1. Conditional Generative Model
- 확률모형으로 추정
- : 낮은 퀄리티의 오디오를 높은 퀄리티의 오디오로 변환
- : 다른 언어로 변환
- : 부제목으로 나머지 글 생성

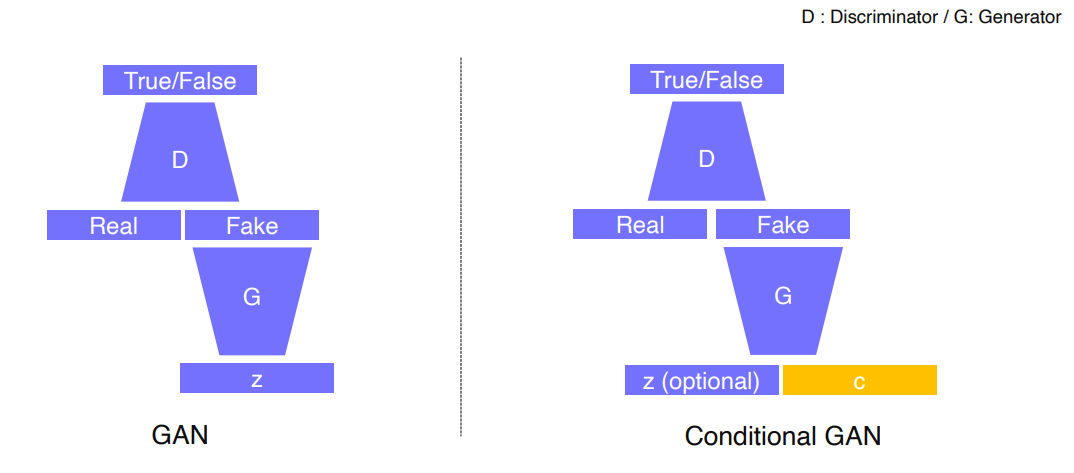
1.1 Conditional GAN
- 기존 GAN에
condition만 추가된 형태
Style transfer,Super resolution,Colorization등이 존재



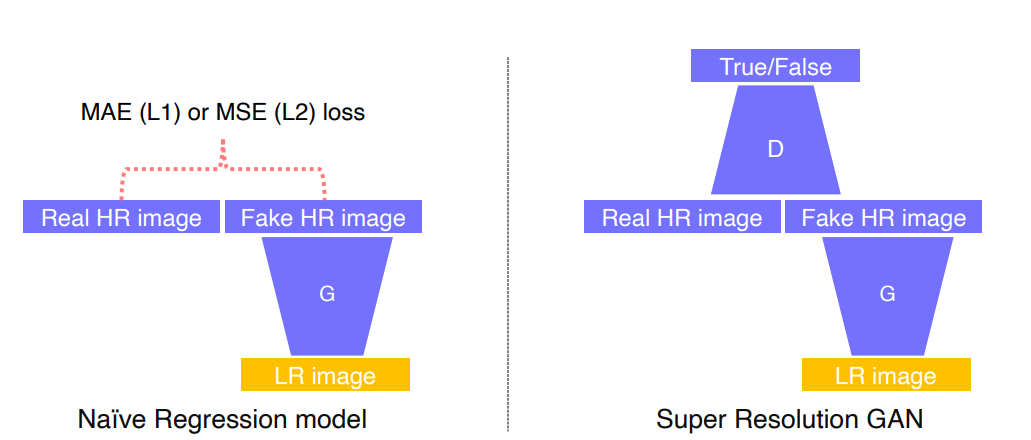
1.2 super resolution
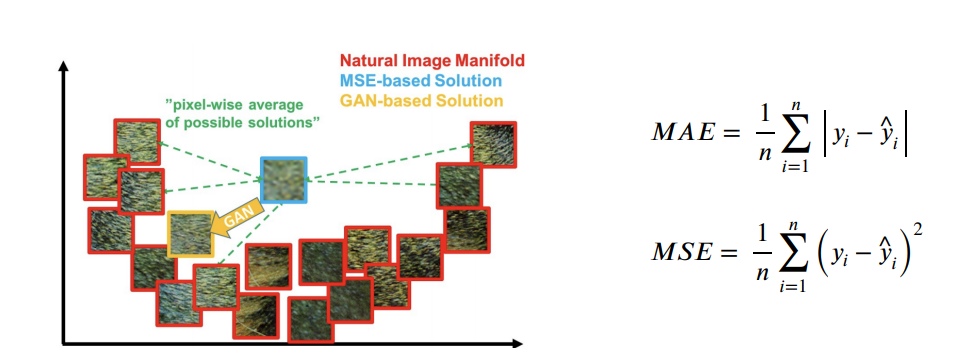
regression을 이용하는 방법과GAN을 이용하는 방법 이 존재- MSE/MAE를 사용하는 경우 실제 이미지에 가깝게 생성하지 않고 실제 이미지의
평균점으로 최적화가 이루어짐
2. Image Translation GANs
2.1 Pix2Pix
- 일반적으로 입력해상도와 출력해상도가 일치
- loss
L1 loss: target 이미지와 조금 더 가까워 지게하는 역할, loss 적용을 위해y(target)이 존재해야함GAN loss: 생성되는 이미지를 realistic하게 생성하는 역할
L1 loss만 적용하는경우 blur된 이미지GAN loss만 적용하는 경우 원본과 다른 이미지L1+GAN loss를 함께 적용하면서 target과 비슷하면서 realistic한 이미지를 생성할 수 있음



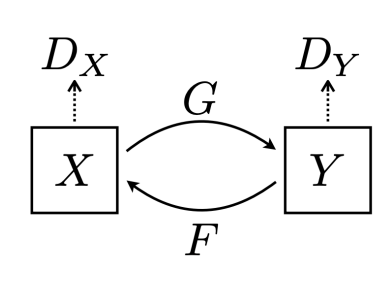
2.2 CycleGAN
non-pairwise데이터셋 사용
- loss
- ,
- ,
- :
cycle-cosisitency lossGAN loss: X) + Y) + +

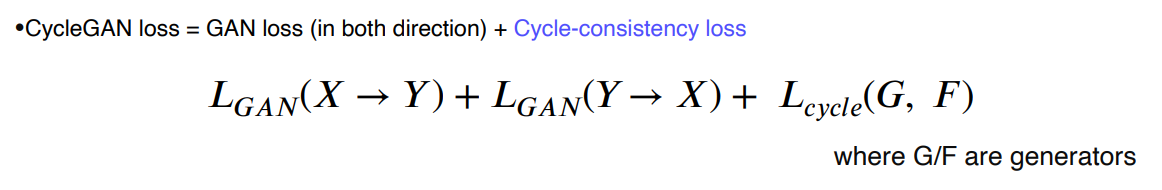
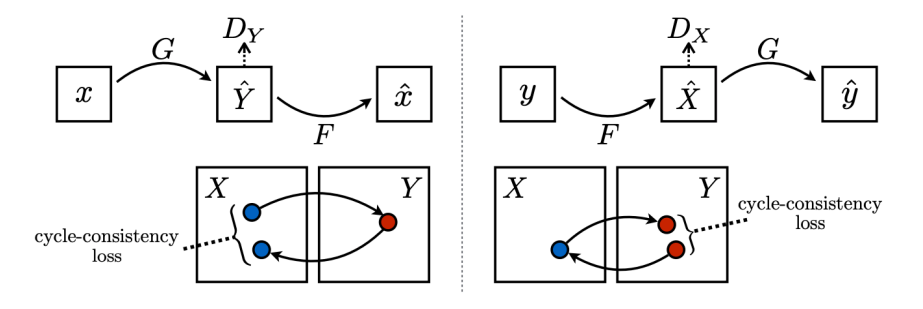
2.3 Perceptual loss
GAN loss(=adversarial loss)
- 상대적으로 학습이 어려움
- pre-train 모델이 필요하지 않음
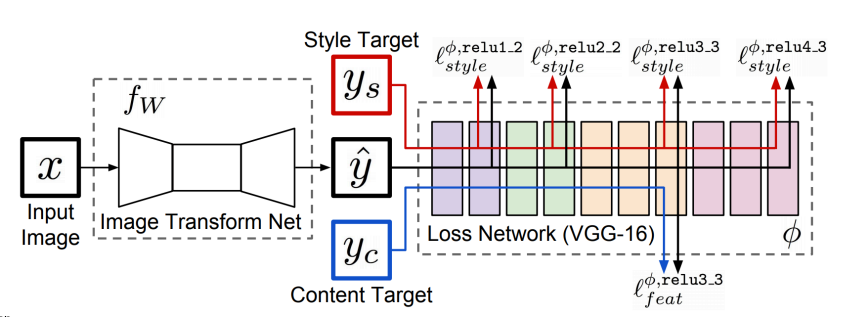
Perceptual loss
- 학습이 간단함
- pre-train 모델이 필요
- GAN을 사용하지 않고 생성모델을 만들 수 있음
Image Transform Net
- image transform net은 모델당 하나의 스타일만 가능
- -> (스타일 바꾼 원본이미지)
- loss network(VGG)는 freeze
feature reconstruction loss
transformed image:Image Transform Net을 통과해서 나온 이미지()content target: 원본- 두 이미지를
loss network(VGG)에 통과시켜L2 loss로 비교- 에 있었던 내부의 contents(ex. 강아지, 아기)가 남아있게 하는 역할
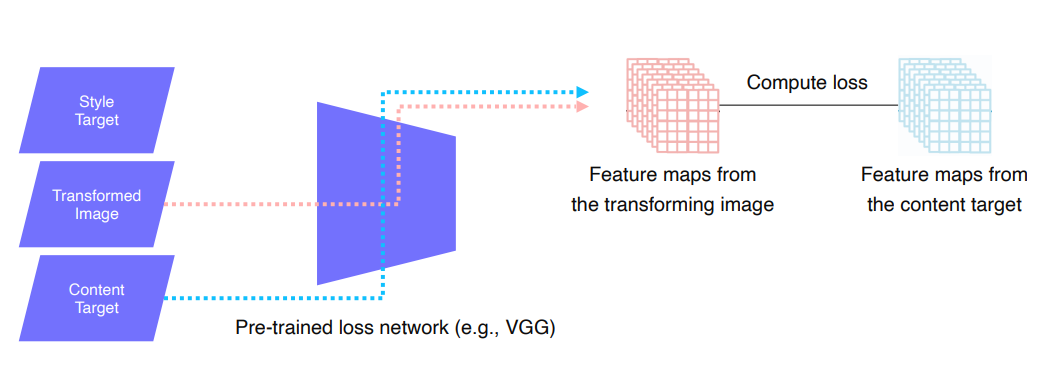
style reconstruction loss
style을 구하는 lossstyle target: ex.반고흐 스타일의 이미지- 두 이미지를
loss network(VGG)에 통과시켜Gram matrices를 얻고,L2 loss로 비교Gram matrices( x ): 공간정보 없이 이미지 전반에 걸친 통계적 특성(style)을 담음feature map을 pooling하여 ( x x ) -> ( x )만들고, ( x ) @ ( x )' 행렬곱을 하여 ( x )크기의Gram matrices를 만듦- 채널은 각각 다른 특징을 detection한다는 것을 바탕으로
Gram matrice는 점곱을 통해 채널 사이의 유사도를 보여줌transformed image()의Gram matrix가style target의Gram matrix를 따라가게 학습을 시킴

3.Various GAN applications
- Deepfake
- Ethical concern about deepfake
- face de-identification
- face anoymization with passcode
- video translatyion
- TTS
- voice conversion
4.과제

인공지능 꿈나무