
스레드(Thread)에 대해서 알아봐요
Light Weight Process라고도 불려요. 프로세스 간에는 각 프로세스의 데이터를 접근하려면 DB같은 외부 프로그램이나 IPC 기법을 활용해야 해요. 어떠한 방식을 사용하던 외부에서의 방식으로 접근하기 때문에 컨텍스트 스위칭 등이 일어나 자원 공유가 원활한 건 아니에요.
그래서, 하나의 프로세스 안에서 자원을 공유하면서 여러 프로그램 실행 흐름을 생성할 수 있게 하는 기능이 있는데 이것이 바로 스레드Thread에요. 스레드는 프로세스 안에서 동시 실행이 가능해요. 그리고 프로세스 안에 있어 프로세스의 데이터를 모두 접근이 가능하죠. 도식화하면 아래와 같아요.
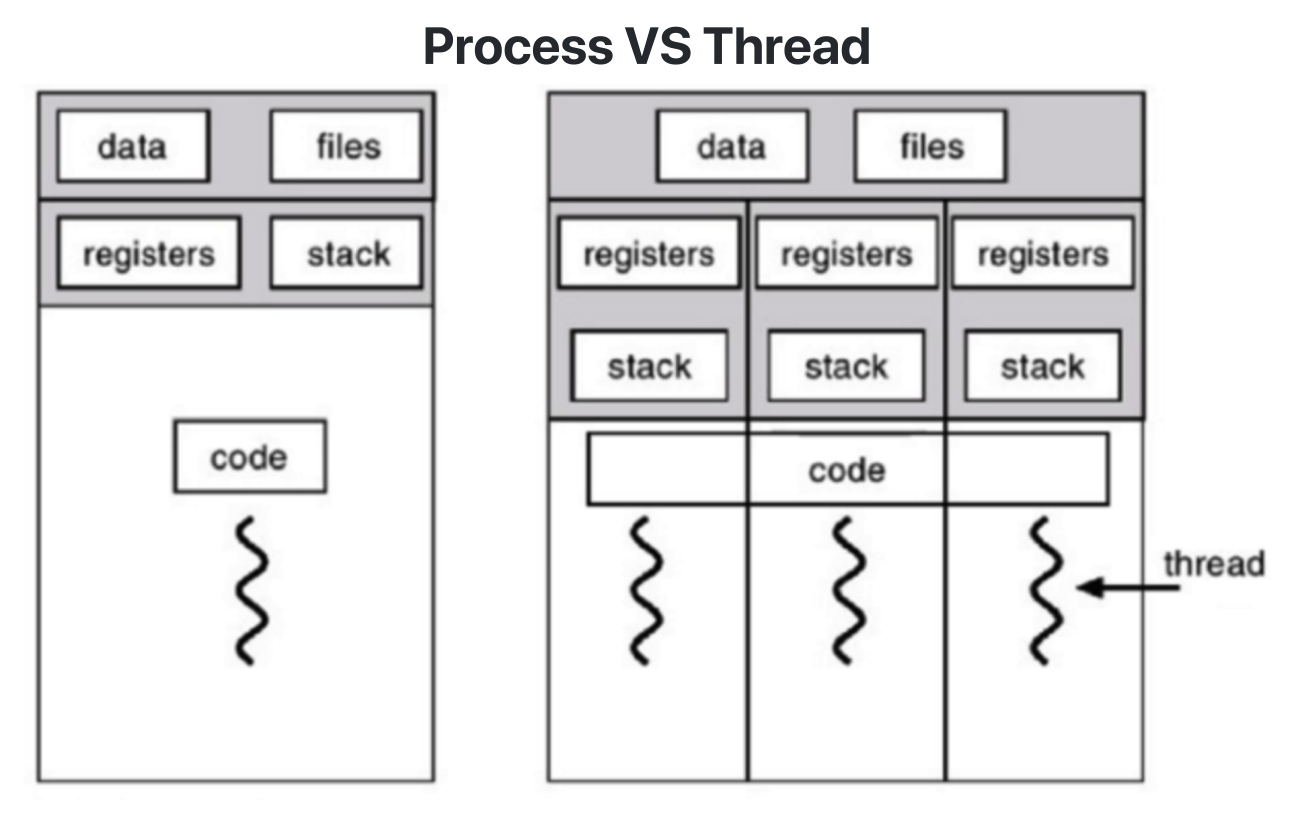
프로세스 메모리 구조는 크게 Text, Data, Heap, Stack으로 나뉘어요. 스레드는 Stack만을 독립적으로 가지고, Data와 Heap 그리고 Text 영역을 공유할 수 있어요. 이러한 스레드 방식 덕분에 여러 CPU에 프로세스를 적재시켜 작업이 가능해져요. 즉, 멀티 코어 환경으로 멀티 프로세싱 작업이 된다는 의미에요.
멀티 프로세스와 멀티 태스킹
스레드 개념이 나오면서 멀티 프로세스와 멀티 태스킹에 관련된 유형이 정립되었어요. 나열하자면,
1. 1-process, 1-thread
프로세스는 하나의 메인 스레드를 가져요. 일반적으로 초소형 시스템에서 주로 사용되요.
2. 1-process, many thread
3. Many process, 1-thread(스레드 사용X)
4. Many process, many thread
요즘은 이게 추세에요. 하지만...
프로세스 vs. 스레드
꽤나 많은 곳에서 들어오는 면접 질문이에요 ㅎㅎ.
- 프로세스는 독립적, 스레드는 프로세스의 일부
- 프로세스는 자신만의 주소 영역을 가지고, 스레드는 주소 영역을 일부(Code, Heap, Data) 공유
스레드의 장단점
스레드는 매우 좋은 기법이긴 하지만, 마냥 좋은 것은 아니에요. 장점, 단점 순으로 설명할게요.
장점 - 사용자에 대한 응답성 향상
프로세스의 작업을 분할시켜 효율성을 높여요. 예를 들면, 사용자 간의 커뮤니케이션을 통해 데이터를 가져오고, 그 데이터를 가지고 작업을 수행한다, 라는 프로세스가 있다면 스레드로 작업 흐름을 2개로 나눠서 하나는 커뮤니케이션, 하나는 데이터를 가지고 프로세스 실행을 가진다면, 커뮤니케이션 대기로 인한 프로세스의 실행 속도를 상승시킬 수 있겠죠.
장점 - 자원 공유 효율성
IPC 기법처럼 프로세스 간 자원 공유를 위한 번거로운 작업이 필요가 없게 되요. 프로세스 안에 있어서 프로세스의 데이터를 모두 접근이 가능하기 때문이에요.
장점 - 작업이 분리되어 코드가 간결
코드 작성하기 나름이지만, 작업을 나누는 것이니 당연히 코드도 그만큼 간결해져요.
하지만, 강력한 기능인 만큼 단점도 존재해요.
단점 - 스레드 중 하나라도 문제 발생 시, 전체 프로세스가 영향
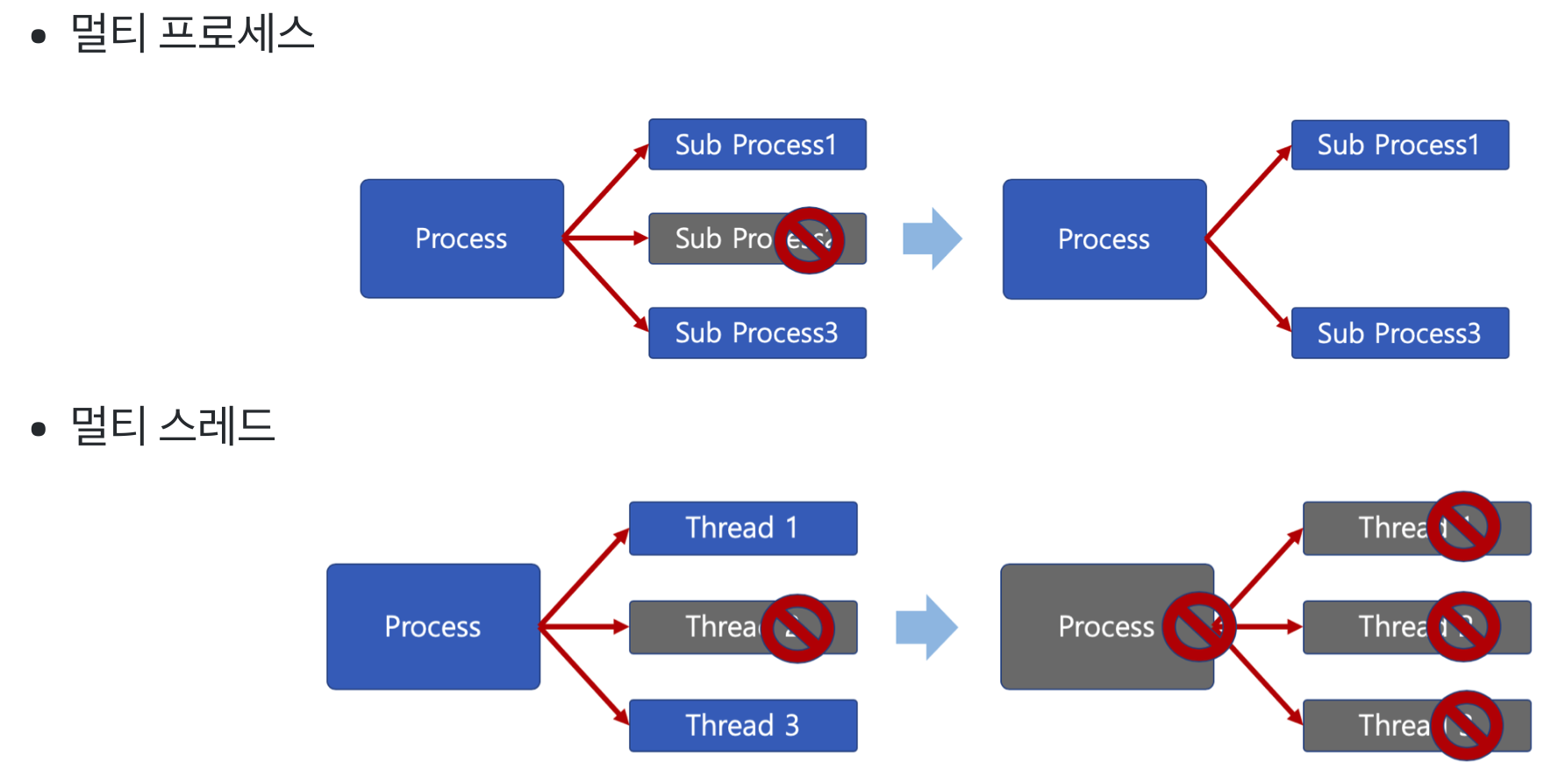
멀티 프로세스 환경에선 프로세스가 하나가 죽더라도 다른 프로세스가 영향을 받지 않아요. 하지만, 스레드는 모든 스레드의 작업이 정상적으로 수행된다는 전제하에 진행되기 때문에, 하나라도 문제가 발생하면 작업 흐름의 전체가 영향을 받아요. 그래서 스레드를 활용한 코드를 작성할 때 매우 주의해야 하고, 활용법도 굉장히 어려워요.
단점 - 컨텍스트 스위칭으로 인한 성능 저하
프로세스처럼, 스레드도 마찬가지로 스레드간 컨텍스트 스위칭이 발생해요. 스레드를 많이 생성할 수록 모든 스레드를 스케줄링해야 하기 때문에 그만큼 발생 빈도가 많아요.
물론 프로세스간 컨텍스트 스위칭보단 오버헤드가 적은 편이긴 하지만, 수가 많다면 아무리 CPU가 연산을 빠르게 수행해도 성능 저하는 피할 수 없어요.
동기화(Synchronization) 이슈
프로세스 안에는 다수의 스레드가 만들어진다고 했어요. 그리고 프로세스의 데이터를 공유할 수가 있어요.
그리고, 스레드는 실행 순서가 정해져 있지 않아요. 그래서 만약 스레드끼리 변수 값을 바꾸면 의도하지 않은 값이 나올 수 있어요. 그래서 순서가 꼬이게 되면 비정상적인 결과가 나올 수 있어요. 이를 동기화Synchronization 이슈라고 해요. 동일 자원을 여러 스레드가 동시 수정 시, 각 스레드 결과에 영향을 주는 것이에요. 그래서 이러한 이슈 때문에 스레드는 동기화 관리가 필요해요.
도식화하면서 설명해볼게요

하나의 스레드는 g_count라는 전역 변수DATA를 1 증가시키는 로직을 수행한다고 가정할게요.
Thread의 실행 흐름
1. 전역 변수를 읽어들여 레지스터에 등록
2. 전역 변수를 1 더함
3. 더한 값레지스터을 전역 변수에 저장
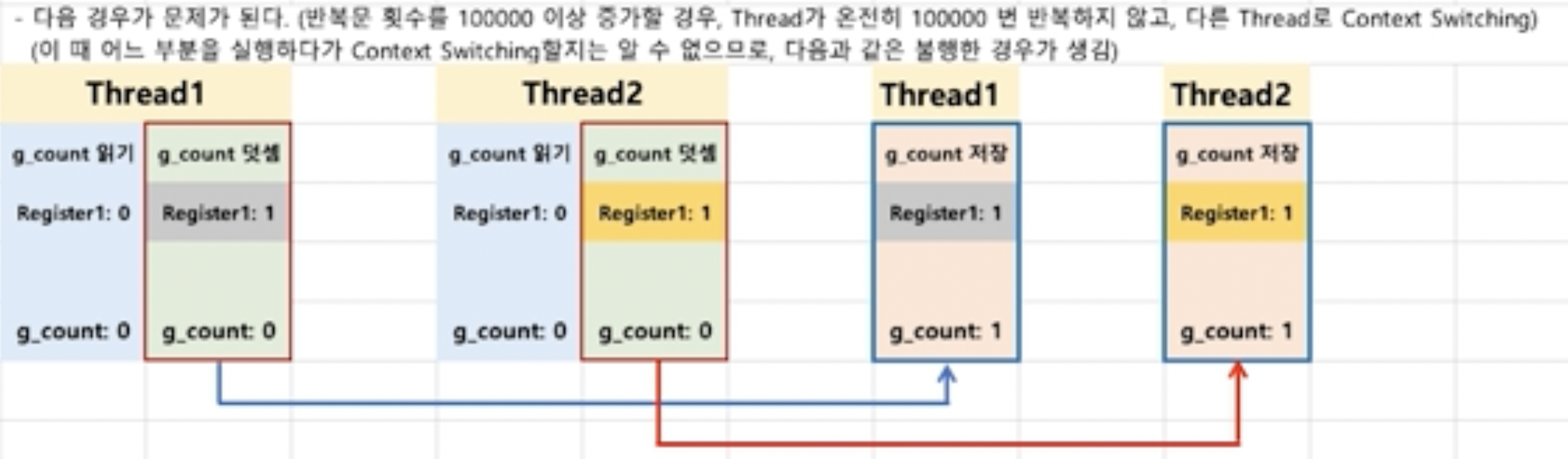
그리고 2개의 스레드가 생성이 되었어요. 처음에 생성 순서에 관계 없이 스레드가 실행되요.
이때 처음 실행하는 스레드가 전역 변수를 읽고 전역 변수 값을 더해주는 중, 컨텍스트 스위칭이 일어나면서 2번째 스레드가 Running 상태가 되요.
마찬가지로 1번째 스레드처럼 '덧셈'을 수행해요.
그 다음에 컨텍스트 스위칭이 일어나면서 1번째 스레드가 드디어 레지스터 값에 있는 값을 전역 변수에 저장해서 전역 변수가 1이 되요.
그리고 다시 컨텍스트 스위칭이 일어나면서 2번째 스레드가 저장을 하는데, 이때 레지스터에 이전에 수행한 결과를 전역 변수에 저장을 하면서 이미 다른 스레드에서 한번 더했음에도, 전역 변수의 결과는 1이 되버리는거에요.
결국 이러한 스레드의 실행 흐름 때문에 알 수 없는 결과가 나오게 되요.
스레드에 대해 매우 간단한 예를 들어볼게요.
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
int g_count = 0;
void* func(void* ptr){
for(int i = 0 ; i < 1000; ++i){
++g_count;
}
}
int main()
{
pthread_t thread1, thread2;
pthread_create(&thread1, NULL, func, 0);
pthread_create(&thread2, NULL, func, 0);
printf("%d\n", g_count);
return 0;
}이 코드의 결과는 뭐가 나올까요? 2000? 안타깝게도 알 수 없다에요.

위 코드를 clang으로 돌린 결과에요. 스레드는 순서가 뒤죽박죽이라 for문을 수행하는 동안 다른 스레드가 실행될 수 있어요.
물론 해결 방법은 있어요. 1번 스레드가 수행되는 동안 다른 스레드가 접근을 못하게 하면 되요.
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
int g_count = 0;
void* func(void* ptr){
for(int i = 0 ; i < 1000; ++i){
++g_count;
}
}
int main()
{
pthread_t thread1, thread2;
pthread_create(&thread1, NULL, func, 0);
pthread_create(&thread2, NULL, func, 0);
pthread_join(thread1, 0); // 이 스레드가 끝날 때까지 다른 스레드는 접근 못해요!
pthread_join(thread2, 0); // 이 스레드가 끝날 때까지 다른 스레드는 접근 못해요!
printf("%d\n", g_count);
return 0;
}
물론 위 코드는 스레드를 쓰는데 의미가 없긴 해요 ㅎㅎ. 여기서 하고 싶은 말은, 그만큼 스레드는 효율성과 동기화 이슈를 고려해서 작성해야 제대로 활용할 수 있다는 것이에요.
그리고 이런 동기화 이슈를 해결하기 위한 기법도 존재해요.
상호 배제(Mutual Exclusive)
동기화 이슈의 해결 방안이에요. 스레드는 프로세스의 모든 데이터를 접근해서 문제가 발생해요. 그래서 여러 스레드가 변경하는 공유 변수에 대해 배제적 접근Exclusive Access가 필요해요. 한 스레드가 공유 변수를 갱신하는 동안 다른 스레드가 동시 접근하지 못하게 막는거에요. 그리고 이렇게 Exclusive Access가 존재하는 자원을 임계 자원이라고 하고, 코드 영역을 임계 영역Critical-section이라고 해요.
당연히 임계 영역에 대한 접근을 막기 위한 Locking 알고리즘들이 존재해요.
세마포어(Semaphore)
임계 영역에 여러 스레드가 들어갈 수는 있되, Counter를 둬서 동시에 자원을 접근할 수 있는 가용 스레드 개수를 제어하는 방식이에요.
이 세마포어 기법은 수도 코드Pseudo-code 형식으로도 표기가 가능해요.
수도 코드
P : 검사(임계 영역 접근) S 값이 1이상이면 영역 진입 후 S 값 1이 차감되요. S 값이 0이면 대기 상태가 되요.
V : 증가(임계 영역 해제) S 값을 1 더하고 임계 영역에서 나와요.
S : 세마포어 값 초기 값만큼 여러 프로세스가 동시에 임계 영역에 접근이 가능해요.
P(S) : wait(S){
while S <= 0; // 대기
S--; // 다른 프로세스 접근 제한
}
V(S) : signal(S){
S++; // 다른 프로세스 접근 허용
}세마포어 - 바쁜 대기
wait()의 S가 0이라면, 임계 영역에 들어가기 위해 반복문을 수행하는데, 이를 바쁜 대기busy waiting이라고 해요. 이는 결국 루프문을 임계 영역에 들어갈 때까지 계속 돌기 때문에 CPU 성능 이슈를 야기해요.
세마포어 - 대기 큐
바쁜 대기로 인한 CPU 성능 이슈를 해결하기 위해 나온 개념이에요. 운영체제처럼 임계영역에 접근할 스레드를 대기 큐안에 넣어서 관리하는 방식이에요.
wait(S){
S->count--;
if (S->count < 0){
add this process to S->queue
block()
}
}wait(S)에서 이전 방식과 달리 S count를 먼저 감소시켜요. 만약 이 감소로 인해 S->count < 0이 되면, 즉 현재 스레드가 wait를 불렀지만 세마포어에 빈 자리가 없는 상태였다면 현재 스레드를 blocking해서 기다리게 해요.
이후에 세마포어를 먼저 획득한 스레드가 signal(S)를 불러 접근 허용 스레드를 하나 증가시키면(s->count)++ 두 가지 상황이 발생해요.
1. 기다리던 스레드가 없었고(증가 이전에 s->count >= 1), 하나의 스레드가 더 접근할 수 있는 경우
wait(S)를 호출하는 스레드들은 (s->count)--시키며 block 없이 진행해요. 따로 signal(S)에서 wakeup을 불러올 필요가 없게 되요.
2. 기다리던 스레드가 있었고(증가 이전에 s->count < 0), 하나의 스레드가 더 접근할 수 있는 경우
기다리던 스레드가 있었고 s->count 증가 이후에도 wait(S)를 호출하는 함수들은 다시 s->count를 음수로 만들면서 block할 예정이라 Signal(S)에서 wakeup을 통해 기다리던 스레드를 깨워줘요.
쉽게 말하면 기다리는거 없으면 따로 block된 스레드 살릴 거 없이 들어온 스레드를 접근 허용해주고, 있으면 그 스레드를 block 상태를 해제해주는 방식으로 스레드가 실행된다 보시면 되요.
signal(S){
S->count++;
if (s->count < 0){
remove a process P from S->queue;
wakeup(P);
}
}뮤텍스(Mutex, Binary Semaphore)
이진 세마포어Binary Semaphore라고도 불려요. 세마포어랑 똑같은데, 임계 구역에 오직 하나의 스레드만 접근이 가능해요. s->count 상태가 0아니면 1인거에요.
Locking 알고리즘은 크게 이 두가지로 나뉜다 보시면 되요. 여기까지만 들으면 완벽하게 스레드를 자알 사용할 수 있겠구나 싶은데, 이 Locking 알고리즘 때문에 발생하는 문제도 존재해요.
교착 상태(Deadlock)
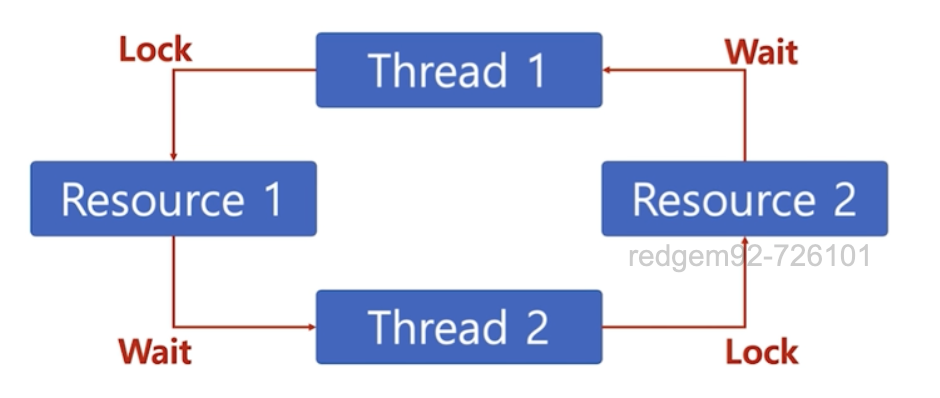
두 개이상의 작업이 서로 상대방의 작업이 끝나기만을 기다리고 있어 다음 단계로 진행 못하는, 무한 대기 상태에요.
이 문제는 스레드 뿐만 아니라 프로세스에서도 발생할 수 있어요.
발생 조건
1. Mutex(Mutual Exclusive)
프로세스들이 필요하는 자원에 대해 배타적인 통제권을 요구하는 경우에요.
2. 점유 대기(Hold and Wait)
프로세스가 할당된 자원을 가진 상태에서 다른 자원을 기다리는 경우에요.
3. 비선점(Non-preemptive)
프로세스가 어떤 자원의 사용을 끝날 때까지 그 자원을 못 뺏는 경우에요.
4. 순환 대기(Circular Wait)
각 프로세스는 순환적으로 다음 프로세스가 요구하는 자원을 가지는 경우에요.
해결 방법
물론 이런 경우를 해결하는 방법도 당연히 존재해요. 해결안은 위에 언급된 4가지 조건이 모두 성립이 되었을 때 일부만 해결하면 풀 수 있어요.
1. 예방
4가지 조건 중 일부를 제거해요.
2. 회피
자원 할당 순서를 정하지 않는 방식으로 순환 대기만 제거해요. 나머지 조건들을 제거하면 프로세스 성능 저하가 발생할 수 있기 때문이에요.
3. 발견
수시로 스레드를 점검해서 교착 상태에 있는 것을 발견하는 방식이에요.
4. 회복
교착 상태에 있는 스레드가 있다면 해제하거나 선점을 해요.
기아 상태(Starvation)
Locking 알고리즘 사용 과정 중 발생할 수 있는 두번째 이슈에요. 특정 프로세스의 우선순위가 너무 낮아서 원하는 자원을 계속 할당을 받지 못하는 상태에요.
Starvation과 Deadlock을 비교하자면, Deadlock은 여러 프로세스가 동일한 자원 점유 요청할 경우 발생하고, Starvation은 여러 프로세스가 부족한 자원을 점유하기 위해 경쟁할 때 특정 프로세스는 영원히 할당 안되는 경우에 발생해요.
해결방안
우선순위가 낮으니까 우선순위를 높여주면 되요. 공평하게 우선순위가 낮았던 프로세스도 우선순위를 수시로 높여줘서 높은 우선순위를 가질 기회를 주는 거에요.
에이징Aging 기법을 통해 오래 기다린 프로세스에게 시간이 지날 수록 우선순위를 높이는 방법이 있고, 아니면 우선순위가 아니라 요청한 순서대로 처리하는 FIFOFirst-in First-out 기법으로 처리하면 되요.
스레드에 대한 정리는, 여기까지에요.
