렇게 backpropagation 과정에서 뒤쪽 레이어부터 차례로 saturation이 발생하여 파라미터가 업데이트되지 못하는 현상을 Vanishing Gradient(기울기 소실)라고 한다.
Internal Covariate Shift
Vanishing Gradient 문제를 해결하기 위해 앞선 연구에서 과 같은 활성화 함수를 사용하거나 를 잘 초기화하는 방식이 제안되었다. 하지만 앞서 제안된 모든 방식은 한 가지 공통적인 문제를 가지는데, 학습 과정에서 아래 사진과 같이 layer별로, 또 batch별로 입력의 데이터 분포가 달라지는 것이다. 이 문제를 해당 논문에서는 Internal Covariate Shift라고 부른다.
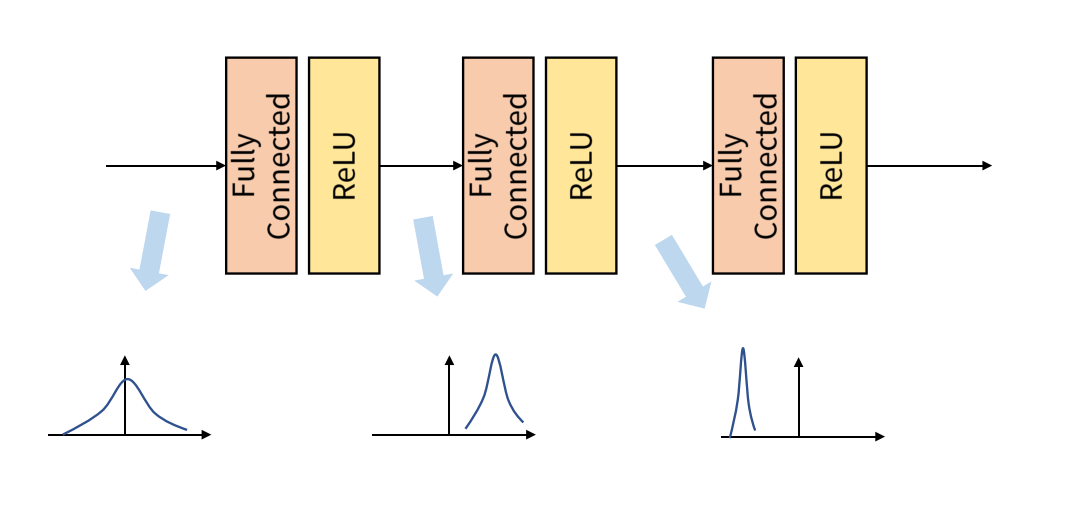
Whitening Transformation
앞선 연구들에 의해, 입력 데이터에 whitening transformation을 적용하면 학습의 효율이 높아진다는 것이 알려져 있었다. 따라서 whitening transformation을 optimization 단계에 적용하는 방법을 생각해 볼 수 있다. 하지만, 이러한 방법은 GD가 normalization 단계에 필요한 파라미터를 업데이트하며 성능을 저하시킬 수 있는 문제가 있다.
좀 더 자세히 살펴보기 위하여, 를 입력받는 레이어를 생각해 보자. 이때 입력 데이터는 이다. 입력 데이터에서 평균을 뺄셈하여 정규화하는 알고리즘을 생각하자.
만약 GD가 에 대한 의 의존성을 무시한다면, 다음과 같은 업데이트가 진행될 것이다.
즉, 에 대한 업데이트가 계속 진행되어도 그것이 결과값에 반영되지 않는다. 따라서 는 끊임없이 증가하는데 반해 의 값은 변하지 않는다. 본 예시에서는 평균을 0에 맞추는 연산만 진행하였으나, 분산을 1에 맞추는 연산까지 진행한다면 이 문제는 더욱 심해진다.
Batch Normalization
이 문제를 해결하기 위해 매개 변수 값에 대해 네트워크가 항상 원하는 분포를 입력받아 활성화되도록 한다. 즉, 다음과 같은 정규화가 이루어지도록 한다.
이 정규화 방식은 한 단계에서의 데이터 뿐 아니라 전체 데이터 를 확인한다는 점에서 앞선 정규화 방식과 차이점을 가진다. 해당 논문에서는 이러한 정규화를 각 batch에 적용하는 알고리즘을 제안한다.
BN for Training Steps
논문에서는 모델 훈련 과정에서의 배치 정규화와 모델 테스트 과정에서의 배치 정규화를 분리하여 소개한다. 아래 그림은 논문에서 제시된 훈련 과정에서의 배치 정규화 알고리즘이다.

batch 을 학습시키는 단계를 가정하자. 먼저, batch의 평균과 분산을 구한다.
구한 평균과 분산을 이용하여 입력 를 정규화한다. 이때 분모가 0이 되는 것을 방지하기 위해 분모에 매우 작은 상수 을 더한다.
이렇게 정규화한 값을 사용하면 을 따르므로 95%의 입력 값에 대해 이 되고, 이러한 입력값은 위에서 언급한 sigmoid 함수의 그래프 개형에서 알 수 있듯 activation function의 비선형성을 잃게 한다. 따라서 정규화한 값을 scaling하고 shifting하는 연산이 추가되는데, 이는 다음과 같이 진행된다.
Scaling과 Shifting에 사용되는 는 backpropagation 과정에서 학습되는 데이터이다. 이때 두 파라미터의 gradient는 다음과 같이 계산된다.
BN for Interference
학습 중에는 batch의 평균과 분산을 이용할 수 있지만, 추론 및 테스트에서는 이를 이용할 수 없다. 따라서 추론에서는 배치 정규화를 통해 추정한 입력 데이터 분포를 반영하기 위해 고정된 평균과 분산을 이용하여 정규화를 수행한다. 이 과정은 아래의 그림에서 제시된 알고리즘과 같이 진행된다.

평균을 계산하는 데에는 미리 저장한 batch의 moving average를 사용하여 해결한다. 위의 그림에서 6-12행은 moving average를 계산하는 알고리즘이다.
결과
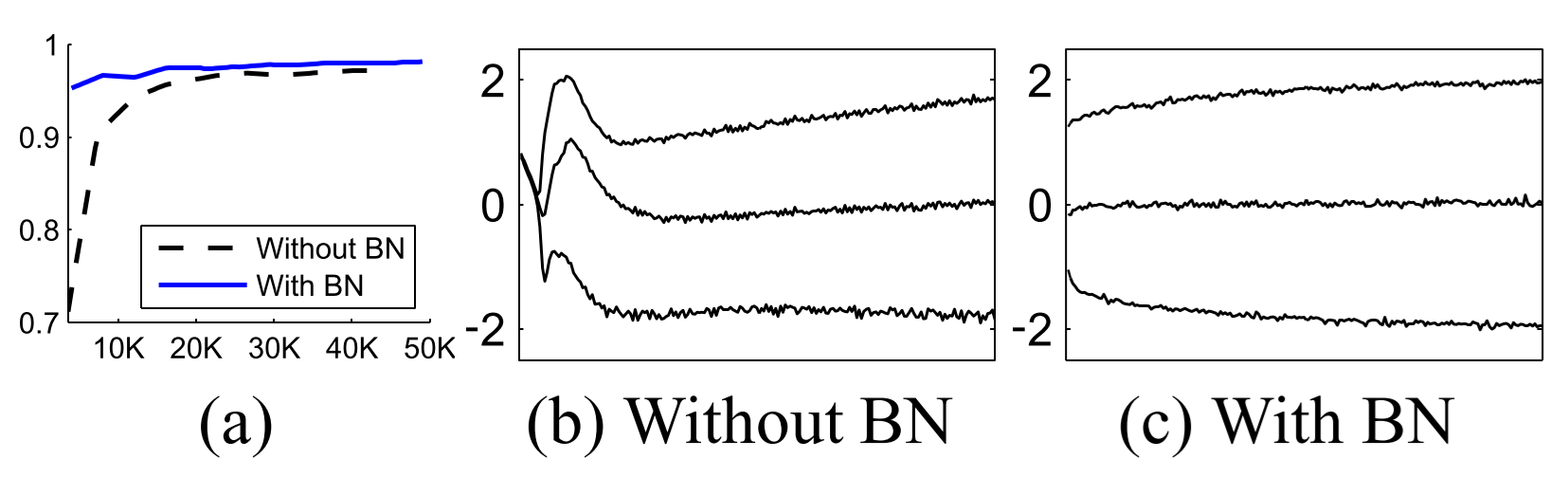
아래의 그림 (a)는 training step에 따른 MNIST 데이터셋의 테스트 정확도이다. BN이 적용된 신경망이 훨씬 빨리 학습되어 더 높은 정확도를 보이는 것을 확인할 수 있다. 그림 (b), (c)는 입력 데이터의 분포를 나타낸 그림이다. BN이 적용된 데이터가 훨씬 균등하게 분포하여 Internal Covariate Shift를 감소시킨다.
아래 그림은 여러 종류의 신경망으로 ImageNet classification challenge benchmark 를 실행시킨 것이다. 전체적으로 BN이 적용된 신경망이 매우 높은 효율을 보이는 것을 표에서 확인할 수 있다.


저도 개발자인데 같이 교류 많이 해봐요 ㅎㅎ! 서로 화이팅합시다!