[부스트캠프 AI tech CV] week09 (2022.03.14) Instance/Panoptic Segmentation and Landmark Localization
부스트캠프 AI tech 3기
목록 보기
25/40
1 Instance segmentation
https://towardsdatascience.com/review-deepmask-instance-segmentation-30327a072339
- 개체(instance) 별로 사물을 segmentation하는 방법

1.1 mask R-CNN
https://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html
- ROI pooling 대신 ROI Align을 사용
- 2개의 head로 나누어지고 예측된 class와 동일한 mask 추출함
- 다른 R-CNN과 마찬가지로 2-stage 모델


1.2 one-stage
- YOLACT(You Only Look At CoefficienTs)
mask coefficients와prototypes의 연산을 통해 detection하는 방법인듯 하다.
- YolactEdge
조금 더 빠른 detection을 위해 개발된 방법

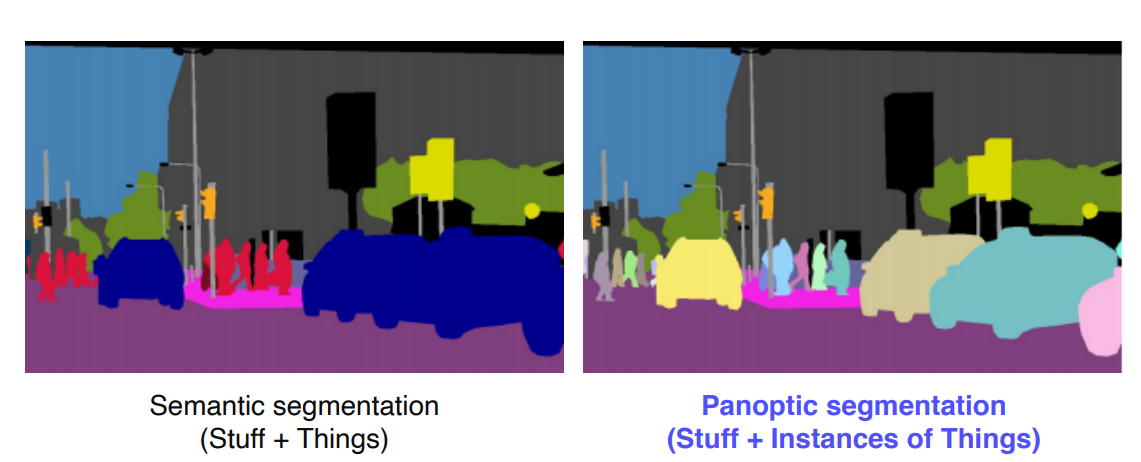
2 Panoptic segmentation
- semantic segmentation: 개체별 구분없이 class 구분
- instance segmentation: 개체별 구분 + class 구분 + 배경x
- panoptic segmentation: 배경 + 개체 + class 구분
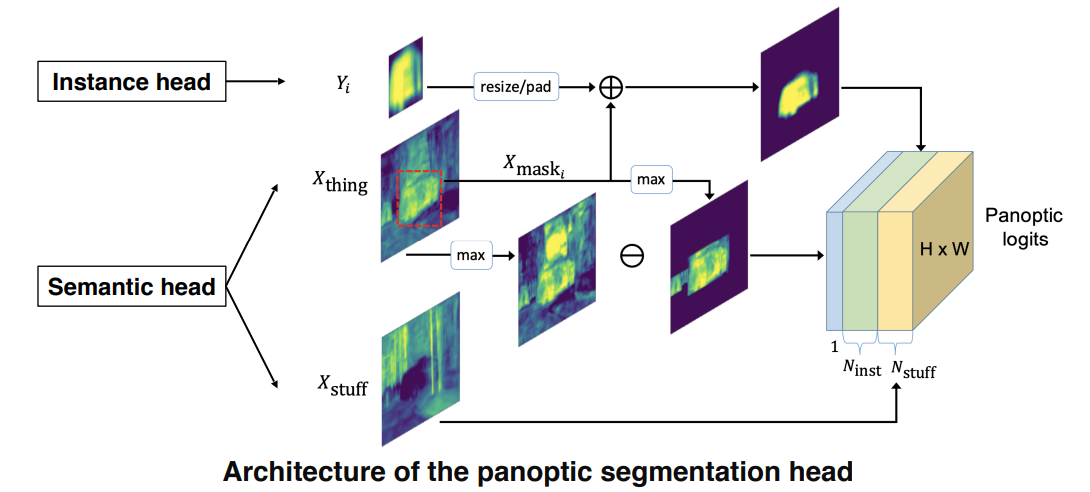
2.1 UPSNet
semantic Head: sementic segmentation에서 처럼 FCN를 통해 semantic logit을 얻음instance Head: 물체 detection + mask logit추출panoptic Head: 앞의 head들을 종합
- : instance
mask- : 물체를 나타내는
mask- : 배경을 나타내는
mask- 와 를 더해 물체의 위치를 더 잘보이게 함 / unknown물체를 배제하기 위해 빼줌

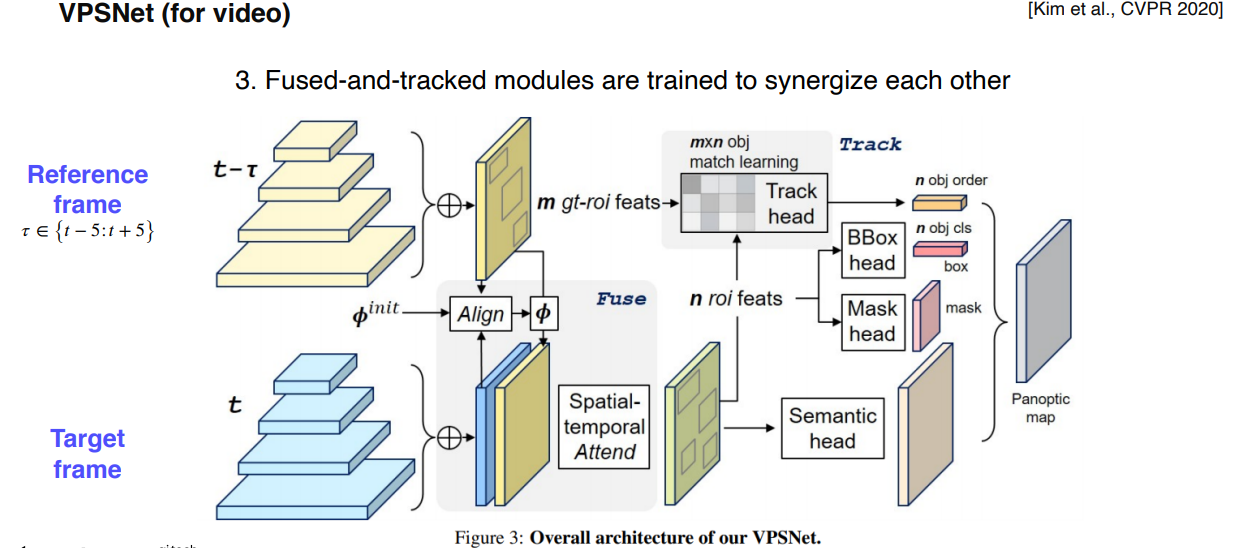
2.2 VPSNet
3 Landmark localization
Landmark localization=keypoint estimation- 얼굴이나 사람의 pose를 추정, 트래킹
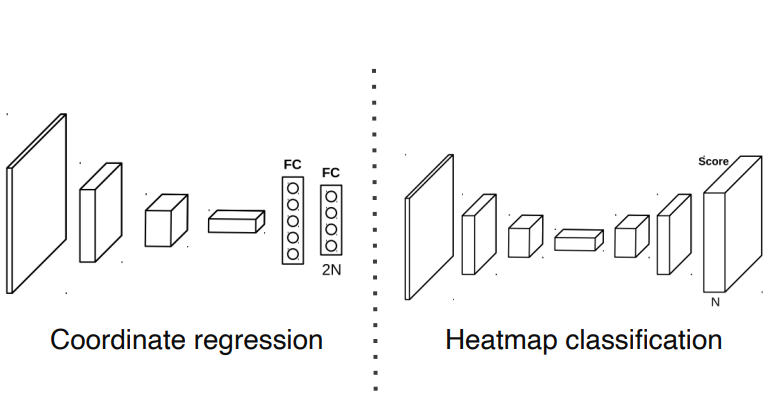
coordinate regression: 포인트의 x,y 위치를 regression하는 방법. 부정확하고 일반화 오류가 있음Heatmap classification: sementic segmentation처럼 하나의 채널의 하나의 key point를 담당, 각 key point마다 하나의 class로 생각. key point가 발생할 확률을 각 픽셀별로 classification. 계산량이 많다는 단점

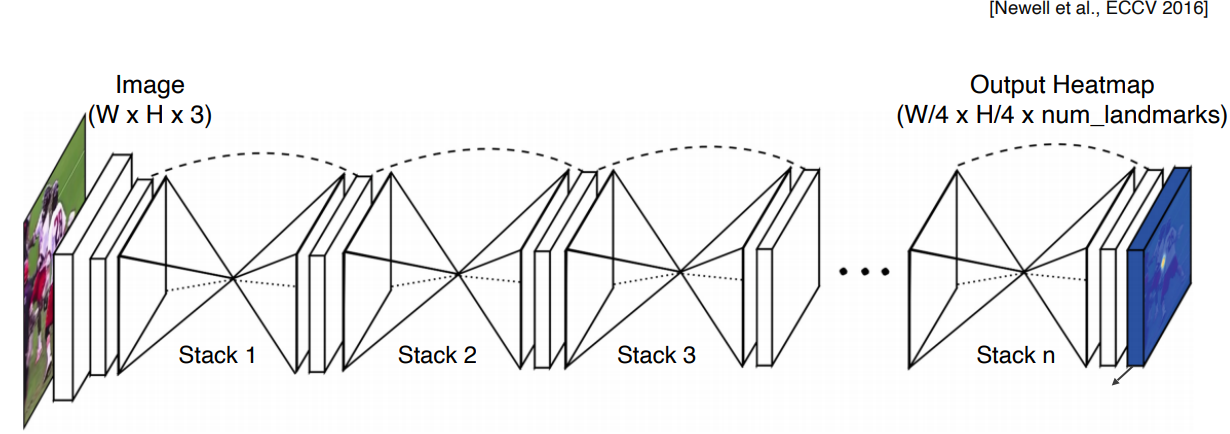
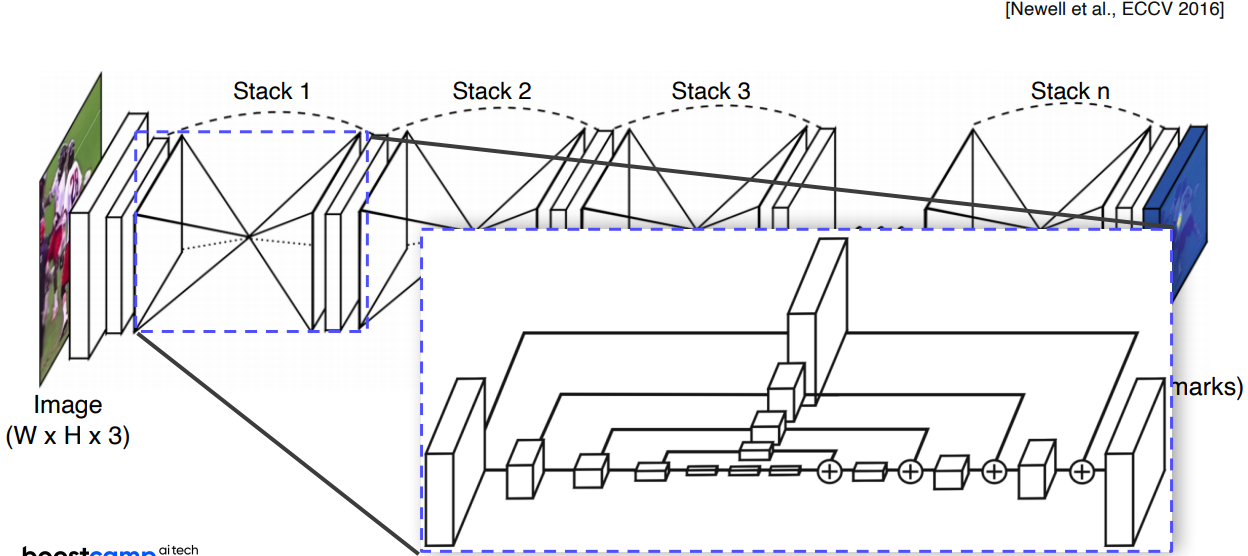
3.1 Hourglass network
stacked hourglass module구조- receptive field를 늘려서 넓은 영역을 보게함
conv layer를 통과하는 skip connection 구조가 있음- UNet과 비슷한 구조(
concat대신plus)
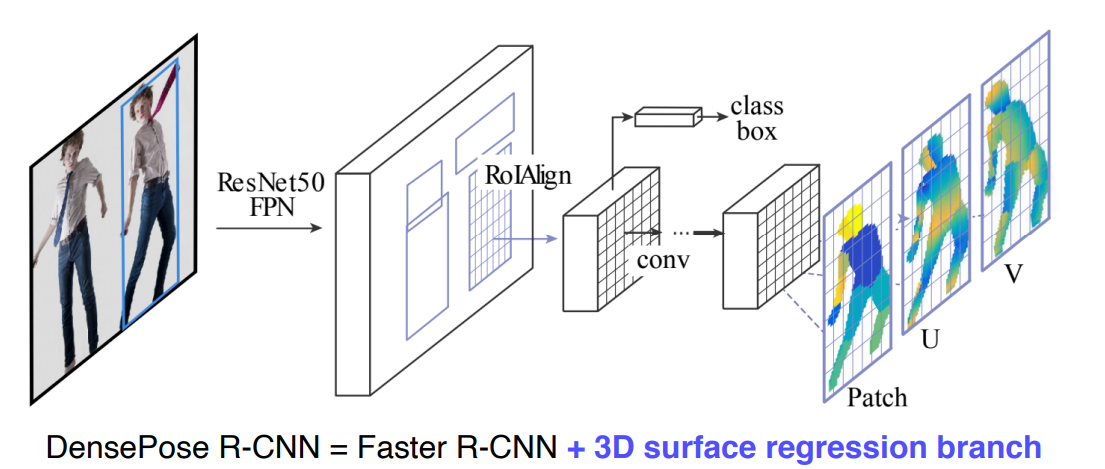
3.2 DensePose
- 신체 모든부위의 landmark 위치를 알게되면 3D를 알게되는 것과 마찬가지임
- UV map 표기법


인공지능 꿈나무